一些概念
本文记录一些概念的定义或解释,都是网上 copy 来的,作回顾之用。
Java 相关
CAS 是什么
CAS:compare and swap,比较并替换。CAS 是一种乐观锁,通过在修改数据时,通过和原来的值进行比较,判断是否有被其他人改变。
CAS 算法的过程是这样的,CAS 包括有三个值:
- v 表示要更新的变量
- e 表示预期的值,即 v 的旧值
- n 表示新值
更新时,判断只有 e 的值等于 v 的旧值时,才会将 n 的值赋给 v,更新为新值。否则,则认为已经有其他线程更新过了,则当前线程什么都不操作,最后 CAS 返回变量 v 的真实值。
CAS是一种乐观锁,它抱着乐观的态度认为自己一定可以成功。当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理, CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
CAS 的“ABA”问题
线程 1 准备修改变量 v 的值,当前值为 A, 但是此时线程 2 把 v 的值修改为了 B,然后又修改成了 A,这时候线程 1 进行 CAS 操作发现 v 的值是 A,认为没问题,于是线程 1 操作成功。
尽管线程 1 的 CAS 操作成功,但是不代表这个过程就是没有问题的。
解决办法:通过版本号(version)的方式来解决 ABA 问题。执行修改操作的时候附带版本号,当版本号与数据的版本号一致时才能执行修改并将 version + 1。版本号只增不减,不会出现 ABA 问题。
NoSQL 是什么
NoSQL(Not only SQL)是对不同于传统的关系型数据库的统称,广义地说,所有非关系型数据库都可称为 NoSQL。比如 Redis、MongoDB。
ZooKeeper 是什么
开源的分布式应用协调服务器,其为分布式系统提供一致性服务。其主要功能包括:配置维护、域名服务、分布式同步、集群管理等。ZAB 协议是 Paxos 算法的工业实现算法。
ZooKeeper 的三类角色:
- Leader:事务请求的唯一处理者,也可以处理读请求。
- Follower:可以直接处理客户端的读请求,并向客户端响应;但不会处理事务请求,只会将请求转发给 Leader;对 Leader 发起的事务提案具有表决权;同步 Leader 中事务处理结果;Leader 选举过程的参与者,具有选举权与被选举权。
- Observer:可以理解为不参与 Leader 选举的 Follower,在 Leader 选举过程中没有选举权与被选举权;同时,对于 Leader 的提案没有表决权。用于协助 Follower 处理更多的客户端读请求。Observer 的增加,会提高集群读请求处理的吞吐量,但不会增加事务请求的通过压力,不会增加选举的压力。
微服务组件包括哪些
一个完整的微服务包括的组件:注册中心,配置中心,熔断,限流,链路跟踪,路由
在微服务中,有些组件为必须组件(必须启动存在),客户端才能正常调用
- 必须组件:注册中心,后台服务(Provider)
- 非必须组件:配置中心,熔断,限流,链路跟踪,路由
什么是路由?路由是指根据请求 URL,将请求分配到对应的处理程序,它只是 API 网关的一个功能点。
什么是注册中心
注册中心可以说是微服务架构中的地址簿,它记录了服务和服务地址的映射关系,在分布式架构中,服务会注册到这里,当服务需要调用其他服务时,就在这里找到服务的地址,进行调用。
服务注册与发现
注册中心的功能就是服务注册与发现。
在微服务架构中,一个应用由一组职责单一化的服务组成,各个服务被动态的部署到不同的节点。面对这样一组服务,应该如何去管理服务之间的依赖关系呢?
