第十 线程与锁
一、线程与进程区别
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
二、开启线程两种方式
方式一:
from threading import Thread import os def work(n): print('%s is running' %n) if __name__ == '__main__': t=Thread(target=work,args=('ckl',)) t.start() print("---main---")
运行结果:
方式二:
from threading import Thread import os class CklThread(Thread): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s is running' %self.name) if __name__ == '__main__': t=CklThread('ckl') t.start() print("---main---")
运行结果:
线程与进程pid
线程pid来自于主线程(所有线程来自同一pid):
from threading import Thread import os def work(): print('%s is running' %os.getpid()) if __name__ == '__main__': t1=Thread(target=work,) t2=Thread(target=work,) t1.start() t2.start() print("---main is %s ---" %os.getpid())
运行结果:
进程pid
进程产生不同的pid
from threading import Thread from multiprocessing import Process import os def work(): print('%s is running' %os.getpid()) if __name__ == '__main__': p1=Process(target=work,) p2=Process(target=work,) p1.start() p2.start() print("---main is %s ---" %os.getpid())
运行结果:
多线程共享同一进程资源
多进程:
from threading import Thread from multiprocessing import Process import os n=99 def work(): global n n = 1 if __name__ == '__main__': p1=Process(target=work,) p1.start() print("---main is %s ---" %n)
运行结果:

#分析:进程之间不共享资源,主进程开启,子进程也开启,子进程修改了n,但是没有共享给主进程,主进程看到的还是99
多线程
from threading import Thread from multiprocessing import Process import os n=99 def work(): global n n = 1 if __name__ == '__main__': t1=Thread(target=work,args=()) t1.start() print("---main is %s ---" %n)
运行结果:

#分析:多线程共享同一个进程内的资源,主进程启动,线程也启动,线程修改了n,所以主进程看到的也是修改后的结果。
多线程共享内存练习:
from threading import Thread msg_list = [] format_list = [] #输入内容 def say(): while True: msg = input('>>: ').strip() msg_list.append(msg) #格式化 def format(): while True: if msg_list: data = msg_list.pop() format_list.append(data.upper()) #存储内容 def save(): while True: if format_list: data = format_list.pop() with open('db.txt','a') as fa: fa.write('%s\n' %data) if __name__ == '__main__': t1 = Thread(target=say) t2 = Thread(target=format) t3 = Thread(target=save) t1.start() t2.start() t3.start()
运行:
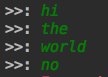
查看文件:

三、Thread对象属性与方法
一些了解方法
from threading import Thread,active_count,enumerate import os def work(): print('%s is running' %os.getpid()) if __name__ == '__main__': t1=Thread(target=work,) t1.start() # print(t1.is_alive()) #有时候True,有时候False,取决于操作系统回收时间 # print(t1.getName()) #Thread-1 print("---main ---") print(active_count()) #2当前活着的进程数,也取决操作系统,不固定 print(enumerate()) #当前活跃的进程对象,返回列表,当前主线程和子线程 # [ < _MainThread(MainThread, started 140735301873664) >, < Thread(Thread - 1, started 123145307557888) >]
current_thread 获取当前线程对象
示例一:
from threading import Thread,active_count,enumerate,current_thread import os def work(): print('%s is running' %current_thread().getName()) #Thread-1 is running if __name__ == '__main__': t1=Thread(target=work,) t1.start() print("---main ---")
示例二:
from threading import Thread,active_count,enumerate,current_thread from multiprocessing import Process import time print(current_thread())
运行结果:

#没有调用,为何有一个主线程?因为运行的时候,就会产生一个进程的(主线程)。
如下示例进一步理解:
from threading import Thread,active_count,enumerate,current_thread from multiprocessing import Process import time def work(): print('%s is running' %current_thread().getName()) #MainThrad 这是子进程的 if __name__ == '__main__': p=Process(target=work()) p.start() print(current_thread()) #MainThrad 这是主进程的
运行结果:

#第一个是子进程的MainThread,第二个是主进程的MainThread,主线程在执行层面代表了其所在进程的执行过程。
from threading import Thread,active_count,enumerate,current_thread from multiprocessing import Process import time def work(): print('%s is running' %current_thread().getName()) if __name__ == '__main__': t1 =Thread(target=work()) t2 = Thread(target=work()) t3 = Thread(target=work()) t1.start() t2.start() t3.start() print(current_thread())
运行结果:

#运行过程:一个进程(主线程)其余都是子进程。
四、守护线程
守护进程运行示例
from multiprocessing import Process import time def work1(): print('w1 is running') time.sleep(1) print('w1 done') def work2(): print('w2 is running') time.sleep(3) print('w2 done') if __name__ == '__main__': p1 = Process(target=work1) p2 = Process(target=work2) p1.daemon = True #守护进程,主进程结束,就跟着结束 p1.start() p2.start() print('-- main --')
运行结果:
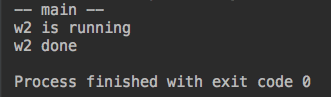
#分析:1.主进程启动,运行两个子进程。2.启动p1和p2,但是p1是守护进程,也就是主进程结束,p1也就结束。3.主进程是代码运行完毕就结束了。4.所以p1还没启动就跟着
结束了。5.主进程虽然结束,但是必须等着子进程运行完毕才结束,所以p2运行完毕(防止僵尸进程)。
守护线程
主线程一定要等待所有非守护线程运行完毕,才结束
from threading import Thread import time def work1(): print('w1 is running') time.sleep(1) print('w1 done') if __name__ == '__main__': t1 = Thread(target=work1) t1.daemon = True #守护进程,主进程结束,就跟着结束 t1.start() print('-- main --')
运行结果:
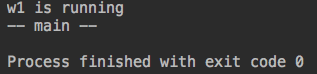
#分析运行:1.运行主线程。2.运行子线程打印运行。3.主线程运行完毕,这时候运行子线程,发现子线程是守护线程,所以也跟着结束掉。所以没有打印运行结束。
进一步示例:
from threading import Thread import time def work1(): print('w1 is running') time.sleep(1) print('w1 done') def work2(): print('w2 is running') time.sleep(3) print('w2 done') if __name__ == '__main__': t1 = Thread(target=work1) t2 = Thread(target=work2) t1.daemon = True t1.start() t2.start() print('-- main --')
运行结果:
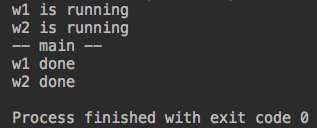
#运行分析:1.运行主线程。2.运行t1和t2,打印开始运行。3.这时候主线程运行完毕,t1是守护进程,应该也会跟着结束。但主线程要等待其它非守护线程运行
完毕才结束,所以等待t2运行完毕。4.等待t2的时间足够长,这时候t1也已经运行完毕,打印t1运行结束,等一会t2也运行结束。
五、GIL
GIL说明:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
GIL阻止同时执行多个python线程,这个锁是必须滴,因为Cpython的内存管理部安全。其它特效也依赖GIL增强安全。
GIL锁是加载解释器上的,保证代码执行不会被python内存回收给回收掉,只能保证解释器层面,不能保证代码层面。
进程可以利用多核,开销大。线程无法利用多核,开销小。
线程的互斥锁
多线程计算示例:
from threading import Thread import time n=100 def work(): global n temp = n time.sleep(1) n = temp -1 if __name__ == '__main__': l = [] for i in range(100): t = Thread(target=work) l.append(t) t.start() for t in l: t.join() print(n)
结果:

#运行分析:1.定义个全局n=100。2.定义一个函数,对全局n-1。3.开启100个线程,执行函数,并且等待所有线程执行完毕,也就是100减去100次,等于0。为何是99?
#结果说明:是因为多线程在执行函数减1的时候,遇到阻塞,然后就把执行权限让出,第二个也拿到执行后,也阻塞,初始值始终是100,最后阻塞了100次,执行了100次,每次都是100-1,所以结果就是99.如何避免这个问题呢?就是线程锁
from threading import Thread,Lock import time n=100 def work(): global n mutex.acquire() #加锁 temp = n time.sleep(0.1) n = temp - 1 mutex.release() #释放锁 if __name__ == '__main__': mutex = Lock() #定义锁 l = [] for i in range(100): t = Thread(target=work) l.append(t) t.start() for t in l: t.join() print(n)
运行结果:

#运行结果正确,但是这样一来,就把并行变成了串行,那还有什么意义?那是不是不用互斥锁,直接使用join,这样写也可以?
from threading import Thread import time n=100 def work(): global n temp = n time.sleep(0.1) n = temp - 1 if __name__ == '__main__': for i in range(100): t = Thread(target=work) t.start() t.join() print(n)
运行结果:

运行结果正确,那么互斥锁岂不是没有用?其实不是的,join是将每次运行都等待,所有代码从上之下而执行,完全串行。而互斥锁,值将加锁的值进行串行,这里刚好是第一行,效果一样,如果还有其他操作呢?加上时间看看效果?
没有互斥锁:
from threading import Thread import time n=100 start_time = time.time() def work(): global n time.sleep(0.05) #模拟其它操作 temp = n time.sleep(0.1) n = temp - 1 if __name__ == '__main__': for i in range(100): t = Thread(target=work) t.start() t.join() print("cost the time is %s and value is %s"%(time.time()-start_time,n))
运行结果:

有互斥锁:
from threading import Thread,Lock import time n=100 start_time = time.time() def work(): time.sleep(0.05) #模拟其它操作 global n mutex.acquire() #加锁 temp = n time.sleep(0.1) n = temp - 1 mutex.release() #释放锁 if __name__ == '__main__': mutex = Lock() #定义锁 l = [] for i in range(100): t = Thread(target=work) l.append(t) t.start() for t in l: t.join() print("cost the time is %s and value is %s" % (time.time() - start_time, n))
运行结果:

#这是因为,互斥锁串行的是加锁的部分,其余代码依然是并行执行。
多进程与多线程时机
多进程可以利用多核,但是开销大。多线程不可以利用多核,但是开销小。
计算密集型示例(多进程):
from multiprocessing import Process import time def work(): res = 1 for i in range(10000000): res += 1 if __name__ == '__main__': p_l = [] start_time = time.time() for i in range(4): p=Process(target=work) p_l.append(p) p.start() for p in p_l: p.join() print(time.time()-start_time)
运行结果:

如果是多线程:
from multiprocessing import Process from threading import Thread import time def work(): res = 1 for i in range(10000000): res += 1 if __name__ == '__main__': p_l = [] start_time = time.time() for i in range(4): p=Thread(target=work) p_l.append(p) p.start() for p in p_l: p.join() print(time.time()-start_time)
运行结果:

模拟IO密集型(多进程):
from multiprocessing import Process from threading import Thread import time def work(): time.sleep(3) if __name__ == '__main__': p_l = [] start_time = time.time() for i in range(4): p=Process(target=work) p_l.append(p) p.start() for p in p_l: p.join() print(time.time()-start_time)
运行结果:

IO密集型(多线程):
from multiprocessing import Process from threading import Thread import time def work(): time.sleep(3) if __name__ == '__main__': p_l = [] start_time = time.time() for i in range(4): # p=Process(target=work) p=Thread(target=work) p_l.append(p) p.start() for p in p_l: p.join() print(time.time()-start_time)
运行结果:

#总结:计算密集型的应用,使用多进程,利用多核的优势,加快计算速度。IO密集型的应用,使用多线程,减少切换及进程频繁创建操作,可以提升速度。
死锁与递归锁
死锁示例:
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class CklThread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print("\033[1;33m %s obtain lock A\033[0m" %self.name) mutexB.acquire() print("\033[1;34m %s obtain lock B\033[0m" %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print("\033[1;35m %s obtain lock B\033[0m" %self.name) time.sleep(1) mutexA.acquire() print("\033[1;36m %s obtain lock A\033[0m" %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t = CklThread() t.start()
运行结果:
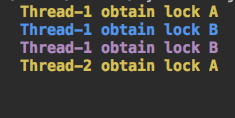
#运行分析:1.运行f1,线程1,获得A锁。2.线程1紧接着获得B锁,3.线程1释放B锁。4.线程1释放A锁。5.线程1得到B锁,等待得到B锁,这时候,休息1s,这期间,线程2得到A锁,准备获得B锁,发现没有,等待线程1释放。线程1睡好,准备获得A锁,发现没有,所以等待线程2释放。就这样。。。死锁了
解决办法:递归锁
from threading import Thread,Lock,RLock import time mutex=RLock() class CklThread(Thread): def run(self): self.f1() self.f2() def f1(self): mutex.acquire() print("\033[1;33m %s obtain lock A\033[0m" %self.name) mutex.acquire() print("\033[1;34m %s obtain lock B\033[0m" %self.name) mutex.release() mutex.release() def f2(self): mutex.acquire() print("\033[1;35m %s obtain lock B\033[0m" %self.name) time.sleep(1) mutex.acquire() print("\033[1;36m %s obtain lock A\033[0m" %self.name) mutex.release() mutex.release() if __name__ == '__main__': for i in range(10): t = CklThread() t.start()
运行结果:
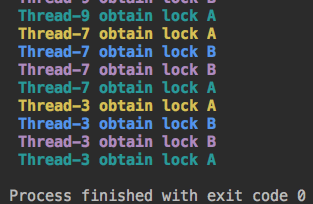
#递归锁原理是内部有一个计数器,这个计数器为0,就可以获得锁,如果不为0,这期间只能有一个线程获得锁。所以上面的🌰,线程1没有释放B锁,线程2是无法获得A锁的。
六、semaphore
semaphore相当于互斥锁一样来工作,来看示例:
from threading import Thread,current_thread,Semaphore import time,random sm = Semaphore(3) #同时可执行的任务 def work(): sm.acquire() print("%s is eating noodles" %current_thread().getName()) time.sleep(random.randint(1,5)) sm.release() if __name__ == '__main__': for i in range(10): t = Thread(target=work) t.start()
运行结果:
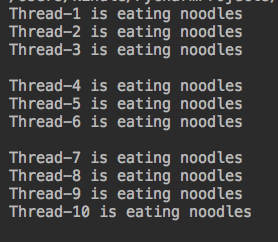
#期间按下回车,一次性只有3个线程在运行。这个跟进程池有什么区别?
进程池是只有3个进程在执行,一共就3个。信号量是一次性造了10个线程,但同时只运行3个.
七、 Event
如果同时运行多个线程,第二个线程要等第一个线程的返回状态来运行下一步操作,那么线程之间的这种状态传递如何实现呢?
这就需要用到Event了,Event内部有一个标志位,如果标志位为True则正常,如果为False则为异常。下面模拟一个连接mysql的示例:
from threading import Thread,current_thread,Event import time ev = Event() def conn_mysql(): print("%s is ready to connect mysql" %current_thread().getName()) ev.wait() #等待返回结果 print("%s has connected" %current_thread().getName()) def check_mysql(): print("Begin to check mysql status...") time.sleep(3) ev.set() #设置状态为True if __name__ == '__main__': t1 = Thread(target=conn_mysql) t2 = Thread(target=conn_mysql) t1.start() t2.start() check_mysql()
运行结果:
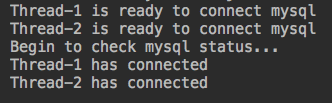
#等待3秒后,检车event返回为ture,进行连接。那么还可以设置超时时间,判断当前状态等:
运行示例:
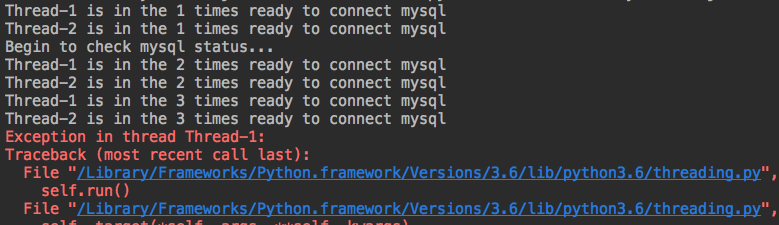
from threading import Thread,current_thread,Event import time ev = Event() def conn_mysql(): count=1 ev.clear() #设置初始值为False while not ev.isSet(): if count > 3: raise ConnectionError("Connect mysql error") print("%s is in the %s times ready to connect mysql" %(current_thread().getName(),count,)) ev.wait(0.5) #阻塞线程,等待超时为0.5 count += 1 print("%s has connected" %current_thread().getName()) def check_mysql(): print("Begin to check mysql status...") time.sleep(3) ev.set() #设置状态为True if __name__ == '__main__': t1 = Thread(target=conn_mysql) t2 = Thread(target=conn_mysql) t1.start() t2.start() check_mysql()
运行结果:
八、线程queue
先进先出:
import queue q = queue.Queue(3) #队列,先进先出 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get())
结果:

后进先出:
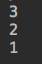
import queue q = queue.LifoQueue(3) #堆栈,先进后出 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get())
运行结果:
优先级
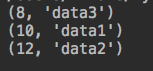
import queue q = queue.PriorityQueue(3) #数字越小,优先级越高 q.put((10,'data1')) q.put((12,'data2')) q.put((8,'data3')) print(q.get()) print(q.get()) print(q.get())
运行结果:
Timer
#5s后,让老习给我汇报
from threading import Timer def work(n): print("I had %s report to me" %n) t = Timer(5,work,args=('laoxi',)) t.start()
结果:

九、进程池与线程池
concurrent.futures 为异步执行调用提供了一个更高级别的接口。
说明:https://docs.python.org/3/library/concurrent.futures.html
进程池:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import os,time,random def work(n): print("%s is running" %os.getpid()) time.sleep(random.randint(1,3)) return n*2 if __name__ == '__main__': p=ProcessPoolExecutor() #不指定,默认是CPU核数 objs_list = [] for i in range(10): objs = p.submit(work,i) #相当于之前进程池的apply_async() objs_list.append(objs) p.shutdown() #相当于之前进程池的close()和join() for j in objs_list: print(j.result()) #相当于之前进程池的get()
运行结果:
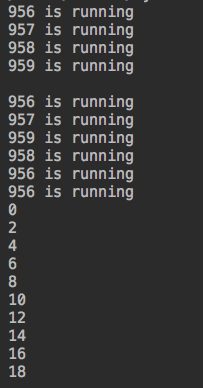
#同时有四个进程在执行,CPU的四个核数。
线程池
线程池的实现同进程池一样,就名字换一下。
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import os,time,random def work(n): print("%s is running" %current_thread().getName()) time.sleep(random.randint(1,3)) return n*2 if __name__ == '__main__': p=ThreadPoolExecutor() #不指定,默认是CPU核数*5 objs_list = [] for i in range(22): objs = p.submit(work,i) #相当于之前进程池的apply_async() objs_list.append(objs) p.shutdown() #相当于之前进程池的close()和join() for j in objs_list: print(j.result()) #相当于之前进程池的get()
运行结果:
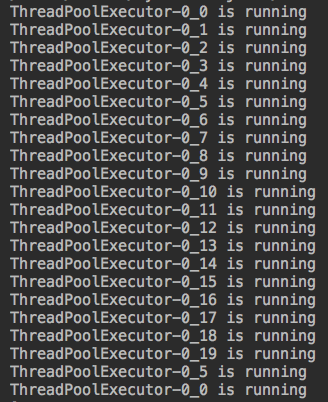

