NEMU PA4 - 虚实交错的魔法: 分时多任务

请注意你的学术诚信!
本博客只提供个人思路的参考和一些想法, 并非能够抄袭的答案
1.本人水平有限,实现的PA可能有可怕的bug
2.本人思路可能有误,需要各位自行判别
多道程序
要实现一个多道程序操作系统, 我们只需要实现以下两点就可以了:
- 在内存中可以同时存在多个进程
- 一个需要注意的地方是栈, 我们需要为每个进程分配各自的栈空间.
- 在满足某些条件的情况下, 可以让执行流在这些进程之间切换
AM中实现内核线程


MAP(REGS, PUSH)
REGS(PUSH)
REGS_LO16(PUSH) REGS_HI16(PUSH)
在__am_asm_trap()中是先将sp减少,然后不断往高地址的PUSH进站(与平常的SP往底地址进栈反常),这是为了与Context中的内容相对应,mv a0, sp就是为了将sp当做参数放入Context *c
.align 3
.globl __am_asm_trap
__am_asm_trap:
addi sp, sp, -CONTEXT_SIZE
MAP(REGS, PUSH)
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
jal __am_irq_handle
其要求在__am_irq_handle 将sp指向新栈,那么在kcontext中我们必须要将一些内容组织一下才能应对接下来的从栈中回复上下文
jal __am_irq_handle
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
csrw mstatus, t1
csrw mepc, t2
MAP(REGS, POP)
addi sp, sp, CONTEXT_SIZE
mret
以yield_os为例考虑整个流程:
#include <am.h>
#include <klib-macros.h>
#define STACK_SIZE (4096 * 8)
typedef union {
uint8_t stack[STACK_SIZE];
struct { Context *cp; };
} PCB;
static PCB pcb[2], pcb_boot, *current = &pcb_boot;
static void f(void *arg) {
while (1) {
putch("?AB"[(uintptr_t)arg > 2 ? 0 : (uintptr_t)arg]);
for (int volatile i = 0; i < 100000; i++) ;
yield();
}
}
static Context *schedule(Event ev, Context *prev) {
current->cp = prev;
current = (current == &pcb[0] ? &pcb[1] : &pcb[0]);
return current->cp;
}
int main() {
cte_init(schedule);
pcb[0].cp = kcontext((Area) { pcb[0].stack, &pcb[0] + 1 }, f, (void *)1L);
pcb[1].cp = kcontext((Area) { pcb[1].stack, &pcb[1] + 1 }, f, (void *)2L);
yield();
panic("Should not reach here!");
}
kcontext的作用就是人工创建内核上下文,准备好一个新进程需要的状态:
- 要跳转到的执行函数地址
- 函数的参数,因为在RISCV中第一个参数是通过a0来实现的,所以我们要设置a0
- 为了difftest,初始化mstatus
- $0, sp不参与保存和回复上下文
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
// Area kstack是要创建的线程的栈,我需要在这个栈中找好位置上下文结构内容
int nr_regs = 0, xlen = 0, context_size = 0;
#ifndef __riscv_e
nr_regs = 32;
#else
nr_regs = 16;
#endif
#if __riscv_xlen == 32
xlen = 4;
#else
xlen = 8;
#endif
context_size = (nr_regs + 3) * xlen;
uint8_t *top_sp = (uint8_t *)kstack.end; // 拿到栈的顶部指针, 注意这里栈顶指针初始是不能用的
uint8_t *low_sp = top_sp - context_size;
Context *c = (Context *)low_sp;
c->gpr[0] = (uintptr_t)0; // $0 其实写不写无所谓,因为$0寄存器不参与保存和恢复上下文
c->gpr[2] = (uintptr_t)low_sp; // sp 其实写不写无所谓,因为sp寄存器不参与保存和恢复上下文
c->gpr[10] = (uintptr_t)arg; // a0
c->mstatus = (uintptr_t)0x1800;
c->mepc = (uintptr_t)entry;
return c;
}
但是, 我们要如何找到别的进程的上下文结构呢? 注意到上下文结构是保存在栈上的, 但栈空间那么大, 受到函数调用形成的栈帧的影响, 每次保存上下文结构的位置并不是固定的. 自然地, 我们需要一个
cp指针(context pointer)来记录上下文结构的位置, 当想要找到其它进程的上下文结构的时候, 只要寻找这个进程相关的cp指针即可.
如下图能够很好地解释上述话:
| |
+---------------+ <---- kstack.end
| |
| context |
| |
+---------------+ <--+
| | |
| | |
| | |
| | |
+---------------+ |
| cp | ---+
+---------------+ <---- kstack.start
| |
cp指向的是本PCB的栈中上下文结构的位置
.align 3
.globl __am_asm_trap
__am_asm_trap:
addi sp, sp, -CONTEXT_SIZE
MAP(REGS, PUSH)
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
jal __am_irq_handle
# 修改CTE中__am_asm_trap()的实现, 使得从__am_irq_handle()返回后,
# 先将栈顶指针切换到新进程的上下文结构, 然后才恢复上下文, 从而完成上下文切换的本质操作
#
# 因为我们从__am_irq_handle返回,return c,而在RISCV中返回值是保存在a0寄存器的,所以
# 我们只要从a0寄存器取出给sp即可
mv sp, a0
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
csrw mstatus, t1
csrw mepc, t2
MAP(REGS, POP)
addi sp, sp, CONTEXT_SIZE
mret
yield_os代码的整个流程可以理解为:
main() --> 其中调用cte_init,将user_handle设置为调度方法schedule,如此可切换其他的进程上下文--> 通过kcontext创建内核线程的上下文-->yield()-->触发ecall EVENT_YIELD--> __am_asm_trap --> __am_asm_trap 保存上下--> __am_irq_handle 调用了 user_handle 即 schedule 返回新的上下文结构的指针c,然后__am_irq_handle 也return c --> c在寄存器a0中,__am_asm_trap 中 mv sp, a0 即让sp指向了新的栈,且栈中有新线程的上下文 --> __am_asm_trap 恢复新线程的上下文,此时计算机的状态已经变成了新线程的状态, mret 从mepc取出值给到pc --> 开始执行新线程的函数f--> yield() --> 进入轮回
Nanos-lite 初步实现内核线程

