
第一题:多线程爬取图片
核心代码与运行结果:
点击查看代码
import re
import requests
import html
import os
import threading
import time
from queue import Queue
from urllib.parse import urljoin, urlparse
import urllib.parse
keyword = "书包"
max_pages = 35
max_images = 135
thread_num = 5
keyword_encoded = urllib.parse.quote(keyword)
base_url = "https://search.dangdang.com/"
image_dir = f"images_{keyword}"
page_queue = Queue()
image_queue = Queue()
products = []
downloaded_images = []
lock = threading.Lock()
stop_flag = False
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def create_dir():
if not os.path.exists(image_dir):
os.makedirs(image_dir)
print(f"创建目录: {image_dir}")
def build_urls():
for page in range(1, max_pages + 1):
if page == 1:
url = f"https://search.dangdang.com/?key={keyword_encoded}&category_id=10009684#J_tab"
else:
url = f"https://search.dangdang.com/?key={keyword_encoded}&category_id=10009684&page_index={page}#J_tab"
page_queue.put(url)
def crawl_page(url):
global stop_flag
if stop_flag:
return
try:
resp = requests.get(url, headers=headers, timeout=10)
resp.encoding = "gbk"
html_text = resp.text
ul = r'<ul[^>]*id="component_59"[^>]*>(.*?)</ul>'
ul_match = re.search(ul, html_text, re.S)
if not ul_match:
return
ul_note = ul_match.group(1)
li_ = r'<li[^>]*ddt-pit="\d+"[^>]*id="\d+"[^>]*>(.*?)</li>'
li_list = re.findall(li_, ul_note, re.S)
for li_each in li_list:
with lock:
if len(downloaded_images) >= max_images:
stop_flag = True
return
#名称
name_match = re.search(r'<a[^>]*title="([^"]*)"[^>]*name="itemlist-title"', li_each, re.S)
