云原生学习作业8
一.Kubernetes Container、Pod、Namespace内存及CPU限制
1,对pod内单个容器资源限制实例yaml文件
apiVersion: v1 kind: Pod metadata: name: nginx-pod spec: containers: - name: nginx image: nginx resources: requests: cpu: "250m" memory: "64Mi" limits: memory: "128Mi" cpu: "500m"
2,对单个pod进行资源限制
apiVersion: v1 kind: LimitRange metadata: name: limitrange namespace: myserver spec: limits: - type: Container #限制的资源类型 max: cpu: "2" #限制单个容器的最大可以用的CPU memory: "2Gi" #限制单个容器的最大可以用的内存 min: cpu: "500m" #限制单个容器的最小需要使用CPU memory: "512Mi" #限制单个容器的最小需要使用的内存 default: cpu: "500m" #默认单个容器的CPU限制 memory: "512Mi" #默认单个容器的内存限制 defaultRequest: cpu: "500m" #默认单个容器的CPU创建请求 memory: "512Mi" #默认单个容器的内存创建请求 maxLimitRequestRatio: cpu: 2 #限制CPU limit/request比值最大为2,限制的CPU数除请求的CPU不能大于2 memory: 2 #限制内存limit/request比值最大为2,限制的内存数除请求的内存数不能大于2 - type: Pod max: cpu: "4" #限制单个Pod的最大CPU,所有容器CPU数加起来最大不能超过4 memory: "4Gi" #限制单个Pod最大内存,所有容器内存加起来最大不能超过4 - type: PersistentVolumeClaim max: storage: 50Gi #限制PVC最大的requests.storage min: storage: 30Gi #限制PVC最小的requests.storage
3,对某个namespace进行资源限制
apiVersion: v1 kind: ResourceQuota metadata: name: quota namespace: myserver spec: hard: requests.cpu: "8" limits.cpu: "8" requests.memory: 8Gi limits.memory: 8Gi pods: "6" services: "6"
二 .nodeSelector、nodeName、node亲和与反亲和
1,nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。你可以将 nodeSelector 字段添加到 Pod 的规约中设置你希望目标节点所具有的节点标签。 Kubernetes 只会将 Pod 调度到拥有你所指定的每个标签的节点上。
示例:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: tomcat-deploy spec: replicas: 1 template: metadata: labels: app: tomcat-app spec: nodeSelector: role: backend containers: - name: tomcat image: tomcat ports: - containerPort: 8080
2,nodeName
用于强制约束将Pod调度到指定的Node节点上,这里说是“调度”,但其实指定了nodeName的Pod会直接跳过Scheduler的调度逻辑,直接写入PodList列表,该匹配规则是强制匹配。
示例:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: tomcat-deploy spec: replicas: 1 template: metadata: labels: app: tomcat-app spec: nodeName: k8s.node1 containers: - name: tomcat image: tomcat ports: - containerPort: 8080
3,node亲和与反亲和
节点亲和性概念上类似于 nodeSelector, 它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于nodeSelector, 但其语法表达能力更强。preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
示例:
apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - antarctica-east1 - antarctica-west1 preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: another-node-label-key operator: In values: - another-node-label-value containers: - name: with-node-affinity image: registry.k8s.io/pause:2.0
三.pod亲和与反亲和、污点与容忍、驱逐
1,pod亲和与反亲和
pod 间亲和性与反亲和性可以基于已经在节点上运行的 Pod 的标签来约束 Pod 可以调度到的节点,而不是基于节点上的标签。
示例:
apiVersion: v1 kind: Pod metadata: name: with-pod-affinity spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: topology.kubernetes.io/zone podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: security operator: In values: - S2 topologyKey: topology.kubernetes.io/zone containers: - name: with-pod-affinity image: registry.k8s.io/pause:2.0
2,污点与容忍、驱逐
2.1,节点亲和性是 Pod的一种属性,它使 Pod 被吸引到一类特定的节点 。 污点(Taint) 则相反——它使节点能够排斥一类特定的 Pod。
容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod, 是不会被该节点接受的。
使用命令给节点增加一个污点。比如,
kubectl taint nodes node1 key1=value1:NoSchedule
给节点 node1 增加一个污点,它的键名是 key1,键值是 value1,效果是 NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 node1 这个节点。
在Pod规约中为Pod设置容忍度,使Pod能调度到设置了污点的node1节点上:
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent tolerations: - key: "example-key" operator: "Exists" effect: "NoSchedule"
2.2,驱逐
目前k8s有4个主要的驱逐场景, 分别是手工驱逐,节点的压力驱逐,污点导致驱逐,pod抢占导致驱逐. 一般而言主要关注的是节点压力导致的驱逐.