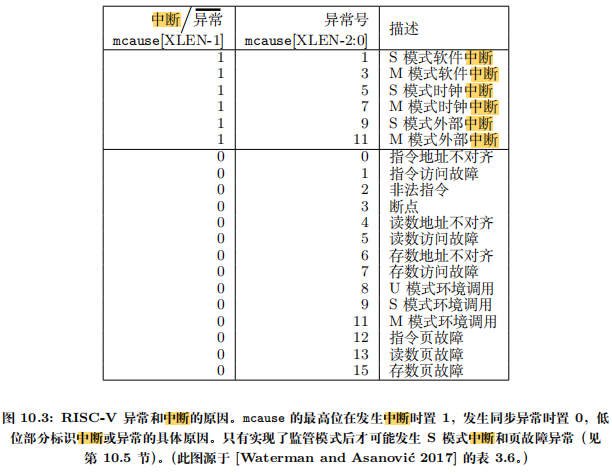
用户进程
捋清楚内核栈和用户栈
创建用户进程的上下文则需要一些额外的考量. 在PA3的批处理系统中, 我们在
naive_uload()中直接通过函数调用转移到用户进程的代码, 那时候使用的还是内核区的栈, 万一发生了栈溢出, 确实会损坏操作系统的数据, 不过当时也只有一个用户进程在运行, 我们也就不追究了. 但在多道程序操作系统中, 系统中运行的进程就不止一个了, 如果让用户进程继续使用内核区的栈, 万一发生了栈溢出, 就会影响到其它进程的运行, 这是我们不希望看到的.
什么是内核栈?
我们知道,我们在ics2023/abstract-machine/scripts/linker.ld中定义了am,klib,nanos-lite这些内核代码的内存映射布局,其中定义了堆栈:
_stack_top = ALIGN(0x1000);
. = _stack_top + 0x8000;
_stack_pointer = .;
end = .;
_end = .;
_heap_start = ALIGN(0x1000);
然后在ics2023/abstract-machine/am/src/riscv/nemu/start.S中使用到了栈指针:
_start:
mv s0, zero
la sp, _stack_pointer
jal _trm_init
现在我们来看看应用程序中的Start.S:ics2023/navy-apps/libs/libos/src/crt0/start.S
.globl _start
_start:
mv s0, zero
jal call_main
并没有改变栈指针,且我们在naive_uload()中通过loader得到应用程序的起始运行地址(即_start),然后直接运行,所以说我们用的还是内核区的栈
void naive_uload(PCB *pcb, const char *filename) {
//printf("nanos-lite naive_uload filename: %s\n", filename);
uintptr_t entry = loader(pcb, filename);
Log("Jump to entry = %p", (void *)entry);
((void(*)())entry) ();
}
同时我们在人工创建上下文时,用的是内核区的堆创建的PCB:
# ics2023/nanos-lite/src/proc.c
#define MAX_NR_PROC 4
static PCB pcb[MAX_NR_PROC] __attribute__((used)) = {};
static PCB pcb_boot = {};
现在有个严重的问题:我们在上述实现内核线程的时候,我人工创建的上下文中我并没有对sp寄存器进行初始化???
- 确实我上述有点写错误了,在构造上下文时应该将sp寄存器设置为相应新的栈地址,但是依据不影响实现的原因是sp根本不参与保存上下文和恢复上下文
- 依据
ics2023/abstract-machine/am/src/riscv/nemu/trap.S代码,x0也不参与保存上下文和恢复上下文
目前我们让Nanos-lite把heap.end作为用户进程的栈顶, 然后把这个栈顶赋给用户进程的栈指针寄存器就可以了.
相关内容分别定义在:
# ics2023/abstract-machine/am/include/am.h
typedef struct {
void *start, *end;
} Area;
# ics2023/abstract-machine/am/src/platform/nemu/trm.c
Area heap = RANGE(&_heap_start, PMEM_END);
# ics2023/abstract-machine/am/src/platform/nemu/include/nemu.h
extern char _pmem_start;
#define PMEM_SIZE (128 * 1024 * 1024)
#define PMEM_END ((uintptr_t)&_pmem_start + PMEM_SIZE)
简单来说就是0x88000000被当做用户程序的栈顶了
实现用户程序的多道程序系统
- 因此, 和内核线程不同, 用户进程的代码, 数据和堆栈都应该位于用户区, 而且需要保证用户进程能且只能访问自己的代码, 数据和堆栈. 为了区别开来, 我们把PCB中的栈称为内核栈, 位于用户区的栈称为用户栈
- 在
ics2023/nanos-lite/src/loader.c中实现了context_uload,因为之前的naive_uload也是在这目录下 - 注意到在RISCV中a0既是第一个传参,也是返回时用的寄存器
- 用户程序首先执行的是在
ics2023/navy-apps/libs/libos/src/crt0/start.S, 因为我们约定将用户栈地址存放到上下文的GPRx(在RISCV中即是a0),所以回复用户程序上下文后然后执行start.S, 我们只要在ics2023/navy-apps/libs/libos/src/crt0/start.S中mv sp, a0就能让sp指向用户栈,达到了切换栈的目的,然后跳转到call_main执行,a0也是call_main的参数

要验证用户程序使用的是用户栈即0x88000000往下的地址,很简单,只要在进入执行用户程序时打印看下sp寄存器的值即可:
uintptr_t sp_val = 0;
asm volatile ("mv %0, sp" : "=r"(sp_val));
printf("sp = 0x%lx\n", (unsigned long)sp_val);
将上述代码放到用户程序的call_main或main处都行

运行后触发了NEMU中的assert: address (0xffffffdc) is out of bound at pc = 0x83007310
这是因为我们的用户程序目前都把栈顶设置为heap.end,如果运行多个运用程序会导致用户程序栈冲突,引发一些奇怪的现象
用户进程的参数
很自然参数和环境变量的传递就需要由操作系统来负责. 最适合存放参数和环境变量的地方就是用户栈了
我们把存放参数和环境变量实现在了ics2023/nanos-lite/src/loader.c中的context_uload函数中
要注意对指针的操作,在本次完成实验中几个需要注意的点:
uint8_t *ustack_end; // 其指向栈的地址
# 如果想要拿到栈ustack_end中保存的地址所对应的字符串:
(char *)((uintptr_t)(*ustack_end)) 这样是行不通的,因为ustack_end是uint8_t*,其(*ustack_end)最多只能拿出8位出来
(char *)((uintptr_t)(*(uintptr_t*)ustack_end)) 这样才是对的
然后在ics2023/navy-apps/libs/libos/src/crt0/start.S中,因为对于RISCV来说a0寄存器即是传参第一个参数对应的寄存器,又是返回时存放返回值的寄存器,且在context_uload中将cp->GPRx其实就是cp->a0
# ics2023/navy-apps/libs/libos/src/crt0/start.S
mv sp, a0
jal call_main
实际上已经做到了将argc在栈中地址给到sp作为用户栈的栈顶,也做到了将argc在栈中地址作为参数传递给call_main函数
void call_main(uintptr_t *args) {
uintptr_t p = (uintptr_t)args;
int argc = *(int *)p;
char **argv = (char **)(p + 4);
char **envp = (char **)(p + 4 + (argc + 1) * sizeof(uintptr_t));
environ = envp;
exit(main(argc, argv, envp));
assert(0);
}
如何理解上述代码?
| |
+---------------+ <---- ustack.end
| | <----------+
| string | <--------+ |
| area | <------+ | |
| | <----+ | | |
| | <--+ | | | |
+---------------+ | | | | |
| NULL | | | | | |
+---------------+ | | | | |
| ...... | | | | | |
+---------------+ | | | | |
| envp[1] | ---+ | | | |
+---------------+ | | | |
| envp[0] | -----+ | | |
+---------------+ | | |
| NULL | | | |
+---------------+ | | |
| argv[argc-1] | -------+ | |
+---------------+ | |
| ...... | | |
+---------------+ | |
| argv[1] | ---------+ |
+---------------+ |
| argv[0] | -----------+
+---------------+
| argc |
+---------------+ <---- cp->GPRx
| |
我在context_uload函数中将argc/argv/envp push 到栈后的内存分布图如上,对于参数args其实就是 argc 所在栈的地址,我们将地址转换为整数p, p + 4其实就是argv[0]所在的地址
*(uintptr_t *)(p + 4)得到的是栈中所保存的argv[0]的地址
*(char *)(*(uintptr_t *)(p + 4))得到argv[0]所指向的字符串值
所以char **argv = (char **)(p + 4);

int main(int argc, char *argv[], char *envp[]);
int execve(const char *pathname,
char *const argv[],
char *const envp[]);
char *argv[] 其实等价于 char **argv,它告诉你:
argv是一个指向可变指针(char *)的数组;- 你既可以修改每个指针(
argv[i] = some_other_string;),也可以修改它指向的字符(argv[0][0] = 'X';),编译器不会阻止你。
char *const argv[]
“
argv是一个数组,数组里的每个元素都是一个只能读不能改的字符指针。”
下面拆开来一步步理解:
-
char *- 这表示“指向字符的指针”,也就是一个能指向 C 字符串首地址的变量。
- 举例:
char *p = "hello";你可以通过p去读 “hello” 里的每个字符,也可以写p[0] = 'H';(如果字符串所在内存是可写的)。
-
char *const-
把
const放在指针名字的左边(或说 “*的右边”),它修饰的是指针本身:char *const p = "hello"; -
这里
p自己是“常量”,一旦初始化指向某个字符串,就不能再改p = 另一个地址; -
但你仍然可以用
p[0] = 'H';去改变它指向的内存内容(如果那块内存允许写)。
-
-
char *const argv[]- 加上
[],就是“一个数组,数组元素类型是char *const”。 - 换句话说,
argv[i](每一项指针)在函数里不能被重新赋值,但你可以通过它去操作(读取或修改)那个字符串。
- 加上
-
为什么编译器把它当成
char *const *argv?- 在函数参数里,写
char *const argv[]和写char *const *argv效果一样:- 参数名
argv本质是一个指针,指向第 0 项那根“常量指针”所在的位置。
- 参数名
- 在函数参数里,写
理清楚一下heap的实现和使用
//abstract-machine/am/include/am.h
// Memory area for [@start, @end)
typedef struct {
void *start, *end;
} Area;
extern Area heap;
//abstract-machine/am/src/platform/nemu/trm.c
Area heap = RANGE(&_heap_start, PMEM_END);
Klib Malloc层面:
为了运行它们, 你还需要实现klib中的
malloc()和free(), 目前你可以实现一个简单的版本:
- 在
malloc()中维护一个上次分配内存位置的变量addr, 每次调用malloc()时, 就返回[addr, addr + size)这段空间.addr的初值设为heap.start, 表示从堆区开始分配. 你也可以参考microbench中的相关代码. 注意malloc()对返回的地址有一定的要求, 具体情况请RTFM.free()直接留空即可, 表示只分配不释放. 目前NEMU中的可用内存足够运行各种测试程序.
OS Syscall层面
堆区的使用情况是由libc来进行管理的, 但堆区的大小却需要通过系统调用向操作系统提出更改. 这是因为, 堆区的本质是一片内存区域, 当需要调整堆区大小的时候, 实际上是在调整用户程序可用的内存区域.
调整堆区大小是通过
sbrk()库函数来实现的, 它的原型是void* sbrk(intptr_t increment);用于将用户程序的program break增长
increment字节, 其中increment可为负数.所谓program break, 就是用户程序的数据段(data segment)结束的位置.
malloc()被第一次调用的时候, 会通过sbrk(0)来查询用户程序当前program break的位置, 之后就可以通过后续的sbrk()调用来动态调整用户程序program break的位置了.当前program break和和其初始值之间的区间就可以作为用户程序的堆区, 由
malloc()/free()进行管理.注意用户程序不应该直接使用
sbrk(), 否则将会扰乱malloc()/free()对堆区的管理记录.在Navy的Newlib中,
sbrk()最终会调用_sbrk()为了实现
_sbrk()的功能, 我们还需要提供一个用于设置堆区大小的系统调用.在GNU/Linux中, 这个系统调用是
SYS_brk, 它接收一个参数addr, 用于指示新的program break的位置.具体实现内容在堆区管理
OS MM层面

