

【生产案例】点赞数、排行榜、未读消息数(含B站方案)
总结:
-
评论未读、@未读、赞未读等一对一关系的未读数可以使用通用计数方案来解决;
通用计数器:一个用户一类的计数用一个字段存储就可以了,相对简单,就是存储量很大
-
在系统通知未读、全量用户打点等存在有限的共享存储的场景下,可以通过记录用户上次操作的时间或者偏移量,来实现未读方案;
内容共享,通过最后一次读时间或则 id 的偏移量来计算,要注意的是:这种未读不是指你有 10 篇没有读的文章,读取一篇就减少 1 这种未读统计,而是你总共有多少未读消息数量,点击后就重置为 0 了
-
信息流未读方案最为复杂,采用的是记录用户博文数快照的方式
这里和系统全量打点的方式类似,也是点击未读后,计数器就重置为 0 了。但是它有关系计算这是和全量打点方式不一样的地方
一、点赞数&排行榜
-
数据库:使用关系型数据库(如MySQL, PostgreSQL) 存储博客文章、用户等基本信息。
点赞/取消点赞逻辑:
set 数据结构来记录用户对文章的点赞状态。例如,使用文章ID作为key,用户ID作为value,存储到set 中,判断用户是否点赞过某篇文章。-
点赞: 当用户点击点赞按钮时,
- 检查Redis 中是否已存在该用户对该文章的记录。
- 如果不存在,则将用户ID添加到文章ID对应的Redis set 中,并在数据库中更新点赞数。
- 如果已存在,则不执行任何操作。
-
取消点赞: 当用户点击取消点赞按钮时,
- 检查Redis 中是否存在该用户对该文章的记录。
- 如果存在,则将用户ID从文章ID对应的Redis set 中删除,并在数据库中更新点赞数。
- 如果不存在,则不执行任何操作。
点赞计数
INCR 和 DECR 命令来原子地增加或减少文章的点赞数,或者直接在数据库中更新点赞数。 排行榜实现
-
Redis Zset:可以使用Redis 的
Zset数据结构来实现排行榜。Zset允许你根据score (点赞数) 对成员(文章ID) 进行排序,并提供获取前N名等功能。 -
数据库查询:也可以在数据库中直接根据点赞数进行排序查询,然后获取前N名。
-
实时性与性能:对于高并发场景,Redis 的
Zset更适合实时性要求高的排行榜。如果点赞数更新不频繁,数据库查询也可以满足需求。
生产案例:B站千亿级点赞系统服务架构设计
key-value = count:patten:{business_id}:{message_id} - {likes},{disLikes}
用业务ID和该业务下的实体ID作为缓存的Key,并将点赞数与点踩数拼接起来存储以及更新* 用mid与业务ID作为key,value则是一个ZSet,member为被点赞的实体ID,score为点赞的时间。当改业务下某用户有新的点赞操作的时候,被点赞的实体则会通过 zadd的方式把最新的点赞记录加入到该ZSet里面来
为了维持用户点赞列表的长度(不至于无限扩张),需要在每一次加入新的点赞记录的时候,按照固定长度裁剪用户的点赞记录缓存。该设计也就代表用户的点赞记录在缓存中是有限制长度的,超过该长度的数据请求需要回源DB查询整个点赞服务的系统可以分为五个部分 -- 架构图参考上述链接
1、流量路由层(决定流量应该去往哪个机房)
2、业务网关层(统一鉴权、反黑灰产等统一流量筛选)
3、点赞服务(thumbup-service),提供统一的RPC接口
4、点赞异步任务(thumbup-job)
5、数据层(db、kv、redis)
二、未读消息数
场景1:系统消息的未读数
-
用户访问系统通知页面需要设置未读数为 0,我们需要将用户最近看过的通知 ID 设置为最新的一条系统通知 ID;
-
如果最近看过的通知 ID 为空,则认为是一个新的用户,返回未读数为 0;
-
对于非活跃用户,比如最近一个月都没有登录和使用过系统的用户,可以把用户最近看过的通知 ID 清空,节省内存空间。
这是一种比较通用的方案,即节省内存,又能尽量减少获取未读数的延迟。 这个方案适用的另一个业务场景是全量用户打点的场景,比如微博的小红点。
