


详细介绍:【AI论文】Seedream 4.0:迈向下一代多模态图像生成
摘要:大家推出Seedream 4.0,这是一款高效且高性能的多模态图像生成系统,它在一个统一的框架内集成了文本到图像(Text-to-Image,T2I)合成、图像编辑和多图像组合功能。我们开发了一种高度高效的扩散变换器,并搭配强大的变分自编码器(Variational Auto-Encoder,VAE),该自编码器还能大幅减少图像标记(token)的数量。这使得我们的模型能够高效训练,并能快速生成原生高分辨率图像(例如,1K-4K分辨率)。Seedream 4.0在涵盖多种分类和以知识为中心的概念的数十亿文本-图像对上进行了预训练。利用在数百个垂直场景中全面收集数据,并结合优化策略,确保了大规模训练的稳定性和强大的泛化能力。通过引入精心微调的视觉语言模型(Vision Language Model,VLM),我们对文本到图像生成和图像编辑任务进行了联合多模态后训练。为了加速推理,我们集成了对抗蒸馏、分布匹配和量化,以及推测解码技巧。在无需大语言模型/视觉语言模型作为提示工程(Prompt Engineering,PE)模型的情况下,生成一张2K分辨率图像的推理时间最快可达1.8秒。全面的评估表明,Seedream 4.0在文本到图像生成和多模态图像编辑方面均能达到最先进的水平。特别是,它在复杂任务中展现出卓越的多模态能力,包括精确的图像编辑和上下文推理,还承受多图像参考,并能生成多个输出图像。这将传统的文本到图像生成系统扩展为一个更具交互性和多维度的创意工具,推动了生成式人工智能在创意和专业应用领域的边界拓展。现在,您许可在volcengine上体验Seedream。Huggingface链接:Paper page,论文链接:2509.20427
研究背景和目的
研究背景:
随着生成式人工智能(Generative AI)的高效发展,多模态图像生成科技成为当前研究的热点。
传统的图像生成模型,如Stable Diffusion、FLUX系列和GPT-4o等,虽然在图像质量和多样性上取得了显著进展,但在处理高分辨率图像、复杂任务(如精确图像编辑和上下文推理)时,仍面临效率和可控性方面的挑战。具体而言,这些模型通常需要大量的计算资源进行训练和推理,且在生成高分辨率图像时速度较慢,难以满足实时应用的需求。此外,它们在处理多模态输入(如文本和图像的组合)时,也表现出一定的局限性,特有是在多图像参考和输出方面。
研究目的:
本研究旨在提出一种高效且高性能的多模态图像生成体系——Seedream 4.0,以解决现有模型在处理高分辨率图像、繁琐任务和多模态输入时的局限性。
具体目标包括:
- 提升图像生成效率:经过开发高效的扩散变换器(Diffusion Transformer, DiT)架构和高压缩比的变分自编码器(Variational Autoencoder, VAE),显著降低模型训练和推理的计算复杂度,实现快速的高分辨率图像生成。
- 增强多模态生成能力:通过联合训练文本到图像(T2I)生成和图像编辑任务,使模型能够处理单图像和多图像的输入和输出,支持复杂的创意和实际应用场景。
- 建立专业级内容生成:扩展模型在结构化、专业和知识密集型内容生成方面的能力,如生成图表、公式和设计素材,缩小创意生成与实际应用之间的差距。
- 优化推理速度:通过集成对抗蒸馏、分布匹配和量化等技术,搭建超快的推理速度,提升用户体验和生产效率。
研究方法
1. 模型架构设计:
Seedream 4.0采用了高效的扩散变换器(DiT)作为主干网络,结合高压缩比的变分自编码器(VAE),显著降低了图像令牌(tokens)的数量,从而提高了训练和推理效率。
具体而言,DiT架构通过增加模型容量同时减少计算量,而VAE则通过压缩图像数据来减少潜在空间中的令牌数量。
2. 多阶段训练策略:
为了充分发挥模型架构的潜力,研究采用了多阶段训练策略,包括持续训练(CT)、监督微调(SFT)和基于人类反馈的强化学习(RLHF)。
CT阶段用于扩展模型的基础知识和多任务能力,SFT阶段则用于培养特定的艺术品质,RLHF阶段则通过微调使模型的输出与人类偏好保持一致。
3. 联合后训练:
研究通过联合后训练T2I生成和图像编辑任务,增强了模型的多模态生成能力。
