
20212218林思凡《Python程序设计》实验四Python综合实验实验报告
课程:《Python程序设计》
班级: 2122
姓名: 林思凡
学号:20212218
实验教师:王志强
实验日期:2022年5月27日
必修/选修: 公选课
一、实验要求
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
二、实验内容
通过python网络爬虫在菜鸟编程www.runoob.com上爬取python编程100个实例,并转化为.py文件保存在华为云ECS云服务器。
三、实验灵感
作为大一新生,对各种高级语言掌握不够深入,经常通过CSDN、菜鸟编程等编程学习网站学习计算机语言,也会上各种oj平台等查看案例。突发奇想,若能将菜鸟编程已有的实例保存到本地,这样在无网络的情况下,也可以学习编程;恰好老师讲了python网络爬虫技术,便通过进一步深入学习做了一个爬虫程序。
四、实验过程及结果
1.观察网页
打开菜鸟编程的python实例页面,观察网页布局:
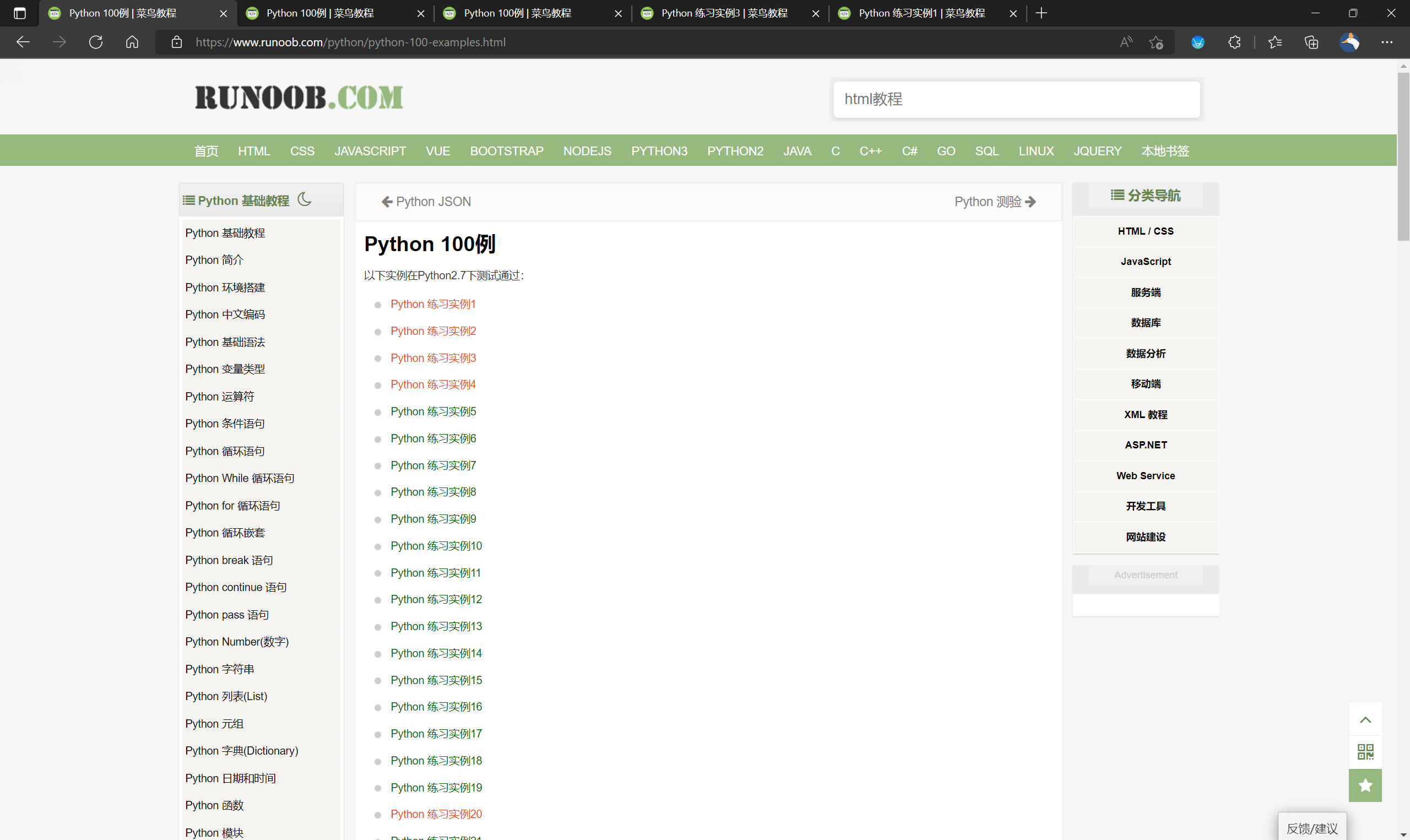
观察到,实例1的网址为

实例2的网址为
https://www.runoob.com/python/python-exercise-example2.html

比对网址,发现网址差别仅在example1和example2,可得出结论,实例网址的普遍规律为https://www.runoob.com/python/python-exercise-example_.html
可以运用此规律建立循环。
2.开始爬虫
