
决策树及其算法
【实验目的】
- 理解决策树算法原理,掌握决策树算法框架;
- 理解决策树学习算法的特征选择、树的生成和树的剪枝;
- 能根据不同的数据类型,选择不同的决策树算法;
- 针对特定应用场景及数据,能应用决策树算法解决实际问题。
【实验内容】
【附录1】
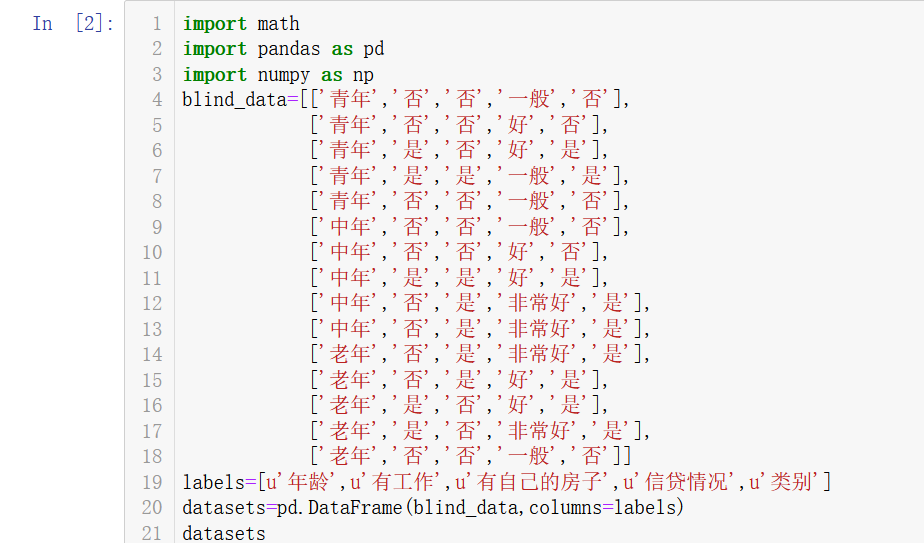
| 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 | |
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
1.针对给定的房贷数据集(数据集表格见附录1)实现ID3算法
#数据导入
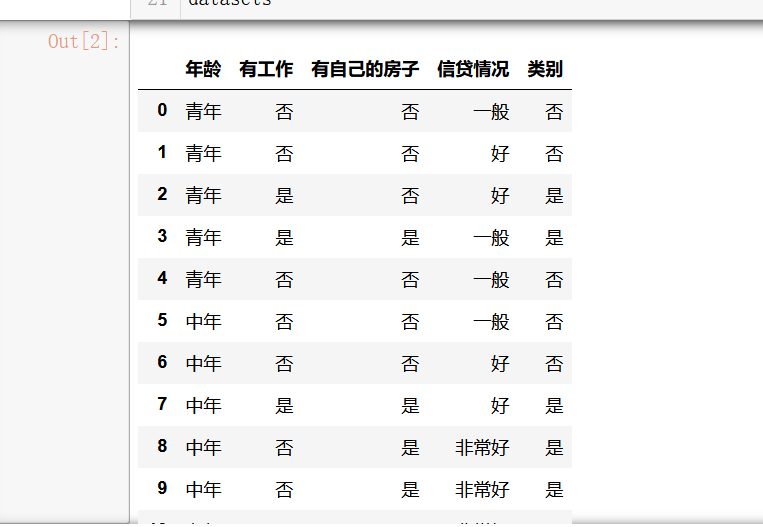
1 import math 2 import pandas as pd 3 import numpy as np 4 blind_data=[['青年','否','否','一般','否'], 5 ['青年','否','否','好','否'], 6 ['青年','是','否','好','是'], 7 ['青年','是','是','一般','是'], 8 ['青年','否','否','一般','否'], 9 ['中年','否','否','一般','否'], 10 ['中年','否','否','好','否'], 11 ['中年','是','是','好','是'], 12 ['中年','否','是','非常好','是'], 13 ['中年','否','是','非常好','是'], 14 ['老年','否','是','非常好','是'], 15 ['老年','否','是','好','是'], 16 ['老年','是','否','好','是'], 17 ['老年','是','否','非常好','是'], 18 ['老年','否','否','一般','否']] 19 labels=[u'年龄',u'有工作',u'有自己的房子',u'信贷情况',u'类别'] 20 datasets=pd.DataFrame(blind_data,columns=labels) 21 datasets
#信息熵
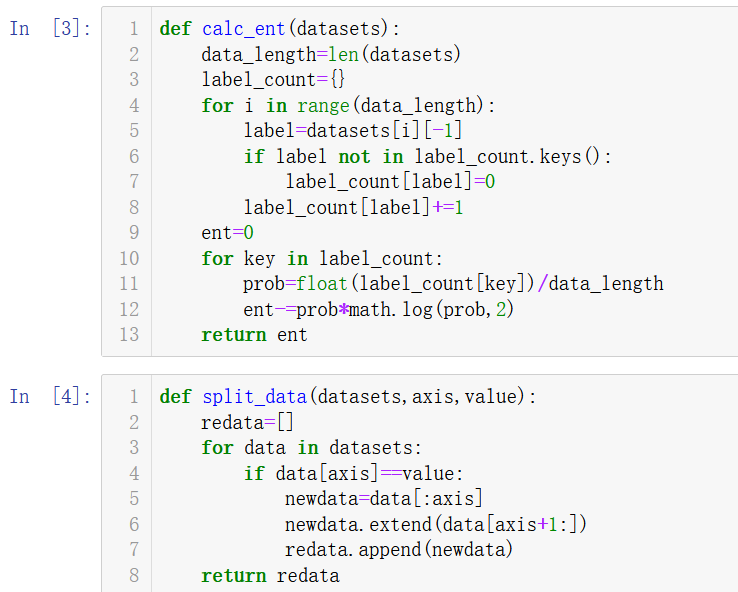
1 def calc_ent(datasets): 2 data_length=len(datasets) 3 label_count={} 4 for i in range(data_length): 5 label=datasets[i][-1] 6 if label not in label_count.keys(): 7 label_count[label]=0 8 label_count[label]+=1 9 ent=0 10 for key in label_count: 11 prob=float(label_count[key])/data_length 12 ent-=prob*math.log(prob,2) 13 return ent
1 def split_data(datasets,axis,value): 2 redata=[] 3 for data in datasets: 4 if data[axis]==value: 5 newdata=data[:axis] 6 newdata.extend(data[axis+1:]) 7 redata.append(newdata) 8 return redata
