第二次作业----深度学习和 pytorch 基础
刘海龙
一、观看视频心得
在绪论当中,我了解到了人工智能的三个层面:计算智能、感知智能和认知智能 ,这三个层面中前两个均属于机器计算层面,大部分工作都是由机器自动化完成,其工作效率可能会远远大于人类,而第三个层面,是目前人工智能的主要发展趋势。从网络上面了解来看,认知智能是人工智能的最高形态,也是当今人工智能发展最想要达到的境界,其中的两个核心是“理解”和“解释”,让机器具有推理、学习、判断等功能。其次机器学习的实现与我们平时写的代码运行有很大的不同,我们写的代码主要为计算方法,给定数据后经过执行代码的过程得到结果。机器学习则是给定数据,然后由机器学习其数据特征、优化数据计算方法,最后得出“计算结果”。
模型、策略、算法是机器学习中的三个目标,其中模型是对学习问题映射的假设。在传统的机器学习中,特征处理的机制都是由人为设计完成的,并将特征映射到目标空间。深度学习模拟人类视觉特征,将特征进行分类划分,并不需要认为来设定某一模型的特征,这样做无疑更加节省时间。这也是为什么深度学习占据人工智能的主要学习方法。但深度学习仍存在许多问题,其算法输出不稳定,容易被“攻击”,若其某一单个数据受到干扰,其结果可能有很大的不同。且模型复杂度高,难以纠错和调试。
二、不懂的地方
什么是卷积核复合,以及在深度学习当中,卷积的作用是什么?
感知器和激活函数的关系,以及他们在算法当中的作用是什么?
梯度是如何产生的及梯度带来的影响?
三、动手实践




吕晓龙
part one
机器学习在做srdp就接触过了,之前一个暑假都在学的基础知识感觉又全都忘了,现在看看视频可能会回想起来一点??(大师兄回来了都回来了)