name = name_match.group(1).strip() if name_match else ""
#价格
price_match = re.search(r'<span class="price_n">\s*(.*?)\s*</span>', li_each, re.S)
price = html.unescape(price_match.group(1).strip()) if price_match else ""
# 提取URL
img_match = re.search(r'<img[^>]*data-original=([\'"])([^\'"]*)\1', li_each, re.S)
if not img_match:
img_match = re.search(r'<img[^>]*src=([\'"])([^\'"]*)\1', li_each, re.S)
img_url = img_match.group(2).strip() if img_match else ""
if all([name, price, img_url]):
with lock:
if len(downloaded_images) >= max_images:
stop_flag = True
return
products.append({'name': name, 'price': price, 'img_url': img_url})
image_queue.put({'name': name, 'price': price, 'img_url': img_url})
except Exception as e:
print(f"[页面错误] {e}")
def download_image(product):
global stop_flag
if len(downloaded_images) >= max_images:
return
try:
img_url = product['img_url']
if img_url.startswith('//'):
img_url = 'https:' + img_url
elif img_url.startswith('/'):
img_url = urljoin(base_url, img_url)
safe_name = re.sub(r'[^\w\-_.]', '_', product['name'][:20])
ext = os.path.splitext(urlparse(img_url).path)[1] or '.jpg'
filename = f"{safe_name}{ext}"
filepath = os.path.join(image_dir, filename)
resp = requests.get(img_url, headers=headers, timeout=10)
if resp.status_code == 200:
with open(filepath, 'wb') as f:
f.write(resp.content)
with lock:
downloaded_images.append(img_url)
print(f"[下载成功] {img_url}")
if len(downloaded_images) >= max_images:
stop_flag = True
else:
print(f"[下载失败] {img_url} 状态码: {resp.status_code}")
