


第一题:爬取天气预报
核心代码与运行结果:
点击查看代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
# 创建表
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
# 插入天气数据
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
# 显示所有天气数据
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("城市", "日期", "天气状况", "温度"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode:
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
# 自动检测编码
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
# 选择天气信息列表
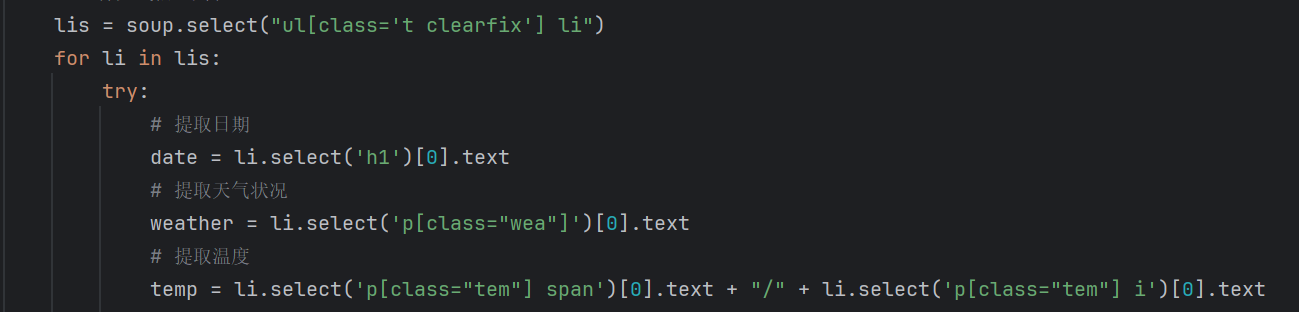
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
# 提取日期
date = li.select('h1')[0].text
# 提取天气状况
weather = li.select('p[class="wea"]')[0].text
# 提取温度
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
# 打印并保存
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
# 处理每个城市
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
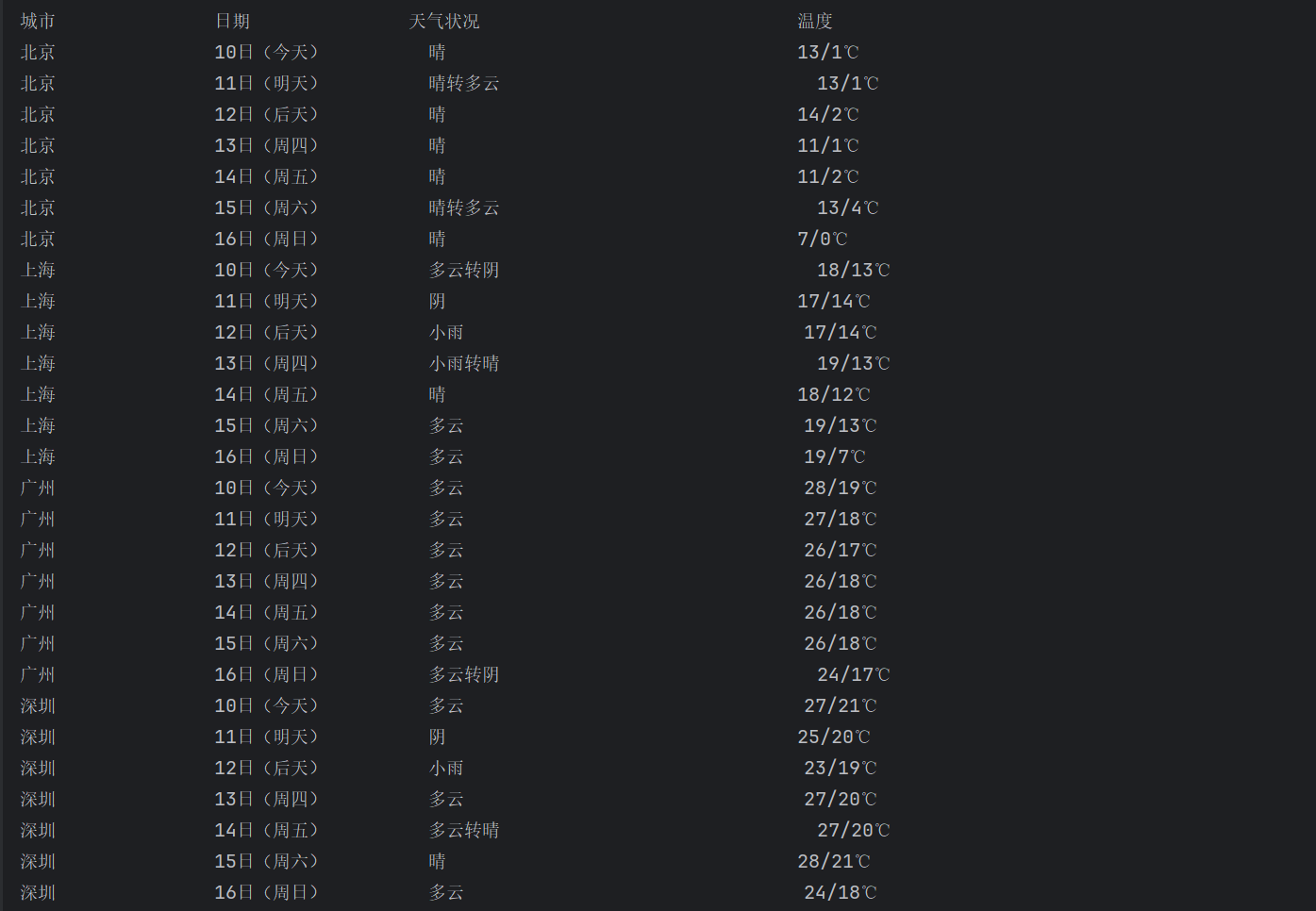
这里运用了 CSS 选择器,刚好能对上网页的结构设计。网页本身就有给样式定位用的 class,如标记天气的 wea、标温度的 tem,直接用这些再加标签层级,一句话就能把要筛选的元素属性和层级都包含进去。既能精准避开没用的内容,还能一次性把天气列表里每天的重复数据都抓出来,比用 find () 简洁,不用写多余代码,也不用纠结关键字冲突
心得体会:
最初爬取数据时,频繁出现编码乱码问题,导致提取的天气、温度文本出现乱码,排查后发现是未适配网页可能的 GBK 编码,通过引入 UnicodeDammit 自动检测编码类型,才解决了问题
第二题:爬取股票信息
核心代码与运行结果:
点击查看代码
import requests
import re
import sqlite3
import pandas as pd
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Cookie": "qgqp_b_id=18c28b304dff3b8ce113d0cca03e6727; websitepoptg_api_time=1703860143525; st_si=92728505415389; st_asi=delete; HAList=ty-100-HSI-%u6052%u751F%u6307%u6570; st_pvi=46517537371152; st_sp=2023-10-29%2017%3A00%3A19; st_inirUrl=https%3A%2F%2Fcn.bing.com%2F; st_sn=8; st_psi=20231229230312485-113200301321-2076002087"
}
null = "null"
def get_html(cmd, page):
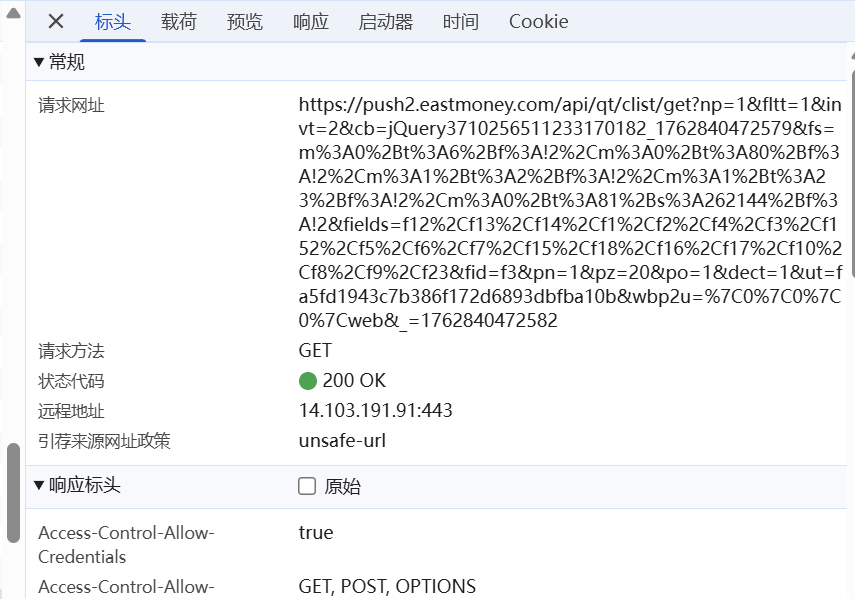
# 构建API请求URL,包含动态参数
url = f"https://7.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409467675731682619_1703939377395&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid={cmd}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1703939377396"
resp = requests.get(url, headers=header)
text = resp.text
# 使用正则表达式去除JSONP回调函数包装,提取纯JSON数据
data_str = re.sub(r'^.*?\(', '', text)
data_str = re.sub(r'\);?$', '', data_str)
# 将字符串转换为Python字典对象
return eval(data_str)
