
从Podman开始一步步构建Hadoop开发集群
摘要
工作关系经常开发大数据相关程序,Hive、Spark、Flink等等都会涉及,为方便随时调试程序便有了部署一个Hadoop集群的想法。在单个主机上部署集群肯定要用到容器相关技术,本人使用过Docker和Podman,在资源和性能比较有限的笔记本上面Podman的总体表现比较不错,而且还可以拉取Docker上的镜像。Podman的安装过程比较简单这里先不赘述,下面一步步展示基于Podman的Hadoop集群安装过程。
软件系统版本
| 系统/软件 | 版本 | 说明 |
|---|---|---|
| Podman Desktop | 1.20.2 | |
| Debian | 9 (stretch) | 10(buster)默认支持的JDK 11以上版本,也通过其他方式安装JDK 8 |
| MySQL | 5.7.42 | |
| Hadoop | 3.3.6 | |
| Hive | 3.1.3 | |
| Spark | 3.5.6 | |
| Flink | 1.20.2 |
Hadoop角色结构
resourcemanager好像必须跟namenode在同一台机器
零、创建容器
创建debian 9容器并指定ip和主机名称
podman run -dt --name node01 --hostname node01.data.org --ip 10.88.0.101 --add-host "node02;node02.data.org:10.88.0.102" --add-host "node03;node03.data.org:10.88.0.103" --cap-add IPC_LOCK --cap-add NET_RAW docker.io/library/debian:9.9 bash
podman run -dt --name node02 --hostname node02.data.org --ip 10.88.0.102 --add-host "node01;node01.data.org:10.88.0.101" --add-host "node03;node03.data.org:10.88.0.103" --cap-add IPC_LOCK --cap-add NET_RAW docker.io/library/debian:9.9 bash
podman run -dt --name node03 --hostname node03.data.org --ip 10.88.0.103 --add-host "node01;node01.data.org:10.88.0.101" --add-host "node02;node02.data.org:10.88.0.102" --cap-add IPC_LOCK --cap-add NET_RAW docker.io/library/debian:9.9 bash
2023年以后Debian官方源地址已经修改,系统自带的源会出现404报错问题,更新官方源或者网上搜索国内公共源。
# 设置系统时区和语言
rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
# 更新镜像源
mv /etc/apt/sources.list /etc/apt/sources.list.old
cat > /etc/apt/sources.list << EOF
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch-backports main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
EOF
apt update
执行apt update更新时如果提示PUBLIC KEY的问题执行下面语句
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 467B942D3A79BD29(更换为提示的KEY)
# 安装必须软件
apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \
openjdk-8-jdk \
net-tools \
curl \
netcat \
gnupg \
libsnappy-dev \
openssh-server \
openssh-client \
sudo \
&& rm -rf /var/lib/apt/lists/*
# 创建hadoop用户并添加sudo权限
chmod 640 /etc/sudoers
groupadd --system --gid=10000 hadoop && useradd --system --home-dir /home/hadoop --uid=10000 --gid=hadoop hadoop && echo "hadoop ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
# 生成秘钥,把node01公钥导入node02和node03中,配置免密登录
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 允许root登录,启动ssh并允许开机启动
echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
/etc/init.d/ssh start
update-rc.d ssh enable
