
elk+kafka
转载于
https://blog.csdn.net/yangpei1/article/details/98897548
https://blog.csdn.net/qq_41475058/article/details/89840468
elk的架构
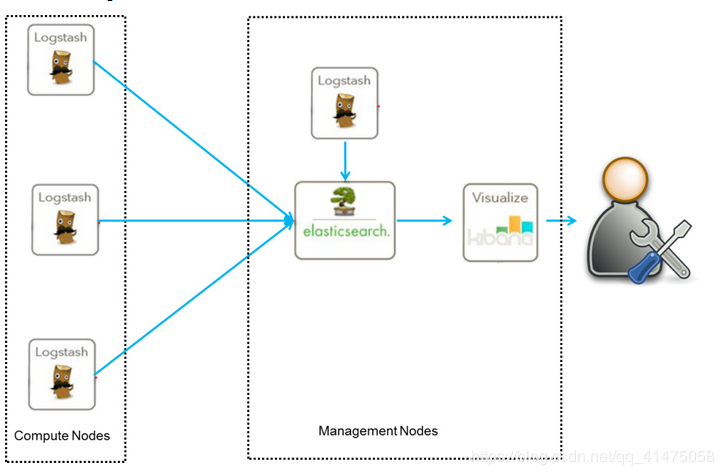
elk+kafka
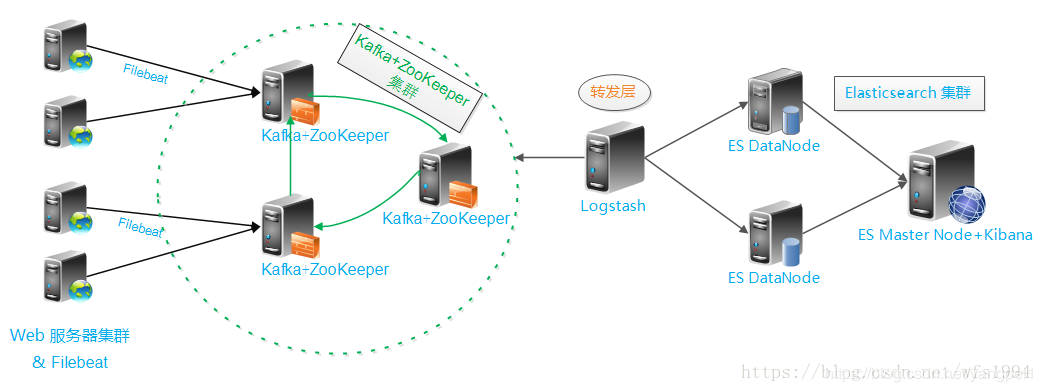
准备工作:
ntp,
主机名,
/etc/hsots 域名相互解析
设置JVM堆大小
[root@mes-1 config]# vim jvm.options
将
-Xms1g ----修改成 -Xms2g
-Xmx1g ----修改成 -Xms2g
或者:
推荐设置为4G,请注意下面的说明:
sed -i ‘s/-Xms1g/-Xms4g/’ /usr/local/elasticsearch-6.5.4/config/jvm.options
sed -i ‘s/-Xmx1g/-Xmx4g/’ /usr/local/elasticsearch-6.5.4/config/jvm.options
注意: 确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。 堆内存大
小不要超过系统内存的50%
系统优化 下面两部都要做 不要忘了打乘号
(1)增加最大文件打开数
永久生效方法: echo “* - nofile 65536” >> /etc/security/limits.conf
(2)增加最大进程数
[root@mes-1 ~]# vim /etc/security/limits.conf —在文件最后面添加如下内容
- soft nofile 65536
- hard nofile 131072
- soft nproc 2048
- hard nproc 4096
(3)增加最大内存映射数
[root@mes-1 ~]# vim /etc/sysctl.conf —添加如下
vm.max_map_count=262144
vm.swappiness=0
[root@mes-1 ~]# sysctl -p
步骤
elk-mater-1 192.168.1.243
elk-mater-2 192.168.1.241
elk-data 192.168.1.242
elk-cache 192.168.1.244
-
更改各设备主机名,设置ntp时间,按照需要的包,
yum -y install lrzsz vim net-tools -
将elk包放到 /tmp目录
tar xvf elk-zk.tar -
根据客户配置情况配置各节点
这里以 2elk-master 1 elk-data 3 elk-cache 为例
配置各主机的hosts文件
vim /etc/hosts
192.168.1.243 elk-master-1
192.168.1.241 elk-master-2 elk-cache2
192.168.1.242 elk-data-1 elk-cache3
192.168.1.244 elk-cache1
ELK
elk依赖于java环境,如果客户环境没有,需要安装
rpm -ivh /tmp/pkg/jdk-8u221-linux-x64.rpm
安装:
执行脚本:
sh /tmp/pkg/elk_install.sh
(安装过程中会出现三个提示,当前节点是否开启 master ingest data)
该节点是否有master资格 [Y/N]
该节点是否存储索引数据 [Y/N]
该节点对文档进行索引之前是否做预处理 [Y/N]
根据该节点的功能配置三个选项
安装完脚本之后默认是es logstash kibana 都是启动的, 如果配置集群,在master1节点开启这三个,其他节点只开启es即可
配置内容
vim /etc/elasticsearch/elasticsearch.yml
73 discovery.zen.ping.unicast.hosts: ["elk-master-1", "elk-master-2","elk-data-1"]
集群初始设备列表,这里以2master 1data为例,根据客户环境具体配置
77 discovery.zen.minimum_master_nodes: 2
集群master节点最小数量,总节点数量/2+1,这里的数量配置2,则在安装elk的时候根据提示 该节点是否有master资格 [Y/N] 得有至少两个
ZOOKEEPER+KAFKA
安装:
执行脚本:
sh /tmp/pkg/zk_install.sh
(安装过程中有提示,设置节点id值,最好和cache节点号保持一致,因为在配置中将使用这个id号指定listeners=PLAINTEXT://elk-cache1:9092,同时保证各节点配置的值不一样的正数。eg:elk-cache1:1,elk-cache2:2 )
请输入zookeepere的节点id
输入kafka的节点id
zookeeper配置
vim /opt/logminer/zookeeper/conf/zoo.cfg
在末尾配置zookeeper数据,根据节点数量各节点的zookeeper参数
server.1=elk-cache1:2555:3555
server.2=elk-cache2:2555:3555
server.3=elk-cache3:2555:3555
kafaka配置
vim /opt/logminer/kafka/config/server.properties