- 为每一个用户存储一个时间戳,代表最近点过这个红点的时间,用户点了红点,就把这个时间戳设置为当前时间;
- 记录一个全局的时间戳,这个时间戳标识最新的一次打点时间,如果你在后台操作给全体用户打点,就更新这个时间戳为当前时间。
- 而我们在判断是否需要展示红点时,只需要判断用户的时间戳和全局时间戳的大小,如果用户时间戳小于全局时间戳,代表在用户最后一次点击红点之后又有新的红点推送,那么就要展示红点,反之,就不展示红点了。
场景2:关注人的信息流的未读数
在现在的社交系统中,关注关系已经成为标配的功能,而基于关注关系的信息流也是一种非常重要的信息聚合方式
信息流的未读数之所以复杂主要有这样几点原因。
-
首先,微博的信息流是基于关注关系的,未读数也是基于关注关系的
就是说,你关注的人发布了新的微博,那么你作为粉丝未读数就要增加 1。如果微博用户都是像我这样只有几百粉丝的 「小透明」 就简单了,你发微博的时候系统给你粉丝的未读数增加 1 不是什么难事儿。但是对于一些动辄几千万甚至上亿粉丝的微博大 V 就麻烦了,增加未读数可能需要几个小时。假设你是杨幂的粉丝,想了解她实时发布的博文,那么如果当她发布博文几个小时之后,你才收到提醒,这显然是不能接受的。所以未读数的延迟是你在设计方案时首先要考虑的内容。
-
其次,信息流未读数请求量极大、并发极高,这是因为接口是客户端轮询请求的,不是用户触发的。也就是说,用户即使打开微博客户端什么都不做,这个接口也会被请求到。在几年前,请求未读数接口的量级就已经接近每秒 50 万次,这几年随着微博量级的增长,请求量也变得更高。而作为微博的非核心接口,我们不太可能使用大量的机器来抗未读数请求,因此,如何使用有限的资源来支撑如此高的流量是这个方案的难点。
-
最后,它不像系统通知那样有共享的存储,因为每个人关注的人不同,信息流的列表也就不同,所以也就没办法采用系统通知未读数的方案。
-
在通用计数器中记录每一个用户发布的博文数;
-
在 Redis 或者 Memcached 中记录一个人所有关注人的博文数快照,当用户点击未读消息重置未读数为 0 时,将他关注所有人的博文数刷新到快照中;他关注所有人的博文总数减去快照中的博文总数就是他的信息流未读数。
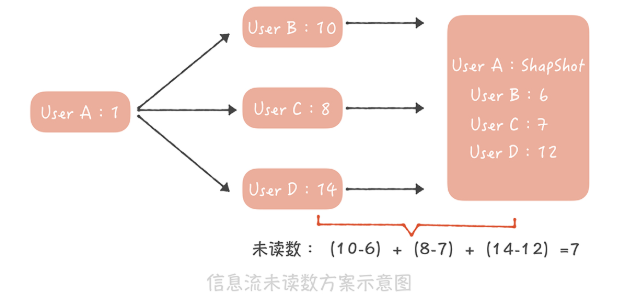
用户 A,像上图这样关注了用户 B、C、D,其中 B 发布的博文数是 10,C 发布的博文数是 8,D 发布的博文数是 14,而在用户 A 最近一次查看未读消息时,记录在快照中的这三个用户的博文数分别是 6、7、12,因此用户 A 的未读数就是(10-6)+(8-7)+(14-12)=7。
这个方案设计简单,全内存操作,性能足够好,能够支撑比较高的并发,事实上微博团队仅仅用 16 台普通的服务器就支撑了每秒接近 50 万次的请求,这就足以证明这个方案的性能有多出色,因此,它完全能够满足信息流未读数的需求。
方案缺陷:比如说快照中需要存储关注关系,如果关注关系变更的时候更新不及时,那么就会造成未读数不准确;快照采用的是全缓存存储,如果缓存满了就会剔除一些数据,那么被剔除用户的未读数就变为 0 了。但是好在用户对于未读数的准确度要求不高(未读 10 条还是 11 条,其实用户有时候看不出来),因此,这些缺陷也是可以接受的。
通过分享未读数系统设计这个案例,我想给你一些建议:
-
缓存是提升系统性能和抵抗大并发量的神器,像是微博信息流未读数这么大的量级我们仅仅使用十几台服务器就可以支撑,这全都是缓存的功劳;
-
要围绕系统设计的关键困难点想解决办法,就像我们解决系统通知未读数的延迟问题一样;
-
合理分析业务场景,明确哪些是可以权衡的,哪些是不行的,会对你的系统设计增益良多,比如对于长久不登录用户,我们就会记录未读数为 0,通过这样的权衡,可以极大地减少内存的占用,减少成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号