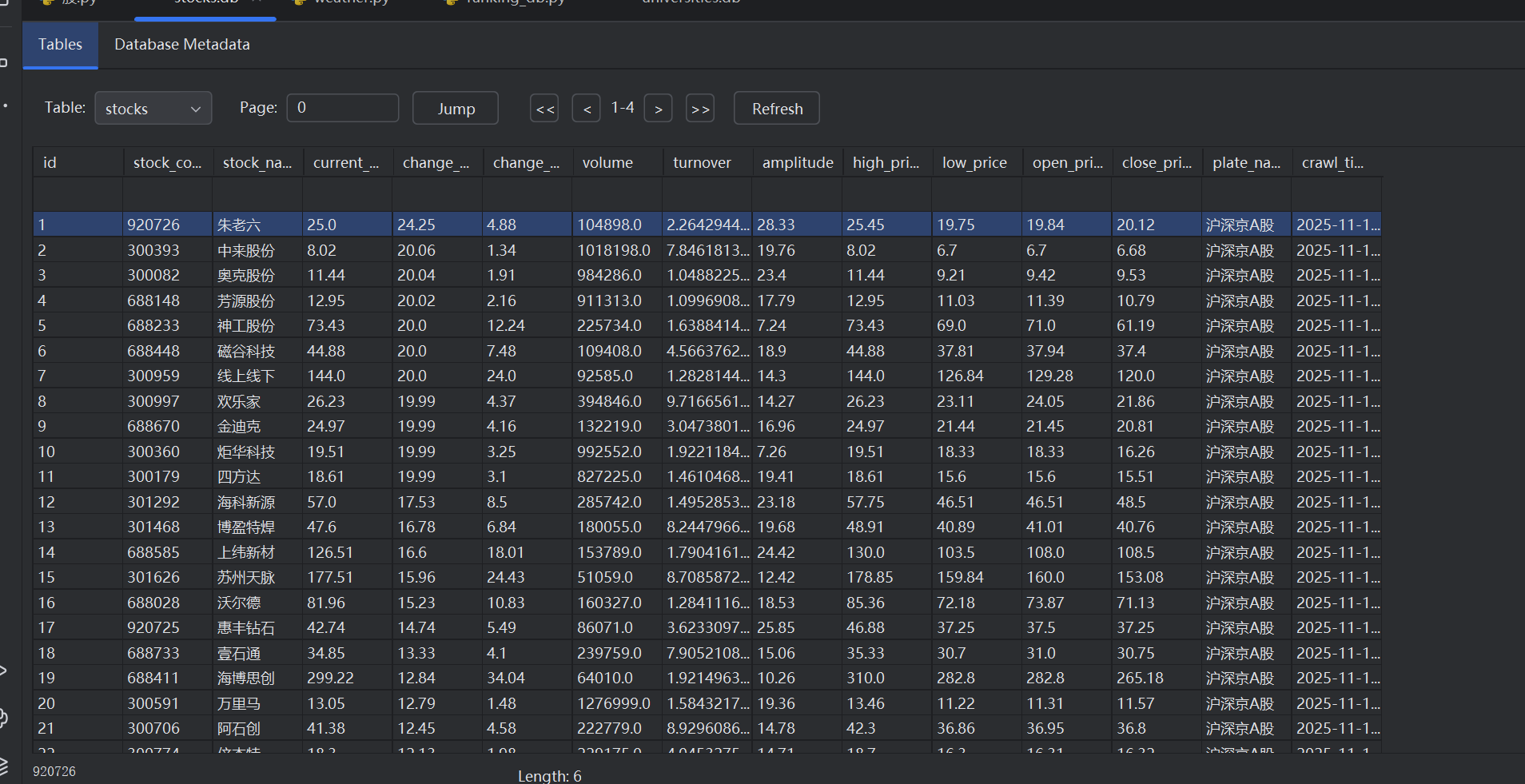
def init_database():
# 连接SQLite数据库(如果不存在则自动创建)
conn = sqlite3.connect('stocks.db')
cursor = conn.cursor()
# 创建股票数据表
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
stock_code TEXT NOT NULL,
stock_name TEXT NOT NULL,
current_price REAL,
change_percent REAL,
change_amount REAL,
volume REAL,
turnover REAL,
amplitude REAL,
high_price REAL,
low_price REAL,
open_price REAL,
close_price REAL,
plate_name TEXT,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(stock_code, crawl_time) -- 防止重复插入相同时间点的数据
)
''')
conn.commit()
return conn, cursor
def save_to_database(cursor, stocks, plate_name):
# 使用事务批量插入数据,提高效率
for stock in stocks:
try:
cursor.execute('''
INSERT INTO stocks
(stock_code, stock_name, current_price, change_percent, change_amount,
volume, turnover, amplitude, high_price, low_price, open_price, close_price, plate_name)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
stock["代码"],
stock["名称"],
stock["最新价"],
stock["涨跌幅"],
stock["涨跌额"],
stock["成交量"],
stock["成交额"],
stock["振幅(%)"],
stock["最高"],
stock["最低"],
stock["今开"],
stock["昨收"],