Klib层面的代码是我们为了测试AM而编写的malloc,实现可以不用去管
重点是OS Syscall和MM层面的:
sbrk和_sbrk均属于Navy-app中,即用户程序的libc库层面,由libc记录program break 用户堆信息,但是申请内存空间需要系统调用syscall的同意
用户堆和内核堆是不同的,我们的Navy-app用户程序在编译链接时并没有指定链接脚本,即其是按照默认的程序内存映射来的:
而内核堆即我们的内核代码AM和Nanos在编译链接通过linker.ld来指定了内存映像,所以在nemu的视角来看用户堆和内核堆的关系应该如下:
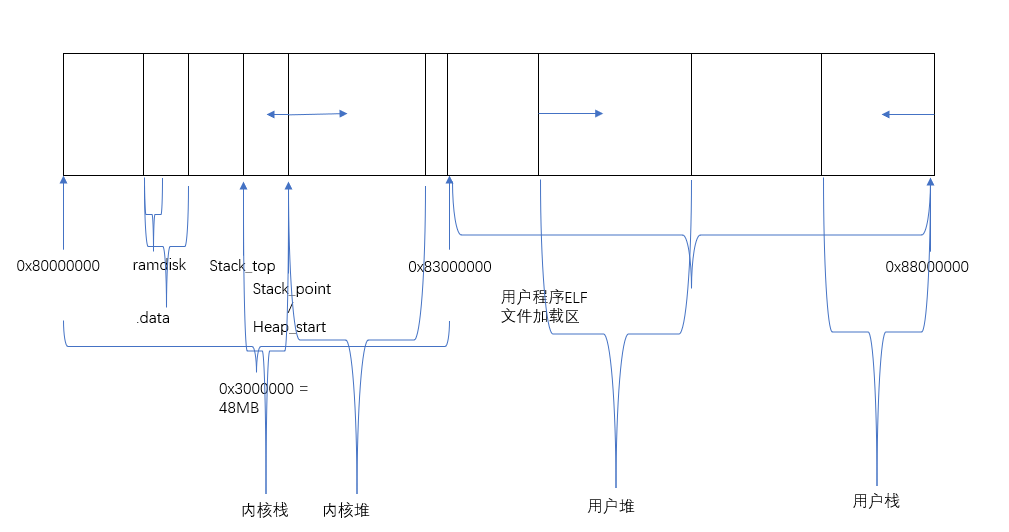
MM的相关内容是管理内核堆的,与用户堆内容无关。
实现带参数的execve()
我们来理一下当用户程序A通过execve调用用户程序B时发生了什么:
- 首先用户程序A调用
execve,触发系统调用,程序跳转到__am_asm_trap上运行 - 保存上下文后到
__am_irq_handle运行 - 识别为EVENT_SYSCALL, 然后程序跳转到
user_handler == do_event执行 - 接着被分发到
sys_execve处理 (通过sys_execve调用的context_uload表示是用户进程要执行某程序,而execve会使得原进程不再返回而是直接执行新进程,所以通过sys_execve调用的context_uload要覆盖掉当前的PCB,当前的PCB即是调用execve的用户进程; 同时内核也会调用context_uload,一般是分配新的PCB传入context_uload)- 在其中调用了
context_uload创建了B的上下文:- 此时的
PCB *current是A的上下文内容,我用B的上下文覆盖了A的上下文,即复用了A的PCB,即当前的PCB *current - 我调用
ucontext创建了B的上下文,同时 调用new_page申请了一块空间作为B的用户栈将B所需的参数Push进栈,依据约定我将B的用户栈argc所在的地址存放到了上下文的GPRx寄存器
- 此时的
- 然后我调用
switch_boot_pcb()切换了PCB *current - 然后调用yield
- 在其中调用了
- 接着又触发了ecall,程序跳转到
__am_asm_trap上运行,保存上下文后到__am_irq_handle运行,识别为EVENT_YIELD, 然后程序跳转到user_handler == do_event执行 - 接着分发到
schedule处理,返回了新的上下文c(要求这个新上下文就是我们的B程序的上下文) - c从
do_event返回给了__am_irq_handle,__am_irq_handle接着返回到__am_asm_trap, 这个值在a0寄存器中 __am_asm_trap中mv sp, a0, 即接下来恢复上下文是从新上下文中恢复,最终跳转到新的执行入口执行
至于讲义中有个奇怪的提示:
最后, 为了结束A的执行流, 我们可以在创建B的上下文之后, 通过
switch_boot_pcb()修改当前的current指针, 然后调用yield()来强制触发进程调度. 这样以后, A的执行流就不会再被调度, 等到下一次调度的时候, 就可以恢复并执行B了.
我想应该是讲义想要我们在init_proc中始终将pcb[0]用于context_kload,即先运行的始终是内核进程
然后再让pcb[1]成为我们用户进程使用的, 如此schedule不用变动也能够成功实现讲义中的要求
void init_proc() {
context_kload(&pcb[0], hello_fun, "context_kload text");
char *const argv[] = {"/bin/exec-test", NULL};
char *const envp[] = {NULL};
context_uload(&pcb[1], "/bin/exec-test", argv, envp);
switch_boot_pcb();
Log("Initializing processes...");
}
- 测试程序
navy-apps/tests/exec-test, 它会以参数递增的方式不断地执行自身. 不过由于我们没有实现堆区内存的回收,exec-test在运行一段时间之后,new_page()就会把0x3000000/0x83000000附近的内存分配出去, 导致用户进程的代码段被覆盖. 目前我们无法修复这一问题, 你只需要看到exec-test可以正确运行一段时间即可.
按照逻辑只有内核调用context_uload才能将用户栈分配到heap_end处,之后用户程序调用execve来执行新的用户程序,其栈都是在内核的堆中分配的一块空间
发现了一个严重的BUG:
在ics2023/nanos-lite/src/loader.c中的 context_uload函数中,如果参数pcb是传递的current的话,且先调用pcb->cp = ucontext(NULL, (Area) { pcb->stack, pcb->stack + sizeof(PCB) }, (void *)entry); 会导致参数char *const *argv, char *const *envp发生改变
这是一个很奇怪的现象
原因我有大概的想法,参数pcb是传递的current那么说明是用户程序A调用execve来执行新的用户程序B,参数char *const *argv, char *const *envp本来就在A的上下文中,若先调用pcb->cp = ucontext(NULL, (Area) { pcb->stack, pcb->stack + sizeof(PCB) }, (void *)entry);会导致修改A的上下文(因为A,B现在共用一个PCB上下文了),从而导致错误
static void sys_execve(Context *c){
const char *fname = (const char *)c->GPR2;
char *const* argv = (char *const *)c->GPR3;
char *const* envp = (char *const *)c->GPR4;
// printf("sys_execve fname: %s\n", fname);
// //debug
// for (int i = 0; argv[i]; i++) printf("argv[%d]: 0x%x %s\n", i, (uintptr_t)argv[i], argv[i]);
// if (argv[0] == NULL) printf("argv[0]: NULL\n");
// for (int i = 0; envp[i]; i++) printf("envp[%d]: 0x%x %s\n", i, (uintptr_t)envp[i], envp[i]);
// if (envp[0] == NULL) printf("envp[0]: NULL\n");
// if (current->cp == c) printf("yes\n");
//printf("nanos-lite sys_execve fname: %s\n", fname);
//naive_uload(NULL, fname);
//printf("1\n");
context_uload(current, fname, argv, envp);
//printf("2\n");
switch_boot_pcb();
//printf("3\n");
yield();
c->GPRx = 0;
}
这是我初步的猜想,现在要进行细致探索:
现在我想要搞清楚用户进程A在恢复上下文时到底用的哪个地址恢复的上下文?
B又是用哪个地址创建上下文的?
我们从内核线程开始:
我们最初的程序是内核程序,此时PCB为pcb_boot,内核的堆栈如下图:
当从内核执行到内核线程K,内核线程K的栈为pcb[0].stack,一个32KB的栈,堆还是内核堆
typedef union {
uint8_t stack[STACK_SIZE] PG_ALIGN;
struct {
Context *cp;
AddrSpace as;
// we do not free memory, so use `max_brk' to determine when to call _map()
uintptr_t max_brk;
};
} PCB;
内核线程K触发yield()--> 触发ecall,跳转到__am_asm_trap执行,将此时计算机(内核线程K)的上下文保存在pcb[0].stack中, pcb[0].cp始终指向着最初我们在pcb[0].stack中用最上的内存空间人工创建的上下文 -->
跳转到__am_irq_handle,接着跳转到do_event,接着调用了schedule处理了yield事件,结果是返回了用户进程A的上下文,此时用户进程的上下文在pcb[1].stack的最上的内存空间中,被pcb[1].cp指向-->
A的上下文一路被返回,最终到了__am_asm_trap的a0寄存器中,在__am_asm_trap中我们使用mv sp, a0,即我们是从pcb[1].stack中恢复的A的上下文 -->
在恢复上下文后,计算机的状态变成用户程序A的初始状态了,用户程序A的初始状态有如下重点:
-
将用户程序A的argc/argv/envp压入用户程序A的最后真正要使用的栈中
-
我们约定过,在内核中创建用户程序会将用户程序要使用的栈地址保存在pcb[1].stack即A的上下文的a0寄存器中
-
用户程序A要执行的入口地址
在__am_asm_trap最后的mret让pc从mepc获取要执行的地址,然后跳转到用户程序A的代码处执行-->
此时用户程序A的用户堆和用户栈如下图:
用户程序A调用execve执行用户程序B--> 用户程序A给用户程序B的参数放在寄存器a0,a1,a2上 -->触发ecall, 跳转到__am_asm_trap执行, 将此时计算机(用户程序A)的上下文保存在用户栈上-->
最终通过 sys_execve 处理事件,在其中:
- context_uload 人工创建了用户程序B的初始状态,此时current PCB为pcb[1],即用户程序A的PCB,我们将current传入context_uload中,当做用户程序B的PCB
- 其中若我们先调用ucontext,然后
pcb->cp = ucontext(NULL, (Area) { pcb->stack, pcb->stack + sizeof(PCB) }, (void *)entry);, - ...
- 好吧我感觉也没有关系哇
- 其中若我们先调用ucontext,然后
虚实交错的魔法
-
绝对代码:程序的内存位置是在链接时刻(link time)确定的(Navy-apps中的程序就是这样), 以前的程序员甚至在程序中使用绝对地址来进行内存访问, 这两种代码称为绝对代码(absolute code).
- 即编译/汇编时,所有指令和数据引用都已经固定为了某个具体的物理地址或线性地址。为链接时重定位
-
可重定位代码:为什么一定要提前确定一个程序的加载位置呢? 如果我们把链接时的重定位阶段往后推迟, 不就可以打破绝对代码的限制了吗?
- 程序在运行时刻并不知道重定位的目标内存位置是否空闲.
- 只有操作系统才知道内存是否空闲, 那就干脆让加载器来进行重定位吧, **于是有了"加载时(load time)重定位"的说法. **
- 具体地, 加载器会申请一个空闲的内存位置, 然后将程序加载到这个内存位置, 并把程序重定位到这个内存位置, 之后才会执行这个程序. 今天的GNU/Linux就是通过这种方式来插入内核模块的.
- 编译/链接阶段
- 链接器(linker)会生成两个部分:
- 机器码 本身(未确定的跳转/数据引用位置用占位符表示);
- 重定位表(relocation table),记录了哪些指令或数据需要在加载时“补地址”,以及如何补。
- 链接器(linker)会生成两个部分:
- 操作系统的加载器(loader)
- 操作系统知道当前内存的空闲分布,会为这个可重定位程序挑选一段合适的“空闲”线性地址空间;
- 把程序的机器码从磁盘拷贝到这段内存;
- 遍历重定位表,把所有占位符替换为“实际加载基址 + 原来偏移”——这一步就是“重定位”;
- 最后跳转到程序入口开始执行。
-
位置无关代码(PIC): 如果程序中的所有寻址, 都是针对程序位置来进行相对寻址操作, 这样的程序就可以被加载到任意位置执行, 而不会出现绝对代码的问题了
- 加载时重定位会带来额外的开销: 如果一个程序要被重复执行多次, 那么就要进行多次的加载时重定位.
- 今天的动态库都是PIC, 为PIE(position-independent executable, 位置无关可执行文件).
- 使用相对寻址会使得程序的代码量增大, 性能也会受到一些影响:
- 相对寻址计算访问地址需要先计算一个“基址”然后再通过这个基址访问目标,这样一来,每次访问一个地址就从「1 条」指令,变成了「2–3 条」指令。
有没有更好的, 一劳永逸的方案呢?
-
虚拟内存:一种尝试是把程序看到的内存和它运行时候真正使用的内存解耦开来. 这就是虚拟内存的思想.
- 在真正的内存(也叫物理内存)之上的一层专门给进程使用的抽象.
- 有了虚拟内存之后, 进程只需要认为自己运行在虚拟地址上就可以了, 真正运行的时候, 才把虚拟地址映射到物理地址.
- 实现方式:分段 / 分页
- 引入了虚拟内存机制, PC就是一个虚拟地址了, 我们需要在访问存储器之前完成虚拟地址到物理地址的映射.
- 操作系统无法干涉指令执行的具体过程. 所以让操作系统来把虚拟地址映射成物理地址, 是不可能实现的.
- 在硬件中进行这一映射是唯一的选择了: 我们在处理器和存储器之间添加一个新的硬件模块MMU(Memory Management Unit, 内存管理单元),
- 但是, 只有操作系统才知道具体要把虚拟地址映射到哪些物理地址上. 所以, 虚拟内存机制是一个软硬协同才能工作的机制:
- 操作系统负责进行物理内存的管理, **加载进程的时候决定要把进程的虚拟地址映射到哪些物理地址; **
- 等到进程真正运行之前, 还需要配置MMU, 把之前决定好的映射落实到硬件上, 进程运行的时候, MMU就会进行地址转换, 把进程的虚拟地址映射到操作系统希望的物理地址.
-
分段: 物理地址=虚拟地址+偏移量.
- 从直觉上来理解, 就是把物理内存划分成若干个段, 不同的进程就放到不同的段中运行, 进程不需要关心自己具体在哪一个段里面
- 分段机制在硬件上的实现可以非常简单, 只需要在MMU中实现一个段基址寄存器就可以了.
- 操作系统在运行不同进程的时候, 就在段基址寄存器中设置不同的值
- MMU会把进程使用的虚拟地址加上段基址, 来生成真正用于访问内存的物理地址,
- 现在的大部分操作系统都不再使用分段机制:
- 巨大无比的程序在一次运行当中只会触碰到很小部分的代码, 其实没有必要分配那么多内存把它们全部加载进来;
- 另一方面, 小程序运行结束之后, 它占用的存储空间就算被释放了, 也很容易成为"碎片空洞" - 只有比它更小的程序才能把碎片空洞用起来.
- 分段机制的简单朴素, 在现实中也许要付出巨大的代价. 事实上, 我们需要一种按需分配的虚存管理机制. 之所以分段机制不好实现按需分配, 就是因为段的粒度太大了
超越容量的界限
在分页机制上运行Nanos-lite
我们需要反其道而行之: 把连续的存储空间分割成小片段, 以这些小片段为单位进行组织, 分配和管理. 这正是分页机制的核心思想.