except Exception as e:
print(f"[图片错误] {product['name'][:10]}... | {e}")
def page_worker():
while not stop_flag and not page_queue.empty():
try:
url = page_queue.get(timeout=1)
crawl_page(url)
page_queue.task_done()
except:
break
def image_worker():
while not stop_flag:
try:
product = image_queue.get(timeout=1)
download_image(product)
image_queue.task_done()
except:
break
if __name__ == "__main__":
print(f"=== 开始爬取「{keyword}」===")
print(f"{max_pages} 页, {max_images} 张 \n")
create_dir()
build_urls()
print("选择模式:1=单线程 2=多线程")
mode = input("请输入 1 或 2:").strip()
start_time = time.time()
if mode == "1":
print("\n=== 单线程模式 ===")
while not page_queue.empty():
crawl_page(page_queue.get())
page_queue.task_done()
while not image_queue.empty():
download_image(image_queue.get())
image_queue.task_done()
else:
print("\n=== 多线程模式 ===")
page_threads = []
for _ in range(thread_num):
t = threading.Thread(target=page_worker)
t.start()
page_threads.append(t)
for t in page_threads:
t.join()
image_threads = []
for _ in range(thread_num):
t = threading.Thread(target=image_worker)
t.start()
image_threads.append(t)
for t in image_threads:
t.join()
end_time = time.time()
print(f"\n共下载图片:{len(downloaded_images)} 张")
print(f"保存目录:{os.path.abspath(image_dir)}")
print(f"耗时:{end_time - start_time:.2f} 秒")
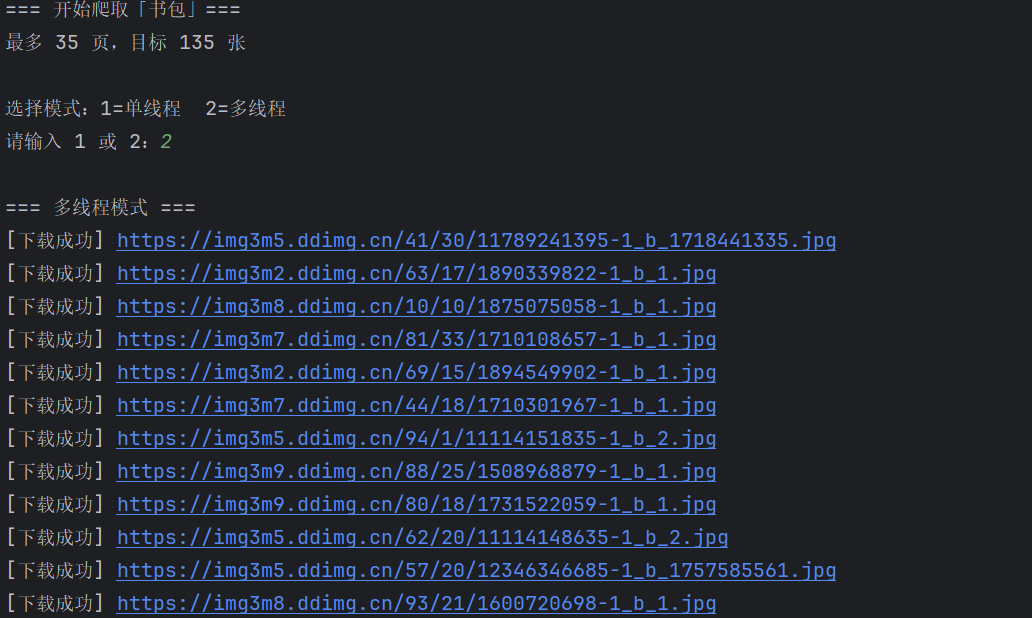
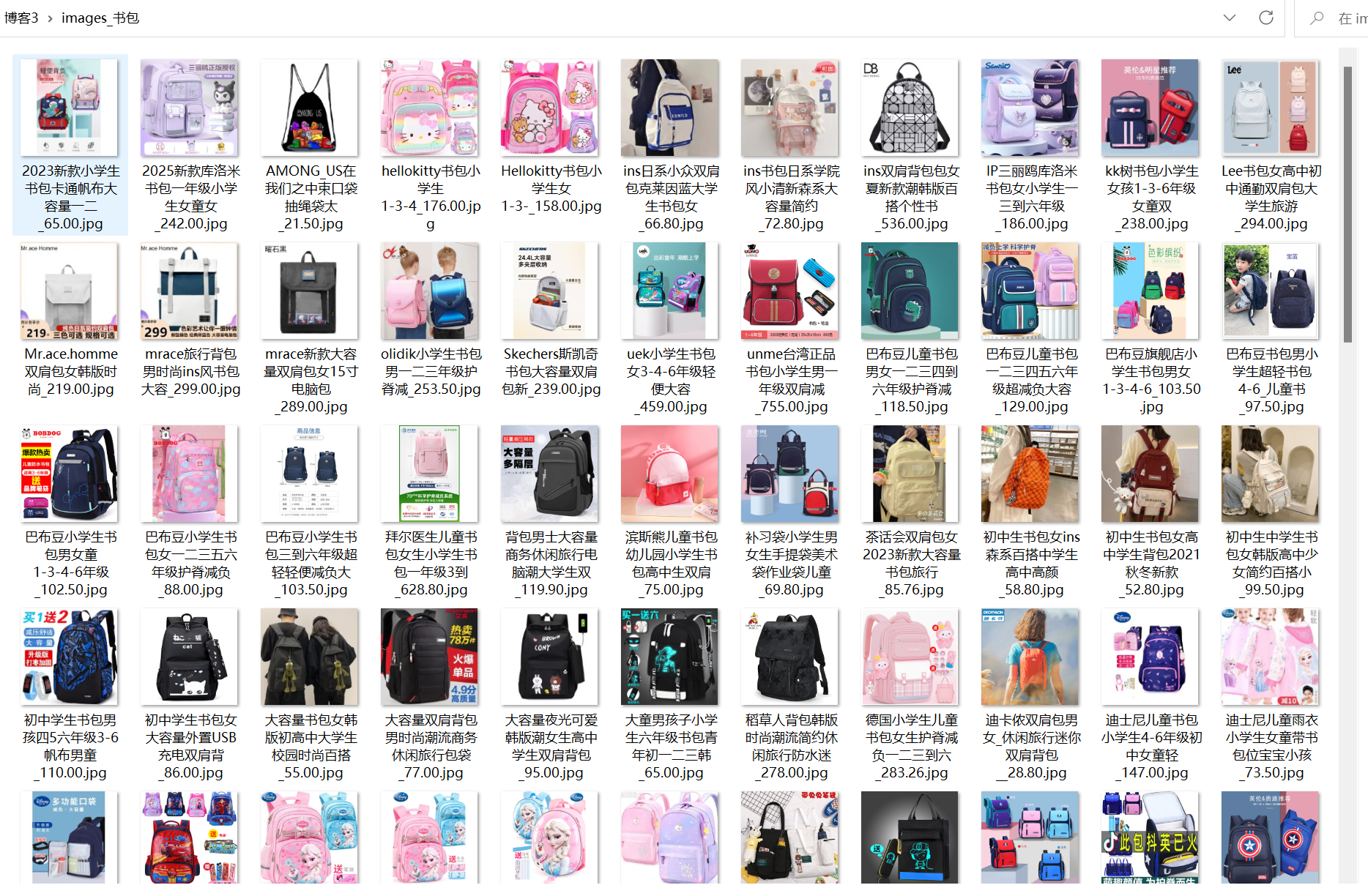
心得体会:
多线程部分遇到过队列阻塞、线程提前退出的问题,通过加锁和 stop_flag 才保证下载数量不会超限。整体下来虽然绕了一些弯路,但对网页结构分析、正则提取和多线程队列同步都更熟练了
第二题:scrapy爬取股票
核心代码与运行结果:
piplines
import pymysql
