数据库性能优化3
概述
数据库索引
1,数据库索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息;也就是数据的目录
列存储索引,Sql Server2012的功能,用于提高静态的大规模数据的访问速度
索引的体积影响索引的性能,索引的体积包括列的数据类型,列的量,列的数据的量
优化应该整体优化,而不是针对某一个sql,某一个索引;因为针对某一个sql的优化会产生的影响可能不止于这一条sql
索引的功能:提高查询性能,维护数据的一致性
2,主键:主要用于维护数据的一致性,对于索引的功能没有非聚集索引那么明显;删除索引时,需要将这些用于维护数据一致性的索引排除
注意,主键也可以指定为非聚集索引
3,增删改:会引起索引维护操作,并且数据量的增加,以及可能的导致碎片的增加影响数据库的性能
4,聚集索引和非聚集索引
索引不能独立表而存在,索引是表上的一个对象
聚集索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引
经典比喻:新华字段的拼音检索
SQL server官方聚集索引物理结构图:
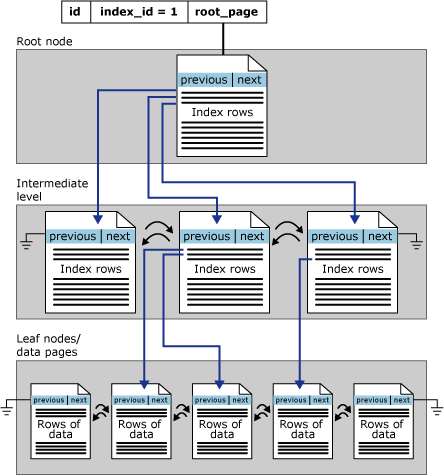
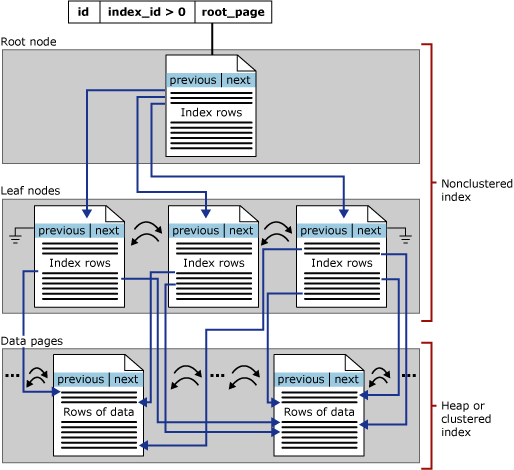
非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索
经典比喻:新华字段的部首检索
SQL server官方非聚集索引物理结构图:
sql server索引分类示例图:
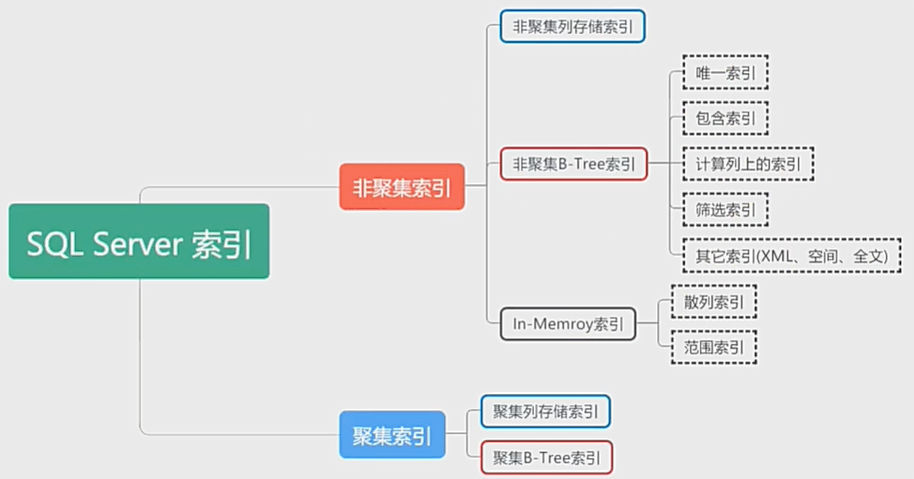
5,堆表和聚集表
堆表:没有聚集索引的表;即使这个表有非聚集索引,这个表的数据也没有顺序;
当存在多个文件组的时候,数据的插入和查询都无法保证顺序;只有order by 可以保证查询的顺序