#define NULL 0(旧写法)或((void*)0)(有些环境下)只是编译器用来生成“空指针常量”的方式;从源码看,p = NULL;等价于p = (type*)0;。大多数现代操作系统(Linux、Windows、macOS 等)会在虚拟地址空间的最底部(线性地址 0x00000000 开始的几个页面)保持不映射状态。
当程序执行到
mov eax, [0](x86)或者更高层语言的*p(其中p == NULL)时,CPU 会将线性地址(0 + offset)发往 MMU 去做分页转换。分页单位发现该页不存在(PTE 的 Present 位=0),立即在硬件层面触发一个“缺页异常(page fault)”。
操作系统捕获这个异常,通常会把它映射为 Segmentation Fault(Linux 下的 SIGSEGV),进而终止程序。
mips32通过软件管理TLB
mips32简单地规定了虚拟地址空间的划分, 在PA中我们只会用到以下三段地址空间, mips32还规定了其余空间的性质, 具体可查阅手册:
[0x80000000, 0xa0000000)属于内核空间, 不进行地址转换[0xa0000000, 0xb0000000)属于I/O空间, 不进行地址转换[0x00000000, 0x80000000)属于用户空间, 需要进行地址转换mips32的内核空间不需要进行地址转换, 那么就不需要维护所谓的内核映射了;
mips32是以地址空间来决定是否需要进行地址转换, 那么也就不存在"分页机制是否开启"的状态了, 所以mips32中并没有类似CR0.PG这样的状态位.
- 在riscv32中我们要进行内核映射
- 在riscv32中我们要通过查看硬件(NEMU)判断分页机制是否开启
x86页级地址转换时出现的一种特殊情况. 由于x86并没有严格要求数据对齐, 因此可能会出现数据跨越虚拟页边界的情况。
例如一条很长的指令的首字节在一个虚拟页的最后, 剩下的字节在另一个虚拟页的开头. 如果这两个虚拟页被映射到两个不连续的物理页, 就需要进行两次页级地址转换, 分别读出这两个物理页中需要的字节, 然后拼接起来组成一个完成的数据返回.
riscv32作为RISC架构, 指令和数据都严格按照4字节对齐, 因此不会发生这样的情况, 否则CPU将会抛出异常
对于x86和riscv32来说, TLB一般都是由硬件来负责管理的: 当TLB miss时, 硬件逻辑会自动进行page table walk, 并将地址转换结果填充到TLB中, 软件不知道也无需知道这一过程的细节.
对PA来说, 这是一个好消息: 既然对软件透明, 那么就可以简化了. 因此如果你选择了x86或者riscv32, 你不必在NEMU中实现TLB.
S 模式提供一种传统的虚拟内存系统,它将内存划分为固定大小的页以进行地址翻译和内存保护。启用分页时,大多数地址(包括取数和存数的有效地址和 PC)都是虚拟地址
翻译过程需要遍历一种称为页表的多叉树。页表的叶子节点指示虚拟地址是否已被映射到一个物理页
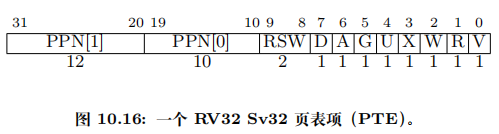
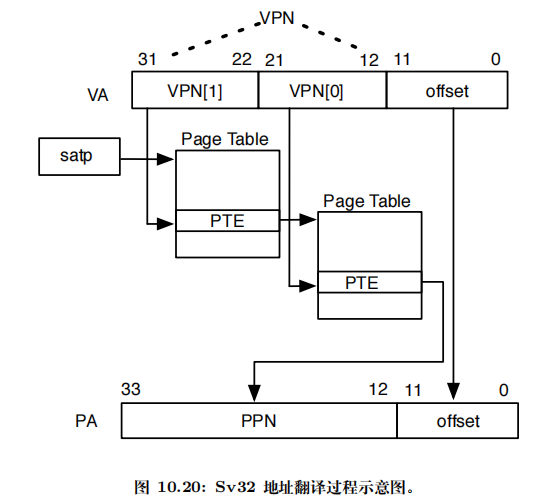
RISC-V 的分页方案以 SvX 的方式命名,其中 X 为虚拟地址的位宽。RV32 的分页方案 Sv32 支持4 GiB的虚拟地址空间:
-
V32 的分页方案 Sv32 支持4 GiB的虚拟地址空间,该空间被划分为 \(2^{10}\)个4 MiB的兆页,每个
兆页被进一步划分为\(2^{10}\)个4 KiB的基页,即分页机制的基本单位。
-
页表的每一项是 4 字节,故页表本身的大小为4 KiB。页表的大小正好是一个页, 这并非巧合,而是为了简化操作系统的内存分配机制。
-
-
分页机制由一个名为 satp(Supervisor Address Translation and Protection,监管模式地址翻译和保护)的 S 模式 CSR 控制。