from pymysql.err import IntegrityError, OperationalError
from datetime import datetime
class StockScrapyPipeline:
def __init__(self):
self.db_config = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'charset': 'utf8mb4'
}
self.conn = None
self.cursor = None
self.database_name = 'stocks'
self.connect_and_create_db()
self.create_table()
#连接MySQL
def connect_and_create_db(self):
try:
self.conn = pymysql.connect(
**self.db_config,
database=None
)
self.cursor = self.conn.cursor()
# 创建数据库
create_db_sql = f"CREATE DATABASE IF NOT EXISTS {self.database_name} DEFAULT CHARACTER SET utf8mb4;"
self.cursor.execute(create_db_sql)
self.conn.commit()
print(f"数据库「{self.database_name}」创建成功")
self.cursor.execute(f"USE {self.database_name};")
print(f"已切换到数据库「{self.database_name}」")
except OperationalError as e:
error_msg = str(e)
if 'Access denied' in error_msg:
print(f"MySQL连接失败")
elif 'Can\'t connect' in error_msg:
print(f"MySQL连接失败")
else:
print(f"MySQL连接失败")
raise
# 自动创建数据表)
def create_table(self):
sql = """
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20) NOT NULL,
stock_name VARCHAR(50) NOT NULL,
current_price FLOAT,
change_percent FLOAT,
change_amount FLOAT,
volume FLOAT,
turnover FLOAT,
amplitude FLOAT,
high_price FLOAT,
low_price FLOAT,
open_price FLOAT,
close_price FLOAT,
plate_name VARCHAR(50),
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(stock_code, crawl_time) # 去重:同一股票同一时间不重复
)
"""
self.cursor.execute(sql)
self.conn.commit()
print(f"数据表「stocks」创建成功")
# 存储爬取的数据
def process_item(self, item, spider):
