云原生学习作业4
一,kubeasz高可用集群二进制部署
规划节点:
172.27.16.5 部署节点,master节点,etcd节点
172.27.16.12 master节点,etcd节点
172.27.16.17 etcd节点
172.27.16.7 node节点
172.27.16.10 node节点
虚拟机操作系统为Centos7.9
1, 以来工具安装
部署节点安装git 和ansible工具
2, 部署前准备工作:
配置从部署节点能够ssh免密登陆所有节点,并且设置python软连接
#$IP为所有节点地址包括自身,按照提示输入yes 和root密码# 为每个节点设置python软链接
ssh-copy-id $IP
# 为每个节点设置python软链接
ssh $IP ln -s /usr/bin/python3 /usr/bin/python
centos7.9操作系统已有python->python3链接,需先删除 rm -rf /usr/bin/python
3,下载项目源码、二进制及离线镜像
下载工具脚本ezdown,举例使用kubeasz版本3.3.1
export release=3.3.1
wget https://github.com/easzlab/kubeasz/releases/download/${release}/ezdown
chmod +x ./ezdown
下载kubeasz代码、二进制、默认容器镜像
# 国内环境 ./ezdown -D # 海外环境 #./ezdown -D -m standard
创建集群配置实例(并安需求修改配置文件)
./ezctl new k8s-cluster1
4,执行安装步骤(01 至 06)
./ezctl setup k8s-cluster1 01
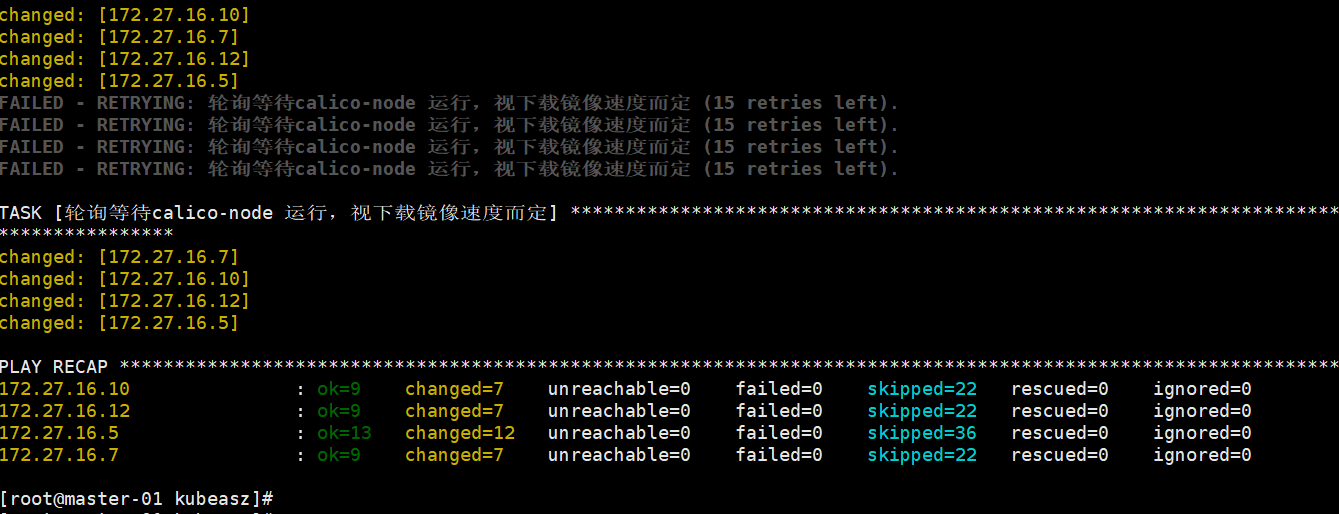
安装结果:
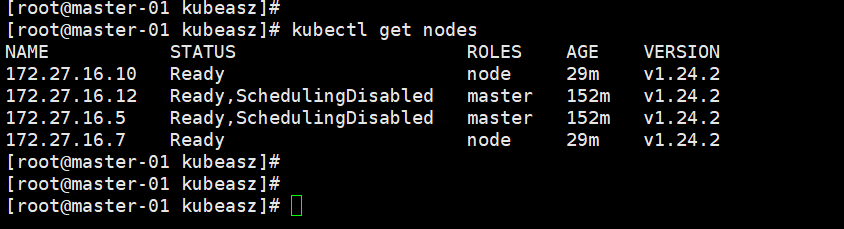
增加master节点:
./ezctl add-master k8s-cluster1 172.27.16.17
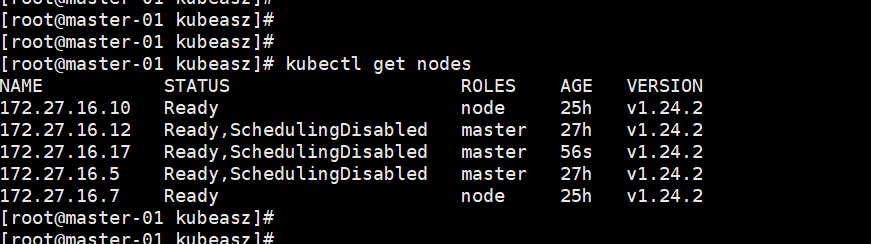
增加node节点:
./ezctl add-node k8s-cluster1 172.27.16.4
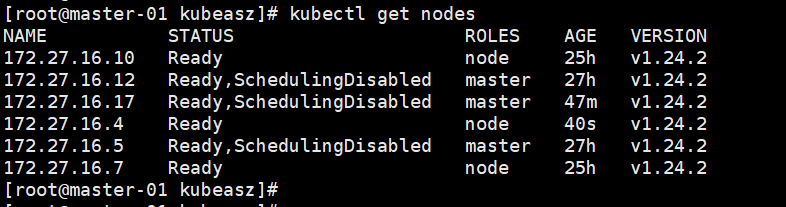
kubernetes集群升级:升级为V1.24.3
升级master:
先到node节点修改kube-lb配置,将要升级的master节点注释,重载服务配置
到升级的master节点停服务
systemctl stop kube-apiserver kube-controller-manager kube-scheduler kube-proxy kubelet
将新版本二进制文件拷贝到master节点/usr/local/bin/下覆盖已有文件
cp kube-apiserver kube-controller-manager kube-scheduler kube-proxy kubelet kubectl /usr/local/bin/
启动服务
systemctl start kube-apiserver kube-controller-manager kube-scheduler kube-proxy kubelet
到node节点修改kube-lb配置,取消已升级的master节点注释,重载服务配置
升级node节点:
master节点执行
kubectl drain 172.27.16.7 --ignore-daemonsets --force
到要升级的node节点停服务 systemctl stop kubelet kube-proxy
拷贝新版本二进制文件到node节点/usr/local/bin/
scp kube-proxy kubelet kubectl node-01:/usr/local/bin/
启动服务
systemctl start kubelet kube-proxy
在master节点执行
kubectl uncordon 172.27.16.7
升级后版本:
升级containerd:
升级前版本

升级过程:
先停止node节点容器,在停止kubelet、kubeproxy、containerd服务并取消开机启动,重启节点操作系统。
拷贝已下载好的新版本containerd,crictl,runc等二进制文件到node节点的/usr/local/bin/目录
启动kubelet、kubeproxy、containerd服务并设置开机启动,完成升级。node节点升级为1.6.6

二,etcd的备份和恢复-基于快照
备份:在部署节点执行 ./ezctl backup k8s-cluster1

恢复:在部署节点执行 ./ezctl restore k8s-cluster1
三,整理coredns的域名解析流程和Corefile配置
域名解析流程:
客户端(pod)将域名解析请求发给coredns的服务(kube-dns) —》 coredns后端pod收到请求 —》coredns后端pod将求情发到apiserver的服务(kubernetes) —>
apiserver收到请求后向etcd发送查询请求 —>》apiserver得到查询结果后,返回给coredns —》 coredns将结果返回给客户端(pod)
Corefile文件解读:
Corefile: | .:53 { errors #错误信息标准输出 health { #在CoreDNS的http://localhost:8080/health端口提供CoreDNS服务的健康报告 lameduck 5s } ready #监听8181端口,当CoreDNS的插件都已就绪时,访问该接口会返回200OK #CoreDNS将基于kubernetes.service.name进行DNS查询并返回查询记录给客户端 kubernetes cluster.local in-addr.arpa ip6.arpa { #修改成当时部署k8s时host文件里面CLUSTER_DNS_DOMAIN对应的值 pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 #度量指标数据以Prometheus的key-value的格式在http://localhost:9153/metrics URI 上提供 forward . /etc/resolv.conf { #不是kubernetes集群内的其他任务域名查询都将转发到预定义的目的server max_concurrent 1000 } cache 30 #启用servic解析缓存,单位为秒 loop #检测域名解析是否有死循环,如coredens转发给内网DNS服务器,而内网DNS服务器又转发给CoreDNS,如果发现死循环,则强制中止CoreDNS进程,kubernetes重建 reload #检测corefile是否更改,再重新编辑configmap配置后,默认2分钟后会自动加载 loadbalance #轮训DNS域名解析,如果一个域名存在多个记录则轮训解析 }
四,dashboard的使用
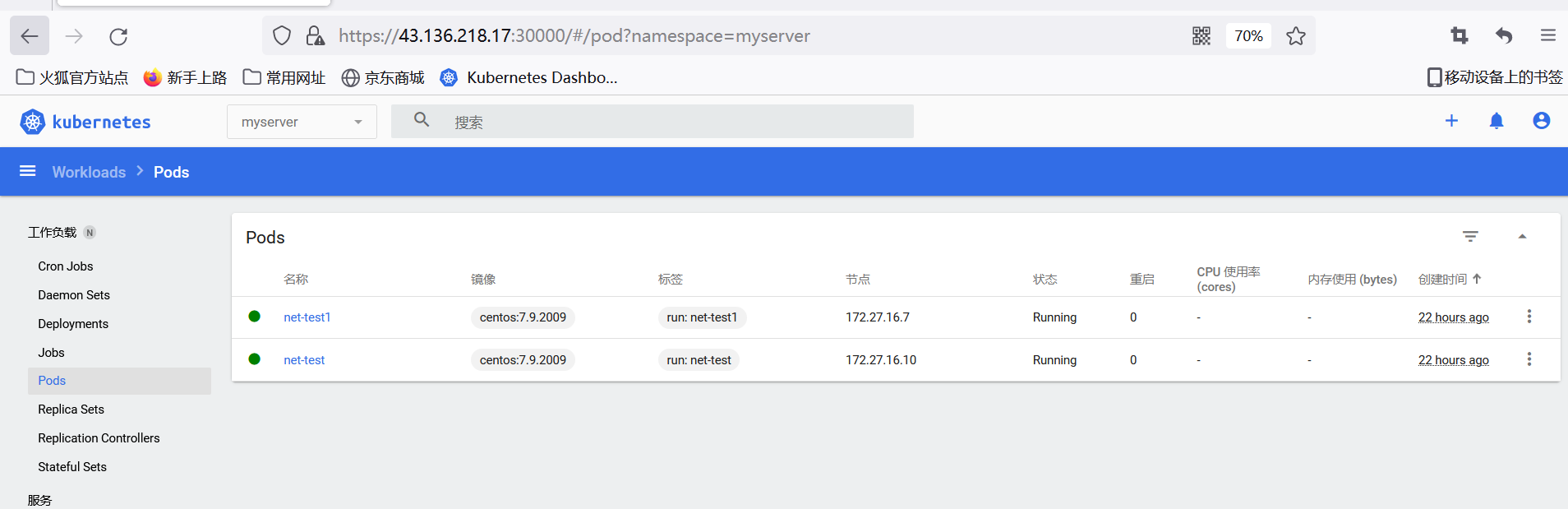
dashboard界面主要用于查询集群各资源对象状况,对各种控制器下的资源做扩缩容等简单操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号