聚集表:有聚集索引的表,这种表在物理存储上也是无序的;但是聚集索引通过键值将数据页串联起来组织,从而达到有序
所以聚集表的默认查询结果是有顺序的,这个顺序就是聚集索引的健的顺序
6,索引的物理结构
B树索引:也就是行索引
列存储索引:用物理的方式来存储大部分的数据,并自带压缩和解压功能;
从而可以查询大型表总的某些列;列存储索引对于大量不是频繁改动的,尤其是静态资源数据性能提升更有优势
当查询瓶颈是在大范围扫描时可以考虑列存储索引
- 列存储来自同一个域且通常相似的值,从而提高了压缩率。 最大限度地减少或消除系统中的 I/O 瓶颈,并显著降低内存占用量。
- 较高的压缩率通过使用更小的内存中空间提高查询性能。 反过来,由于 SQL Server 可以在内存中执行更多查询和数据操作,因此可以提升查询性能。
- 批处理执行可同时处理多个行,通常可将查询性能提高 2 到 4 倍。
- 查询通常仅从表中选择几列,这减少了从物理介质的总 I/O
列存储用例使用场景:
建议的用例:
-
使用聚集列存储索引来存储数据仓库工作负载的事实数据表和大型维度表。这种方法最多可将查询性能和数据压缩率提高 10 倍
- 使用非聚集列存储索引对 OLTP 工作负载执行实时分析
IAM页:
Index Allocation Map,索引分配映射;可以认为是表的入口;IAM页是用来跟踪表的指定分配单元,在分区的GAM区间中页或区的分配情况
当有一个空表插入了一行数据时增加两页;其中一页是数据页,用来存放用户的数据,另外一页叫做IAM(索引分配映射)页,用来将数据页链接起来;示例如下
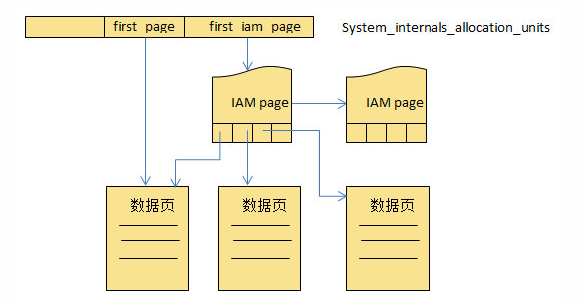
当访问堆表或者索引的时候,会先去访问IAM页,从中找到实际的索引或者数据的位置;从这个根节点(起始点)出发--->中间节点---->叶子节点
对于聚集索引而言;叶子节点存储的是数据本身