根据节点配置指定kafka集群的节点连接zookeeper参数,(这里布了三套zookeeper)
31行: listeners=PLAINTEXT://elk-cache1:9092 (配置各节点的kafka服务)
默认使用用户输入的id号,匹配cache节点号
123行: zookeeper.connect=elk-cache1:2181,elk-cache2:2181,elk-cache3:2181
启动:
zookeeper: /opt/logminer/zookeeper/bin/zkServer.sh start
kafka: /opt/logminer/kafka/bin/kafka-server-start.sh -daemon /opt/logminer/kafka/config/server.propertie
测试:
1)启动 先启动zookeeper
在三个节点依次执行:
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
三台都启动以后查看一下端口,这里端口正常就可以进行下一步了
ss -anpt | grep 2181
[root@es-3-head-kib-zk-file kafka_2.11-2.1.0]# ss -anpt | grep 2181
LISTEN 0 50 :::2181 ::😗 users:(("java",pid=84513,fd=97))
(2)验证
yum install -y nc
[root@es-2-zk-log kafka_2.11-2.1.0]# echo conf | nc 127.0.0.1 2181
clientPort=2181
dataDir=/opt/data/zookeeper/data/version-2
dataLogDir=/opt/data/zookeeper/logs/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=1
initLimit=20
syncLimit=10
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0
(3)启动kafka
在三个节点依次执行
[root@es-2-zk-log ~]# cd /usr/local/kafka_2.11-2.1.0/
[root@es-2-zk-log kafka_2.11-2.1.0]# nohup bin/kafka-server-start.sh config/server.properties &
(2)验证
创建topic
[root@mes-1-zk kafka_2.11-2.1.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic 最好在第一台机器上创建
Created topic "testtopic".
三台机器上都查询一下
bin/kafka-topics.sh --zookeeper 192.168.88.129:2181 --list
显示testtopic就算可以了
模拟消息生产和消费 发送消息到192.168.88.129
[root@mes-1-zk kafka_2.11-2.1.0]# bin/kafka-console-producer.sh --broker-list 192.168.88.129:9092 --topic testtopic
hello
[root@es-2-zk-log kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.88.129:9092 --topic testtopic --from-beginning
hello 接收到消息 可能会有延迟比较慢
FILEBEAT LOGSTASH
filebeat 配置内容
配置完之后重启服务
以收集httpd日志为例
/etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:- /var/log/httpd/access_log
output.kafka:
hosts: ["elk-cache1:9092","elk-cache2:9092","elk-cache3:9092"]
topic: "apache"
logstash配置
配置完之后重启logstash服务
vim /etc/logstash/conf.d/httpd.conf
input {
kafka { #指定kafka服务
type => "apache_log"
codec => "json" #通用选项,用于输入数据的编解码器
topics => "apache" #这里定义的topic
decorate_events => true #此属性会将当前topic、group、partition等信息也带到message中
bootstrap_servers => "elk-cache1:9092, elk-cache2:9092, elk-cache3:9092"
}
}
output{ #输出插件,将事件发送到特定目标
stdout{
codec => "rubydebug"
}
elasticsearch { #输出到es
hosts => ["elk-master-1:9200"] #指定es服务的ip加端口
index => ["%{type}-%{+YYYY.MM.dd}"] #引用input中的type名称,定义输出的格式
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号