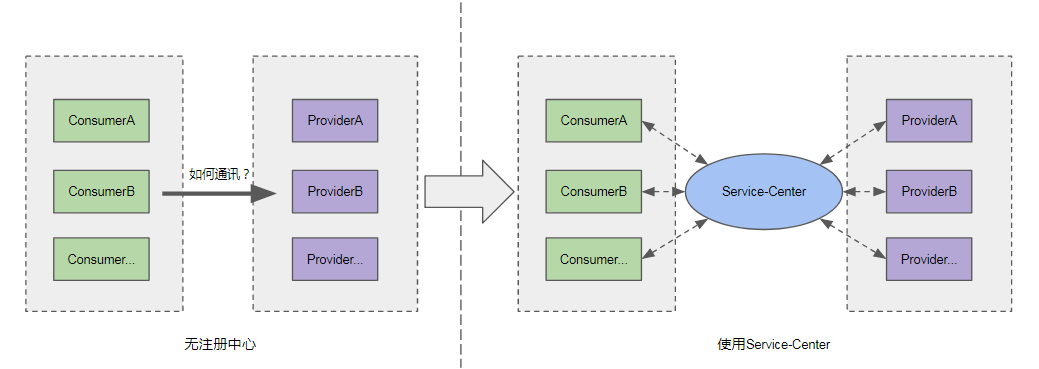
服务注册中心的出现正是为了解决这样的问题,它提供的注册机制,允许服务提供者将自己的信息登记到中心;提供的发现机制,供服务消费者从中心查找服务提供者信息。 服务注册中心有以下几个优点:
- 解耦服务提供者与服务消费者,服务消费者不需要硬编码服务提供者地址;
- 服务动态发现及可伸缩能力,服务提供者实例的动态增减能通过注册中心动态推送到服务消费者端;
- 通过注册中心可以动态的监控服务运行质量及服务依赖,为服务提供服务治理能力。
为什么需要注册中心
服务注册中心给客户端提供可供调用的服务列表,客户端在进行远程服务调用时,根据服务列表然后选择服务提供方的服务地址进行服务调用。服务注册中心在分布式系统中大量应用,是分布式系统中不可或缺的组件。
注册中心是整个服务调用的核心部分,如果服务不存在注册中心,那么通过网关会调用不到,导致失败。
什么是反向代理
理解代理:代理本质上是一个服务器,可以类比为一个中介,A 和 B 本来可以直连,中间插入一个 C,C 就是中介。
- 正向代理:服务端不知道真实的客户端是谁,客户端请求的服务都由代理服务器代替来请求。如通过 VPN 访问谷歌,VPN 就是一个正向代理服务器。
- 反向代理:反向代理是代理服务器将客户端请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给客户端。客户端不感知代理的存在。
反向代理的作用有:
- 提升服务器安全,如保护内网免受 web 攻击
- 实现负载均衡
区别:
两者的区别在于代理的对象不一样:正向代理代理的对象是客户端,反向代理代理的对象是服务端。
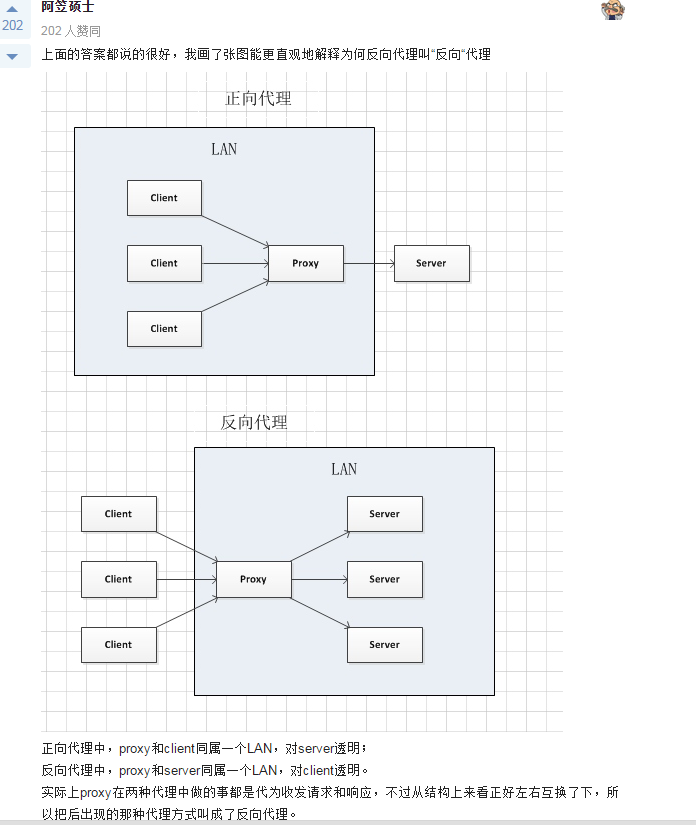
图中提及的 LAN 是 Local Area Network,中文名叫做局域网。
dependencyManagement 和 dependencies 的区别
dependencyManagement即依赖管理。它的作用是申明一些依赖,但不会实际引入这些依赖,真正会引入引入的依赖是 dependencies 中配置的。
dependencyManagement一般是在父工程的 pom.xml 中使用,dependencyManagement 申明当前工程可能会使用到的一些依赖,子模块需要用哪个就在自己的 pom.xml 中添加依赖,不过不需要加版本号了,会继承父工程 dependencyManagement 中申明的版本号。
这么做的目的:
- 在父模块中使用 dependencyManagement 声明依赖能够统一项目内依赖的版本,子模块无须声明版本,避免出现子模块中同一依赖项版本不一致的情况,降低依赖冲突的几率。
- dependencyManagement 申明了依赖,子模块需要什么依赖就自己引入,避免引入一些不必要的依赖。
另外,dependencyManagement 结合 import 标签,可以将目标 pom.xml 中的 dependencyManagement 配置导入合并到当前 pom.xml 的 dependencyManagement 中。
<dependencyManagement>
<dependencies>
<!--导入依赖管理配置-->
<dependency>
<groupId>xxx</groupId>
<artifactId>xxx</artifactId>
<version>1.0</version>
<!--依赖范围为 import-->
<scope>import</scope>
<!--类型一般为pom-->
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
集群与分布式的区别
集群是个物理形态,分布式是个工作方式。
