摘要:
使用代理防止大量爬取时被封ip 原理 普通访问b站 使用代理,d为代理ip 示例 # 原理. 通过第三方的一个机器去发送请求 import requests # 218.60.8.83:3129 proxies = { "https": "https://218.60.8.83:3129" } re 阅读全文
posted @ 2024-12-19 22:30
一只大学生
阅读(21)
评论(0)
推荐(0)
摘要:
防盗链: 溯源, 当前本次请求的上一级是谁 案例 抓取梨视频 # 1. 拿到contId # 2. 拿到videoStatus返回的json. -> srcURL # 3. srcURL里面的内容进行修整 # 4. 下载视频 import requests # 拉取视频的网址 url = "http 阅读全文
posted @ 2024-12-19 22:16
一只大学生
阅读(21)
评论(0)
推荐(0)
摘要:
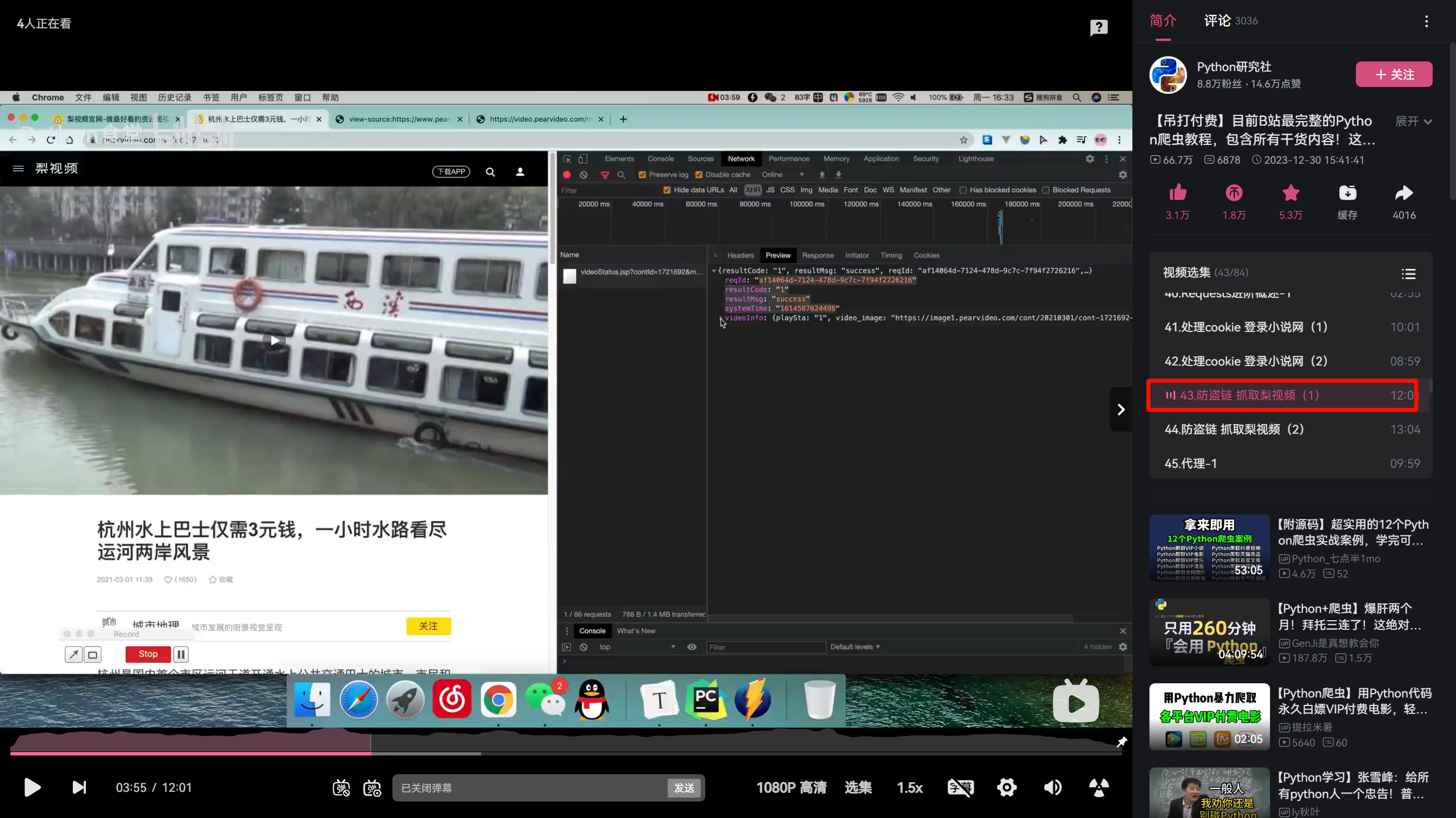 阅读全文
posted @ 2024-12-19 21:59
一只大学生
阅读(11)
评论(0)
推荐(0)
摘要:
Cookie存储在用户的浏览器中 Token 一般携带在url后面或headers中,有签名加密,安全性相对更高 案例 爬取书架上内容 # 登录 -> 得到cookie # 带着cookie 去请求到书架url -> 书架上的内容 # 必须得把上面的两个操作连起来 # 我们可以使用session进行 阅读全文
posted @ 2024-12-19 21:49
一只大学生
阅读(39)
评论(0)
推荐(0)
摘要:
用爬虫下载图片,当下载大量图片时可能会感觉卡,这是因为pycharm给每个文件都加了索引以便快速查找。想要防止卡顿,可以将图片目录转化为已排除(红色文件夹)。 具体操作 阅读全文
posted @ 2024-12-19 11:17
一只大学生
阅读(34)
评论(0)
推荐(0)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号