#信息增益及输出结果
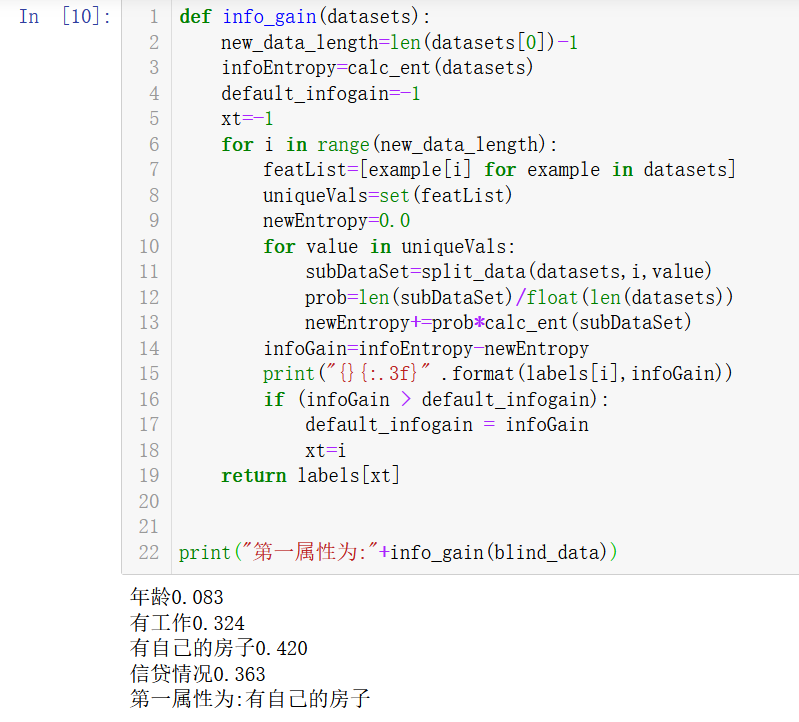
1 def info_gain(datasets): 2 new_data_length=len(datasets[0])-1 3 infoEntropy=calc_ent(datasets) 4 default_infogain=-1 5 xt=-1 6 for i in range(new_data_length): 7 featList=[example[i] for example in datasets] 8 uniqueVals=set(featList) 9 newEntropy=0.0 10 for value in uniqueVals: 11 subDataSet=split_data(datasets,i,value) 12 prob=len(subDataSet)/float(len(datasets)) 13 newEntropy+=prob*calc_ent(subDataSet) 14 infoGain=infoEntropy-newEntropy 15 print("{}{:.3f}" .format(labels[i],infoGain)) 16 if (infoGain > default_infogain): 17 default_infogain = infoGain 18 xt=i 19 return labels[xt] 20 21 22 print("第一属性为:"+info_gain(blind_data))
#ID3算法
ID3算法是从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树,直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。
1 class Node: 2 def __init__(self, root=True, label=None, feature_name=None, feature=None): 3 self.root = root 4 self.label = label 5 self.feature_name = feature_name 6 self.feature = feature 7 self.tree = {} 8 self.result = {'label:': self.label, 'feature': self.feature, 'tree': self.tree} 9 10 def __repr__(self): 11 return '{}'.format(self.result) 12 13 def add_node(self, val, node): 14 self.tree[val] = node 15 16 def predict(self, features): 17 if self.root is True: 18 return self.label 19 return self.tree[features[self.feature]].predict(features) 20 21 class DTree: 