首先导入模块requests, lxml,并按照上述规律设置基础网址:

查找头部信息,在菜鸟网页按F12,点击网络查找所需的头部信息:
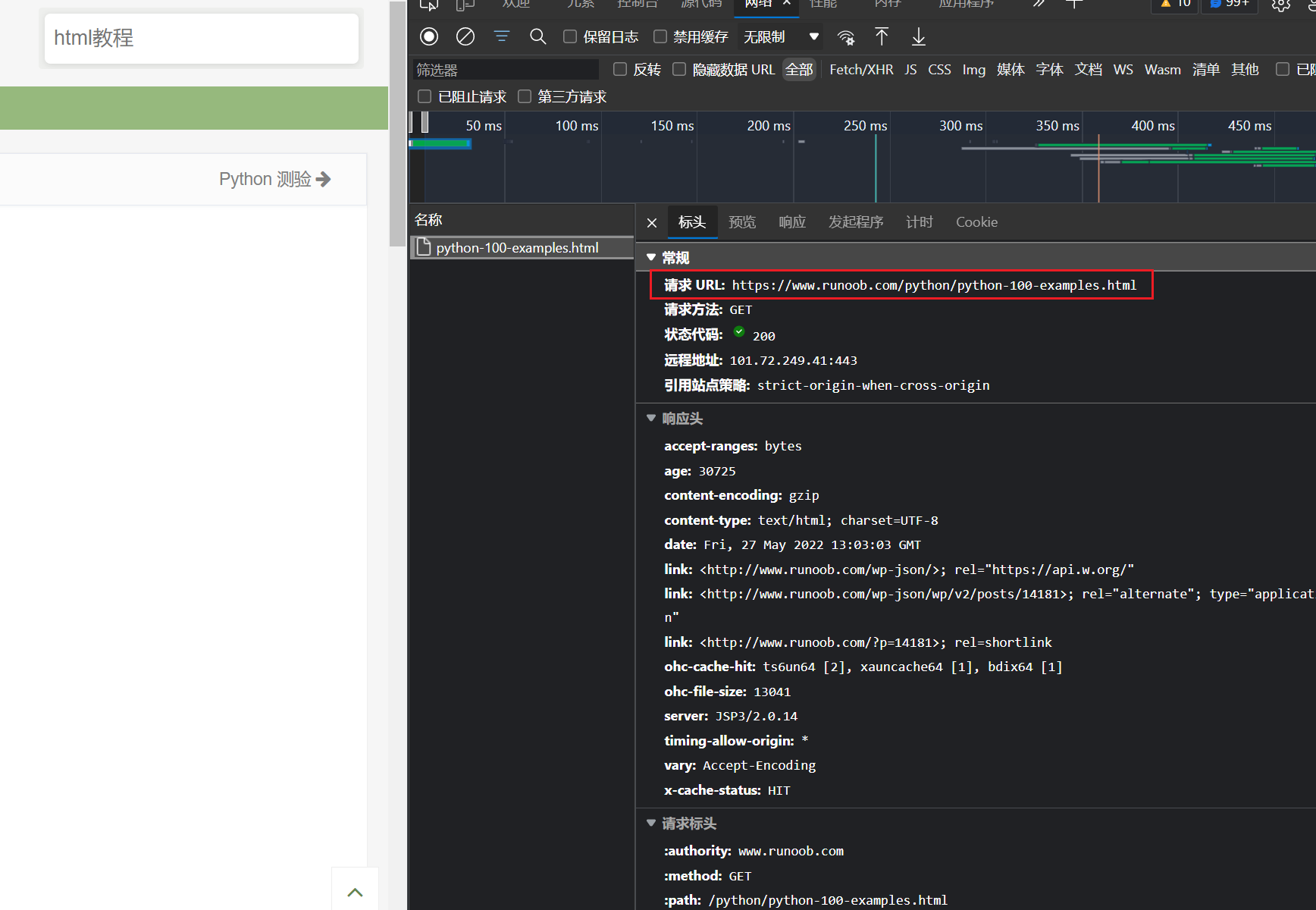
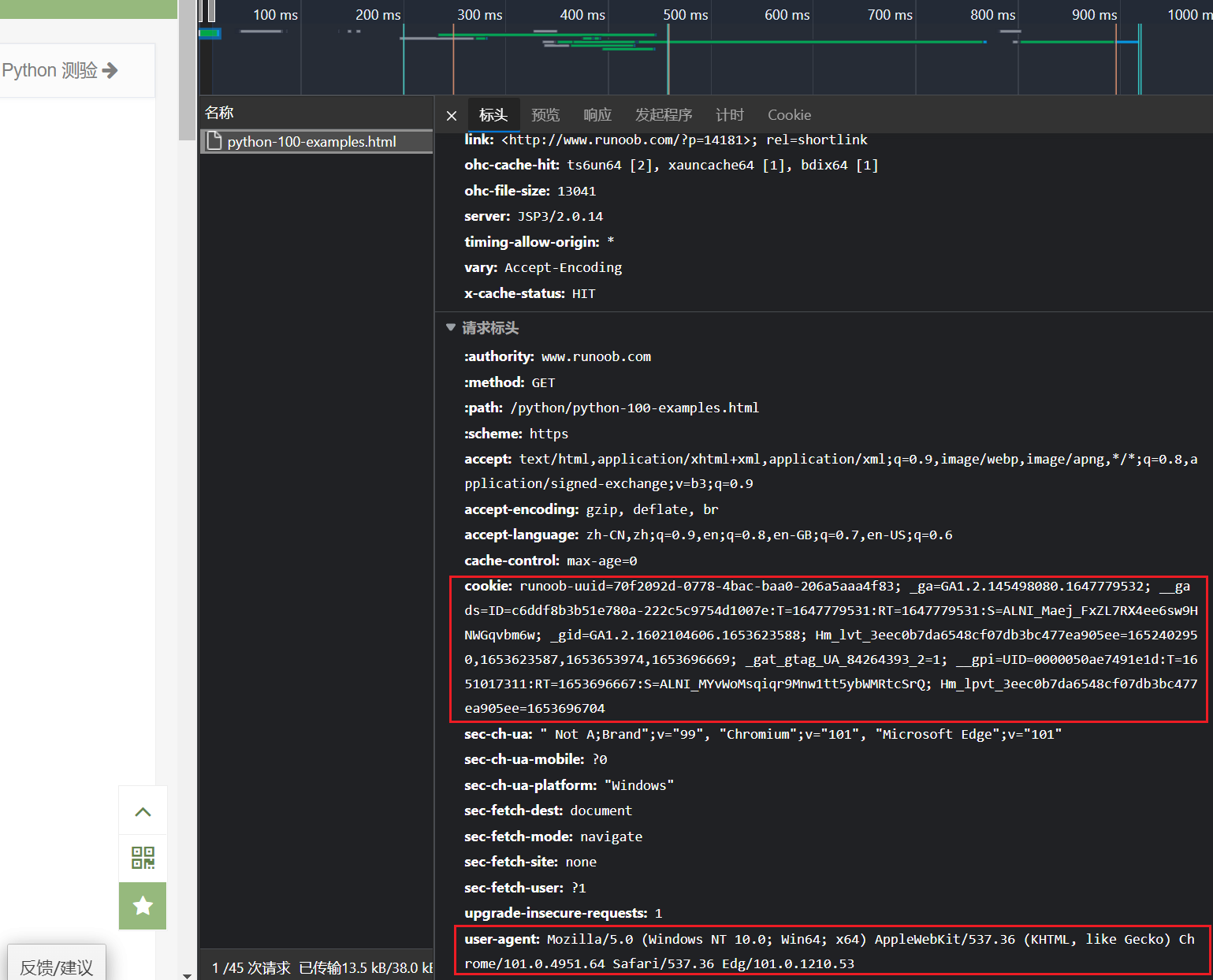
创建getHTML()函数:

代码说明:response = requests.get(url, headers=headers):构造一个向服务器请求资源的url对象。
创建writepy()函数:
用途是将爬到的python实例信息写进文件里。

创建主函数main():

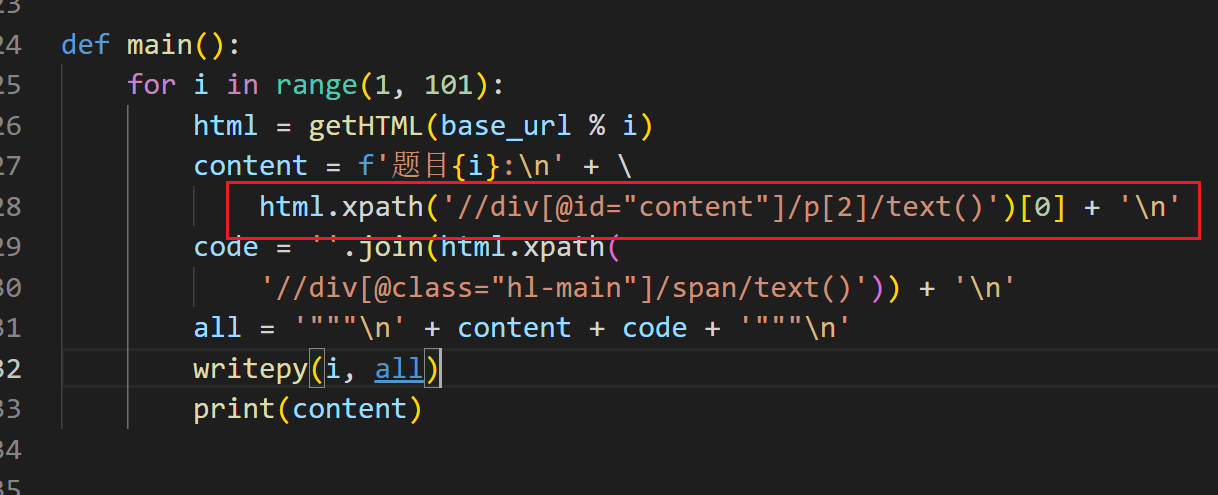
用一个for循环爬取实例1~实例100的html,在菜鸟网页通过DevTools观察网页元素
观察到,实例题目源代码:'div',属性'id' = 'content',并且属于第二个<p>标签

通过html.xpath()查找出对应的文本储存在content中,其中用@进行属性过滤。
用相同的方法,继续观察实例的代码部分:

同样,通过规则查找对应的文本信息,储存在变量code中。joim()函数连接字符串。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串。
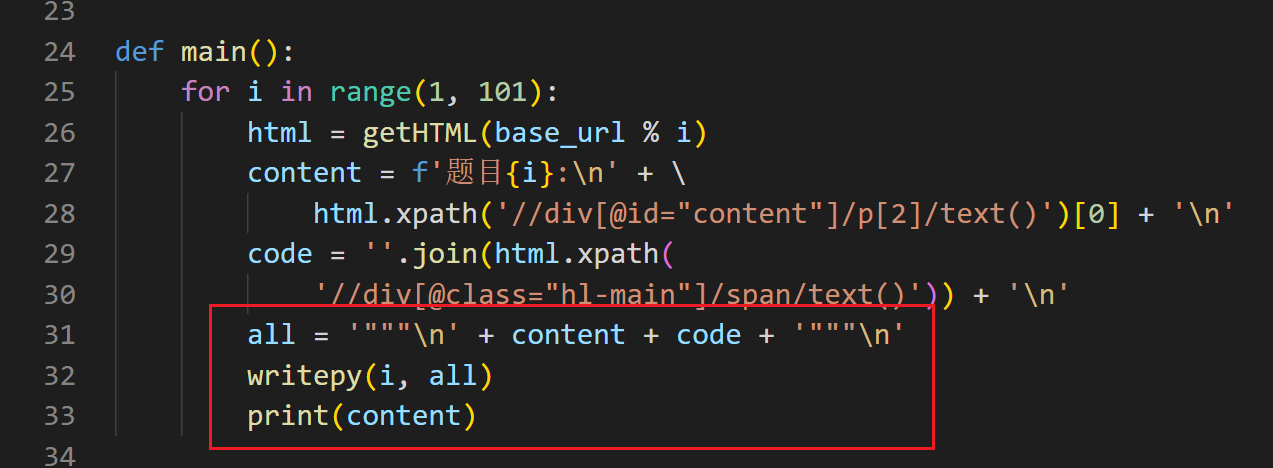
最后,将储存的content和code拼接起来,加入三个单边双引号"""注释,存储进变量all中,再通过writepy写进.py文件中。print语句会打印每个实例的标题(内容)。