plate_name
))
except sqlite3.IntegrityError:
# 忽略重复数据
print(f"跳过重复数据: {stock['代码']} - {stock['名称']}")
continue
except Exception as e:
print(f"插入数据时出错: {e}")
# 配置要爬取的股票板块及其对应的API参数
cmd = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
}
# 初始化数据库
conn, cursor = init_database()
print("数据库初始化完成")
# 开始爬取各个板块的股票数据
for name in cmd:
page = 1
max_pages = 10
stocks = [] # 存储当前板块的所有股票数据
# 分页爬取数据
while page <= max_pages:
# 获取当前页的数据
data = get_html(cmd[name], page)
if data['data'] == null:
print(f"第{page}页无数据,提前结束")
break
print(f"正在爬取 {name} 第{page}页")
# 提取股票列表数据
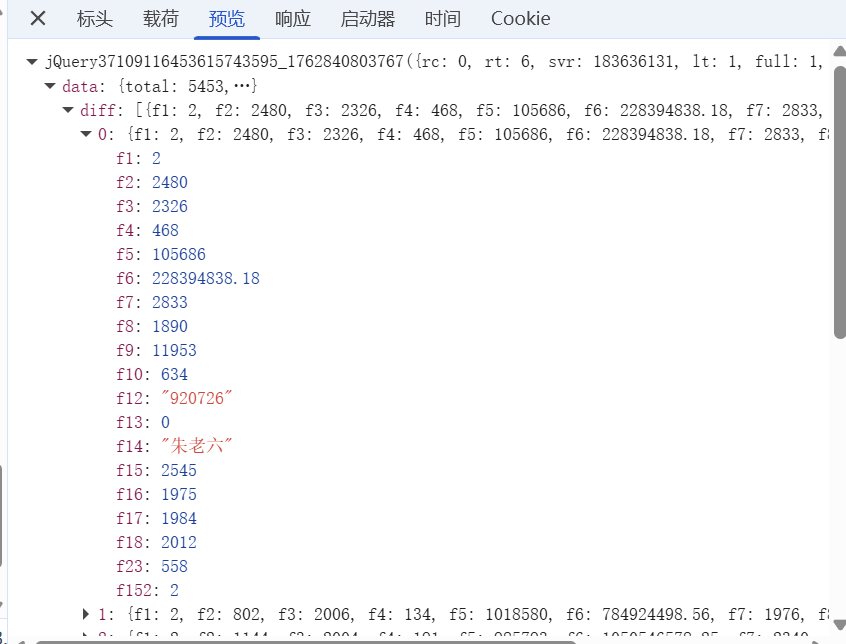
items = data['data']['diff']
# 遍历每条股票数据,提取关键字段
for item in items:
stock = {
"代码": item["f12"],
"名称": item["f14"],
"最新价": item["f2"],
"涨跌幅": item["f3"],
"涨跌额": item["f4"],
"成交量": item["f5"],
"成交额": item["f6"],
"振幅(%)": item["f7"],
"最高": item["f15"],
"最低": item["f16"],
"今开": item["f17"],
"昨收": item["f18"],
}
stocks.append(stock)
page += 1
save_to_database(cursor, stocks, name)
conn.commit()
print(f"已保存 {len(stocks)} 条 {name} 数据到数据库")
cursor.close()
conn.close()
print("所有数据已成功保存到数据库")