- MODE 字段用于开启分页并选择页表级数
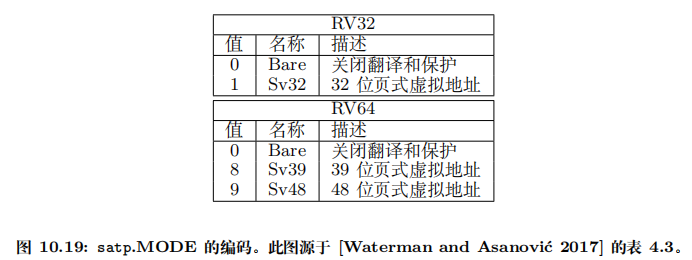
- ASID(Address Space Identifier,地址空间标识)字段是可选的,可用于降低上下文切换的开销。
- PPN 字段以4 KiB页为单位存放根页表的物理页号。
- 如何理解?什么叫做以4KiB为单位存放根页表的物理页号?其实可以想一想satp的PPN只有22位,如何想要完全放进32位的物理地址肯定是放不进去的。
- 其实我们也不需要存放完整的32位,因为对齐: RV32 默认的页面大小是 4 KiB(2¹² B)。这意味着所有的页表项都映射到 4 KiB 对齐的物理页框(physical page frame)上——也就是说,它的物理地址的底 12 位必然是 0, 所以我们将物理地址右移12位在放进PPN字段也没关系
- 通常 M 模式软件在第一次进入 S 模式前会将 satp 清零以关闭分页,然后 S 模式软件在创建页表后将正确设置 satp 寄存器
- MODE 字段用于开启分页并选择页表级数
RV64 支持多种分页方案,最常用的是 Sv39。与 Sv32 相同,Sv39 也使用4 KiB基
页。PTE 的大小变成两倍(8 字节),故能容纳更长的物理地址。为使页表和页的大
小保持一致,树的分叉数量降到 2^9,但变为三层。Sv39 的512 GiB地址空间被划分为
2^9 个1 GiB的吉页,每个吉页被进一步划分为 2^9 个2 MiB的兆页,略小于 Sv32 的兆
页。每个兆页被进一步划分为 2^9 个4 KiB的基页。
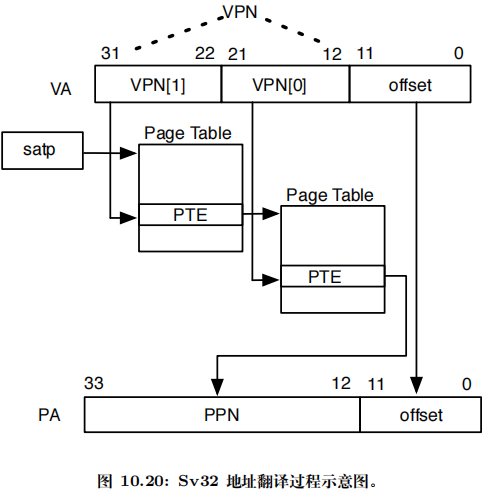
satp 寄存器启用分页时,处理器将从根部遍历页表,将 S 模式和 U 模式的虚拟地址翻译为物理地址。
-
satp.PPN 给出一级页表的基地址,VA[31:22] 给出一级索引,因此处理器将读取位于地址(satp.PPN×4096 + VA[31:22]×4)的 PTE;
-
该 PTE 包含二级页表的基地址,VA[21:12] 给出二级索引,因此处理器将读取位于地址(PTE.PPN×4096 + VA[21:12]×4)的叶子 PTE;
-
叶子 PTE 的 PPN 字段和页内偏移(原始虚拟地址的低 12 位)组成最终的物
理地址,即(LeafPTE.PPN×4096 + VA[11:0])。
等下,这里的PA物理内存有34位?
对的,需要注意的是SvX中的X表示虚拟内存地址的位数, Sv32 下的物理地址宽度 = PTE.PPN 总位数 + 页内偏移位数,这样设计的好处是:
- 支持更大的物理内存:尽管虚拟地址只 32 位(4 GiB 空间),机器可以接入多达 2³⁴ B = 16 GiB 的物理内存。
- 灵活可配置:具体能用多少位 PA,取决于实现里 PTE 中 PPN 字段的宽度,以及硬件真正支持的物理地址位数。
我在riscv 的特权指令手册Volume II中找到了satp对应的Number:
NEMU中并没有实现satp所以我们实现一下
// ics2023/nemu/src/isa/riscv32/include/isa-def.h
typedef struct {
word_t satp;
word_t mtvec;
vaddr_t mepc;
word_t mstatus;
word_t mcause;
} MUXDEF(CONFIG_RV64, riscv64_CSRS, riscv32_CSRS);
// ics2023/nemu/src/isa/riscv32/local-include/reg.h
static inline word_t *check_csrs_idx(word_t idx){
switch (idx)
{
case 0x180:
return &cpu.csrs.satp;
case 0x305:
return &cpu.csrs.mtvec;
case 0x341:
return &cpu.csrs.mepc;
case 0x300:
return &cpu.csrs.mstatus;
case 0x342:
return &cpu.csrs.mcause;
default:
panic("Unknown csr");
break;
}
}
在分页机制上运行用户进程
为此, 我们需要对工程作一些变动. 首先,编译Navy应用程序的时候需要为make添加VME=1的参数, 这样就可以将应用程序的链接地址改为0x40000000
// ics2023/abstract-machine/am/include/am.h
// Memory protection flags
#define MMAP_NONE 0x00000000 // no access
#define MMAP_READ 0x00000001 // can read
#define MMAP_WRITE 0x00000002 // can write
// ics2023/abstract-machine/am/src/native/platform.c
void __am_pmem_map(void *va, void *pa, int prot) {
// translate AM prot to mmap prot
int mmap_prot = PROT_NONE;
// we do not support executable bit, so mark
// all readable pages executable as well
if (prot & MMAP_READ) mmap_prot |= PROT_READ | PROT_EXEC;
if (prot & MMAP_WRITE) mmap_prot |= PROT_WRITE;
void *ret = mmap(va, __am_pgsize, mmap_prot,
MAP_SHARED | MAP_FIXED, pmem_fd, (uintptr_t)(pa - pmem));
assert(ret != (void *)-1);
}
依据如上信息我们就知道如何设置prot参数了:
不过, 此时
loader()不能直接把用户进程加载到内存位置0x40000000附近了, 因为这个地址并不在内核的虚拟地址空间中, 内核不能直接访问它.loader()要做的事情是, 获取程序的大小之后, 以页为单位进行加载:
- 申请一页空闲的物理页
- 通过
map()把这一物理页映射到用户进程的虚拟地址空间中. 由于AM native实现了权限检查, 为了让程序可以在AM native上正确运行, 你调用map()的时候需要将prot设置成可读可写可执行- 从文件中读入一页的内容到这一物理页中
所以我们应该把prot设置成为3
可以偷懒的一点是在AM native中实现了权限检查,但是我们的riscv中却没有,所以我们riscv中实现的map可以不用管prot这个参数
对齐
不过, 此时
loader()不能直接把用户进程加载到内存位置0x40000000附近了, 因为这个地址并不在内核的虚拟地址空间中, 内核不能直接访问它.loader()要做的事情是, 获取程序的大小之后, 以页为单位进行加载:
- 申请一页空闲的物理页
- 通过
map()把这一物理页映射到用户进程的虚拟地址空间中. 由于AM native实现了权限检查, 为了让程序可以在AM native上正确运行, 你调用map()的时候需要将prot设置成可读可写可执行- 从文件中读入一页的内容到这一物理页中
这一切都是为了让用户进程在将来可以正确地运行: 用户进程在将来使用虚拟地址访问内存, 在loader为用户进程维护的映射下, 虚拟地址被转换成物理地址, 通过这一物理地址访问到的物理内存, 恰好就是用户进程想要访问的数据.
在 RISC 风格的处理器(比如大多数 RISC-V、ARM(在早期或精简配置下)、PowerPC 等)上,“不支持非对齐访问”通常指的是:
任何一次载入(load)或存储(store)都必须满足“地址对齐”要求,否则硬件会抛出一个对齐异常(misaligned access exception),而不会自动拆分或合并多次内存访问。
对齐检查发生在虚拟地址还是物理地址?
- 虚拟地址层面
- CPU 在执行一条
load/store指令时,会先把它给出的虚拟地址(VA)与访问长度N做对齐检查。 - 如果
VA % N != 0,CPU 直接报对齐异常,根本不会走到页表翻译阶段。
- CPU 在执行一条
- 物理地址层面
- 如果虚拟地址对齐检查通过,CPU 再把它送到 MMU 做分页翻译,得到物理地址(PA)。
- 由于分页映射是按页(通常 4 KiB)对齐的,页内低 12 位是 VA==PA 的,因此对齐检查在 VA 上通过,也必然在 PA 上通过。
- 换句话说,你只要保证虚拟地址对齐,物理地址的对齐就自动成立。
为了测试实现的正确性, 我们先单独运行dummy(别忘记修改调度代码), 并先在
exit的实现中调用halt()结束系统的运行, 这是因为让其它程序成功运行还需要进行一些额外的改动. 如果你的实现正确, 你会看到dummy程序最后输出GOOD TRAP的信息, 说明它确实在分页机制上成功运行了.
记录下修改:
// 如下是为了测试而修改的
// ics2023/nanos-lite/src/syscall.c
static void sys_exit(Context *c){
halt(0);
}
// ics2023/nanos-lite/src/proc.c
void init_proc() {
Log("Initializing processes...");
switch_boot_pcb();
char *const argv[] = {NULL};
char *const envp[] = {NULL};
context_uload(&pcb[1], "/bin/dummy", argv, envp);
}
Context* schedule(Context *prev) {
current = &pcb[1];
return current->cp;
}
内核映射的作用