这一过程借助因果扩散设计实现,使得模型能够同时处理文本和图像输入,生成符合要求的图像输出。
4. 推理加速技术:
为了实现超快的推理速度,研究集成了对抗蒸馏、分布匹配和量化等技能。
对抗蒸馏通过引入对抗学习框架来稳定初始化过程,分布匹配则通过可学习的扩散判别器构建更精细的分布匹配,量化技巧则通过减少计算精度来提高推理速度。
研究结果
1. 综合性能提升:
Seedream 4.0在T2I生成和图像编辑任务上均取得了显著的性能提升。
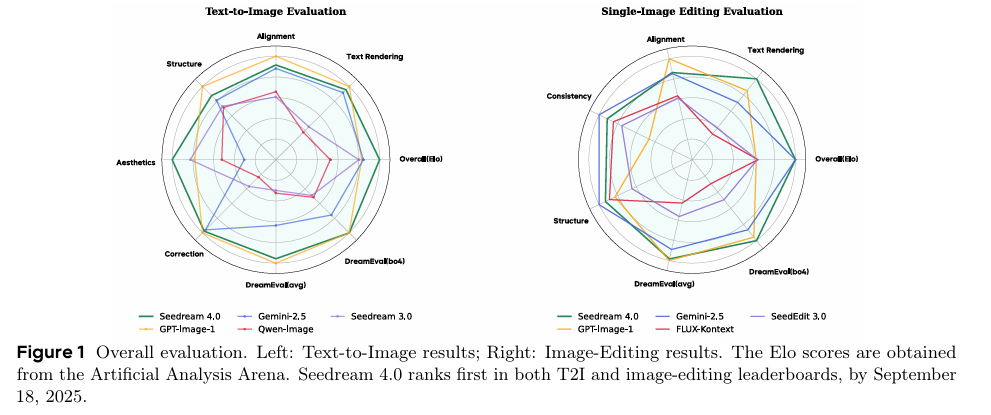
在公共平台Artificial Analysis Arena的评估中,Seedream 4.0在T2I生成和图像编辑排行榜上均排名第一,显著优于其他领先模型,如GPT-Image-1和Gemini-2.5Flash Image。
2. 细粒度评估:
通过MagicBench4.0基准测试,研究对Seedream 4.0在T2I生成、单图像编辑和多图像编辑任务上的表现进行了细粒度评估。
结果显示,Seedream 4.0在所有评估维度上均表现出色,特别是在视觉美观性、指令遵循和一致性方面显著优于竞争对手。
3. 多模态生成能力:
Seedream 4.0展示了强大的多模态生成能力,能够处理单图像和多图像的输入和输出。
在多图像编辑任务中,Seedream 4.0能够理解不同输入图像之间的上下文关系,生成结构完整且一致性高的输出图像。
4. 专业场景应用:
除了艺术图像生成外,Seedream 4.0还展示了在专业场景下的强大能力,如生成图表、公式和设计素材等。
这一能力使得Seedream 4.0在实际应用中具有更广泛的适用性。
5. 推理速度优化:
通过集成多种推理加速技术,Seedream 4.0实现了极快的推理速度。
在生成2K分辨率图像时,Seedream 4.0的推理时间可缩短至1.4秒,显著优于现有模型。
研究局限
1. 数据多样性限制:
尽管研究在数据收集方面进行了优化,但仍存在某些知识密集型概念(如指令性内容和数学表达式)代表性不足的问题。
这可能导致模型在处理这些特定类型的任务时表现不佳。
2. 模型复杂度与效率权衡:
虽然Seedream 4.0在模型架构和推理加速方面进行了优化,但随着模型复杂度的增加,训练和推理过程中的计算资源需求也相应增加。
如何在保持高性能的同时进一步降低计算复杂度,是未来研究需要解决的问题。
3. 多模态理解的深度:
尽管Seedream 4.0在多模态生成方面取得了显著进展,但在处理艰难上下文和深度多模态理解任务时,仍存在一定的局限性。
例如,在需要高级上下文推理或专业领域知识的任务中,模型的表现可能仍有提升空间。
未来研究方向
1. 扩展数据多样性:
未来研究可以进一步扩展数据集,增加对知识密集型概念的覆盖,以提高模型在处理这些任务时的性能和泛化能力。
同时,可以探索数据增强和合成数据生成技术,以缓解资料稀缺问题。
2. 优化模型架构与训练策略:
针对模型复杂度和计算资源需求的疑问,未来研究允许探索更高效的模型架构和训练策略。
例如,采用模型剪枝、量化和知识蒸馏等工艺降低模型复杂度,同时保持高性能。此外,可以研究更先进的优化算法和分布式训练方法,以支持更大规模模型的训练。
3. 提升多模态理解能力:
为了增强模型在处理复杂上下文和深度多模态理解任务时的能力,未来研究能够探索更先进的多模态融合技术和上下文建模方法。
例如,结合Transformer架构和图神经网络(GNN)等技能,提升模型对多模态资料的理解和推理能力。
4. 探索新的应用场景:
通过除了艺术图像生成外,未来研究还能够探索Seedream 4.0在其他领域的应用潜力,如医学影像生成、遥感图像处理、虚拟现实和增强现实等。通过针对不同应用场景进行定制化创建和优化,进一步拓展Seedream 4.0的应用范围。
5. 加强模型可解释性与可信度:
随着生成式AI在关键领域(如医疗、金融等)的应用日益广泛,模型的可解释性和可信度成为重要考量因素。
未来研究可以探索如何提升Seedream 4.0的可解释性,例如通过可视化技术、注意力机制分析等方法揭示模型的决策过程。同时,允许研究模型的不确定性估计方法,量化模型预测的可信度,为实际应用献出更加可靠的依据。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号