然后执行程序。
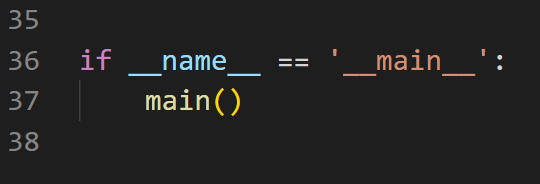
完整源代码:
import requests from lxml import etree base_url = 'https://www.runoob.com/python/python-exercise-example%s.html' # 网址含字符串 def getHTML(url): # 头文件 headers = { 'cookie': 'runoob-uuid=70f2092d-0778-4bac-baa0-206a5aaa4f83; _ga=GA1.2.145498080.1647779532; __gads=ID=c6ddf8b3b51e780a-222c5c9754d1007e:T=1647779531:RT=1647779531:S=ALNI_Maej_FxZL7RX4ee6sw9HNWGqvbm6w; Hm_lvt_3eec0b7da6548cf07db3bc477ea905ee=1651191230,1651795615,1652402950,1653623587; _gid=GA1.2.1602104606.1653623588; __gpi=UID=0000050ae7491e1d:T=1651017311:RT=1653623603:S=ALNI_MYvWoMsqiqr9Mnw1tt5ybWMRtcSrQ; Hm_lpvt_3eec0b7da6548cf07db3bc477ea905ee=1653623819; _gat_gtag_UA_84264393_2=1', 'referer': 