sql = """
INSERT INTO stocks
(stock_code, stock_name, current_price, change_percent, change_amount,
volume, turnover, amplitude, high_price, low_price, open_price, close_price, plate_name, crawl_time)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
values = (
item['stock_code'], item['stock_name'], item['current_price'],
item['change_percent'], item['change_amount'], item['volume'],
item['turnover'], item['amplitude'], item['high_price'],
item['low_price'], item['open_price'], item['close_price'],
item['plate_name'], datetime.now()
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except IntegrityError:
spider.logger.info(f"跳过重复数据: {item['stock_code']} - {item['stock_name']}")
return item
def close_spider(self, spider):
if self.cursor: self.cursor.close()
if self.conn: self.conn.close()
print(f"数据库连接已关闭")
主代码
import scrapy
import json
import re
from stock_scrapy.items import StockScrapyItem
class StocksSpider(scrapy.Spider):
name = 'stocks' # 爬虫名称(启动时要用)
allowed_domains = ['push2.eastmoney.com']
# 爬取板块:沪深京A股)
cmd_dict = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
}
def start_requests(self):
for plate_name, cmd in self.cmd_dict.items():
url = f"https://7.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid={cmd}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
yield scrapy.Request(
url=url,
callback=self.parse,
meta={"plate_name": plate_name, "page": 1, "cmd": cmd}
)
# 解析数据以及分页
def parse(self, response):
plate_name = response.meta['plate_name']
current_page = response.meta['page']