一、Hadoop基础环境安装
hadoop软件下载安装
设置环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export HADOOP_VERSION=3.3.6
export HADOOP_HOME=/opt/hadoop-$HADOOP_VERSION
echo "export LANG=zh_CN.UTF-8" >> /etc/profile
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> /etc/profile.d/hadoopbase.sh
echo "export JRE_HOME=${JAVA_HOME}/jre" >> /etc/profile.d/hadoopbase.sh
echo "export CLASSPATH=.:\${JAVA_HOME}/lib:\${JRE_HOME}/lib" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_VERSION=3.3.6" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_HOME=/opt/hadoop-3.3.6" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_CONF_DIR=/etc/hadoop" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_CLASSPATH=\$HADOOP_HOME/etc/hadoop:\$HADOOP_HOME/share/hadoop/common/lib/*:\$HADOOP_HOME/share/hadoop/common/*:\$HADOOP_HOME/share/hadoop/hdfs:\$HADOOP_HOME/share/hadoop/hdfs/lib/*:\$HADOOP_HOME/share/hadoop/hdfs/*:\$HADOOP_HOME/share/hadoop/mapreduce/*:\$HADOOP_HOME/share/hadoop/yarn:\$HADOOP_HOME/share/hadoop/yarn/lib/*:\$HADOOP_HOME/share/hadoop/yarn/*" >> /etc/profile.d/hadoopbase.sh
echo "export PATH=${JAVA_HOME}/bin:$HADOOP_HOME/bin/:\$PATH" >> /etc/profile.d/hadoopbase.sh
source /etc/profile
创建数据目录
mkdir -p /data/hadoop-data
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/nameNode
mkdir -p /data/hadoop/dataNode
安装Hadoop
# 导入hadoop安装包校验KEY
curl -O https://dist.apache.org/repos/dist/release/hadoop/common/KEYS
gpg --import KEYS
# hadoop 版本
set -x \
&& curl -fSL "https://www.apache.org/dist/hadoop/common/hadoop-$HADOOP_VERSION/hadoop-$HADOOP_VERSION.tar.gz" -o /tmp/hadoop.tar.gz \
&& curl -fSL "https://www.apache.org/dist/hadoop/common/hadoop-$HADOOP_VERSION/hadoop-$HADOOP_VERSION.tar.gz.asc" -o /tmp/hadoop.tar.gz.asc \
&& gpg --verify /tmp/hadoop.tar.gz.asc \
&& tar -xf /tmp/hadoop.tar.gz -C /opt/ \
&& rm /tmp/hadoop.tar.gz*
ln -s $HADOOP_HOME/etc/hadoop /etc/hadoop
mkdir $HADOOP_HOME/logs
node01节点修改配置
- /etc/hadoop/hadoop-env.sh
#文件最后添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- /etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
- /etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dataNode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- /etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
- /etc/hadoop/yarn-site.xml resourcemanager好像必须跟namenode在同一台机器
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node01:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