这里利用了浏览器网络监控功能,通过全局搜索clist等关键词,找到了隐藏的股票数据API接口。分析JS代码中的URL构造逻辑后,获得了完整的API地址和参数格式,成功绕过了传统网络请求分析找不到接口的限制
心得体会:
这里利用了网络请求分析的方法,通过反复试错才找到正确的API接口。最初我在XHR中寻找数据接口,结果一无所获;后来转向JS请求分析,才发现真正的数据接口隐藏在脚本文件中。代码实现也经历了多次调整,从最初无法获取数据到最终成功解析JSONP格式,每一步都是通过不断调试和修正错误才走通的
第三题:爬取软科所有院校信息
核心代码与运行结果:
点击查看代码
import requests
import sqlite3
import json
API = "https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2021"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.shanghairanking.cn/rankings/bcur/2021"
}
try:
resp = requests.get(API, headers=HEADERS, timeout=15)
resp.raise_for_status()
result = resp.json()
rankings = (result.get("data") or {}).get("rankings", [])
print(f"成功获取 {len(rankings)} 条数据")
except Exception as e:
print("获取失败:", e)
exit()
rows = []
for item in rankings:
# 用临时字典收集字段
info = {
"rank": item.get("ranking") or item.get("rank"),
"name": item.get("univNameCn") or item.get("univName"),
"province": item.get("province") or "",
"type": item.get("univCategory") or "",
"score": item.get("score") or ""
}
if not info["rank"] or not info["name"]:
continue
# 清洗数据
info["name"] = info["name"].strip()