cmd = response.meta['cmd']
response_text = response.text
data_str = re.sub(r'^.*?\(', '', response_text)
data_str = re.sub(r'\);?$', '', data_str)
data = json.loads(data_str)
if not data.get('data') or not data['data'].get('diff'):
self.logger.info(f"{plate_name} 第{current_page}页无数据")
return
# 提取股票数据并提交
stock_list = data['data']['diff']
for stock in stock_list:
stock_item = StockScrapyItem(
stock_code=stock.get("f12", ""),
stock_name=stock.get("f14", ""),
current_price=stock.get("f2", 0),
change_percent=stock.get("f3", 0),
change_amount=stock.get("f4", 0),
volume=stock.get("f5", 0),
turnover=stock.get("f6", 0),
amplitude=stock.get("f7", 0),
high_price=stock.get("f15", 0),
low_price=stock.get("f16", 0),
open_price=stock.get("f17", 0),
close_price=stock.get("f18", 0),
plate_name=plate_name
)
yield stock_item
# 分页处理
total_pages = data['data'].get('pages', 1)
if current_page < total_pages:
next_page = current_page + 1
next_url = f"https://7.push2.eastmoney.com/api/qt/clist/get?pn={next_page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid={cmd}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
yield scrapy.Request(
url=next_url,
callback=self.parse,
meta={"plate_name": plate_name, "page": next_page, "cmd": cmd}
)
self.logger.info(f"📄 {plate_name} 第{current_page}页爬完,准备爬第{next_page}页(共{total_pages}页)")
else:
self.logger.info(f"📄 {plate_name} 共{total_pages}页,爬取完成")
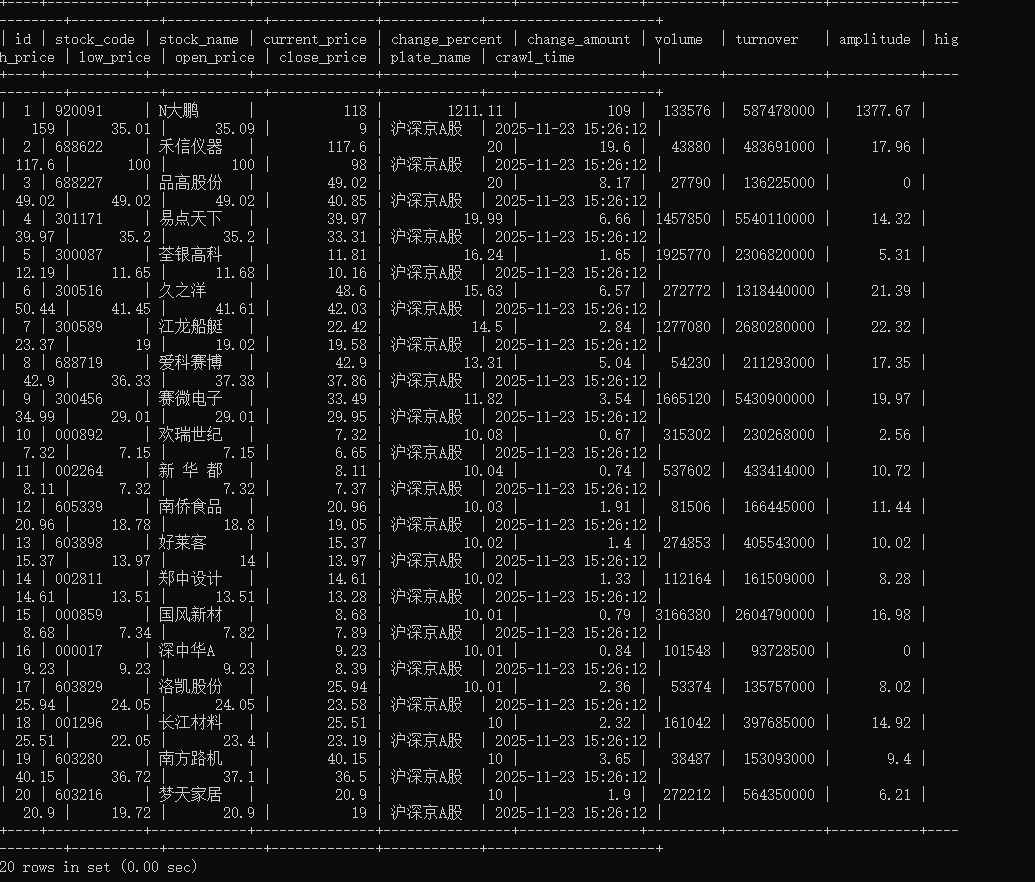
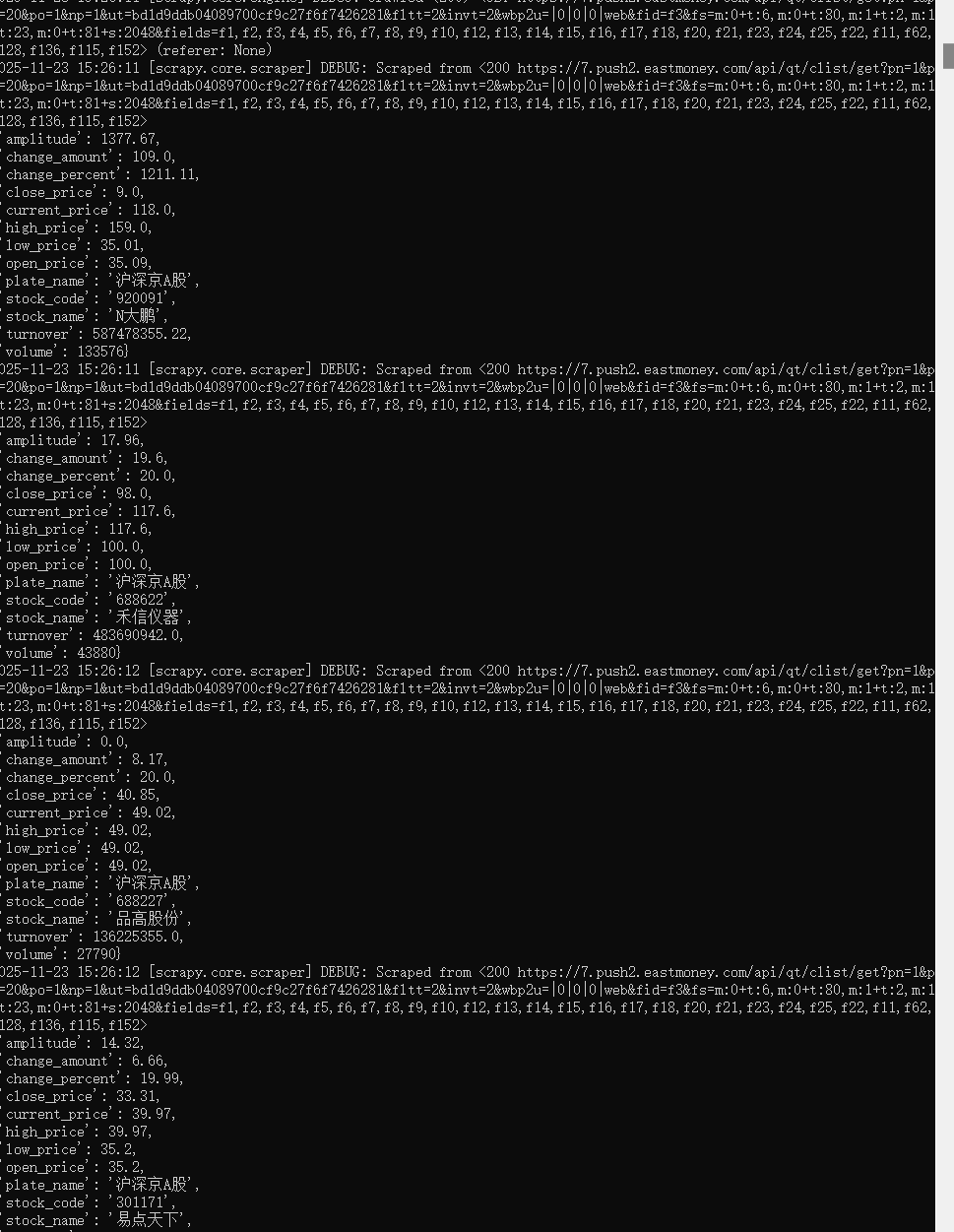
心得体会:
通过设计 Pipeline 实现 MySQL 存储并加 UNIQUE 约束,成功解决了数据去重问题
