Visual Tracking with Fully Convolutional Networks
本文作者提出了一种新的全卷积神经网络的方法来做视觉跟踪。
作者不是简单的将卷积神经网络看做是一个黑盒的特征提取器。而是在线下通过大量的图像数据,深入研究了CNN特征的性能。
通过研究得到的一些发现激发了作者设计出文中的跟踪系统。卷积神经网络的不同层上的特征在不同层次上描写叙述着目标的不同的特征。在网络的顶层编码着很多其它的语义特征。它可以充当一个类别检測器。
然而更底层则携带者很多其它的可区分性的特征,它可以更好的将目标从相似的外观上区分开来。可以同一时候利用这两个层次上的特征来做跟踪。作者还提出了一种特征图谱选择的方法。它可以去掉噪声和不相关的特征图谱。从而降低了计算的复杂度,提高了跟踪的精度。
对于给定的有限的在线训练数据,以及深度模型的复杂性,直接将CNNs应用到跟踪的问题上效果是不好的。
由于CNN的性能依靠大规模的训练。为了更好的利用CNN,所以作者就从在线跟踪的视角上深入的研究了CNN特征的性能。
通过深入研究。作者得到了几点发现,并激发作者设计出自己的跟踪系统。
第一点,CNN的不同层上的特征对于跟踪问题有不同的效果。顶层的特征捕获了目标的更加抽象的高层语义特征。
他们可以从不同的类别上区分目标。而且对于形变和遮挡有非常好的鲁棒性。
可是他们缺乏将目标从一些同样类别区分开来的能力。更底层则提供了更加具体的局部特征,它可以帮助我们将目标从干扰项中区分开来。可是,他们缺少对外观变化的鲁棒性。基于这些发现。作者提出了一种在跟踪过程中自己主动的转换使用这两层的特征。
第二点,预先在ImageNet上面训练的CNN特征可以非常好的区分通用的目标对象。
可是,对于一个特定的目标,并非全部的特征对于鲁棒的跟踪都是实用的。一些特征响应可能会是噪声。通过适当的特征选择。这些对于表达目标没实用的噪声特征会被清理掉,留下的特征可以更加精确的表达目标,而且抑制背景的响应。
本文的几点贡献:
1)、作者分析了从大规模图像分类任务上学习到的CNN的特征,发现了对于跟踪非常重要的性能。促进了进一步的理解CNN特征,而且设计了有效的基于CNN的跟踪器。
2)、作者提出了一种新的跟踪方法。它联合了两个不同卷积层。在处理激烈的外观变化和从相似的干扰项中区分目标上有相得益彰的效果。非常好的缓和了漂移的问题。
3)、提出了一种自己主动的选择有区分性的特征图谱。丢弃噪声和不相关的特征图谱,进一步的提高了跟踪的精度。
3、Deep Feature Analysis for Visual Tracking(深度特征分析for视觉跟踪)
分析深度表达对于理解深度学习的机制是非常实用的。作者的特征分析是基于一个16层的VGG网络。它是在ImageNet图像分类任务上预训练的,他有13个卷积层和3个全连接层。我们主要集中在conv4-3层(第10个卷积层)和conv5-3(第13个卷积层),这两层都会产生512个特征图谱。
发现一:虽然CNN特征图谱的感受也很大。可是激活的特征图谱很稀疏而且是局部的。激活的区域和语义目标区域是很相关的。
因为pooling层和卷积层,conv4-3和conv5-3层的感受野是很大的(各自是92*92和196*196)。特征图谱上仅仅有一些部分区域的值是非零的。这些非零值是局部化的。而且和图像的前景目标的位置是很符合的。作者也用了參考文献【26】中的方法来提取CNN特征的显著图。
这些显著图表明。输入的变化会导致在目标区域总的选择的特征图谱大幅度的添加。因此。特征图谱可以捕获和目标相关的视觉表达特征。这些证据表明,从图像分类任务中学习到的DNN特征是局部的,而且是和目标的视觉线索相关的。因此这些CNN特征可以被用来做目标定位的。
发现二:非常多CNN特征图谱是噪声或者是跟我们要从背景中区分特定目标任务无关的。
