云原生学习作业9
一.日志收集案例-容器内置日志收集
tomcat-filebeat镜像打包、配置太复杂,操作失败。
二.overlay与underlay通信总结
Overlay网络和Underlay网络是一组相对概念,Overlay网络是建立在Underlay网络上的逻辑网络。
1、underlay:
Underlay 网络是由各类物理设备构成,通过使用路由协议保证其设备之间的IP连通性的承载网络。可以理解为物理网络。
Underlay网络正如其名,是Overlay网络的底层物理基础。
在Underlay网络中,互联的设备可以是各类型交换机、路由器、负载均衡设备、防火墙等,但网络的各个设备之间必须通过路由协议来确保之间IP的连通性。Underlay网络可以是二层也可以是三层网络。其中二层网络通常应用于以太网,通过VLAN进行划分。三层网络的典型应用就是互联网,其在同一个自治域使用OSPF、IS-IS等协议进行路由控制,在各个自治域之间则采用BGP等协议进行路由传递与互联。随着技术的进步,也出现了使用MPLS这种介于二三层的WAN技术搭建的Underlay网络。
2、overlay:
Overlay 网络是通过网络虚拟化技术,在同一张Underlay网络上构建出的一张或者多张虚拟的逻辑网络。不同的Overlay网络虽然共享Underlay网络中的设备和线路,但是Overlay网络中的业务与Underlay网络中的物理组网和互联技术相互解耦。Overlay网络的多实例化,既可以服务于同一租户的不同业务(如多个部门),也可以服务于不同租户,是SD-WAN以及数据中心等解决方案使用的核心组网技术。可以理解为逻辑网络。相互连接的Overlay设备之间建立隧道,数据包准备传输出去时,设备为数据包添加新的IP头部和隧道头部,并且被屏蔽掉内层的IP头部,数据包根据新的IP头部进行转发。当数据包传递到另一个设备后,外部的IP报头和隧道头将被丢弃,得到原始的数据包,在这个过程中Overlay网络并不感知Underlay网络。
三.网络组件flannel总结
Flannel是由CoreOS提出的跨主通信容器网络解决方案,通过分配和管理全局唯一容器IP以及实现跨组网络转发的方式,构建基于Overlay Network的容器通信网络。Flannel的框架包含以下组件:每个节点上的代理服务flanneld,负责为每个主机分配和管理子网;全局的网络配f置存储etcd(或K8S API)负责存储主机和容器子网的映射关系;多种网络转发功能的后端实现。最常见的模式有三种:UDP、VXLAN和Host-gateway。
1,UDP
UDP是与Docker网桥模式最相似的实现模式。不同的是,UDP模式在虚拟网桥基础上引入了TUN设备(flannel0)。TUN设备的特殊性在于它可以把数据包转给创建它的用户空间进程,从而实现内核到用户空间的拷贝。在Flannel中,flannel0由flanneld进程创建,因此会把容器的数据包转到flanneld,然后由flanneld封包转给宿主机发向外部网络。
UDP转发的过程为:Node1的container-1发起的IP包(目的地址为Node2的container-2)通过容器网关发到docker0,宿主机根据本地路由表将该包转到flannel0,接着发给flanneld。Flanneld根据目的容器容器子网与宿主机地址的关系(由etcd维护)获得目的宿主机地址,然后进行UDP封包,转给宿主机网卡通过物理网络传送到目标节点。在UDP数据包到达目标节点后,根据对称过程进行解包,将数据传递给目标容器。
UDP模式使用了Flannel自定义的一种包头协议,实现三层网络Overlay网络处理跨主通信的问题。但是由于数据在内核和用户态经过了多次拷贝:容器是用户态,docker0和flannel0是内核态,flanneld是用户态,最终又要通过内核将数据发到外部网络,因此性能损耗较大,对于有数据传输有要求的在线业务并不适用。
2,VXLAN