- /etc/hadoop/workers
node01
node02
node03
- 拷贝到其他节点
scp -r /opt/hadoop-3.3.6 root@node02:/opt/
scp -r /opt/hadoop-3.3.6 root@node03:/opt/
# 分别在node02和node03节点创建软链接
ln -s $HADOOP_HOME/etc/hadoop /etc/hadoop
- 初始启动前操作
# 在node01上格式化namenode
hdfs namenode -format
- 启动服务
- 在node01上执行
bash $HADOOP_HOME/sbin/start-all.sh
bash $HADOOP_HOME/sbin/stop-all.sh
- 启动历史服务查看历史日志(在一台机器上运行即可)
bin/mapred --daemon start historyserver
- 检查服务启动动是否正常
jps
打开浏览器验证
- HDFS上传文件
http://node01:50070/ 验证HDFS上传文件
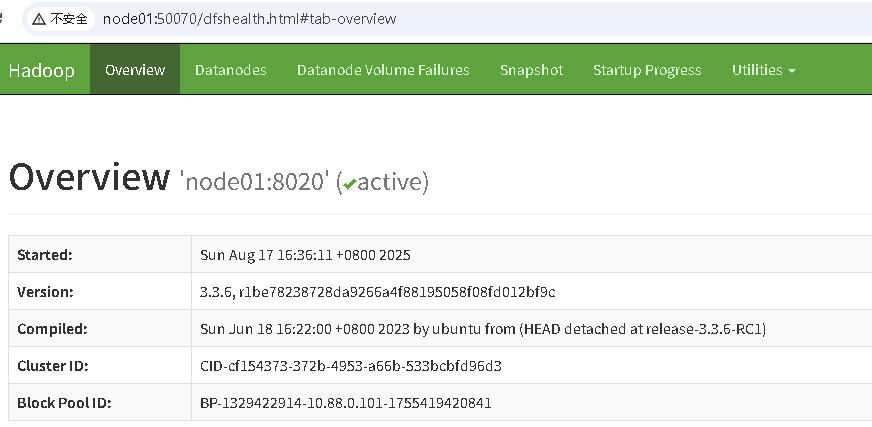
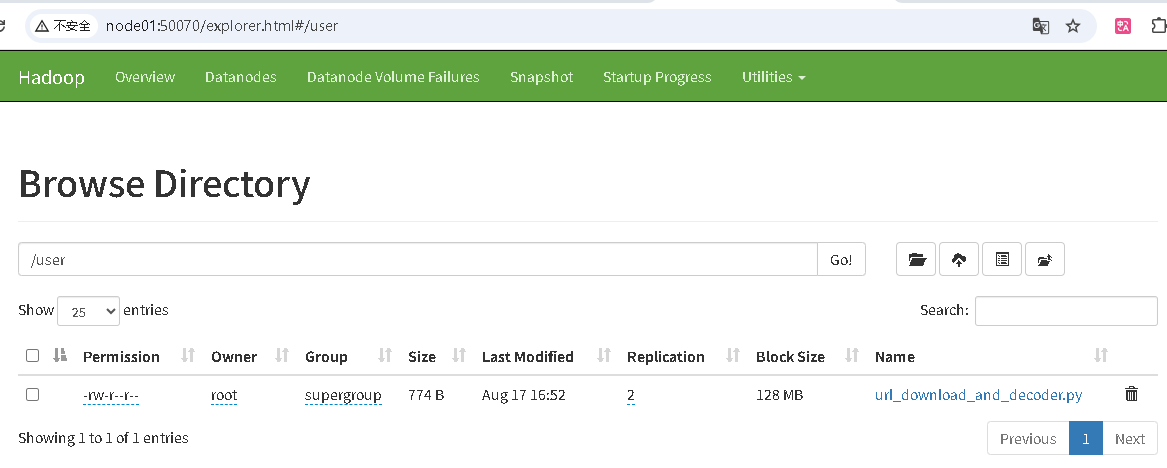
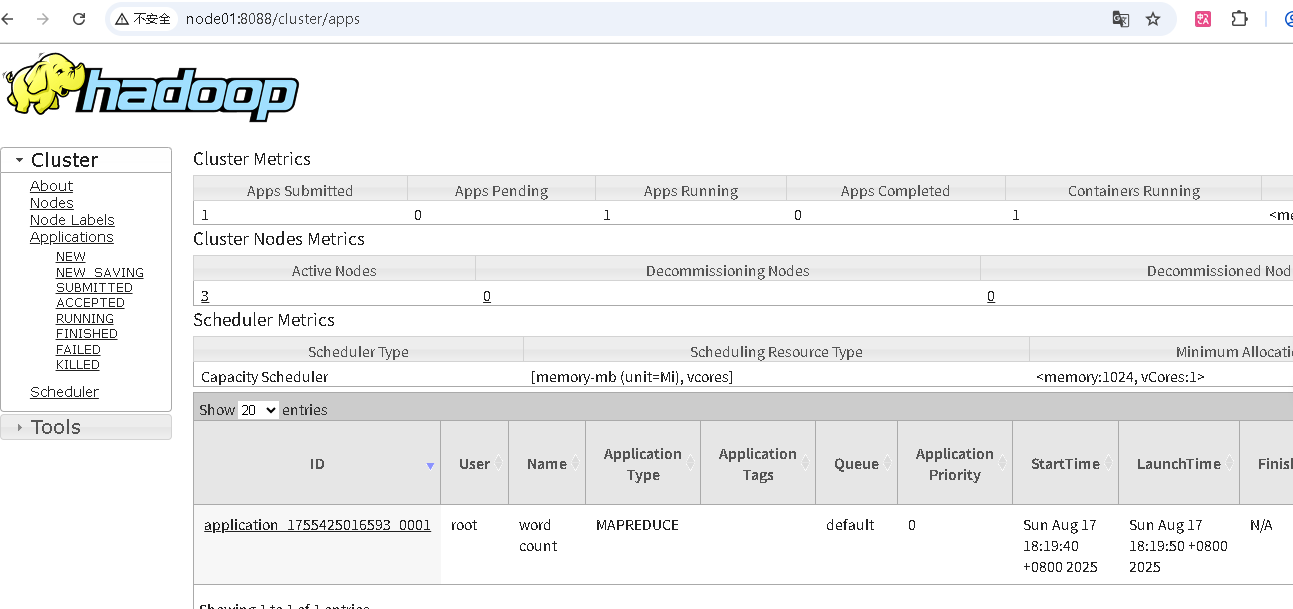
- mapreduce跑wordcount任务验证
运行wordcount测试样例统计一个文本用词数量,文本要先上传到HDFS
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /tmp/harrypotter.txt /output/harr
output目录下载和查看输出结果
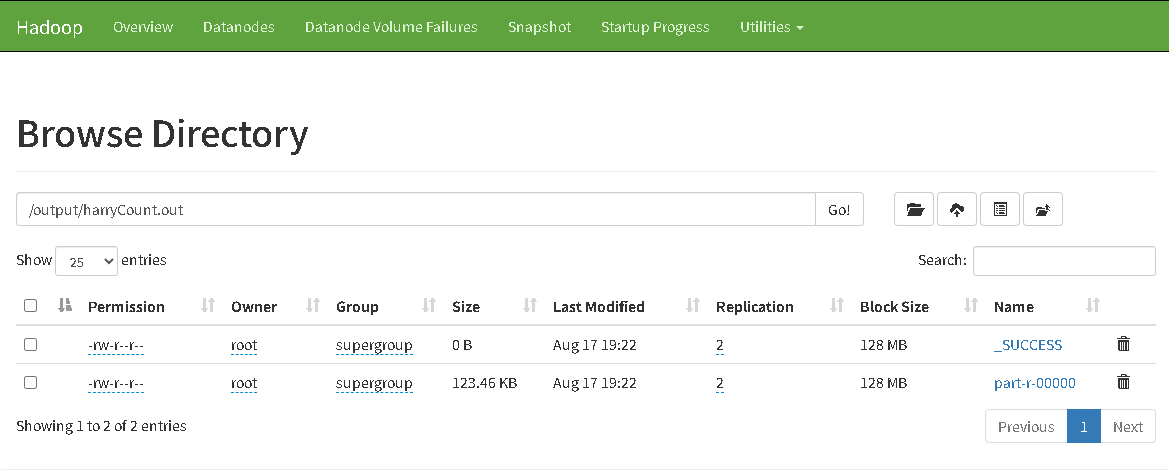
至此Hadoop平台的搭建已经完成。基础的Yarn、HDFS、MapReduce功能已经齐全,后面在此基础上完成Hive、Spark和Flink环境部署。
二、Hive安装
Hive部署有三种模式,这里采用远程模式将元数据保存在单独节点的MySQL数据库上。Hive服务部署在node03节点,客户端链接node03的10000端口号就可以使用Hive服务。
1、MySQL 安装
使用mysql:5.7.42-debian镜像安装MySQL环境
podman run -dt --name rmdb01 --hostname rmdb01.data.org --ip 10.88.0.111 `
--add-host "node01;node01.data.org:10.88.0.101" `
--add-host "node02;node02.data.org:10.88.0.102" `
--add-host "node03;node03.data.org:10.88.0.103" `
--cap-add IPC_LOCK --cap-add NET_RAW `
-e MYSQL_ROOT_PASSWORD=123456 `
-e DEFAULT_CHARSET=utf8mb4 `
-e DEFAULT_COLLATION=utf8mb4_unicode_ci `
-p 3306:3306 -p 33060:33060 `
docker.io/library/mysql:5.7.42-debian mysqld
登录容器设置时区
echo "default-time-zone = '+08:00'" >> /etc/mysql/mysql.conf.d/mysqld.cnf
rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
登录MySQL创建hive用户,设置授权
create database metastore character set utf8mb4 collate utf8mb4_unicode_ci;
create user 'hive'@'%' identified by '123456';
grant all on metastore.* to 'hive'@'%';
2、Hive安装
登录node03节点,下载并解压hive安装包
curl -O https://archive.apache.org/dist/hive/KEYS
gpg --import KEYS
curl -fSL "https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz" -o /tmp/hive.tar.gz
curl -fSL "https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz.asc" -o /tmp/hive.tar.gz.asc
gpg --verify /tmp/hive.tar.gz.asc
tar -xf /tmp/hive.tar.gz -C /opt/ && rm /tmp/hive.tar.gz*
mv /opt/apache-hive-3.1.3-bin /opt/hive-3.1.3
echo "export HIVE_HOME=/opt/hive-3.1.3" >> /etc/profile.d/hivebase.sh
source /etc/profile
下载mysql connector包