22 def __init__(self, epsilon=0.1): 23 self.epsilon = epsilon 24 self._tree = {} 25 26 def calc_ent(datasets): 27 data_length = len(datasets) 28 label_count = {} 29 for i in range(data_length): 30 label = datasets[i][-1] 31 if label not in label_count: 32 label_count[label] = 0 33 label_count[label] += 1 34 ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()]) 35 return ent 36 37 def cond_ent(self, datasets, axis=0): 38 data_length = len(datasets) 39 feature_sets = {} 40 for i in range(data_length): 41 feature = datasets[i][axis] 42 if feature not in feature_sets: 43 feature_sets[feature] = [] 44 feature_sets[feature].append(datasets[i]) 45 cond_ent = sum([(len(p)/data_length)*self.calc_ent(p) for p in feature_sets.values()]) 46 return cond_ent 47 48 def info_gain(ent, cond_ent): 49 return ent - cond_ent 50 51 def info_gain_train(self, datasets): 52 count = len(datasets[0]) - 1 53 ent = self.calc_ent(datasets) 54 best_feature = [] 55 for c in range(count): 56 c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c)) 57 best_feature.append((c, c_info_gain)) 58 59 best_ = max(best_feature, key=lambda x: x[-1]) 60 return best_ 61 62 def train(self, train_data): 63 """ 64 input:数据集D(DataFrame格式),特征集A,阈值eta 65 output:决策树T 66 """ 67 _, y_train, features = train_data.iloc[:, :-1], train_data.iloc[:, -1], train_data.columns[:-1] 68 69 if len(y_train.value_counts()) == 1: 70 return Node(root=True, 71 label=y_train.iloc[0]) 72 73 74 if len(features) == 