2.2.1 手工驱逐
可以使用 drain 手工排空当前的计算节点. 不过在一般实践中都是先禁止调度,而后才是排空当前节点的 pod.
2.2.2 节点压力驱逐
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控集群节点的内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿。
2.2.3 污点驱逐
node在运行过程中,被设置了NoExecute的污点,会影响已经在节点上运行的 Pod,如下
- 如果 Pod 不能忍受这类污点,Pod 会马上被驱逐。
- 如果 Pod 能够忍受这类污点,但是在容忍度定义中没有指定
tolerationSeconds, 则 Pod 还会一直在这个节点上运行。 - 如果 Pod 能够忍受这类污点,而且指定了
tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。
2.2.4 pod抢占驱逐
Pod可以有优先级。 优先级表示一个 Pod 相对于其他 Pod 的重要性。 如果一个 Pod 无法被调度,调度程序会尝试抢占(驱逐)较低优先级的 Pod, 以使悬决 Pod 可以被调度。
四.搭建ELK及kafka日志收集环境
1,kafka
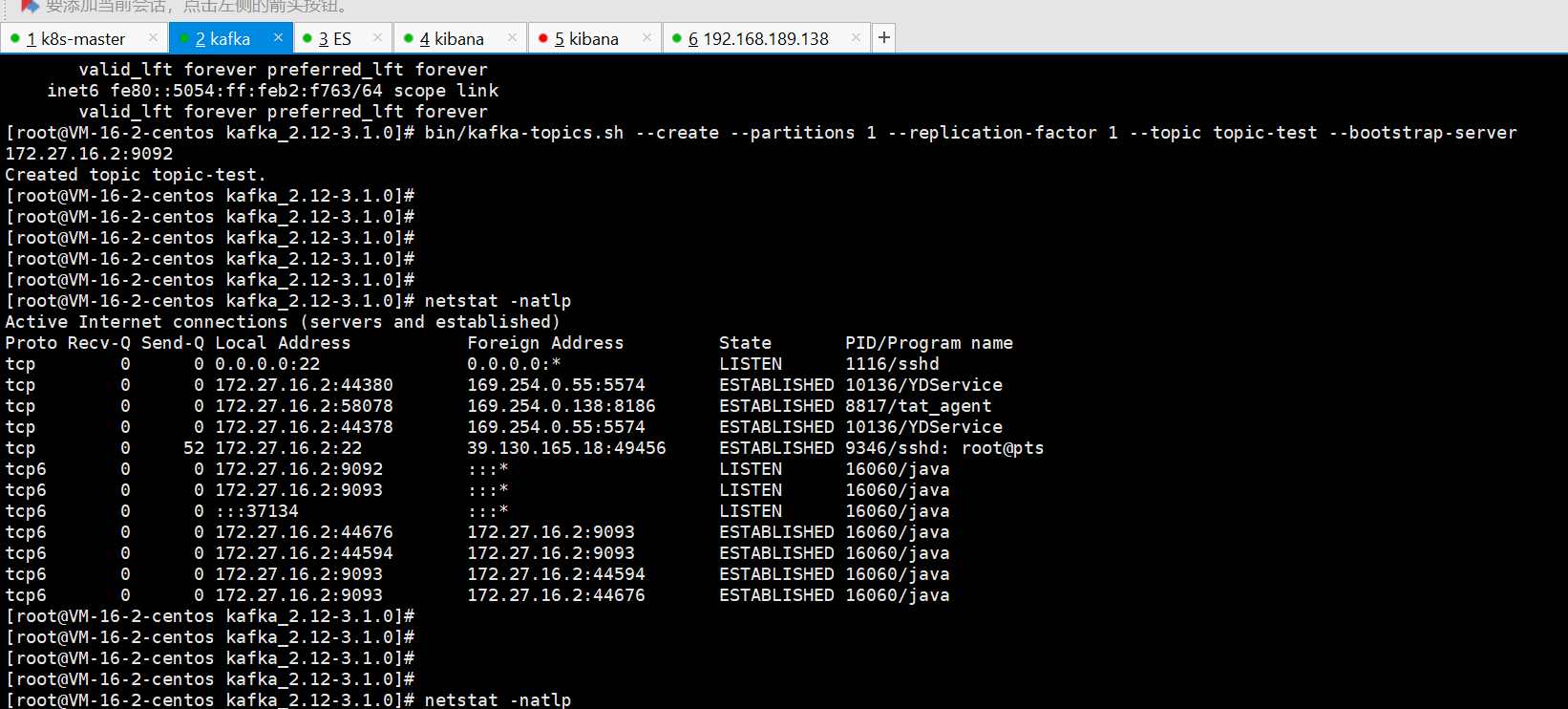
2, es
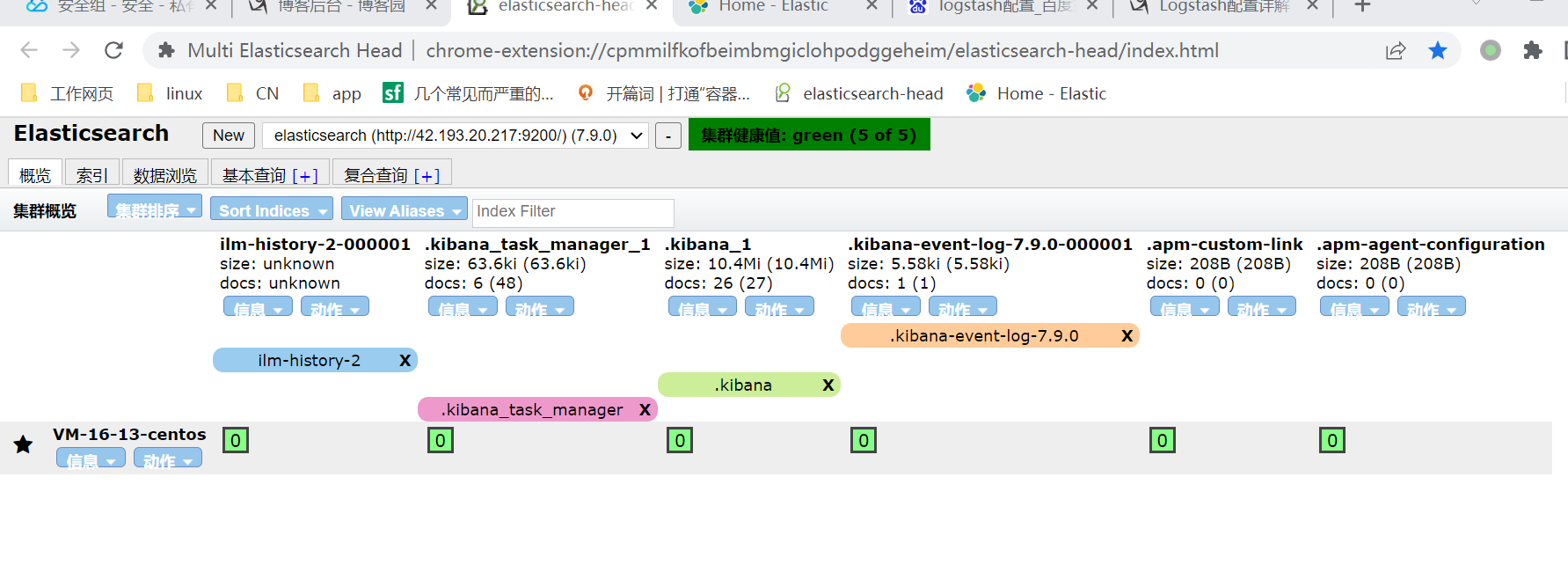