curl -fSL "https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar" -o /opt/hive-3.1.3/lib/mysql-connector-java-8.0.30.jar
HDFS创建临时目录和hive数据存储目录并授权
hdfs dfs -mkdir /tmp
hdfs dfs -chmod g+w /tmp
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod g+w /user/hive/warehouse
复制hive-site.xml模板,修改下面参数
cp conf/hive-default.xml.template conf/hive-site.xml
<property>
<name>system:java.io.tmpdir</name>
<value>/data/hive-data/tmp</value>
</property>
<property>
<name>system:user.name</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://rmdb01:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
添加MySQL数据库IP地址映射,初始化元数据
echo "10.88.0.111 rmdb01 rmdb01.data.org" >> /etc/hosts
cd /opt/hive-3.1.3
bin/schematool -initSchema -dbType mysql -verbose
元数据初始化成功后登录MySQL数据库修改几个字段的字符集,解决hive元数据中文显示乱码问题
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8mb4;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8mb4;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8mb4;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8mb4;
开启hive服务
cd /opt/hive-3.1.3
nohup bin/hive --service metastore > /dev/null 2>&1 &
nohup bin/hive --service hiveserver2 > /dev/null 2>&1 &
登录hive测试
bin/hive
执行hql操作建表、查询,登录http://node01:8088/ 页面查看执行日志
create database dwintdata;
create table dwintdata.student_info (
id bigint comment 'ID',
name string comment '姓名',
age int comment '年龄',
sex string comment '性别,1为男0为女',
descript string comment '特长描述'
) comment '学生信息表'
stored as orc;
insert into dwintdata.student_info
values (1, 'zhangsan', 18, '1', '三好学生')
,(2, 'lisi', 18, '1', '体育生')
,(3, 'zhaolei', 19, '1', '爱好打篮球')
,(4, 'qianlong', 19, '0', '喜欢画画')
,(5, 'sunpier', 17, '0', '喜欢跳舞')
,(6, 'zhoubo', 17, '1', '活泼开朗')
;
select *
from dwintdata.student_info
;
select min(age), max(age)
from dwintdata.student_info
;
select age, count(1)
from dwintdata.student_info
group by age
;

三、Spark
登录node01节点,下载安装spark安装包
curl -O https://archive.apache.org/dist/spark/KEYS
gpg --import KEYS
curl -fSL "https://archive.apache.org/dist/spark/spark-3.5.6/spark-3.5.6-bin-without-hadoop.tgz" -o /tmp/spark.tar.gz
curl -fSL "https://archive.apache.org/dist/spark/spark-3.5.6/spark-3.5.6-bin-without-hadoop.tgz.asc" -o /tmp/spark.tar.gz.asc
gpg --verify /tmp/spark.tar.gz.asc
tar -xf /tmp/spark.tar.gz -C /opt/ && rm /tmp/spark.tar.gz*
mv /opt/spark-3.5.6-bin-without-hadoop /opt/spark-3.5.6
配置Spark运行环境和默认配置,复制到其他节点
# 配置spark home
echo "export SPARK_HOME=/opt/spark-3.5.6" >> /etc/profile.d/sparkbase.sh