'https://www.runoob.com/python/python-100-examples.html', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53' } # 通过response=request.get(url)构造一个向服务器请求资源的url对象。 response = requests.get(url, headers=headers) return etree.HTML(response.text) # 文本类型 # 调用HTML类对HTML文本进行初始化,成功构造XPath解析对象,同时自动修正HMTL文本 def writepy(i, text): # 用with open()来写,同时包含open()和close() with open('python实例%s.py' % i, 'w', encoding='utf-8') as file: file.write(text) # 将变量text写入文件 def main(): # 从1-100页的网址 for i in range(1, 101): html = getHTML(base_url % i) content = f'题目{i}:\n' + \ html.xpath('//div[@id="content"]/p[2]/text()')[0] + '\n' # 文本获取:用@符号进行属性过滤,此处表示匹配div下属性id为content的内容 code = ''.join(html.xpath( '//div[@class="hl-main"]/span/text()')) + '\n' all = '"""\n' + content + code + '"""\n' writepy(i, all) print(content) if __name__ == '__main__': main()
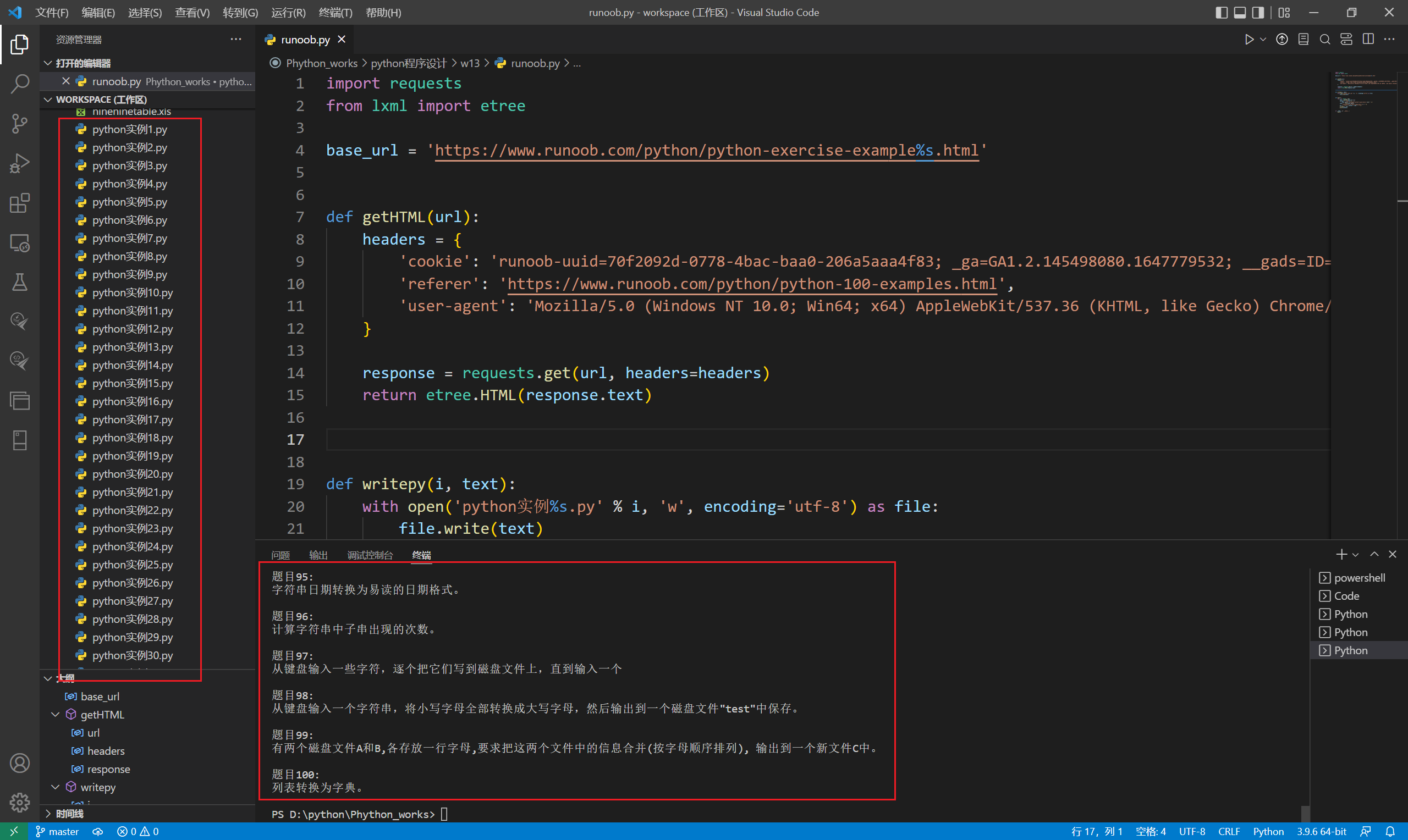
程序执行效果如下:


3.上传代码到华为云弹性云服务器ECS并运行
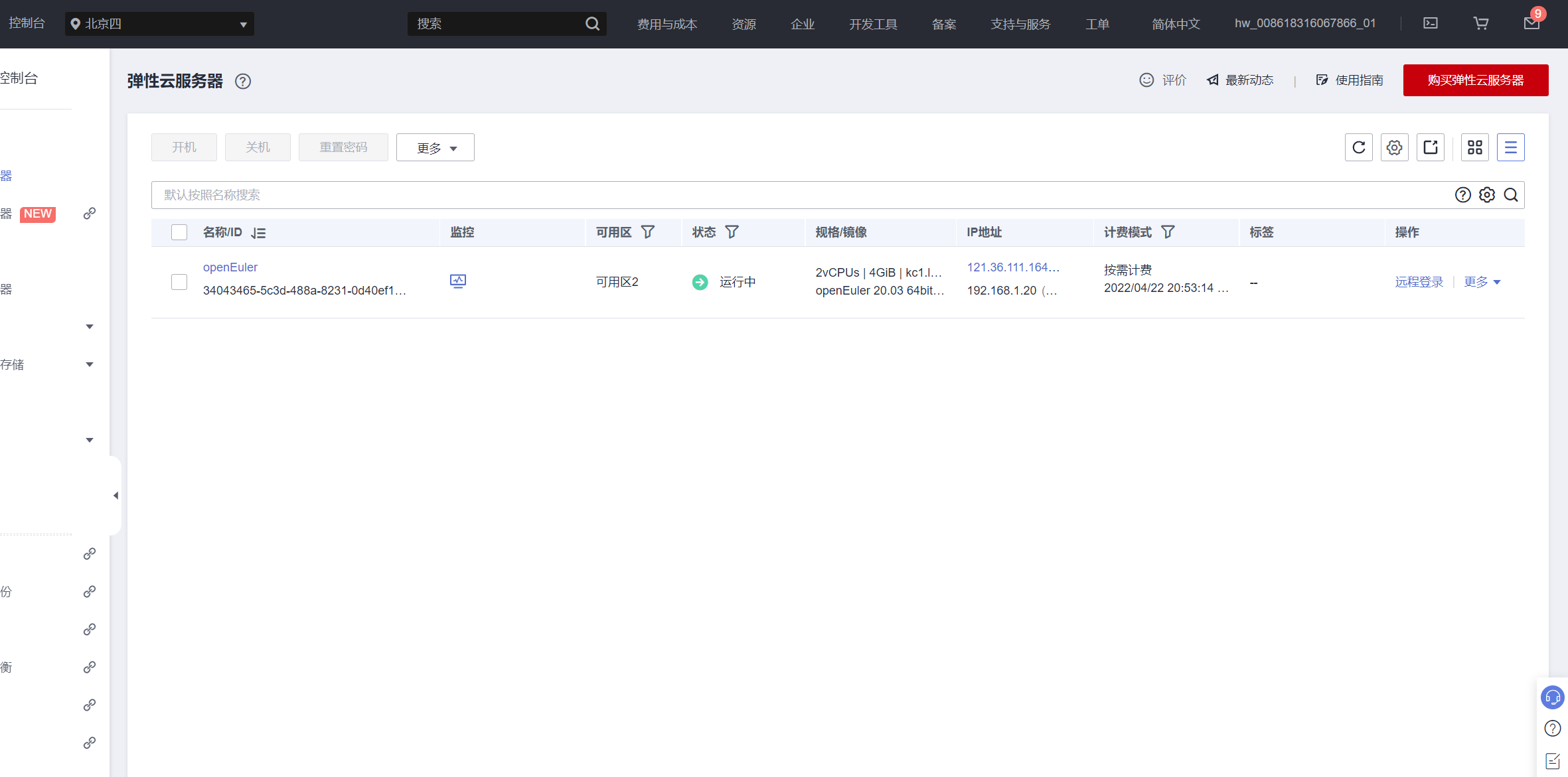
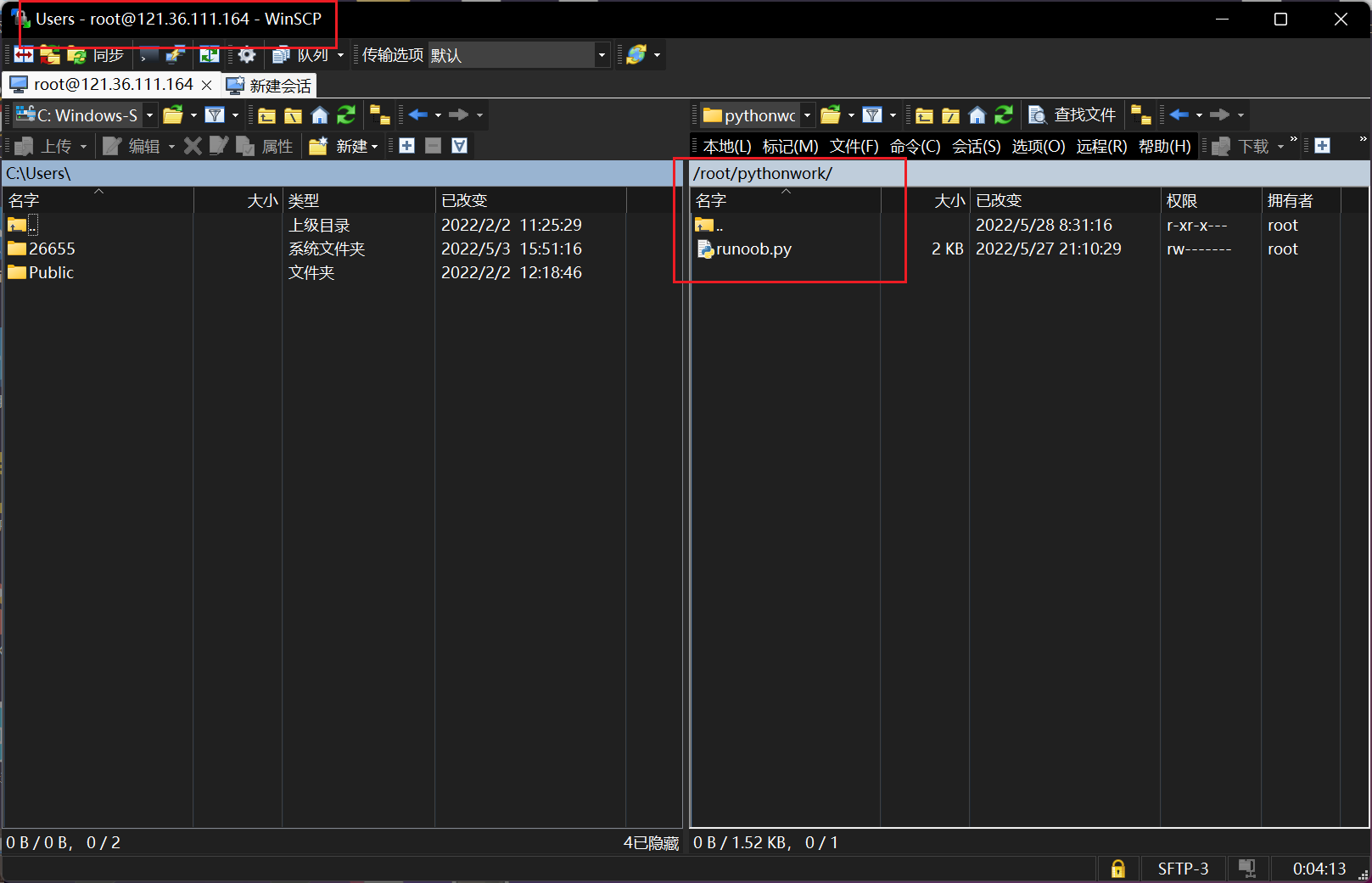
通过putty登录云服务器,创建文件夹pythonwork,通过winscp将程序拖到云服务器的文件夹里
接下来在云服务器上运行。
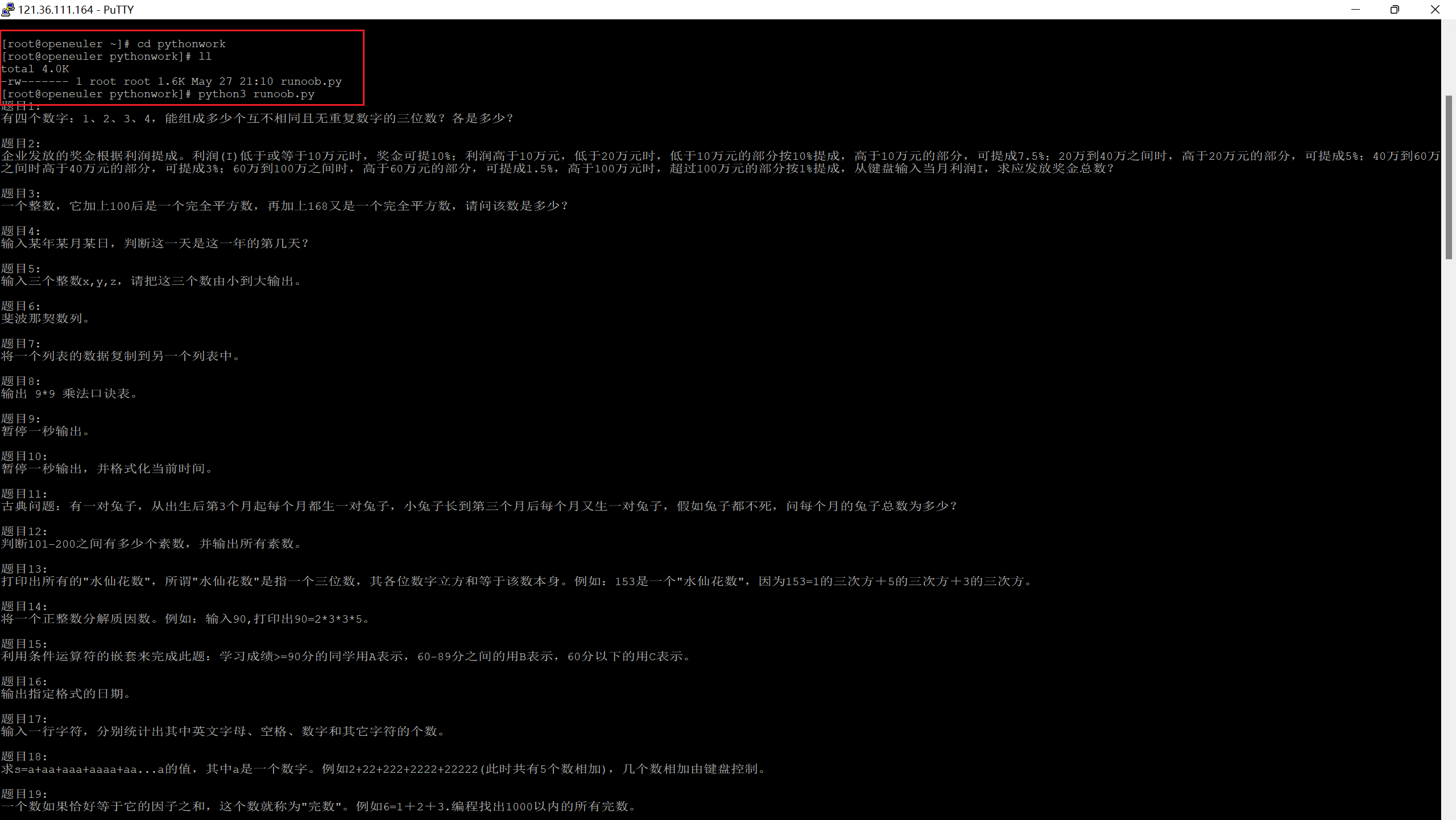

实验结束。
五、实验过程中遇到的问题和解决过程
问题一:上完课,对网络爬虫一知半解
解决1:花了两天课余时间看网课,认真学习爬虫,为本项目打下基础。
问题二:不知道如何将网址
中的普遍规律和差异“1” “2”体现在程序中
解决:上网查阅相关python字符串的表示方法,了解到有一种表示方法是‘%s’%x,意思是将内容x填充到%s的地方,成功解决问题。
问题三:不知道如何获取头文件信息
解决3:上网查资料得,在爬取的网站界面按F12进入开发者工具DevTools,点击网络,再刷新页面,点击停止记录网络日志,点击最开始的网络活动,就可以看到所有的请求信息。
问题四:使用html.xpath()提取文本的时候发生错误
解决4:一处提取规则不规范,改正后正常运行。