对于非聚集索引而言;叶子节点存储的是索引健和指向实际数据页的指针
索引碎片:
外部碎片;指的IAM页与页之间的连续性;在连续性高的情况下;SQL Server一次性可以加载更多数据到内存中
内部碎片:指的是页里面的数据的连续性;碎片会导致数据页和索引页的增多
索引层级:索引根节点到叶子节点的层级,层级越多,查找的开销也就越多
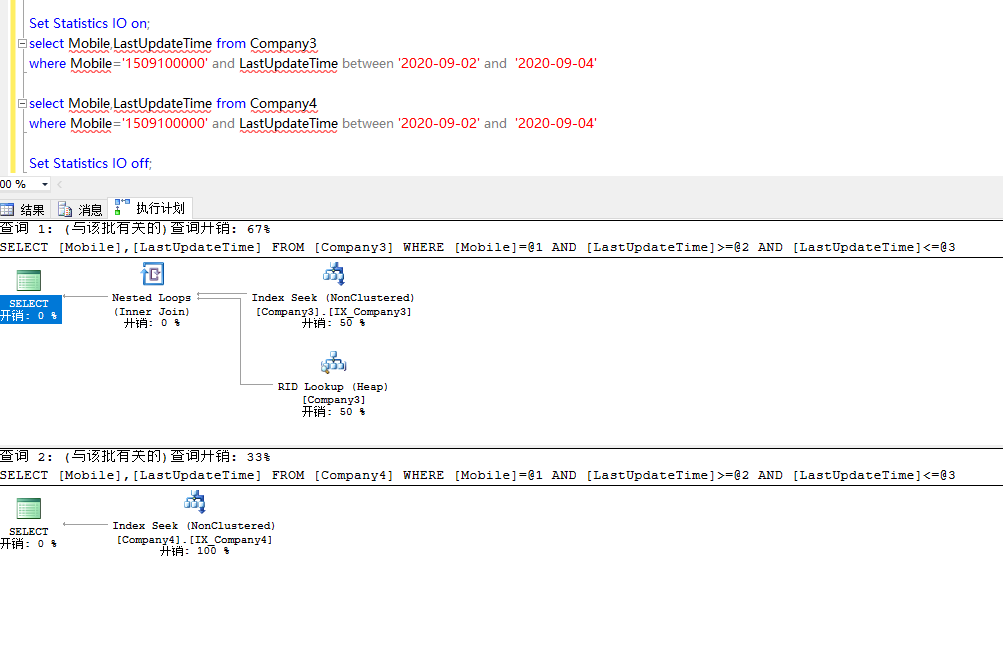
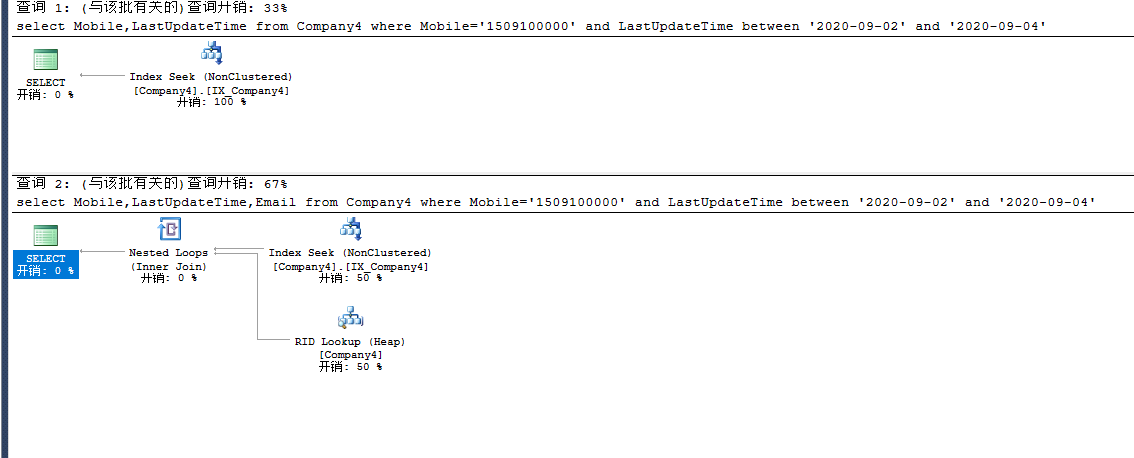
索引的访问方式:扫描(Index Scan),查找(Index Seek),书签查找(RID Lookup,Key Lookup)
索引字段的对索引查找的影响(适用于>,>=,<,<=等范围查找)
示例:UserInfo表,索引名index_non_com;该索引包含A,B,C三个字段
where A='a' and B='b' and C='c' //此语句可以正确使用索引
where A='a' and B='b' //此语句可以正确使用索引
where A='a' and C='c' //此语句可以正确使用索引
where C='c' and A='a' //此语句可以正确使用索引
where C='c' //此语句通常发生的是扫描,不会正确使用索引
where B='b' and C='c'//此语句通常发生的是扫描,不会正确使用索引
这几个示例充分体现了索引的第一列的重要性
书签查找:是由于非聚集索引无法覆盖查找的某个查询中的列导致的
SARG:如何使用高效索引的写法
where条件负号左边出现标量函数:示例 where Upper(UserNo)='A';改写成where (UserNo='A' or UserNo='a')
示例where Age+1=N;改写成where Age=N+1
示例where Left(UserNo,4)='ppp' 改写成where UserNo like 'ppp%'