具体而言,这段代码在protect()中的作用主要是将内核虚拟内存映射的页目录内容复制到用户线程的页目录中
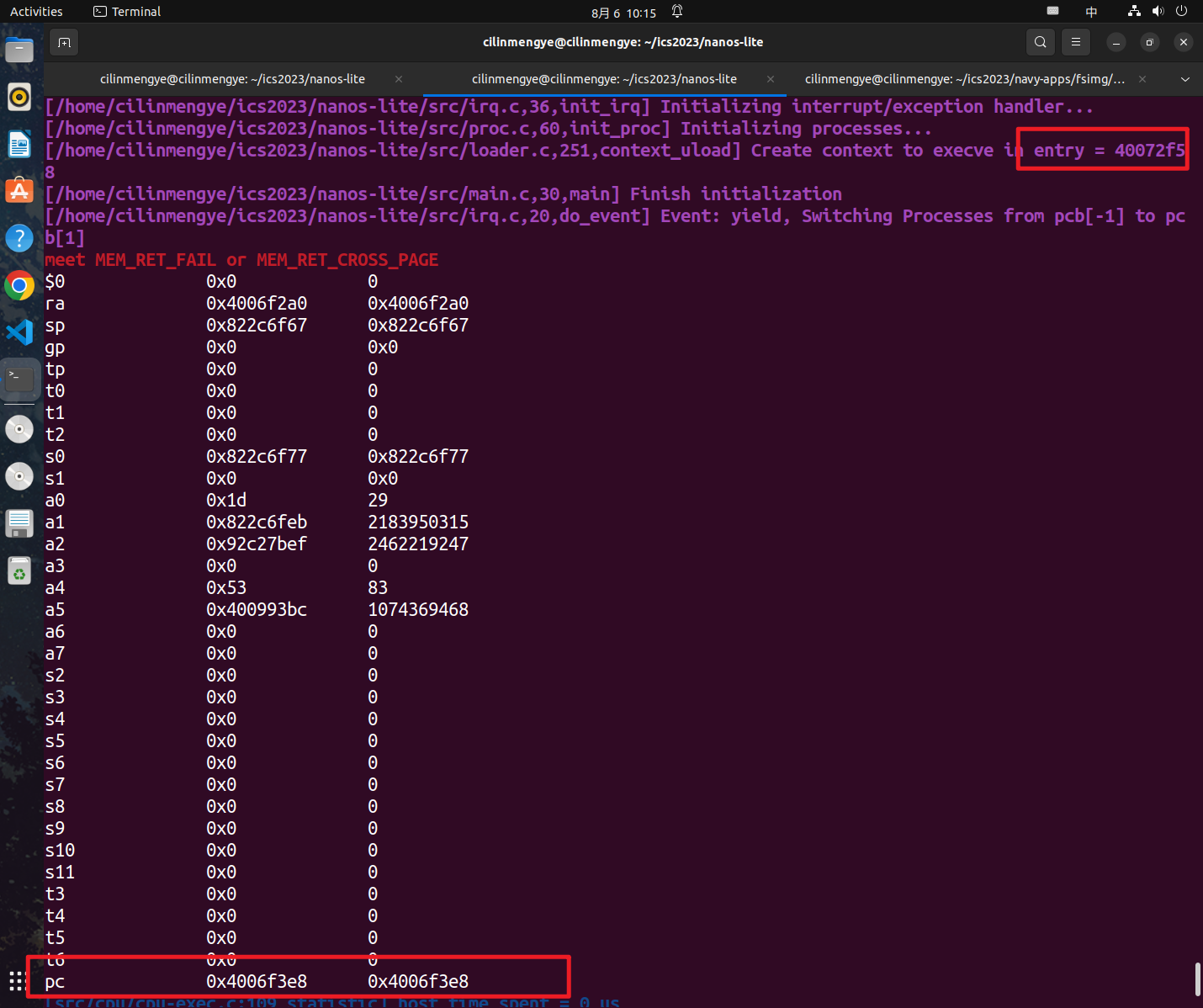
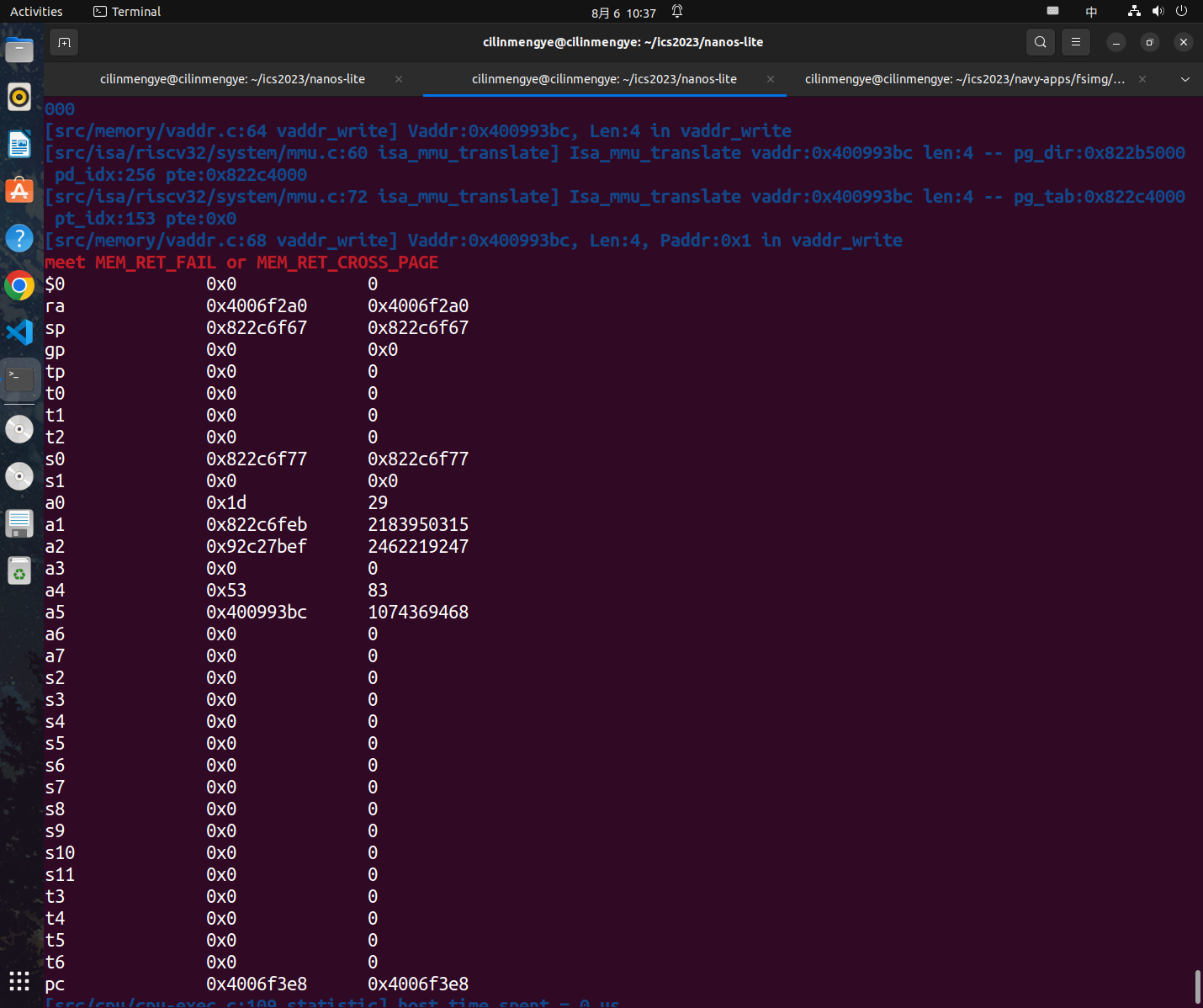
否则会有MEM_RET_FAIL的错误,即找不到对应的页
具体到保存上我是在执行ics2023/nemu/src/memory/vaddr.c中的word_t vaddr_ifetch(vaddr_t addr, int len)遇到了这个问题
vaddr_ifetch函数主要是在NEMU中取指令用的,当我们操行系统中切换到用户态时,satp寄存器其中表示页目录的地址也会进行变化,即切换到了用户线程的页目录地址
实现上述内容的操行系统代码在ics2023/abstract-machine/am/src/riscv/nemu/cte.c的__am_irq_handle函数中,在执行完__am_switch(c);后便达到了目标
但是此时我们还没有彻底执行完内核相关代码,我们还是需要在内核区取出指令,而此时我们又开启了虚拟内存又没有内核区的虚拟内存映射的页目录相关内容,所以就会发生上述报错
堆区管理
堆区的使用情况是由libc来进行管理的
调整堆区大小是通过
sbrk()库函数来实现的:void* sbrk(intptr_t increment);用于将用户程序的program break增长
increment字节, 即program break由libc来进行管理
sbrk()最终会调用_sbrk()其具体实现为:通过记录的方式来对用户程序的program break位置进行管理,
- program break一开始的位置位于
_end- 被调用时, 根据记录的program break位置和参数
increment, 计算出新program break- 通过
SYS_brk系统调用来让操作系统设置新program break- 若
SYS_brk系统调用成功, 该系统调用会返回0, 此时更新之前记录的program break的位置, 并将旧program break的位置作为_sbrk()的返回值返回- 若该系统调用失败,
_sbrk()会返回-1
在操作系统这边我们简化了实现,首先我们不会回收堆,我们的SYS_brk永远都是返回0
现在我们开了虚拟内存,我们在SYS_brk中要做的事情就是在虚拟地址new_program_break上 分配新页,注册新页, 其中new_program_break = program_break + increment
注意我们这里是非常简化的实现
我们还假设void *_sbrk(intptr_t increment) 中的increment>=0
思考题

