

一、storm vs hadoop
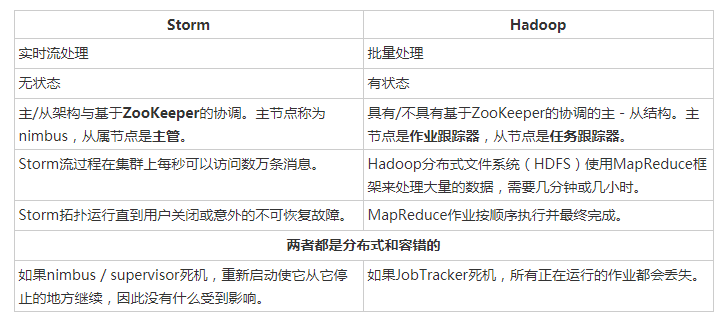
基本上Hadoop和Storm框架用于分析大数据。两者互补,在某些方面有所不同。Apache Storm执行除持久性之外的所有操作,而Hadoop在所有方面都很好,但滞后于实时计算。下表比较了Storm和Hadoop的属性。
二、storm术语
spout //水龙头,stream的源头,通常接受twitter,kafka的数据,传递数据给bolt,可以多实例(多线程)
bolt //转接头,是逻辑处理单元,filter,agg,join。。。交给下一个bolt,生成输出,可以多实例(多线程)
tuple //元祖,是storm主要的数据结构,是有序元素列表,逗号分隔值
stream //一系列tuple
topoloy //spout产生数据,交给bolt处理,依次下传。top始终是运行态
task //spout和每个bolt执行的程序就是task
worker //工作进程。top以分布式方式运行,storm会在worker集合上均匀分发task。worker节点的角色是监听job,启动或停止新job
三、架构
nimbus(master) //运行top。收集task运行的信息,分发给supervisor。
//负责分发数据,给worker指定task,监控故障
slave(supervisor) //可以一个或多个work进程,类似于yarn的NM.接受nimbus的指令,
//接受nimbus的指定,管理多个worker进程以及指派task给worker
work process //自身不执行task,而是创建executor,并让他执行task
//每个worker进程有多个executor.
thread(executor) //executor可执行多task,但是都必须同属于一个bolt(spout)
task //任务处理
zk //协调