source /etc/profile
scp /etc/profile.d/sparkbase.sh root@node02:/etc/profile.d
scp /etc/profile.d/sparkbase.sh root@node03:/etc/profile.d
# 在所有节点创建数据目录
mkdir -p /data/spark-data/
ssh root@node02 mkdir -p /data/spark-data
ssh root@node03 mkdir -p /data/spark-data
# 配置spark-env.sh
cd /opt/spark-3.5.6
cp conf/spark-env.sh.template conf/spark-env.sh
echo "SPARK_MASTER_HOST=node01" >> conf/spark-env.sh
echo "SPARK_LOCAL_DIRS=/data/spark-data" >> conf/spark-env.sh
echo "export SPARK_DIST_CLASSPATH=\$HADOOP_HOME/etc/hadoop/*:\$HADOOP_HOME/share/hadoop/common/lib/*:\$HADOOP_HOME/share/hadoop/common/*:\$HADOOP_HOME/share/hadoop/hdfs/*:\$HADOOP_HOME/share/hadoop/hdfs/lib/*:\$HADOOP_HOME/share/hadoop/hdfs/*:\$HADOOP_HOME/share/hadoop/yarn/lib/*:\$HADOOP_HOME/share/hadoop/yarn/*:\$HADOOP_HOME/share/hadoop/mapreduce/lib/*:\$HADOOP_HOME/share/hadoop/mapreduce/*:\$HADOOP_HOME/share/hadoop/tools/lib/*" >> conf/spark-env.sh
# 配置-spark-defaults.conf
cp conf/spark-defaults.conf.template conf/spark-defaults.conf
echo "spark.driver.memory 1g" >> conf/spark-defaults.conf
echo "spark.driver.cores 1" >> conf/spark-defaults.conf
echo "spark.executor.memory 512mb" >> conf/spark-defaults.conf
echo "spark.executor.cores 1" >> conf/spark-defaults.conf
# 复制spark目录到其他节点
scp -r /opt/spark-3.5.6 root@node02:/opt/
scp -r /opt/spark-3.5.6 root@node03:/opt/
执行spark pi样例程序测试验证
cd /opt/spark-3.5.6
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--total-executor-cores 2 \
examples/jars/spark-examples_2.12-3.5.6.jar 10
四、Flink
继续登录node01节点,下载安装flink安装包
curl -O https://archive.apache.org/dist/flink/KEYS && gpg --import KEYS
curl -fSL "https://archive.apache.org/dist/flink/flink-1.20.2/flink-1.20.2-bin-scala_2.12.tgz" -o /tmp/flink.tar.gz
curl -fSL "https://archive.apache.org/dist/flink/flink-1.20.2/flink-1.20.2-bin-scala_2.12.tgz.asc" -o /tmp/flink.tar.gz.asc
gpg --verify /tmp/flink.tar.gz.asc
tar -xf /tmp/flink.tar.gz -C /opt/ && rm /tmp/flink.tar.gz*
echo "export FLINK_HOME=/opt/flink-1.20.2" >> /etc/profile.d/flinkbase.sh
source /etc/profile
# 复制到其他节点
scp /etc/profile.d/flinkbase.sh root@node02:/etc/profile.d/
scp /etc/profile.d/flinkbase.sh root@node03:/etc/profile.d/
# conf/conf.yaml末尾添加
echo "classloader:" >> /opt/flink-1.20.2/conf/conf.yaml
echo " check-leaked-classloader: false" >> /opt/flink-1.20.2/conf/conf.yaml
# 复制flink目录到其他节点
cd /opt