问题五:无法在ECS服务器安装lxml
解决5:询问同学,得知云服务器python自带的系统pip安装不了,通过在云服务器执行命令
wget https://files.pythonhosted.org/packages/1a/04/d6f1159feaccdfc508517dba1929eb93a2854de729fa68da9d5c6b48fa00/setuptools-39.2.0.zip unzip setuptools-39.2.0.zip cd setuptools-39.2.0 python3 setup.py build wget https://files.pythonhosted.org/packages/ae/e8/2340d46ecadb1692a1e455f13f75e596d4eab3d11a57446f08259dee8f02/pip-10.0.1.tar.gz tar xf pip-10.0.1.tar.gz cd pip-10.0.1 python3 setup.py install
成功安装pip,成功下载lxml。
六、参考资料
IndexError: list index out of range 错误原理及解决方法(python)_于科技人文间徘徊的博客-CSDN博客
with open() as f:用法_何小智的博客-CSDN博客
python爬虫之xpath解析(附实战)_李富贵要上岸985的博客-CSDN博客_python xpath
python Request库的get()方法_星河呀的博客-CSDN博客_requests.get
lxml基本用法总结_kikay的博客-CSDN博客_lxml
七、课程小结
总体来说,python这门课,令我印象深刻,十分难忘。
Python是我接触到第一门的高级计算机语言,也是我目前最喜欢的计算机语言。相比C语言,python没有那么多繁重复杂、需要严格遵守的语法规则,不需要在程序开始时导入库函数,仅靠简简单单的缩进,就能将循环体、条件判断语句的内外部区分开来。另外,python还有强大无比的系统内置库和第三方外置库,只需要下载之后导入,就能享受到相比C语言无尽的便捷。毫无疑问,python现已成为主流的计算机编程语言。
我第一次接触python是在高考完的那个暑假。从繁重学业中解放出来的我,突然感觉到一阵空虚。为了不使自己的暑假一无所获,我买了图灵系列的python从入门到实践一书,而这也是我梦的开端。通过python,我逐渐学习数字、字符的表示,逐渐深入了解字符串(string)、列表(list)、元组(tuple)、字典(dictionary)和集合(set)五大数据结构类型。在我的同学们一起出门聚餐、开派对、游玩,享受高中最后的暑假的时候,我会因为弄懂for循环语句,理清函数的用法,明白类的意义,成功下载pygame并运行第一个python小游戏而欣喜不已,我的同学们也渐渐因为我了解他们不知道的知识,而投来羡慕的目光。就这样,这门神奇的语言陪伴了我度过高三暑假。
在准备选大一下学期的选修课的时候,我毫不犹豫地选修了王志强老师的python程序设计。到了课堂上我才愈发觉得人外有人、天外有天。python是一片海洋,而我只不过是在海边因为拾到几个贝壳而沾沾自喜的小孩子。我之前所学的知识,只不过是一点皮毛,基础中的基础罢了。