如果要进行性能优化,就需要减少用户态与内核态之间的数据拷贝,这就是VXLAN模式解决的问题。VXLAN的核心在于在三层网络的基础上构建了二层网络,使分布在不同节点上的所有容器在这个虚拟二层网络下自由通信。二层虚拟网络通过VXLAN在宿主机上创建的VTEP设备(flannel.1)实现,flannel.1和flanneld一样负责封包解包工作,不同的是flannel.1的封解包对象是二层数据帧,在内核中完成。
VXLAN的转发过程为:Node1的容器container-1发出的数据包经过docker0,路由给VTEP设备。每个在flannel网络中的节点,都会由flanneld维护一张路由表,指明发往目标容器网段的包应该经过的VTEP设备IP地址。Node1的VTEP会获得数据包应该发向Node2的VTEP设备的IP,并通过本地的ARP表知道目的VTEP设备的MAC地址,然后封装在数据包头部构成二层数据帧并再加上VXLAN头,标识是由VTEP设备处理的数据帧。另外,flannel会维护转发数据库FDB,记录目标VTEP的MAC地址应该发往的宿主机(也就是Node2),宿主机网卡将封装为外部网络传输的包转发到Node2。数据帧在Node2上解封后,宿主机会识别VXLAN头部,直接在内核拆包,然后转发到目标VTEP设备并转到对应容器。
作为Flannel中最被普遍采用的方案,VXLAN采用的是内置在Linux内核里的标准协议,因此虽然封包结构比UDP模式复杂,但装包和解包过程均在内核中完成,实际的传输速度要比UDP模式快许多。较快的传输速度和对底层网络的可兼容性也使得VXLAN适用性较其他模式更高,成为业务环境下的主流选择。
3,Host-gateway
host-gw是一种主机网关模式,每个主机会维护一张路由表,记录发往某目标容器子网的数据包的下一跳IP地址(也就是子网所在宿主机的IP)。宿主机将下一跳目的主机的MAC地址作为目的地址,通过二层网络把包发往目的主机。目的主机收到后,会直接转发给对应容器。所以host-gw模式下,数据包直接以容器IP包的形式在网络中传递,每个宿主机就是通信链路中的网关。
和其他两种模式相比,host-gw模式少了额外的封包和拆包过程,效率与虚拟机直接的通信相差无几。但是,该模式要求所有节点都在物理二层网络中联通,且每个主机都需要维护路由表,节点规模较大时有较大的维护压力,因此不适用复杂网络。
四.网络组件calico总结
Calico 是一个三层的虚拟网络解决方案,它把每个节点都当作虚拟路由器(vRouter),并把每个节点上的 Pod 都当作是“节点路由器”后的一个终端设备并为其分配一个 IP 地址。各节点路由器通过 BGP 协议学习生成路由规则,从而实现不同节点上 Pod 间的互联互通。
Calico 把 Kubernetes 集群环境中的每个节点上的 Pod 所组成的网络视为一个自治系统,而每个节点也就自然由各自的 Pod 对象组成虚拟网络,进而形成自治系统的边界网关。各节点间通过 BGP 协议交换路由信息并生成路由规则。
BGP 模式:将节点做为虚拟路由器通过 BGP 路由协议来实现集群内容器之间的网络访问。
IPIP 模式:在原有 IP 报文中封装一个新的 IP 报文,新的 IP 报文中将源地址 IP 和目的地址 IP 都修改为对端宿主机 IP。
cross-subnet:Calico-ipip 模式和 calico-bgp 模式都有对应的局限性,对于一些主机跨子网而又无法使网络设备使用 BGP 的场景可以使用 cross-subnet 模式,实现同子网机器使用 calico-BGP 模式,跨子网机器使用 calico-ipip 模式。
五.NetworkPolicy Ingress及Egress简介及案例
NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许 Pod 与网络上的各类网络“实体” 通信。ingress:每个 NetworkPolicy 可包含一个