分布式是将一个系统分成不同的服务,部署在不同的服务器,每个节点独立工作,多个节点对外完成系统整体功能。
集群是将一个系统部署到几台服务器上,实现同一业务。集群强调组织性与关联性,多台机器统一管理,最终目的是高可用。
分布式的每一个节点,都可以做集群,而集群并不一定就是分布式的。
这两者是相辅相成的。
Java Web
get、post、put、delete 的区别
- POST(添加):向服务器提交数据。POST 请求将提交的数据包含在请求体中,而 GET 请求将参数包含在 URL 中。因此,POST 请求能提交的数据量比 GET 更大,且相对更安全。
- GET(查询):向指定资源发出请求,请求数据显示在 URL 中。
- DELETE(删除):删除指定的资源。
- PUT(修改):向服务器更新指定资源。
@RequestBody 和 @RequestParam 的区别
@RequestParam:表示请求参数的键值对,传参形式:{url}?param=xxx@RequestBody:常用于 json 格式的请求体。
RESTful 是什么
一个叫 Fielding 的人将他对互联网软件的架构原则,定名为 REST,全称 Representational State Transfer,翻译为“表现层状态转移”。如果一个架构符合 REST 原则,就称它为 RESTful 架构。
“表现层状态转移”中的"表现层"其实指的是"资源"(Resources)的"表现层"。所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片。每种资源对应一个特定的 URI(统一资源定位符)。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
我们总结一下什么是 RESTful 架构:
- 每一个 URI 代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;
- 客户端通过四个 HTTP 动词(GET、POST、PUT、DELETE),对服务器端资源进行操作,实现"表现层状态转化"。
设计 RESTful API
在 RESTful 架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以 API 中的名词也应该使用复数。
对于资源的具体操作类型,由HTTP动词表示。比如:
- GET /zoos:列出所有动物园
- POST /zoos:新建一个动物园
- GET /zoos/ID:获取某个指定动物园的信息
- PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE /zoos/ID:删除某个动物园
- GET /zoos/ID/animals:列出某个指定动物园的所有动物
- DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
MySQL
聚集索引是什么
聚集索引就是存放的物理顺序和列中的顺序一样。一般主键索引就是聚集索引。非聚集索引就是普通索引,非聚集索引只是是逻辑上连续。
聚集索引和非聚集索引的区别:
- 聚集索引可以一次查到数据, 而非聚集索引是先查到记录对应的主键, 再使用主键的聚集索引查到数据。
- 一张表中聚集索引只能有一个,非聚集索引可以有多个。
回表查询
在InnoDB中,二级索引叶子节点存储的不是记录的指针,而是主键的值。所以,对于二级索引的查询,会查两颗B+树,先在二级索引定位主键,再去主键索引的B+树上找到最终记录。由于主键索引构建的B+树其叶子节点存放的是所有的数据行,即整张表的数据,所以称之为回表查询。
MySQL 中数据类型的位数有什么用

1、常用的整数类型如tinyint,int,bigint,它们本身根据自己的数据类型就限定了取值范围,跟位数没关系。比如tinyint,默认有符号范围是 -128 到 127。无符号范围是 0 到 255。int和bigint能存储的数值范围就更大了。