老师在最后几次课中,在所学知识基础上做出了一定的拓展,不仅讲述了re模块正则表达式的应用,而且讲授了socket套接字,也就是应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯;而且讲述了网络爬虫,能够在短时间内爬取大量的网站资料。在跟着老师一步一步操作socket套接字,并且在自己创建的服务器端和客户端第一次成功实现对话的时候,我别提有多高兴了,但更多的是为python的强大所折服。这是我第一次见到python不仅能在本地运行无网络程序,更能连接两台主机,实现交互;在讲网络爬虫的时候,我更是震惊不已。在我以往的观念中,能写代码获取网站信息的都只是电影中无所不能的网络工程师,没想到利用python,竟然能够如此轻而易举地做成我想都不敢想的事情!在结课之后,为了完成本次大作业,我又花了三天左右的时间学习网络爬虫,抓住每一次下课的间隙,吸收着无尽的知识。渐渐地,我对爬虫的整个过程有了一定的了解,并在不断的查阅资料和咨询同学中,完成了本次大作业。当我自己写的程序运行成功之后,那种快乐是只有我自己能体会到的。
说起来,我对python掌握的东西还远远不够。虽然结课了,但是我还是会将对Python的热爱一直保存下去。感谢老师使我懂得,学习计算机语言,不能光啃书本,更要不停地操作实践。程序报错了不要灰心,仔细查找错误原因并加以改正,如此循环往复,在你成功运行程序的那一刻,你的个人水平也会得到很大的提高!
感谢老师的悉心指导!希望以后有机会还能选老师的计算机选修课!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号