第一个视频是关于机器学习的前瞻,应用场景,发展历史,还有机器学习的一些做不到的事情,人脸识别在美国是真的用不了= =
第二个视频是介绍了一些模型设计的原理,激活函数,BP算法,最后还提到了向量机和无监督的自编码器,但是还是没有看懂这俩(理直气壮) 因为当时就是直奔着CNN跟RNN去的。
还有这个人讲的BP有点麻烦,建议看这篇博客,简单明了
https://blog.csdn.net/qq_32241189/article/details/80305566
问题就是:
希望老师能再讲一下RBM和自编码器,尤其是涉及到数学的地方可以给解释一下,因为已经全忘了。
part two
第一部分的代码就是教大家pytorch的简单使用,像是拼接cat,改变维度permute,等等
运行的时候报错了,因为是在本地的pycharm跑的还是什么原因
报错的原因是v在随机的时候生成的类型是Long,m @ v的时候要求是Float类型的。
v = torch.arange(1,5)
m @ v
改就把v改成 v.float
这个是pytorch中文使用文档:https://github.com/apachecn/pytorch-doc-zh
这个是pytorch使用函数查询:https://pytorch-cn.readthedocs.io/zh/latest/
所谓熟能生巧,多用多查可能就会背过吧大概。
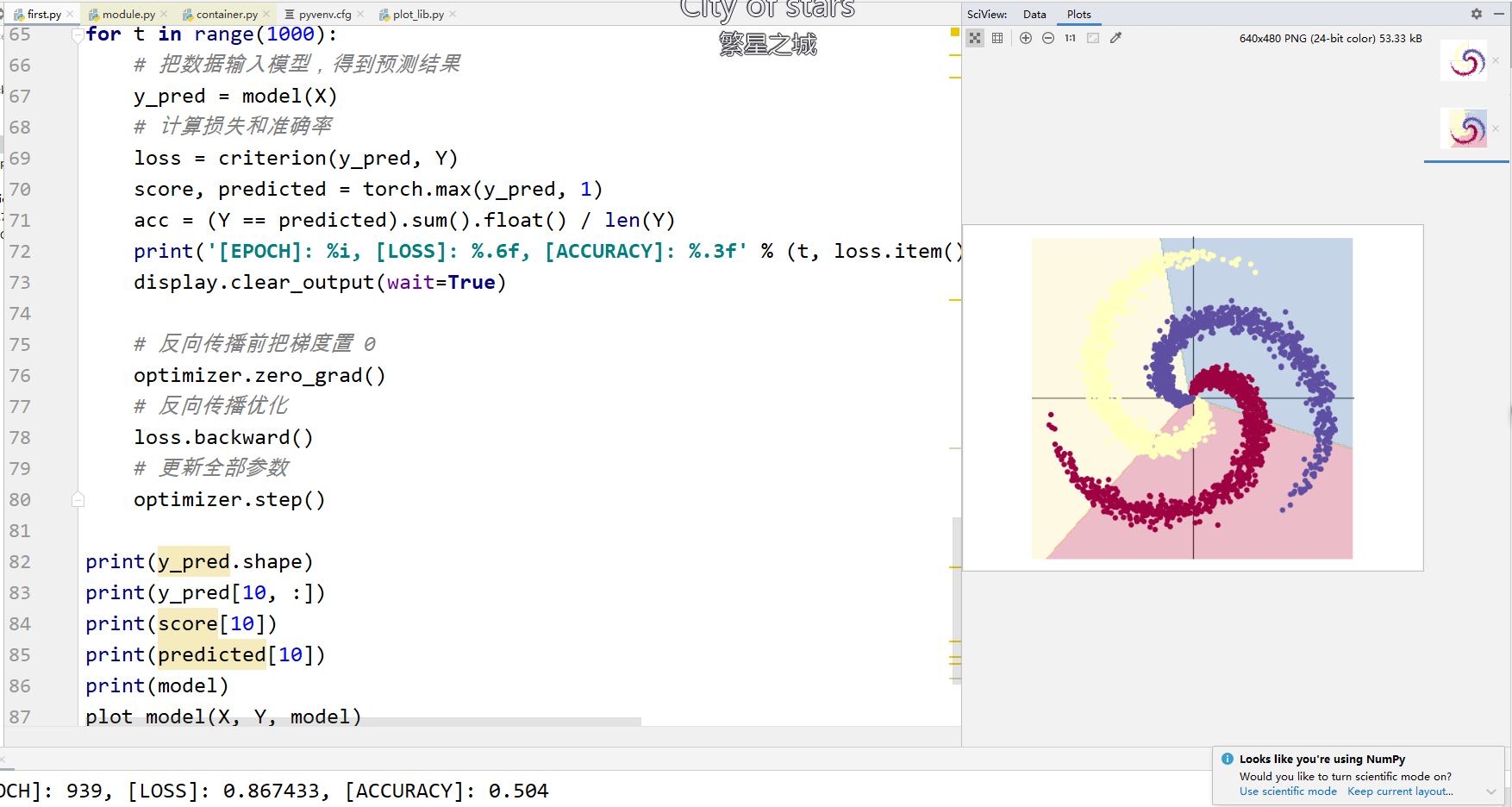
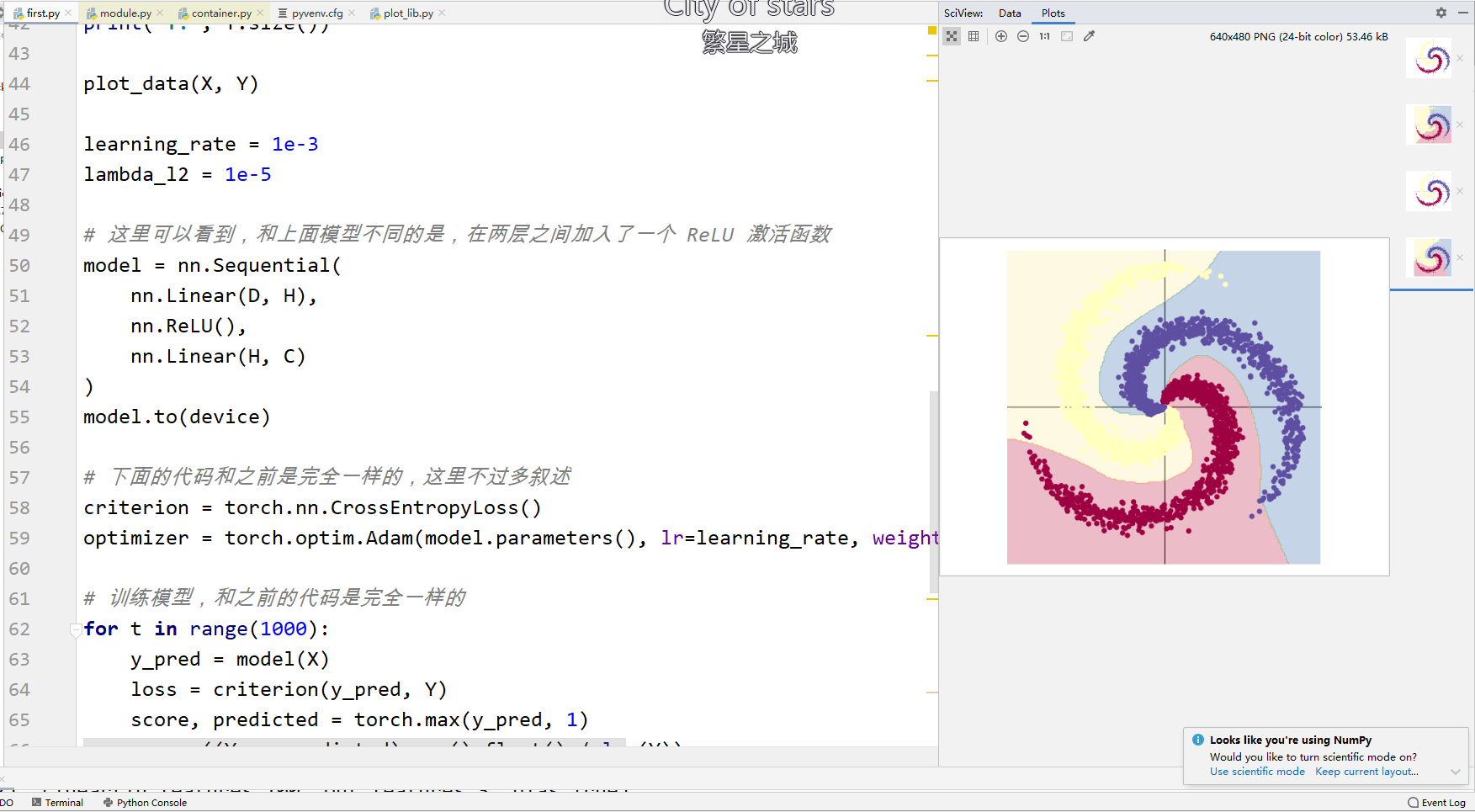
第二部分的代码是一个简单的模型,应该是两个,一个是一层全连接层一个是两层全连接层夹了一个激活函数。
展示了真实的模型是怎么训练产生的,以及激活函数和层数对于模型的影响。