隐式类型转换也会导致优化器无法选择正确的索引
全表扫描:
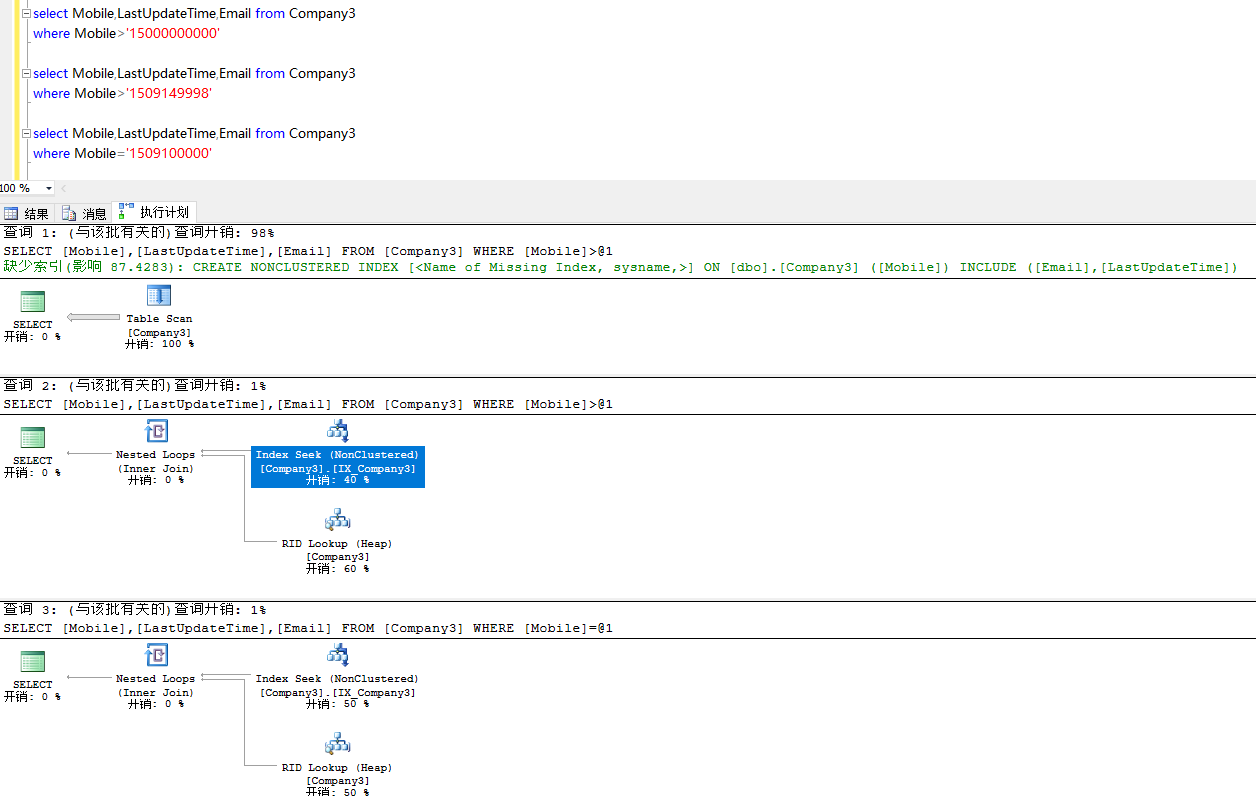
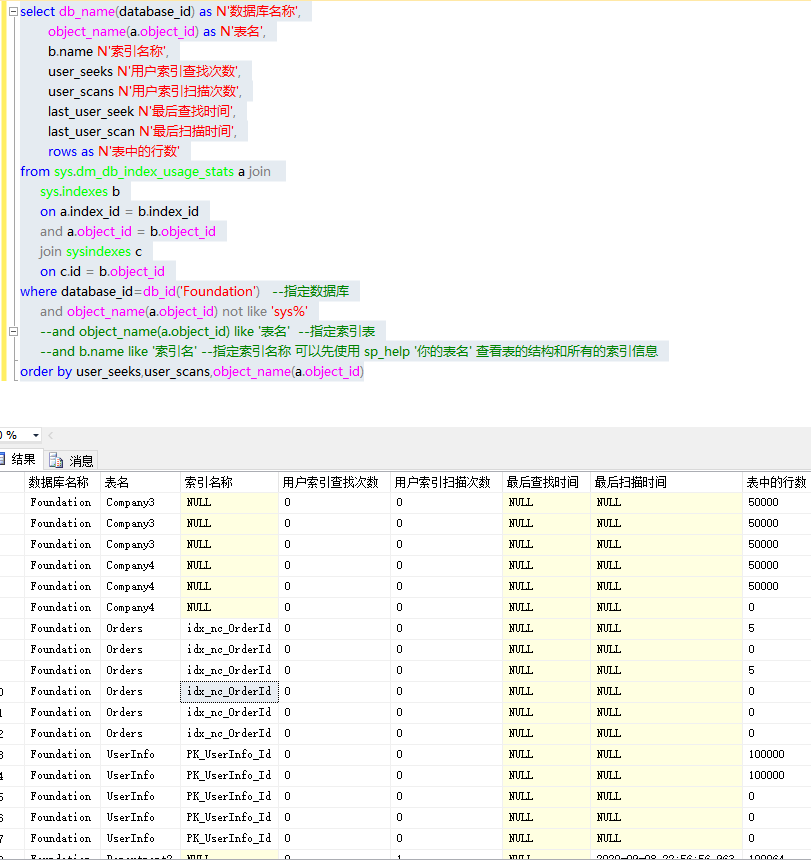
select db_name(database_id) as N'数据库名称',
object_name(a.object_id) as N'表名',
b.name N'索引名称',
user_seeks N'用户索引查找次数',
user_scans N'用户索引扫描次数',
last_user_seek N'最后查找时间',
last_user_scan N'最后扫描时间',
rows as N'表中的行数'
from sys.dm_db_index_usage_stats a join
sys.indexes b
on a.index_id = b.index_id
and a.object_id = b.object_id
join sysindexes c
on c.id = b.object_id
where database_id=db_id('Foundation') --指定数据库
and object_name(a.object_id) not like 'sys%'
--and object_name(a.object_id) like '表名' --指定索引表
--and b.name like '索引名' --指定索引名称 可以先使用 sp_help '你的表名' 查看表的结构和所有的索引信息
order by user_seeks,user_scans,object_name(a.object_id)
查询索引的缺失状况:
在数据分析执行情况的过程中,会记录缺失的索引;我们可以通过sql语句查询数据库缺失的索引状况
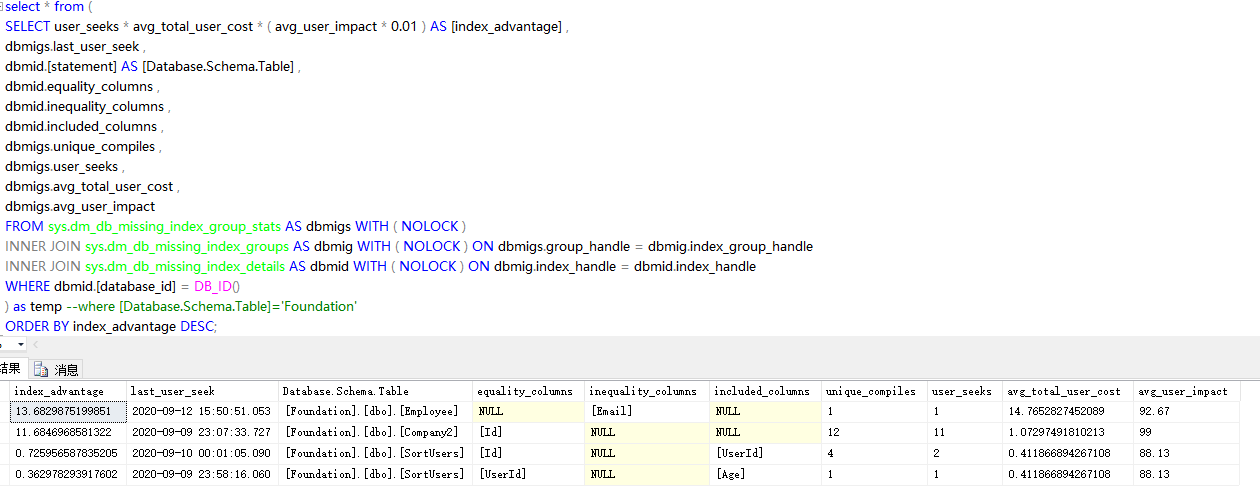
select * from ( SELECT user_seeks * avg_total_user_cost * ( avg_user_impact * 0.01 ) AS [index_advantage] , dbmigs.last_user_seek , dbmid.[statement] AS [Database.Schema.Table] , dbmid.equality_columns , dbmid.inequality_columns , dbmid.included_columns , dbmigs.unique_compiles , dbmigs.user_seeks , dbmigs.avg_total_user_cost , dbmigs.avg_user_impact FROM sys.dm_db_missing_index_group_stats AS dbmigs WITH ( NOLOCK ) INNER JOIN sys.dm_db_missing_index_groups AS dbmig WITH ( NOLOCK ) ON dbmigs.group_handle = dbmig.index_group_handle INNER JOIN sys.dm_db_missing_index_details AS dbmid WITH ( NOLOCK ) ON dbmig.index_handle = dbmid.index_handle WHERE dbmid.[database_id] = DB_ID() ) as temp --where [Database.Schema.Table]='Foundation' ORDER BY index_advantage DESC;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号