CNN特征描写叙述了各种各样的一般性的目标。他们可以检測丰富的视觉形态。可是,当我们跟踪一个特定的目标的时候。它应该集中在一个更小的视觉形态的子集上面,这样可以更好的将目标从背景中分离出来。大多数的特征图谱有一个非常小的或者为零的值。
因此,有非常多特征图谱是和目标没有关系的或者关系不大的。这样,我们就行通过选择的少量的特征图谱来做跟踪。而且性能不会退化。
发现三:不同层编码了不同类型的特征。高层捕获语义方面的目标类别特征,底层编码类内更有区分性的特征。
因为特征图谱的冗余,我们採用一种稀疏表达的机制来促进更好的视觉化。我们将通过网络得到的特征图谱
![]()

。改造成一个d维的向量,n表示特征图谱的数量。
![]()
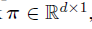
表示前景掩码。然后我们用特征图谱的一个子集来重建前景掩码。通过解例如以下方程式:
通过大量的实验分析,作者的到,conv4-3的特征图谱保存了很多其它中间层次的信息,可以更加精确的将属于同一类别的不同图像区分开来。可是。conv5-3可以将人脸和非人脸区分开来。这些结果激励我们要将这两种特征结合的用到更加鲁棒的视觉跟踪中。
4、提出的算法
1、对于一个给定的目标,特征图谱选择的过程是选择最相关的特征图谱。能避免过拟合。
2、一般的网络(GNet)是用选择的最相关的特征图谱来捕获目标的类别信息。
3、特殊的网络(SNet)是用来从具有相似外观的背景中区分目标。他用的也是选择出来的最相关的特征图谱。
4、一般的网络和特殊的网络都是在第一帧来初始化的,完毕目标对象的前景热图的回归。採取不同的在线更新策略。
5、对于新输入的一帧图像。感兴趣的区域包括目标和背景,他们会被送入网络。
6、依据一般网络和特殊的网络。会分别生成两个前景的热图。然后会依据两个热图分别对目标进行定位。
7、然后终于的目标是通过一个干扰项检測机制来决定步骤6中的哪一个热图会被利用。
4.1. 特征图谱的选择
文中提出的特征图谱选择的方法是基于目标的热图回归模型的,叫做sel-CNN。
sel-CNN模型在卷积层的后面包括一个dropout层。没有不论什么的非线性变换。将选择的特征图谱作为输入用来预測目标的热图M,他是一个二维高斯分布。以目标的真实值为中心。这个模型通过最小化预測值和真实值M的均方误差来训练。
通过反向传播收敛參数学习以后,我们就固定模型的參数,然后依据他们对损失函数的影响来选择特征图谱。对于输入的特征图谱,首先给他向量化。
然后特征图谱对损失函数的影响能够通过计算例如以下一个二阶泰勒展开式:
![]()

各自是目标函数相对于输入特征图谱的一阶和二阶的导数。特征图谱中的元素的数量特别的大(>270000)。计算全部二阶导数的复杂度大概是O(270000*270000),他是很耗时的。
我们用一个对角矩阵来近似海森矩阵,这种话公式【5】中右边的第三项就能够忽略了。这样一来,一阶导数和二阶导数就能够通过反向传播来计算了。
全部的特征图谱依据他们的重要性用降序的方式来排序,然后选择前K个特征图谱。这些选择的特征图谱对目标函数有着非常大的影响。因此他们和跟踪任务最相关。
我们的特征图谱的选择方法能够在线进行。在我们的试验中,我们只在第一帧上进行特征选择就得到了非常好的效果。
这要归功于鲁棒的CNN特征。
二次逼近的想法能够追溯到1989.它主要是降低參数的数量和提快速度。然而我们的目标是去除掉噪声特征图谱来提高跟踪的精度。
4.2. 目标定位
在第一帧图像上进行了特征图谱的选择之后,我们分别建立了GNet和SNet。
这两个网络有同样的结构,包括两个额外的卷积层。
第一个卷积层的卷积核的大小为9*9。输出的36特征图谱作为下一层的输入。第二个卷积层的卷积核的大小为5*5,输出前景的热图。选择ReLU作为这两层的非线性变换。
SNet和GNet在第一帧通过最小化例如以下的损失函数的来初始化的:
注意,sel-CNN和GNet和SNet是具有不同的CNN结构的。
sel-CNN的结构很的简单,避免利用噪声特征图谱来拟合目标函数。可是GNet和SNet就相对复杂一点。
由于噪声特征图谱已经在特征图谱选择阶段被去除了,更复杂的模型能够促进更加精确的跟踪。
对于新给定的一帧图像,我们先圈出感兴趣的区域。通过前向传播将感兴趣的区域通过网络。我们会分别从GNet和SNet网络中得到前景热图。目标首先会被GNet网络得到的热图定位。目标的位置信息为
x,y,sigma 分别表示目标的中心坐标和尺度。
给定的上一帧目标的位置![]()
 。我们如果当前帧的候选目标的位置服从高斯分布:
。我们如果当前帧的候选目标的位置服从高斯分布:
![]()
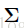
是对角协方差矩阵,表明定位參数的差异。
第i个候选目标的置信度的计算方法,候选区域中的全部的热图值的加和。有最高置信度得分的候选区域被GNet预測为目标。
GNet是基于conv5-3层的,他捕获了语义特征,对于类内变化具有鲁棒性。因此。GNet网络生成的前景热图会将目标和具有相似的外观的干扰的背景都标注出来。
为了预防跟踪器漂移到背景上面。我们进一步的利用干扰项的检測机制来决定终于目标的位置。
我们用![]()
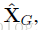 表示GNet网络预測的目标的区域,在热图中对应的目标区域表示为
表示GNet网络预測的目标的区域,在热图中对应的目标区域表示为
![]() 。干扰项发生在背景的概率是通过在目标区域的外面和里面的置信度的比例来预计的。
。干扰项发生在背景的概率是通过在目标区域的外面和里面的置信度的比例来预计的。
![]()
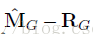
代表的是热图中的背景区域。
当概率![]()
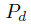 小于一个阈值的时候,我们觉得没有干扰项,就用GNet预測的目标的位置作为终于的位置。
小于一个阈值的时候,我们觉得没有干扰项,就用GNet预測的目标的位置作为终于的位置。
否则,我们利用SNet网络预測的结果作为终于的结果。
4.3. 在线更新
为了避免在线更新时背景噪声的进入,我们在初始化之后固定GNet。仅仅更新SNet。
SNet的更新遵循下面两个不同的规则:适应性规则和可区分性规则,这是为了使SNet网络可以适应目标的外观的变化。而且提高它区分前景和背景的能力。依据适应性规则,我们每隔20帧用一段时间间隔中置信度最高的跟踪结果来微调SNet网络。基于可区分性的规则,当我们使用公式【9】检測干扰项的时候,SNet要用第一帧跟踪的结果和当前帧来更新,通过最小化例如以下公式:
![]()
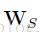
表示的是SNet网络的卷积权重。
(x,y)表示的是空间坐标。
公式【10】中的第二项相当于是在第一帧中定位目标的损失。
当当前帧有干扰项的时候,或者目标遭受到非常严重的遮挡的时候。对于学习目标的外观来说,这个预计的目标区域是不可靠的。因此,我们选择了一个保守的机制,通过添加第一帧来监督更新,这样一来,我们的学习模型依旧可以捕获到第一帧目标的外观。公式【10】的第三项去除了不可靠的目标区域的损失,仅仅考虑了当前帧中背景区域的损失。它可以强化模型将很多其它的形变干扰看作是背景。合并公式【10】中的第二项和第三项可以帮助SNet网络更好的将目标从背景中分离开来,而且减轻因为遮挡和干扰项带来的模型的退化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号