马良吉
视频学习心得及问题总结
学习心得
通过两个视频的学习,我发现我之前对机器学习的定义有一定的误区,原来机器学习是产生模型的算法,通过数据拟合产生对应的模型,而产生模型的一般都会存在误差,误差是由数据学习决定,数据过少模型误差很大,过多数据可能会导致过拟合也会产生很大的误差。
问题总结
对监督学习、强化学习的不是很理解
代码练习
2.1
- 截图
-
解读
解读写在了代码的注释中。
2.2
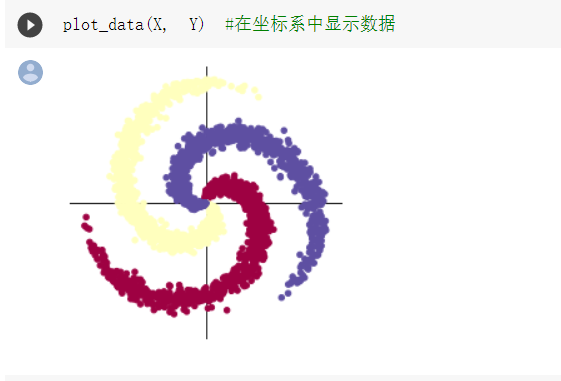
- 截图

- 解读

样本类别即螺旋翅膀数量,当C=4时
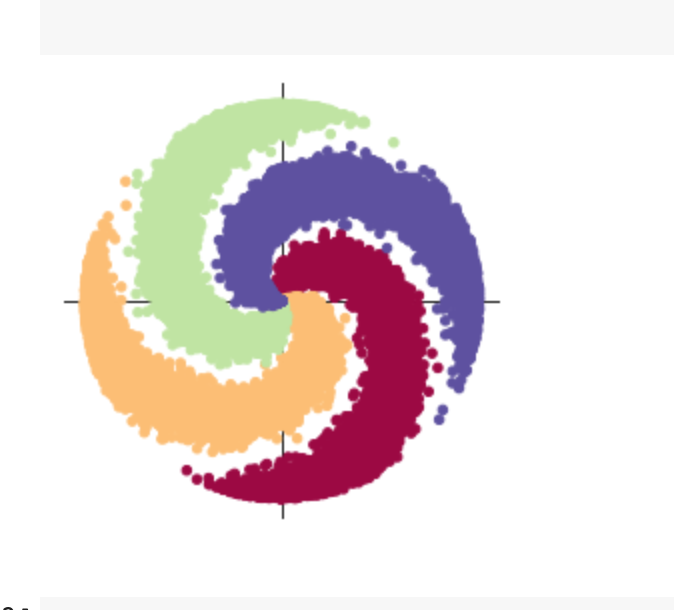
N为样本点数量
宋江
视频总结
1.基本介绍:
讲述了人工智能发展的过程。介绍了人工智能的层次:计算智能,感知智能(现阶段),认知智能。现阶段发展在于“人工智能+”,应用于生活。人工智能是领域,机器学习是领域中的一类方法,深度学习是一类方法中的一个点。机器学习将准则不再由专家进行定义,而是用训练文档,实现机器自动学习。减少人繁琐工作,提高信息处理效率,减少人工规则带来的主观影响。机器学习自动从数据中获得知识,包含三部分模型(数据标记,数据分布,建模对象),策略,算法。无监督学习适合描述数据,监督学习适合预测数据标记。
2.绪论:
传统机器学习:人工设计特征。深度学习:机器自动学习。
深度学习到后深度学习,人工工作更少。
深度学习应用研究:视觉+语言。
深度学习的“不能”:
算法输出不稳定,容易被攻击。
模型复杂度高,难以纠错和调试。
模型层级符合程度高,参数不透明。
端到端训练方式对数据依赖性强,模型增量性差
专注直观感知类问题,对开放性推理问题无能为力