3, kibana
五.实现daemonset和
1, daemonset日志收集
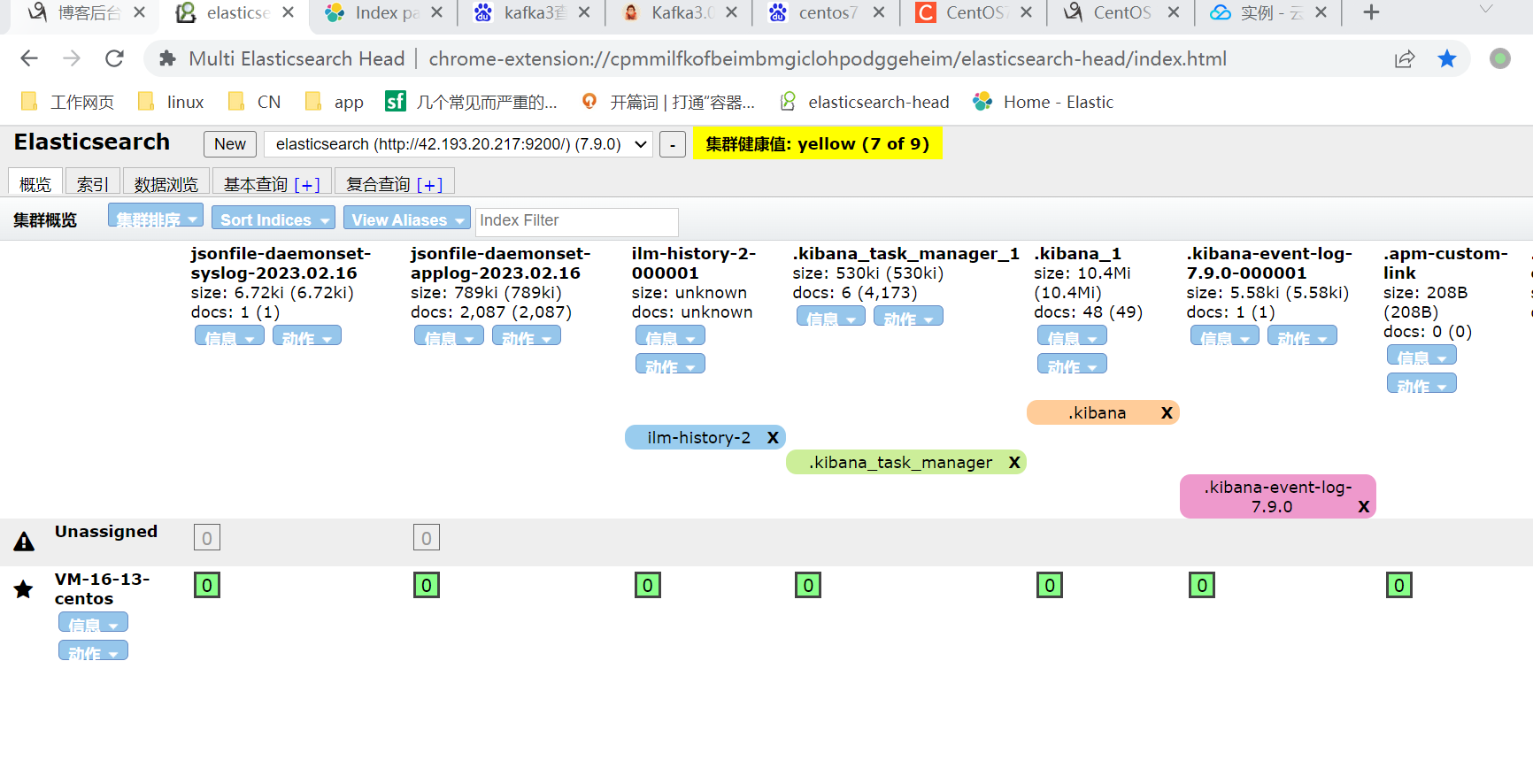
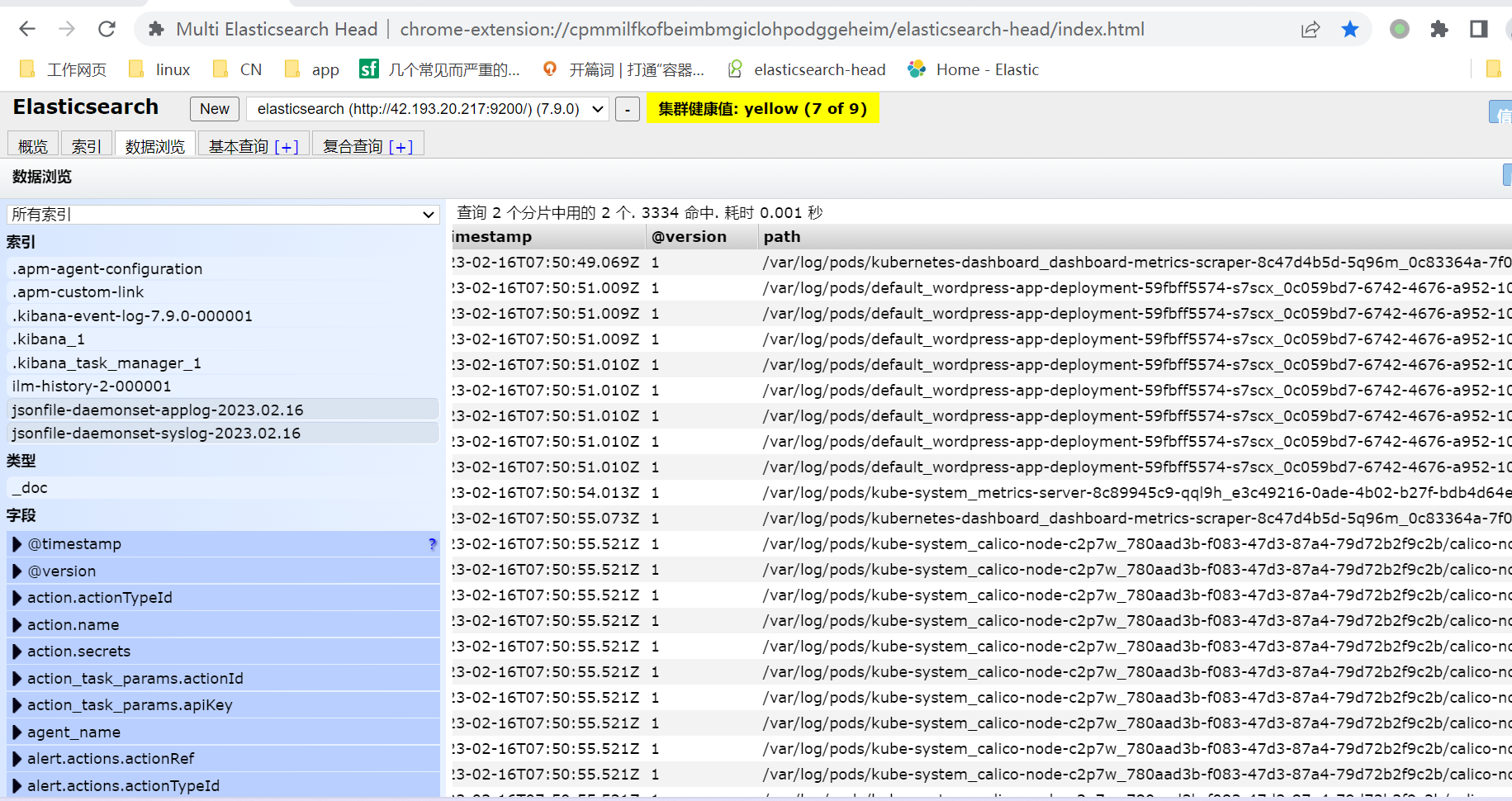
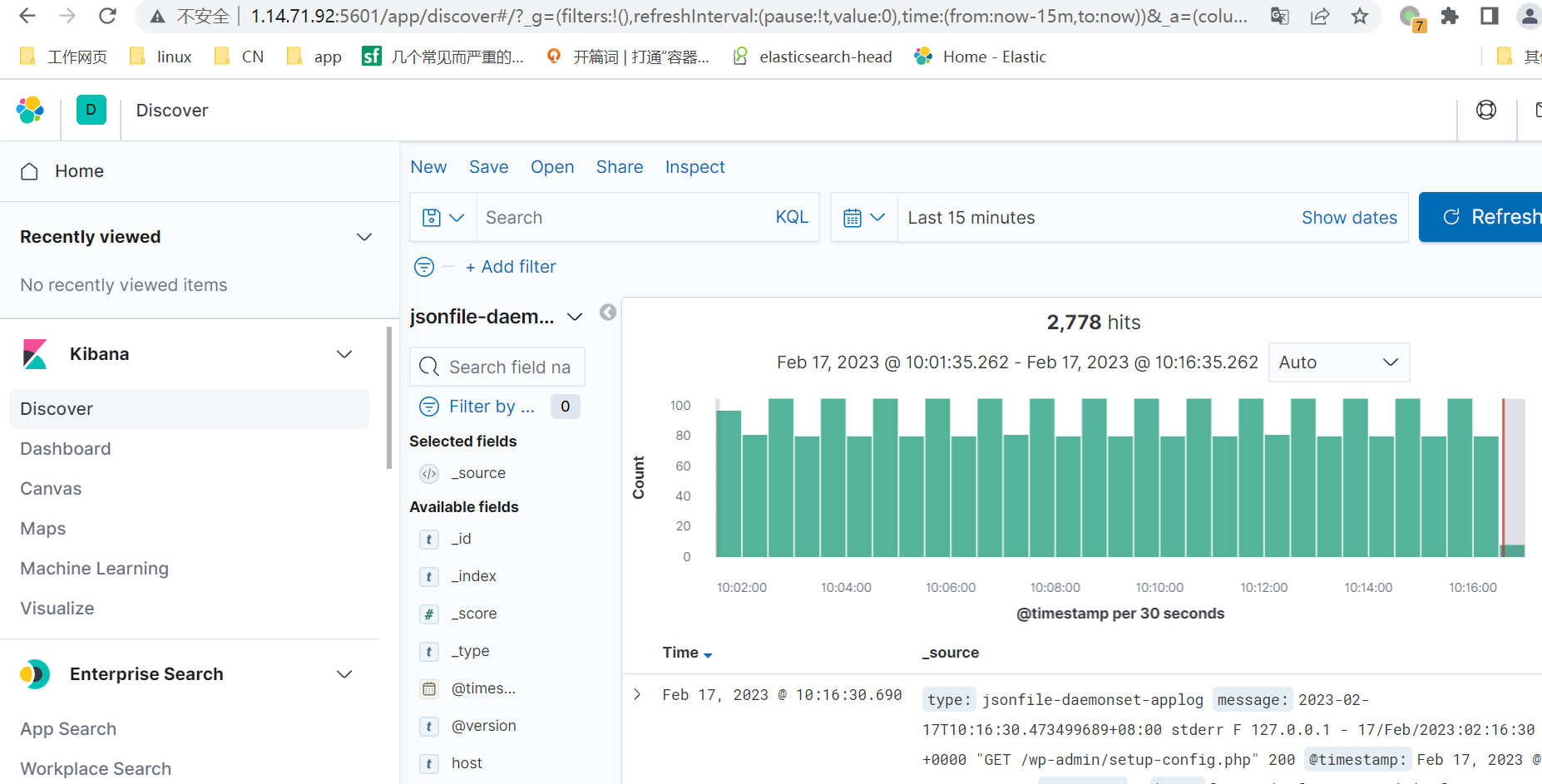