native中实现VME的方式,其用一张哈希表来查找页表项,hash表的key值为页表项对应的虚拟地址va, value为页表项的物理地址,其中每个页表项竟占4KiB, 其页表项中的内容包括:
- va, pa, 下一个页表项节点指针,prot对应页的权限,is_mapped是否被映射
- char key[]用于hash查找,其中的内容为va
具体而言其有一个数据结构hash表,其大小为Addr_Range / PGSIZE, 即一级页表,其大小为页表项的个数
通过key(va的字符串)查找到对应页表项的物理地址(页表项地址通过pg_alloc申请而来)
同时页表项本身通过链表形式又组织到了一起

具体看 context_uload 中的实现,我是先申请了用户栈后再调用ucontext 在内核栈上创建用户进程上下文
对我而言我是可以在用户栈上创建用户进程上下文的

我认为是在函数中Context* __am_irq_handle(Context *c)执行__am_switch(Context *c)的原因
假设A程序要切换到B程序,那么直到执行到trap.S中mv sp, a0都是在用A程序的用户栈
但是__am_switch(Context *c)在mv sp, a0之前就把计算机的地址空间切换调了
即A程序还想用到其用户栈,但是在地址空间中已经找不到了(因为__am_switch(Context *c)将地址空间切换到了B的地址空间,B的地址空间页目录中没有A用户栈虚拟地址转换到物理地址的映射)
程序运行首先要获取指令,但是A程序的地址空间被切换调了,那么获取A程序的指令应该也是获取不到了,所以首先就应该看到取指的地方错误了:

DEBUG
如果遇到了如上指令层面的错误,比较好的方法是objdump查看下这个指令
那么原ELF文件在哪?首先navy-app的程序编译链接后的ELF文件在ics2023/navy-apps/fsimg/bin下,然后我们只要知道出错时加载的是哪个程序即可
一个好习惯或许是在实现重要内核的时候多使用Log和Assert来打印出一些重要的信息
pal程序相关加载位置:
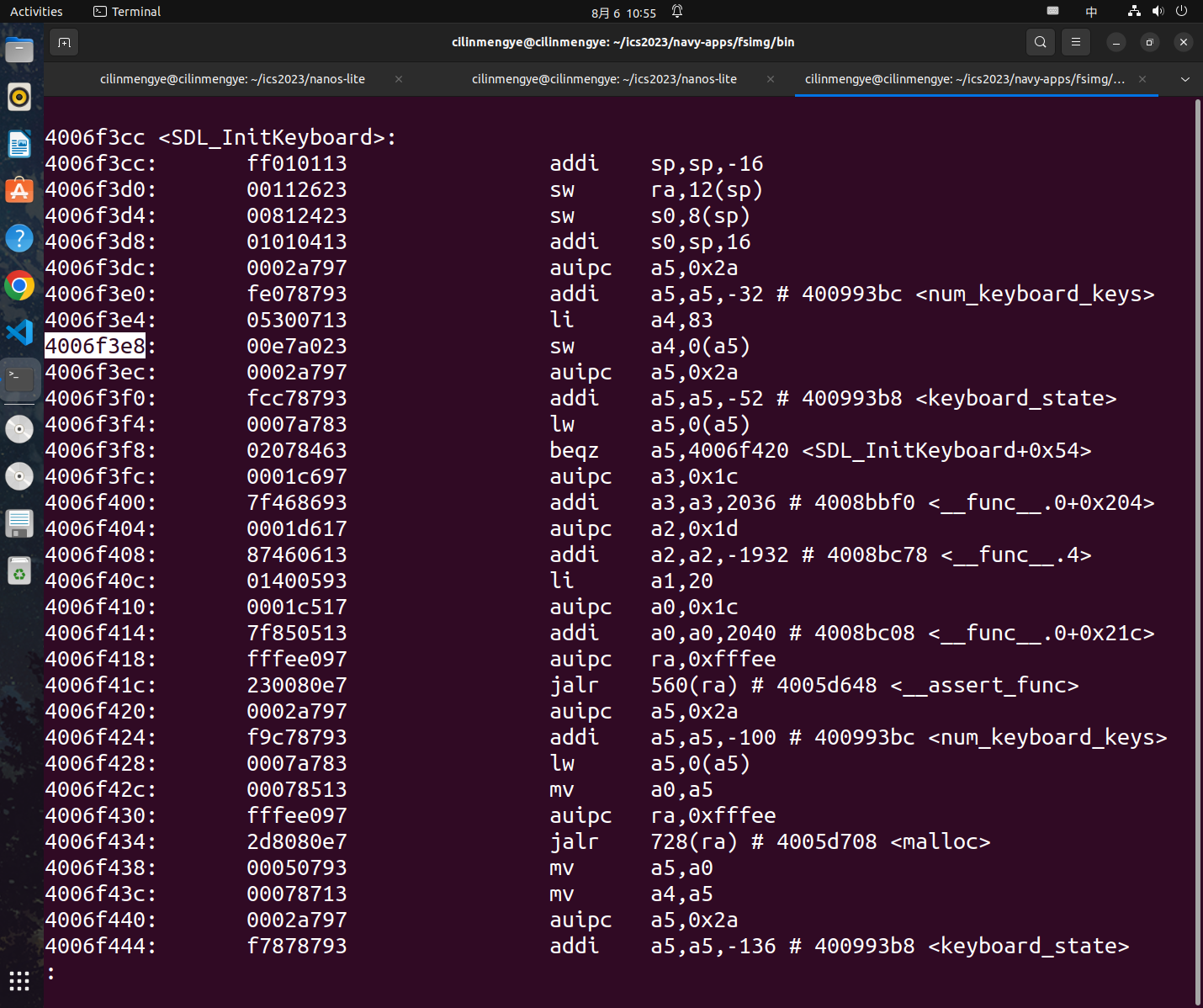
上述问题是loader中申请页面大小时写错了
这个问题主要是mm_brk中的内容写错了
总结
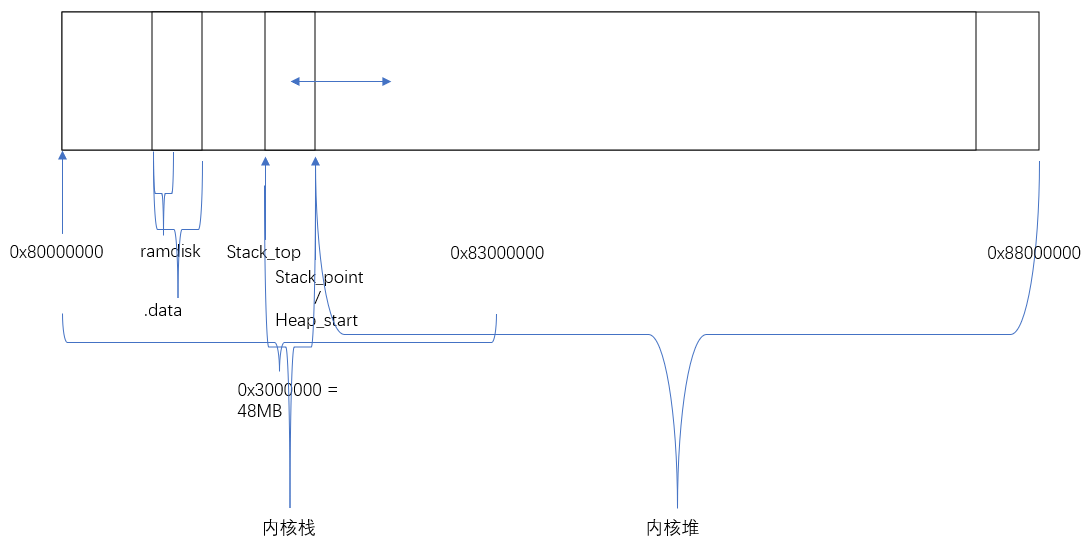
在实现虚拟内存后NEMU的内存布局如上
内核堆一直到0x88000000, 这是因为此时由内核管理物理内存的分配了,而空闲物理内存全部来自内核堆
可以说用户进程全部的空间地址来自这个内核堆,因为不管是加载器loader还是用户进程调用malloc时,都是内核在内核堆上以页为单位分配空间给用户进程
我们在实现虚拟内存时,内核有一个共同的va <--> pa的映射(即每个用户进程和内核线程看到了内核虚拟地址映射是一样的),且同时va == pa
在对用户进程进行虚拟地址管理时,每个进程都有一个页目录(因为我们是riscv32所以是采用二级页表)
页目录的地址由内核从内核堆中分配而来
我们将用户进程在链接时放到了0x40000000,这是虚拟地址,我们可以将其映射到不同的物理地址上,达到了可以运行多个用户进程的效果
在面对虚拟内存时,将虚拟地址和物理地址的转换和对应想象成如下会好很多:
同时可以把页目录和第二级页表想象成多叉树:

完成实验时要注意线程之间栈的切换和地址空间的切换
在nanos-lite中所谓的地址空间就是一种映射,其实现就是页表,即每个进程都有个地址空间
在abstract-machine/am/src/riscv/nemu/vme.c中一些重要的API:
void protect(AddrSpace *as)行为就是为用户进程创建初始的页目录和设置页目录映射的虚拟地址的范围void map(AddrSpace *as, void *va, void *pa, int prot)行为就是在as中保存的页目录中将虚拟地址va映射到物理地址pa上,这个过程可能需要我们创建二级页表,写页表项等- 注意 map 一次只能将映射一个va <-> pa 即一次映射的空间大小是一页 PGSIZE == 4KiB
- 在nanos-lite中设定虚拟地址上用户栈在用户地址范围的最后32KB


 浙公网安备 33010602011771号
浙公网安备 33010602011771号