第三题:scrapy爬取外汇网站数据
核心代码与运行结果:
piplines
import pymysql
from pymysql.err import IntegrityError, OperationalError
from datetime import datetime
class ForexScrapyPipeline:
def __init__(self):
self.db_config = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'charset': 'utf8mb4'
}
self.conn = None
self.cursor = None
self.db_name = 'forex'
self.table_name = 'boc_forex'
self.connect_db()
self.create_table()
def connect_db(self):
try:
self.conn = pymysql.connect(**self.db_config, database=None)
self.cursor = self.conn.cursor()
# 创建数据库
self.cursor.execute(f"CREATE DATABASE IF NOT EXISTS {self.db_name} DEFAULT CHARSET utf8mb4;")
self.cursor.execute(f"USE {self.db_name};")
print(f"数据库{self.db_name}已就绪")
except OperationalError as e:
print(f"MySQL连接失败")
raise
# 建表
def create_table(self):
sql = f"""
CREATE TABLE IF NOT EXISTS {self.table_name} (
id INT AUTO_INCREMENT PRIMARY KEY,
currency_name VARCHAR(50) NOT NULL,
buy_transfer FLOAT,
buy_cash FLOAT,
sell FLOAT,
middle_rate FLOAT,
publish_date DATE,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(currency_name, publish_date)
)
"""
self.cursor.execute(sql)
self.conn.commit()
print(f"✅ 数据表{self.table_name}已就绪")
# 存数据
def process_item(self, item, spider):
sql = f"""
INSERT INTO {self.table_name}
(currency_name, buy_transfer, buy_cash, sell, middle_rate, publish_date, crawl_time)
VALUES (%s,%s,%s,%s,%s,%s,%s)
"""
values = (
item['currency_name'],
item['buy_transfer'],
item['buy_cash'],
item['sell'],
item['middle_rate'],
item['publish_date'],
datetime.now()