#运行结果说明:同时运行20个线程CPU核数*5,其它都一样。
用concurrent来实现回调函数
#之前回调函数
from multiprocessing import Pool import requests import json import os #下载链接 def get_page(url): print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} #分析内容 def pasrse_page(res): print('<%s> parse:%s' %(os.getpid(),len(res))) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.sohu.com', 'https://www.163.com', 'https://www.qq.com', 'http://www.sina.com.cn', 'http://www.jd.com' ] p=Pool(3) #进程池为3 for url in urls: p.apply_async(get_page,args=(url,),callback=pasrse_page) #一旦某个获取网页结束,则主进程分析网页 p.close() p.join()
运行结果:
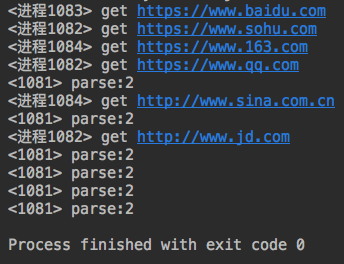
#同时有3个进程在执行。如果是使用concurrent呢?
from multiprocessing import Pool from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import requests import json import os #下载链接 def get_page(url): print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} #分析内容 def pasrse_page(res): print('<%s> parse:%s' %(os.getpid(),len(res))) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.sohu.com', 'https://www.163.com', 'https://www.qq.com', 'http://www.sina.com.cn', 'http://www.jd.com' ] # p=Pool(3) #进程池为3 p=ProcessPoolExecutor() for url in urls: # p.apply_async(get_page,args=(url,),callback=pasrse_page) #一旦某个获取网页结束,则分析网页 p.submit(get_page,url).add_done_callback(pasrse_page) #这个函数相当于回调函数 # p.close() # p.join() p.shutdown()
运行结果:


#分析原因:
p.apply_async(get_page,args=(url,),callback=pasrse_page) #这个回调函数拿到的是一个结果 p.submit(get_page,url).add_done_callback(pasrse_page) #这个回调函数拿到的是一个对象,而非结果
修改如下:
from multiprocessing import Pool from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import requests import json import os #下载链接 def get_page(url): print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} #分析内容 def pasrse_page(res): res = res.result() #得到结果 print('<%s> parse:%s' %(os.getpid(),len(res))) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.sohu.com', 'https://www.163.com', 'https://www.qq.com', 'http://www.sina.com.cn', 'http://www.jd.com' ] # p=Pool(3) #进程池为3 p=ProcessPoolExecutor() for url in urls: # p.apply_async(get_page,args=(url,),callback=pasrse_page) #一旦某个获取网页结束,则分析网页 p.submit(get_page,url).add_done_callback(pasrse_page) #这个函数相当于回调函数 # p.close() # p.join() p.shutdown()
运行结果:
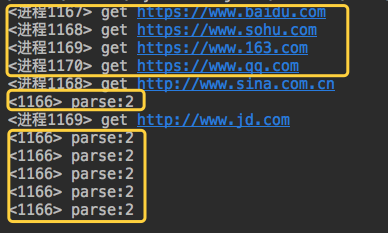
#并发四个进程在执行,主进程在分析结果
线程池模拟网页分析:
from multiprocessing import Pool from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import requests import json import os #下载链接 def get_page(url): print('<进程%s> get %s' %(current_thread().getName(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} #分析内容 def pasrse_page(res): res = res.result() #得到结果 print('<%s> parse:%s' %(current_thread().getName(),len(res))) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.sohu.com', 'https://www.163.com', 'https://www.qq.com', 'http://www.sina.com.cn', 'http://www.jd.com' ] # p=Pool(3) #进程池为3 p=ThreadPoolExecutor(3) for url in urls: # p.apply_async(get_page,args=(url,),callback=pasrse_page) #一旦某个获取网页结束,则分析网页 p.submit(get_page,url).add_done_callback(pasrse_page) #这个函数相当于回调函数 # p.close() # p.join() p.shutdown()
运行结果:
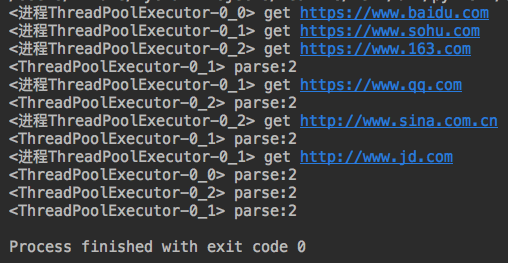
#每次运行3个,因为指定了线程数。分析不再是主线程分析,而是哪个线程结束,哪个线程去分析。
concurrent的map的使用
python的map方法回忆:
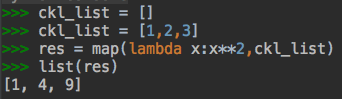
之前的进程池改用map方法实现:
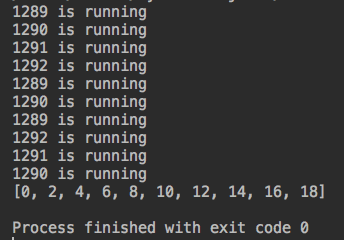
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import os,time,random def work(n): print("%s is running" %os.getpid()) time.sleep(random.randint(1,3)) return n*2 if __name__ == '__main__': p=ProcessPoolExecutor() res = p.map(work,range(10)) #将每一次结果,当做参数传递给work p.shutdown() print(list(res)) #得到迭代器的结果
运行结果:
十、协程
实现函数之间的切换,如何实现?之前的yield:
import time def consumer(): while True: res = yield def producer(): g = consumer() next(g) for i in range(10000000): g.send(i) start = time.time() producer() print(time.time()-start)
运行结果:

这样切换没有意义,单纯切换,没有因为阻塞而切换,有更好的切换,greenlet模块,如下:
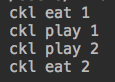
from greenlet import greenlet def eat(name): print("%s eat 1" %name) g2.switch('ckl') #第一次switch传参 print("%s eat 2" %name) g2.switch() def play(name): print("%s play 1" %name) g1.switch() print("%s play 2" %name) g1 = greenlet(eat) g2 = greenlet(play) g1.switch('ckl') #在第一次switch的时候传参
运行结果:
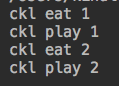
#这样实现了yield,但是仍然是没有意义的切换,没有因为阻塞切换,如果遇到阻塞才切换呢?这就使用另外一个模块,gevent
import gevent def eat(name): print("%s eat 1" %name) gevent.sleep(3) print("%s eat 2" %name) def play(name): print("%s play 1" %name) gevent.sleep(2) print("%s play 2" %name) g1=gevent.spawn(eat,'ckl') g2=gevent.spawn(play,'ckl') gevent.joinall([g1,g2])
运行结果:
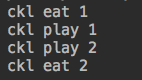
#运行分析:1.运行eat,打印ckl eat 1,这时候遇到阻塞。2.且到play,打印ckl paly 1,这时候遇到阻塞,切到eat,eat仍然为阻塞,切换到play,paly也是阻塞,这样反复切,最后play先阻塞完毕,所以打印ckl play 2,paly运行完毕,再切换到eat,打印ckl eat 2,这没有使用系统的time模块,默认是不识别系统的time,如果要识别,必须如下实现:
from gevent import monkey;monkey.patch_all() import gevent import time def eat(name): print("%s eat 1" %name) time.sleep(3) print("%s eat 2" %name) def play(name): print("%s play 1" %name) time.sleep(2) print("%s play 2" %name) g1=gevent.spawn(eat,'ckl') g2=gevent.spawn(play,'ckl') gevent.joinall([g1,g2])
运行结果:
客户端和服务端并发的实现,使用gevent,如下:
服务端:
from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print('client %s:%s msg: %s' %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == '__main__': server('127.0.0.1',8080)
客户端:
from threading import Thread from socket import * import threading def client(server_ip,port): c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了 c.connect((server_ip,port)) count=0 while True: c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8')) msg=c.recv(1024) print(msg.decode('utf-8')) count+=1 if __name__ == '__main__': for i in range(500): t=Thread(target=client,args=('127.0.0.1',8080)) t.start()
运行结果服务端:
客户端:

#这样就可以在一个线程内,实现多并发的效果,这样就是协程。协程就是用户态下的轻量级线程。
协程有点:
1.开销小,更加轻量级。
2.单个线程内实现并发,最大限度使用CPU
缺点:
1.协程本质是单线程,无法利用多核,可以一个程序开旭多个进程,每个进程多个线程,多个线程开启协程
2.协程出现阻塞,将阻塞整个线程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号