人类知识无法有效引入进行监督,机器偏见难以避免
3.神经网络基础
单层感知器到多层感知器。
单隐层神经网络可视化
万有逼近定理:如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-输出)能以任意精度逼近任意预定的连续函数。
双隐层感知器逼近非连续函数(隐层足够宽的时候可以逼近任意函数)
神经元总数相当,增加网络深度比宽度能带来更强的网络表示能力,缠上更多的线性区域。
深度和看宽度对函数复杂度贡献不同,深度贡献指数的,宽度贡献线性的。
4.逐层预训练:受限于玻尔兹曼机和自编码器
自编码器一般是多层神经网络
玻尔兹曼机 可见层和隐层内部节点可连接
RBM对联合概率密度建模,是生成模型
自编码器直接对条件概率建模,是判别模型
5.问题
复杂度高的模型存在问题,会难以纠错和调试,对于较为简单的模型也会出现这种问题吗?
代码学习
1.定义数据,特别是多维数组的时候方便快捷,相较于c,c++语言有明显的优势。
2.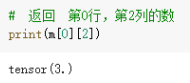
这里会出现“3.”而不是“3”
3.
默认是long类型,需要进行类型转换
4.展现了单层和多层两种模型训练


余泽芃
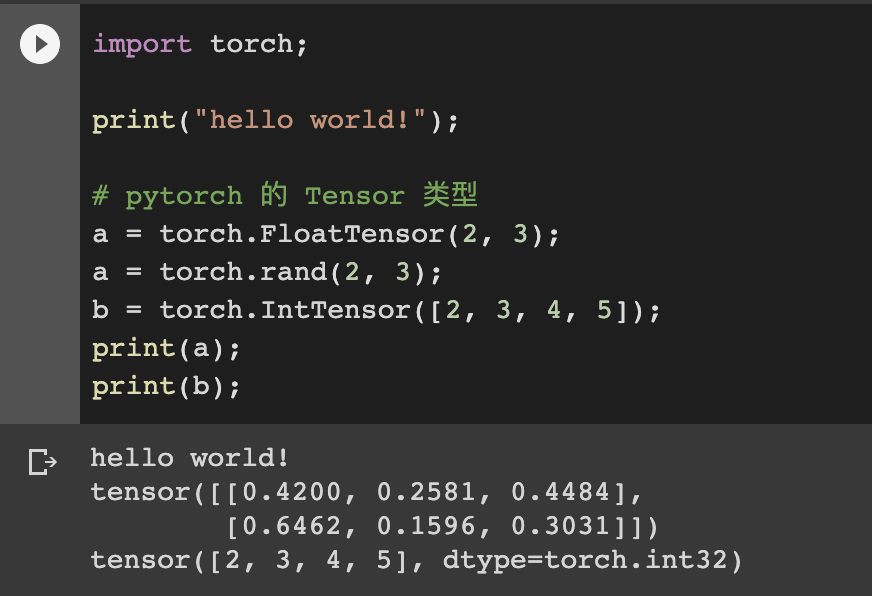
pytorch 的简单使用
在 colab 上编写 pytorch 程序,定义了两个 Tensor 类型数据
深度学习
深度学习是让机器像人一样学习,然后解决复杂的难题。
目前只是大致的了解,也没有尝试过。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号