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except IntegrityError:
print(f"跳过重复:{item['currency_name']}")
return item
def close_spider(self, spider):
if self.cursor: self.cursor.close()
if self.conn: self.conn.close()
print(f"关闭数据库连接")
主程序
import scrapy
from forex_scrapy.items import ForexScrapyItem
from datetime import datetime
class BocForexSpider(scrapy.Spider):
name = 'boc_forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
publish_date = response.xpath('//div[contains(text(), "发布时间")]/text()').get()
if not publish_date:
publish_date = datetime.now().strftime('%Y-%m-%d')
else:
publish_date = publish_date.split(':')[-1].strip()
rows = response.xpath('//table//tr[position()>1]')
print(f'找到{len(rows)}条货币数据,开始抓取')
for row in rows:
item = ForexScrapyItem()
# 按顺序取
item['currency_name'] = row.xpath('./td[1]/text()').get('').strip()
item['buy_transfer'] = row.xpath('./td[2]/text()').get('0').strip()
item['buy_cash'] = row.xpath('./td[3]/text()').get('0').strip()
item['sell'] = row.xpath('./td[4]/text()').get('0').strip()
item['middle_rate'] = row.xpath('./td[6]/text()').get('0').strip()
item['publish_date'] = publish_date
if item['currency_name']:
yield item
print(f'已抓:{item["currency_name"]} - 中间价:{item["middle_rate"]}')
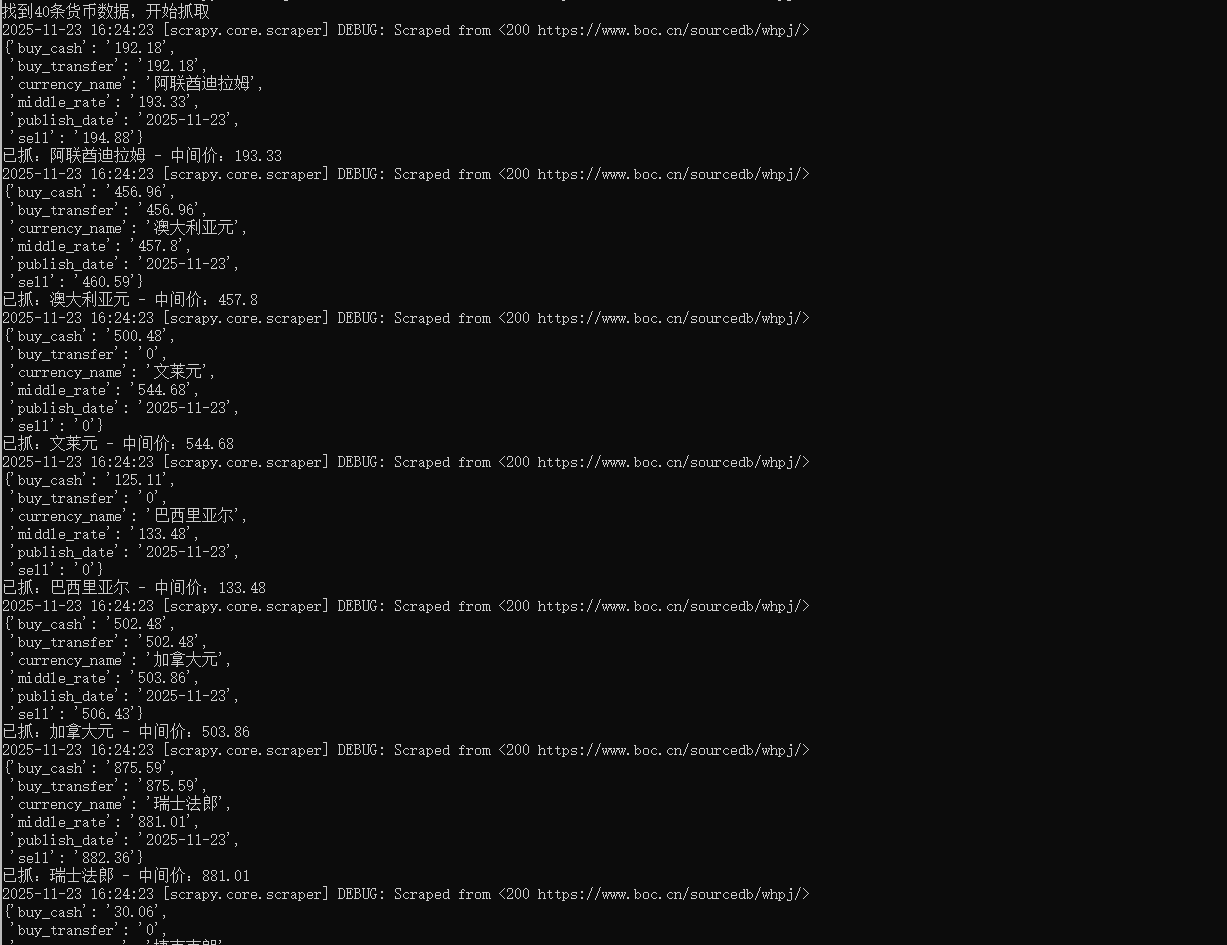
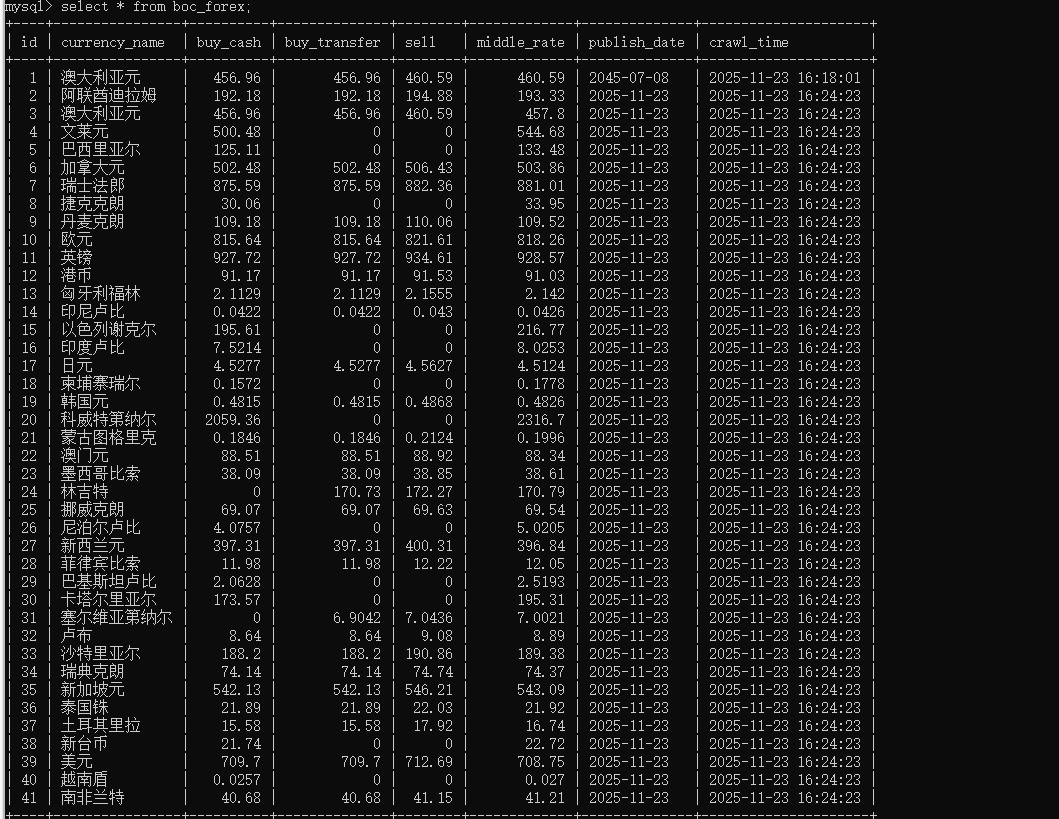
心得体会:
网页使用GBK编码,而Scrapy默认以UTF-8 解析,导致插入数据库后出现中文乱码,通过response.body.decode('gbk') 解决了中文乱码问题。加深了对网页编码处理和数据库存储的理解
Gitee仓库路径:
https://gitee.com/wudilecl/2025_crawl

 浙公网安备 33010602011771号
浙公网安备 33010602011771号