0: 75 return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0]) 76 77 78 max_feature, max_info_gain = self.info_gain_train(np.array(train_data)) 79 max_feature_name = features[max_feature] 80 81 82 if max_info_gain < self.epsilon: 83 return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0]) 84 85 86 node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature) 87 88 feature_list = train_data[max_feature_name].value_counts().index 89 for f in feature_list: 90 sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1) 91 92 93 sub_tree = self.train(sub_train_df) 94 node_tree.add_node(f, sub_tree) 95 return node_tree 96 97 def fit(self, train_data): 98 self._tree = self.train(train_data) 99 return self._tree 100 101 def predict(self, X_test): 102 return self._tree.predict(X_test) 103 104 datasets, labels = create_data() 105 data_df = pd.DataFrame(datasets, columns=labels) 106 dt = DTree() 107 tree = dt.fit(data_df) 108 109 tree


2.针对iris数据集,应用sklearn的决策树算法进行类别预测。
1 def create_data(): 2 iris = load_iris() 3 df = pd.DataFrame(iris.data, columns=iris.feature_names) 4 df['label'] = iris.target 5 df.columns = [ 6 'sepal length', 'sepal width', 'petal length', 'petal width', 'label' 7 ] 8 data = np.array(df.iloc[:100, [0, 1, -1]]) 9 return data[:, :2], data[:, -1] 10 11 12 X, y = create_data() 13 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.35)
1 from sklearn.tree import DecisionTreeClassifier 2 from sklearn.tree import export_graphviz 3 import graphviz