位数叫做 zerofill,翻译过来是"填零",用于显示的位数。比如 int(5),如果勾选了"填零"这个选项。存入 整数 100,则展示 00100,位数不足前面补 0,超过 5 位正常显示。
2、字符串类型的字段,比如varchar(225),这里括号里的大小就代表能存储的字符个数,varchar(225)这个字段就最多能存储 225 个字符,注意是字符,中文也能存 225 个。
3、带小数的一般用decimal,比如decimal(5,2),5 代表整个数值的总位数,2 代表小数点个数。比如该字段能存 100.12,不能存 1000.12。
MySQL 索引的原理
MySQL 中,表数据是按照 B+ 树组织的一个数据结构,这个数据结构就是 MySQL 中的索引。
MySQL 中的索引有两种:主键索引和非主键索引。
一、主键索引
InnoDB 会为每一个表自动创建一个主键索引,也就是一棵 B+ 树。
如果一张表没有建主键,InnoDB 会优先选唯一键(Unique)作为主键,如果连唯一键也没有,InnoDB 会为每一条表记录添加一个叫做DB_ROW_ID的列作为默认主键,只不过这个主键我们看不到。所以对于 InnoDB 而言,主键索引一定存在的。
那主键索引,也就是 B+ 树的结构是怎样的呢?
InnoDB 将数据划分为若干个“页”,以页作为磁盘与内存交互的最小单位,每个页默认大小为16 KB。在一个页中,表数据是按照主键,由小到大串联起来的单项链表。
主键索引又叫聚簇索引,主键索引的特点:
- 按照主键大小和数据页对数据排序,数据用单向链表链接,数据页之间用双向链表链接。
- B+ 树的非叶子节点不保存数据,只保存关键字,这些关键字是其子树的最大(或最小)关键字。
- B+ 树的叶子节点保存了表的完整记录。
二、普通索引和联合索引
为主键之外的单个列添加的索引叫普通索引。普通索引也是一棵 B+ 树,它跟主键索引的区别在于:
- 它的叶子节点不再存储完整数据,而是只记录该索引列的值和它的主键值。
- 它的内部节点也是按照索引列来排序,不是按照主键排序。
我们根据索引列查询时,定位到叶子节点后,就可以拿到主键值,再根据主键值从主键索引中查找我们想要的数据。这个过程叫回表。可想而知,如果该索引列由很多重复的值,那么会发生多次回表操作,可见索引列的散列程度应该较高才可以。
理解了普通索引,再看联合索引就很简单了。联合索引就是给多个列建立索引,比如给 A、B 两列建立联合索引,那么它的叶子节点就存储的是 A 列、B 列和主键值。数据的排序方式是先按 A 列排序, A 列值相同再按照 B 列排序。这就解释了,在使用联合索引的时候为什么要遵循“最左匹配”原则。因为 B 列的值存储是乱序的,如果用 B 列查询,索引起不到作用。
和普通索引一样,联合索引的查询也是先通过关键字定位索引数据,再获得主键值,去查询主键索引中查。它也存在回表操作,如果只是查询联合索引其中一列的数据,就不用回表。如select B from t where A = 'xxx'。
其他
敏捷开发与DevOps的区别
敏捷开发的核心是迭代开发。
"增量开发",指的是软件的每个版本,都会新增一个用户可以感知的完整功能。也就是说,按照新增功能来划分迭代。
增量开发加上迭代开发,才算真正的敏捷开发。
DevOps 是开发 (Dev) 和运营 (Ops) 的复合词,它将人、流程和技术结合起来,不断地为客户提供价值。
DevOps 强调软件产品交付过程中 IT 工具链的打通,同时使孤立的角色(开发、IT 运营、质量工程和安全)可以协调和协作,使得各个团队减少时间损耗,更加高效地协同工作。从而有 CI/CD 的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号