scp -r flink-1.20.2 root@node02:/opt/
scp -r flink-1.20.2 root@node03:/opt/
# 验证测试
bin/flink run -t yarn-per-job --detached examples/streaming/SocketWindowWordCount.jar --hostname 172.20.92.161 --port 9000
flink历史任务日志查看配置
编辑conf.yaml添加下面配置
# 配置作业完成后日志信息归档路径
jobmanager:
archive:
fs:
dir: hdfs://node01:8020/user/flink/completed-jobs/
# 配置历史服务器的网页地址端口和历史日志的路径,日志刷新间隔10秒(10000毫秒)
historyserver:
web:
address: node01
port: 8082
archive:
fs:
dir: hdfs://node01:8020/user/flink/completed-jobs/
fs.refresh-interval: 10000
启动历史日志服务器,在yarn界面点击任务后面的"HISTORY"就会跳转到flink界面查看已完成作业的日志。
# 查看历史任务日志
bin/historyserver.sh start
五、FAQ
1.容器中安装ping工具报错
需要在创建容器时添加cap-add参数IPC_LOCK和NET_RAW,desktop在Security -> Capabilities位置,命令行创建容器时添加下面参数
--cap-add=IPC_LOCK --cap-add=NET_RAW (或者--cap-add=ALL)
2.在HDFS web ui 上传文件时提示“Couldn't upload the file”
- 检查hdfs-site.xml是否配置dfs.permissions=false
- 检查操作上传的主机的hosts文件是否配置hadoop集群节点IP映射,上传文件时会调用域名
- HDFS目录是否有写入权限
3.容器挂载宿主机磁盘可能遇到权限问题,登录Podman machine default
修改配置/etc/wsl.conf
[automount]
enabled=true
mountFsTab=false
options="metadata"
4.避免容器自动生成宿主机hosts记录问题
修改配置/etc/wsl.conf
[network]
generateHosts = false
5.容器与宿主机网络互通,没有设置容器的端口映射时,可以通过添加路由的方式,让宿主机直接访问容器IP。在宿主机上添加路由,网关设置为Podman machine default系统的IP地址。
route ADD 10.88.0.0 MASK 255.255.0.0 172.24.137.159 IF 37
附
Debian 9(stretch)镜像源
- 官方
deb http://archive.debian.org/debian/ stretch main contrib non-free
deb-src http://archive.debian.org/debian/ stretch main contrib non-free
deb http://archive.debian.org/debian/ stretch-backports main contrib non-free
deb http://archive.debian.org/debian-security/ stretch/updates main contrib non-free
deb-src http://archive.debian.org/debian-security/ stretch/updates main contrib non-free
- 腾讯
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch-backports main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
- 阿里云
deb http://mirrors.aliyun.com/debian-archive/debian/ stretch main contrib non-free
deb-src http://mirrors.aliyun.com/debian-archive/debian/ stretch main contrib non-free
deb http://mirrors.aliyun.com/debian-archive/debian/ stretch-backports main contrib non-free
deb http://mirrors.aliyun.com/debian-archive/debian-security/ stretch/updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian-archive/debian-security/ stretch/updates main contrib non-free
本文来自博客园,作者:计艺回忆路,转载请注明原文链接:https://www.cnblogs.com/ckmemory/p/19040331

 浙公网安备 33010602011771号
浙公网安备 33010602011771号