【数据库】MySql的索引详解
简介
索引是一种用于快速查询和检索数据的数据结构,类似于书的目录。在几百页的书通过几页目录就可以精确定位到我们想看的章节
优点和缺点
- 优点
- 正确的使用索引可以大大提高检索速度
- 可以使用唯一索引保证数据在库中的唯一性
- 使用聚合索引减少回表,降低IO次数
- 缺点
- 索引不宜创建的太多,否则增删改时不仅修改数据,还要修改大量的索引数据
- 索引也会占用磁盘空间
索引结构
- B树:多路平衡查找树,B树的所有节点都会存储
key(索引)和data(行记录) - B+树:B树的变体,B+树只有叶子节点
key(索引)和data(行记录),其他节点都只存放key。B+树的叶子节点会存放相邻叶子节点指针, B树没有这个特性。 - Hash:键值对的集合,通过
key可以快速的查询到对应的value, - 黑红树
Mysql中,Innodb和MyISAM存储引擎都是用 B+树 - MyISAM中B+树叶子结点存放的是行记录的地址,如果要取到数据需要再进行一次IO,这样设计是因为 MyISAM中,数据和索引是两个文件
- Innodb中B+树叶子节点存放的是行记录,Innodb中,数据和索引是一个文件。
索引分类
- 主键索引:一张表只能有一个,主键不能为null,不能重复,如果没有显示指定,Innodb会自动检查是否有唯一且不能为null的字段,如果有选择该字段为默认主键,否则自动生成一个当做自增主键
- 普通索引:没有特殊要求,允许数据重复且可以为null,只是加快了查询速度
- 唯一索引:和普通索引一样,唯一区别是不允许数据重复,值可以为null
- 联合索引:多个字段一起创建一个索引,该索引有最左匹配原则,
- 最左匹配原则:如果where条件中包含索引中最左边的字段,就可以使用该索引,否则即使包含除了最左字段意外其他所有字段,都不会走索引查询
- 举例:组合索引 name age dep
- select name from table where name='A' 可以走索引
- select name from table where age=15 and dep='A' 不会走索引
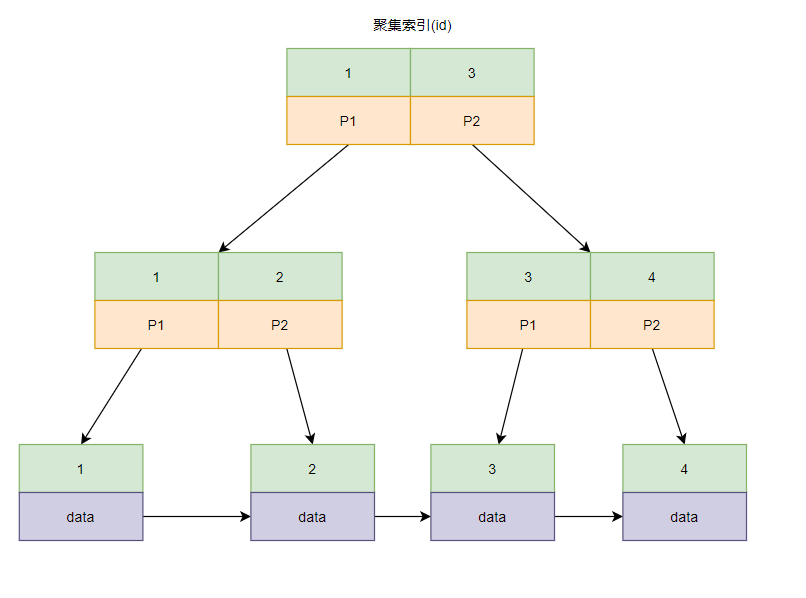
聚集索引
索引结构和数据存放在一起
- 优点
- 查询块,因为数据和索引在一个文件中,减少了一次IO
- 因为叶子节点是按照根据所以大小有序排列的,所以排序和范围查找很快
- 缺点
- 插入时,可能会导致数据跨页,造成大量IO操作
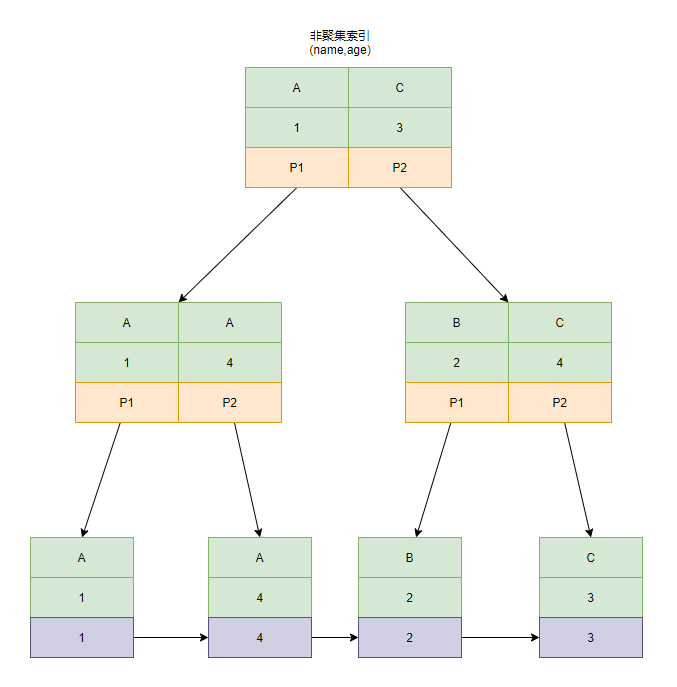
非聚集索引
索引和数据分开放
- 优点:非聚集索引叶子不存储数据,更新起来相对较快
- 缺点:因为叶子节点存储的数据地址,所以查找记录会多一次IO操作
结构图
以表table为例
| id | name | age |
|---|---|---|
| 1 | A | 1 |
| 2 | B | 2 |
| 3 | C | 3 |
| 4 | A | 4 |
聚集索引结构图
非聚集索引结构图

索引下推
mysql提供的索引优化功能,允许存储引擎在进行索引遍历时,根据where条件过滤掉不匹配的数据,从而减少IO次数,以期提高查询效率。
创建索引的建议
可以用来创建索引的字段
- 字段值不能为null
- 频繁查询的字段
- 频繁排序的字段
索引的个数
- 单表索引个数建议不超过5个,索引太多的话增删改也会有很大压力
索引失效场景
- 有组合索引,但是未遵循最左匹配原则
- 在索引字段上进行计算、函数、类型转化
- 模糊匹配时使用
%value,使用value%,是可以走部分索引的 - 查询中使用
OR,但是没有使用索引列,会导致索引失效 - 隐式转换

 浙公网安备 33010602011771号
浙公网安备 33010602011771号