ingress 规则的白名单列表。 每个规则都允许同时匹配 from 和 ports 部分的流量。示例策略中包含一条简单的规则: 它匹配某个特定端口,来自三个来源中的一个,第一个通过 ipBlock 指定,第二个通过 namespaceSelector 指定,第三个通过 podSelector 指定。egress:每个 NetworkPolicy 可包含一个
egress 规则的白名单列表。 每个规则都允许匹配 to 和 port 部分的流量。该示例策略包含一条规则, 该规则将指定端口上的流量匹配到 10.0.0.0/24 中的任何目的地。示例1:
隔离
default 名字空间下 role=db 的 Pod 。Ingress 规则:允许以下 Pod 连接到
default 名字空间下的带有 role=db 标签的所有 Pod 的 6379 TCP 端口: 1),default 名字空间下带有 role=frontend 标签的所有 Pod2),带有
project=myproject 标签的所有名字空间中的 Pod3),IP 地址范围为 172.17.0.0–172.17.0.255 和 172.17.2.0–172.17.255.255 (即,除了 172.17.1.0/24 之外的所有 172.17.0.0/16)
Egress 规则:允许
default 名字空间中任何带有标签 role=db 的 Pod 到 CIDR 10.0.0.0/24 下 5978 TCP 端口的连接。
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy namespace: default spec: podSelector: matchLabels: role: db policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 172.17.0.0/16 except: - 172.17.1.0/24 - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 6379 egress: - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978
2,拒绝所有入站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
3,允许所有入站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
4,拒绝所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
5,允许所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
六,Ingress使用总结
Ingress 可为 Service 提供外部可访问的 URL、负载均衡流量、终止 SSL/TLS,以及基于名称的虚拟托管。
ingress相当于service的service,可以将外部请求通过不同规则的筛选后转发到不同的service,实现k8s集群外部对k8s集群内部服务的访问。
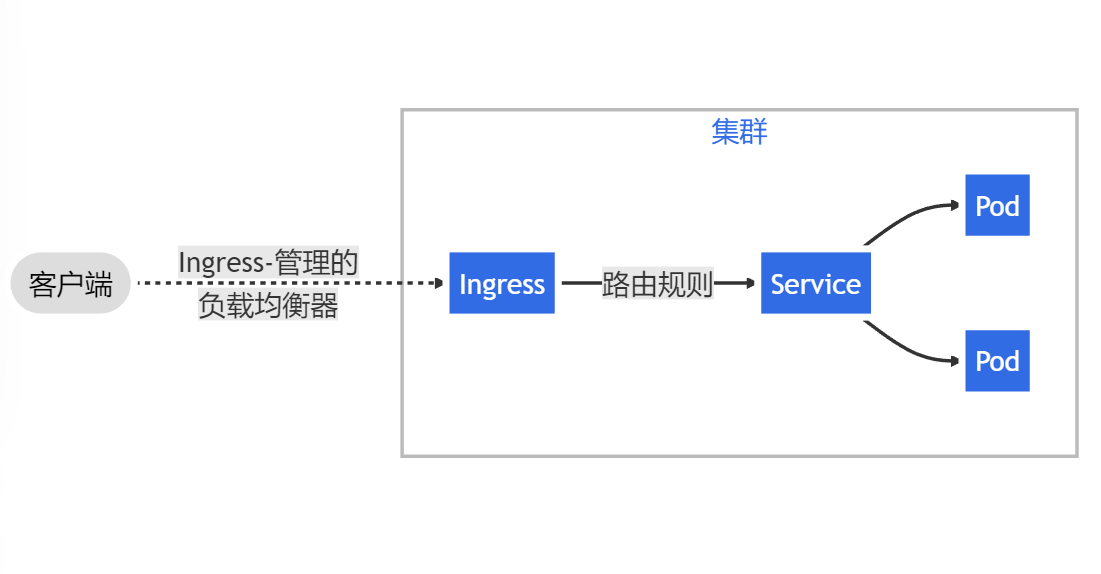
示例:用ingress通过域名apiserver.km.cloud.com将cbs-apiserver(k8s集群内service)向集群外提供访问接口。
apiVersion: extensions/v1beta1 kind: Ingress metadata: generation: 1 name: cbs-apiserver-ingress namespace: tce spec: rules: - host: apiserver.km.cloud.com http: paths: - backend: serviceName: cbs-apiserver servicePort: 8000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号