info["province"] = info["province"].strip()
# 将字典解包为元组插入
rows.append(tuple(info.values()))
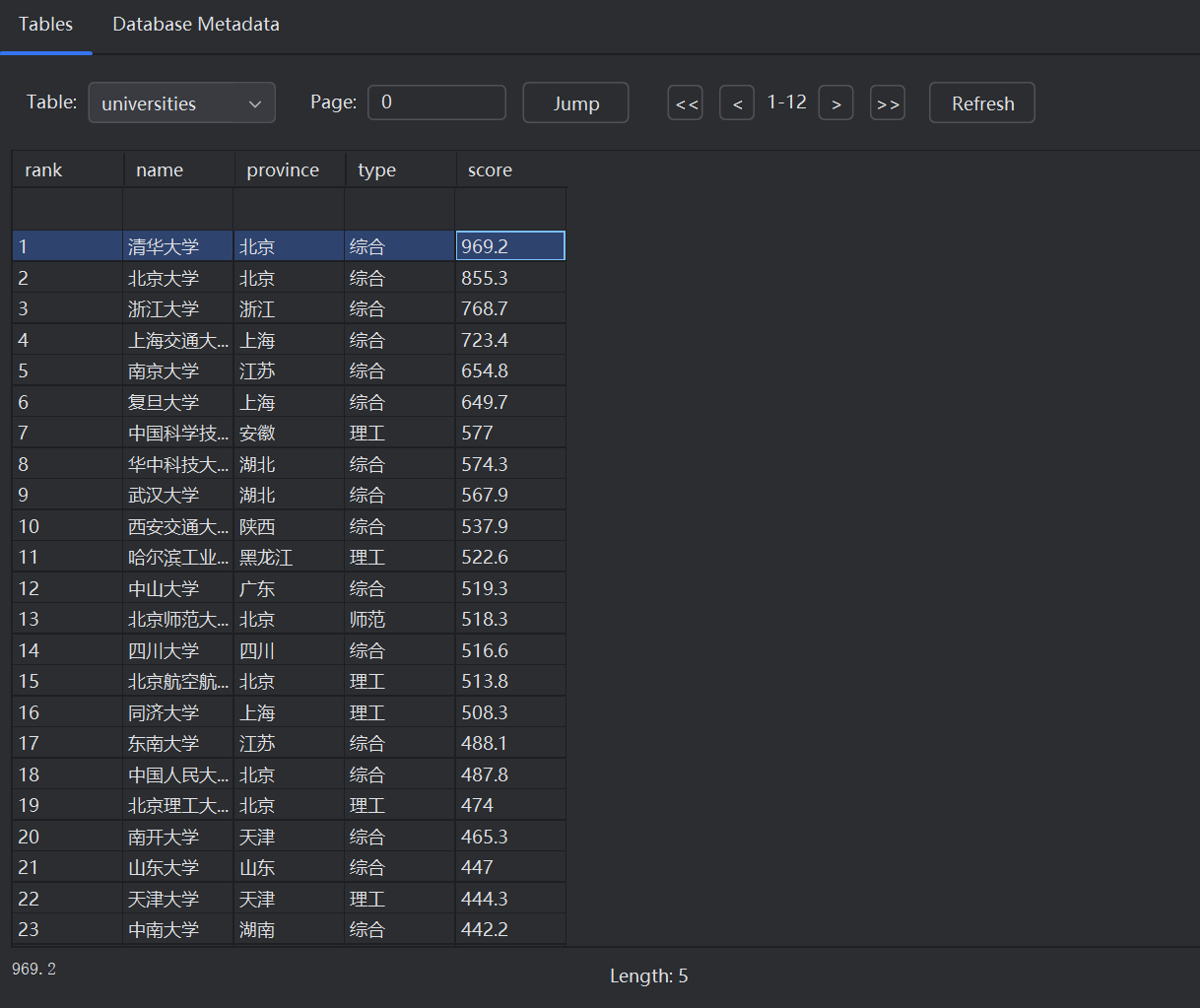
print("\n" + "=" * 60)
print(f"{'排名':<6}{'学校名称':<15}{'省市':<8}{'类型':<10}{'总分':<8}")
print("-" * 60)
for r in rows[:30]:
print(f"{r[0]:<6}{r[1]:<15}{r[2]:<8}{r[3]:<10}{r[4]:<8}")
conn = sqlite3.connect("universities.db")
cur = conn.cursor()
try:
cur.execute("""
create table universities (
rank text,
name text,
province text,
type text,
score text,
constraint pk_univ primary key (rank, name)
)
""")
print("\n创建表 universities")
except sqlite3.OperationalError:
cur.execute("delete from universities")
print("\n表已存在,已清空旧数据")
count = 0
for row in rows:
try:
cur.execute("insert into universities values (?,?,?,?,?)", row)
count += 1
except sqlite3.IntegrityError:
pass
conn.commit()
conn.close()
print(f"\n共保存 {count} 条记录到 universities.db")

心得体会:
原本用HTML解析的方式,转变为直接调用官方接口获取JSON 数据。以前通过解析网页只能拿到一页内容,而且结构不稳定,容易因为网页更新而出错;而现在通过分析接口请求参数,使用requests直接抓取JSON,数据更完整、速度更快、也更可靠
Gitee仓库路径:
https://gitee.com/wudilecl/2025_crawl

 浙公网安备 33010602011771号
浙公网安备 33010602011771号