1 clf = DecisionTreeClassifier() 2 clf.fit(X_train, y_train,)
1 clf.score(X_test, y_test)
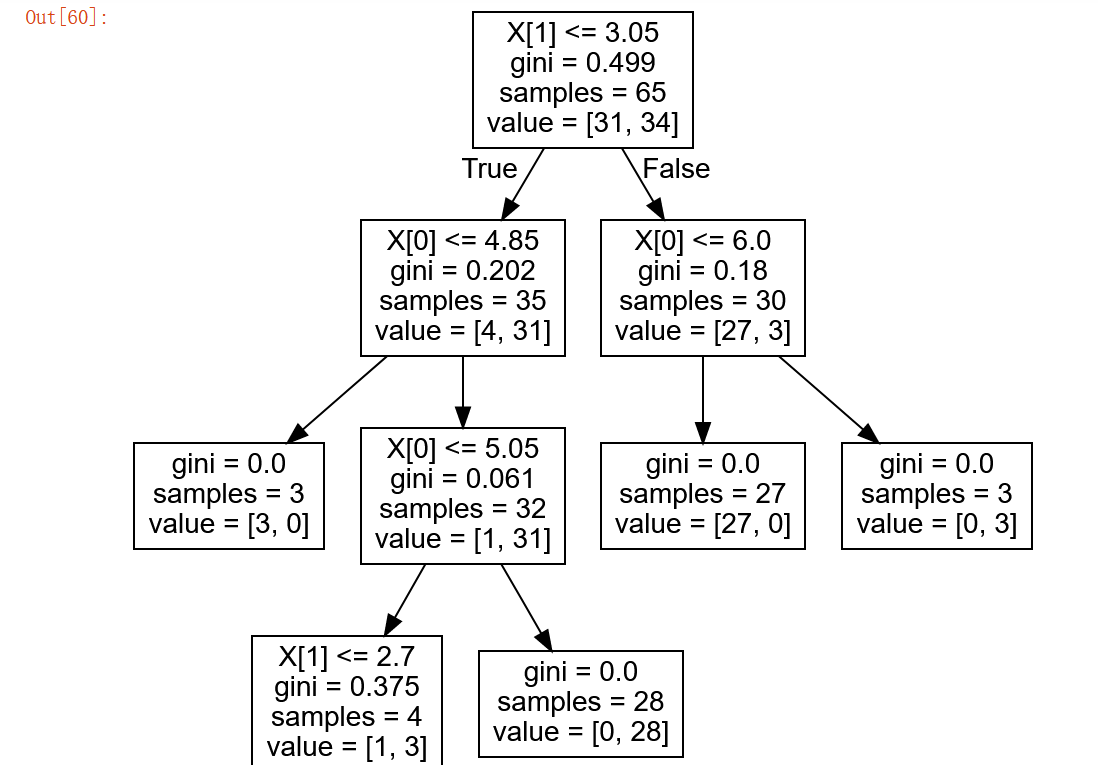
1 tree_pic = export_graphviz(clf, out_file="mytree.pdf") 2 with open('mytree.pdf') as f: 3 dot_graph = f.read() 4 graphviz.Source(dot_graph)
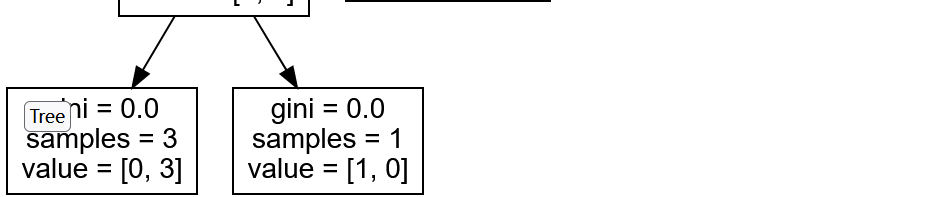
【实验报告】
1、ID3、C4.5的应用场景
#ID3
a、 ID3算法是基于信息增益计算的,信息增益是指划分可以带来纯度的提高,信息熵的下降;
b、信息增益计算:是父亲节点和信息熵减去所以子结点的加权信息熵,这个权重系数为每个子结点在父节点出现的概率,即每个子结点的归一化信息熵;
c、计算公式:在这里插入图片描述
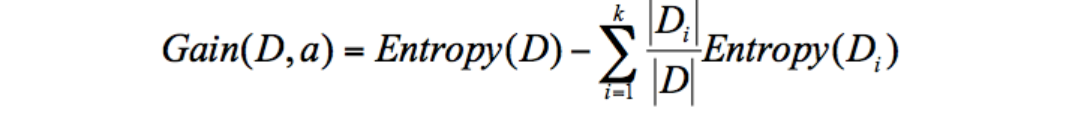
d、计算每个属性的信息增益,选择信息增益最大的作为根节点即可,其他节点选择也类似;
e、 ID3算法的特点
优点:算法简单,可解释性强;
缺点:对噪声敏感,且倾向于选择取值比较多的属性,尽管某些属性可能对分类任务没有太大的作用,但依然被选作最优属性。
#C4.5
a、C4.5算法是ID3算法的改进,具体的,有以下四方面的改进:采用信息增益率而非信息增益,解决了ID3倾向于选择取值多属性的问题。信息增益率=信息增益/属性熵;
采用悲观剪枝(属于后剪枝技术),通过递归估算每个内部节点的分类错误率来判断是否对其进行剪枝,这种剪枝方法不再需要一个单独的测试数据集,解决了ID3构造决策树容易产生过拟合的情况,提升了决策树的泛化能力;
C4.5算法通过选择具有最高信息增益的划分所对应的阈值,可以离散化处理连续属性;
针对数据集不完整情况,即存在缺失值,C4.5可以进行处理,乘以加权系数即可。
b、 C4.5算法的特点:
优点:C4.5算法在ID3算法的基础上,用信息增益率代替了信息增益,解决了噪声敏感的问题;并且可以对构造树进行剪枝、处理连续属性以及数值缺失等情况;
缺点:C4.5算法需要对数据集进行多次扫面,算法效率相对较低。
2、决策树剪枝策略
决策树剪枝的目的去除训练树的过拟合问题,以维持树合理的深度及广度。按照剪枝的时段分可分为预剪枝及后剪枝。预剪枝是在树的生长时提前停止树的生长,后剪枝是在决策树生长完成后根据分枝节点的误差进行剪枝。不管是预剪枝还是后剪枝,在代码实现时,一个关键点是记录下节点的相关信息,包括到达该节点的训练样本数、当该节点作为叶子节点时的判定类别、错误样本数、节点的信息熵等。
3、实验问题
“No modoule graphviz”
出现以上报错,说明我们没有下载和配置graphviz安装包,我用的是Anaconda,所以我一开始的解决方法是进入电脑控制面板,通过指令"pip install graphviz"去安装graphviz包,但是还是不出现我想要的结果。

于是我上网查找了一些前辈的解答,直接在Anaconda中找到了四种graphviz包
我都安装并使用了,最后得到了我想要的结果。