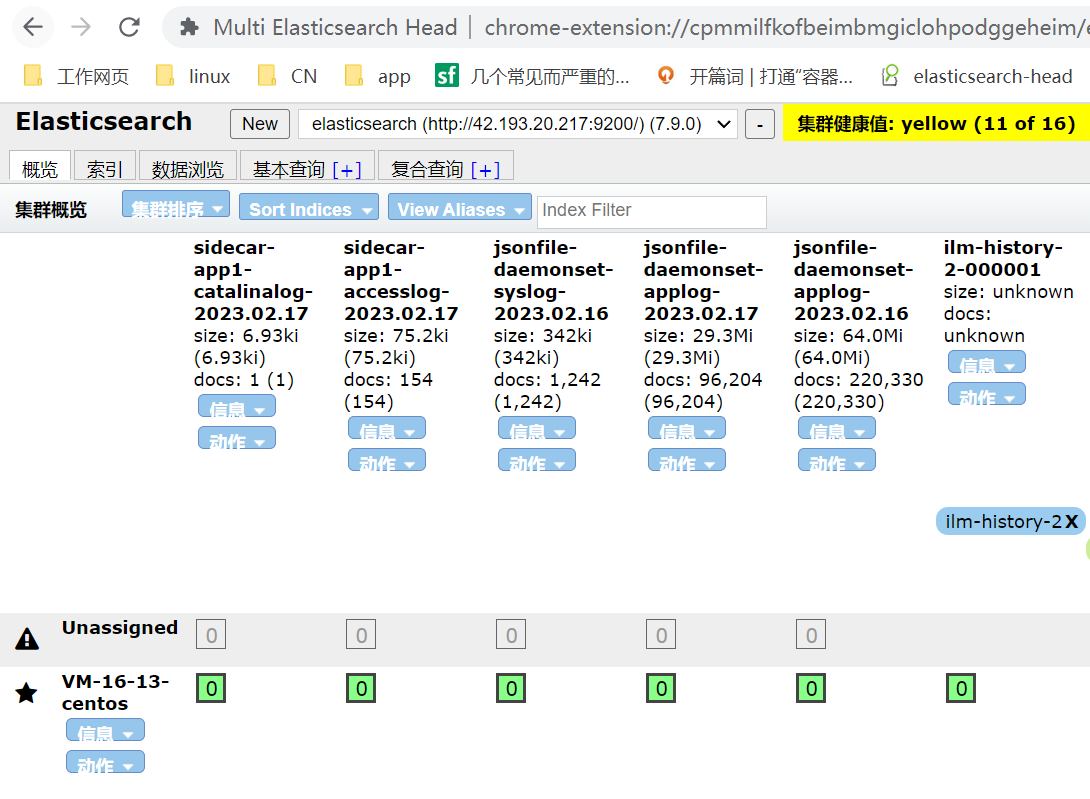
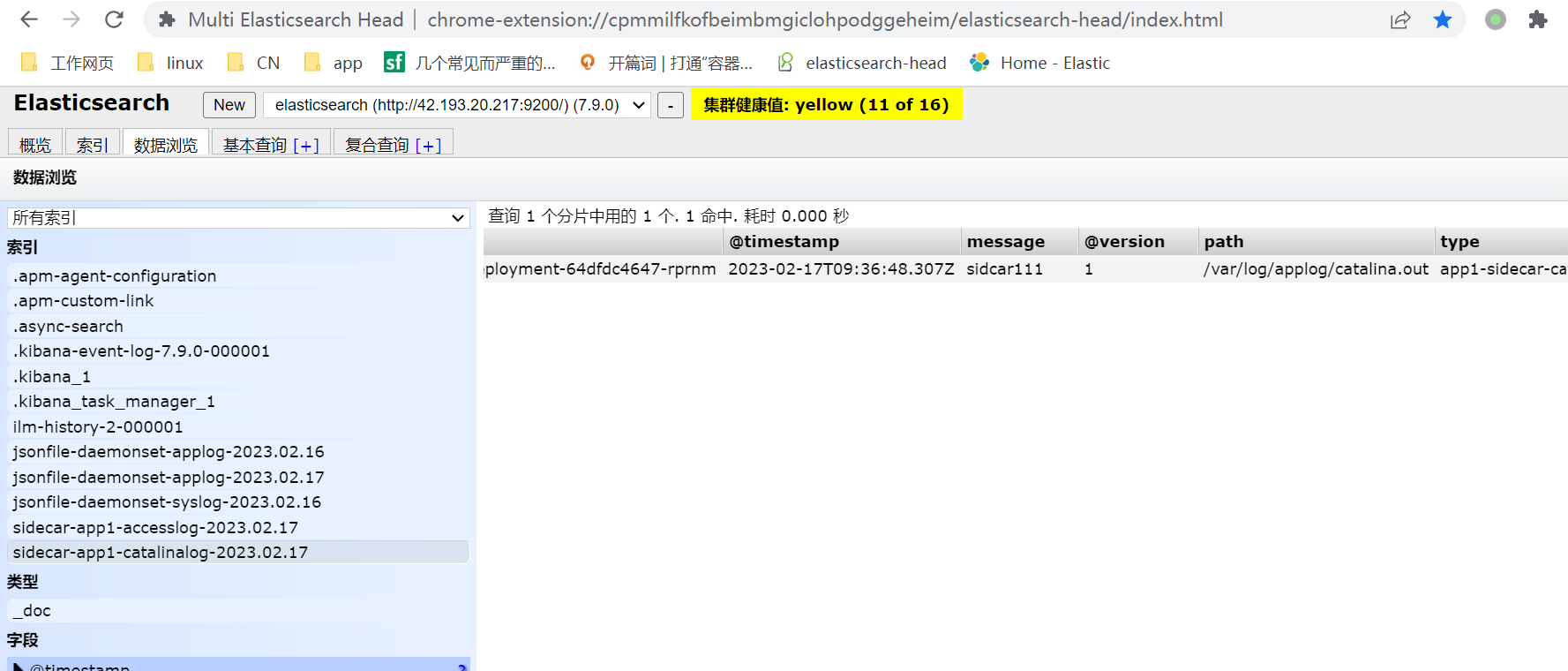
2,sidcar日志收集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号