性能分析 | Optimizing Multithreaded Applications

Parallel Performance Metric
并行应用的的性能指标总的可以分为两大类:
-
效率:用于评估多线程程序的好坏,分析CPU真正的利用率
- Effective CPU Utilization
-
可扩展性:用于评估性能随负载的变化而变化的情况
- Amdahl’s Law
- Universal Scalability Law (USL)
Effective CPU Utilization

-
Overhead Time: Threading libraries such as pthread, OpenMP, and Intel TBB incur additional overhead for creating and managing threads.
-
Spin Time: thread was just spinning in a busy-wait loop while waiting for a lock
-
ThreadCount: 在parallel applications中一般除了工作线程为,还有housekeeping threads,一般包括主线程、I/O 线程、监控/日志线程、调度线程等;我们“Thread Count” 一般指进程当前创建并可能会被调度执行的所有线程数量,不会区分它们是 worker 线程还是用于其他维护任务的线程。
- 辅助线程也会占用 CPU 时间(或在某些时刻被调度到 CPU 上),如果它们消耗显著时间,就会减少可分配给 worker 线程的 CPU 资源。
- 因此在评估并发度或配置 worker thread 数量时,需要考虑它们。
同时测量这些指标比较困难,作者提及到:
"Measuring overhead and spin time can be challenging, and I recommend using a
performance analysis tool like Intel VTune Profiler, which can provide these metrics."
影响CPU Time的有Wait Time,Wait Time包括:
- Sync Wait Time
- Preemption Wait Time
当线程不因同步(如等待锁、I/O 等)而阻塞,而是真正处于可运行状态(有工作要做),却没有被调度器分配到 CPU 运行,就产生了 Preemption Wait Time:
- 时间片轮转:线程用完分配给它的时间片,被调度器挂起,放回就绪队列,等待下一次调度。
- 优先级或调度策略:更高优先级的线程或实时/系统线程占用了 CPU,使该线程被抢占。
- CPU 资源不足(oversubscription):系统或应用创建的可运行线程数超过了可用逻辑核心数,导致一部分线程必须排队等待执行。
- 与其他进程/线程的竞争:除了本进程内的线程,还可能与操作系统自身线程或其他进程的线程争用 CPU,进一步增加等待。
高 Preemption Wait Time 往往意味着系统的可运行线程超过了可用 CPU,或优先级/负载分配不均衡:如果应用线程数远大于核心数,且多数线程长期保持可运行状态(计算密集型任务),就会导致轮流抢占,很多线程只能在队列中等待,增加了上下文切换开销,降低整体效率。
Performance Scaling in Multithreaded Programs
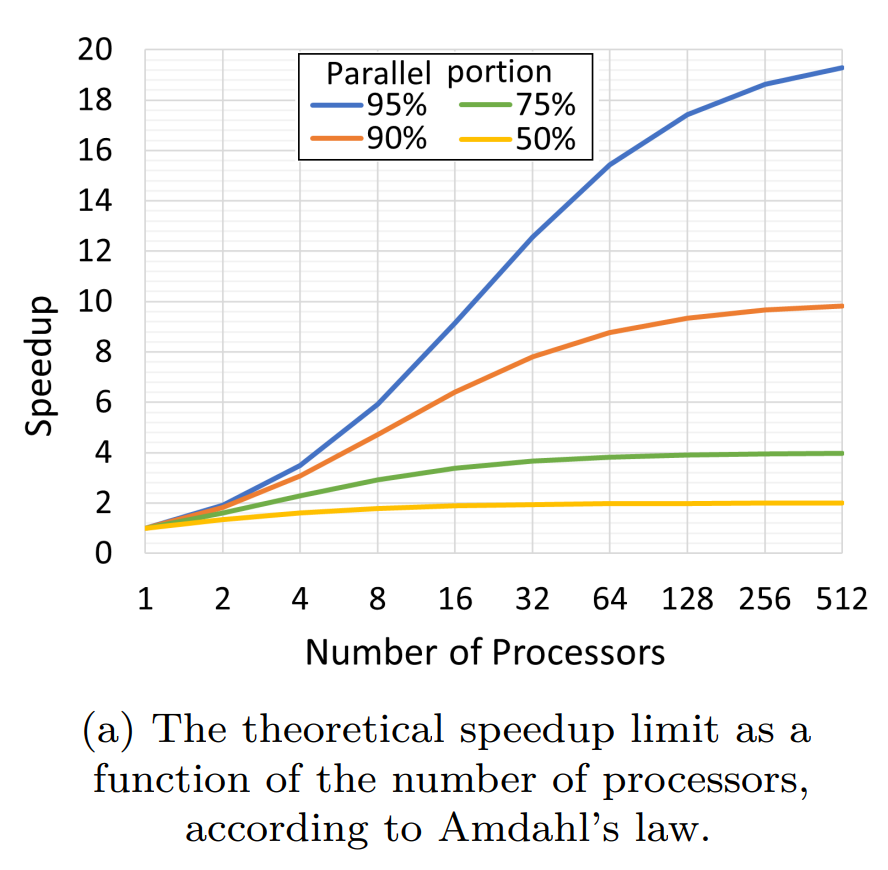
Amdahl’s Law
Amdahl's Law 是用来回答这样一个问题:
“如果一个任务中某一部分无法并行化,那么增加处理器数量对任务整体性能提升的上限是多少?”
它定义了 Speedup (加速度) 为:
其中:
- \(T(1)\):用一个处理器完成任务所需时间
- \(T(N)\):用 N 个处理器完成任务所需时间
Amdahl's Law 强调 任务执行时间的缩短,所以是基于 相对速度提升 来衡量多核带来的效果。
Universal Scalability Law (USL)
Universal Scalability Law (USL)是 Amdahl's Law 的扩展,用于描述和预测系统或应用在多处理器/多线程资源下的可扩展性(scalability)。
USL:评估吞吐量 Throughput
Universal Scalability Law (USL) 则是从更现实的角度出发:
“当并发负载增加时(线程/用户/处理器数量增加),应用系统的吞吐量会如何变化?”
它定义了吞吐量函数 \(X(N)\):
其中:
- \(X(N)\):系统处理 N 个并发实体(线程/用户)时的 吞吐量
- \(\gamma\):理想线性增长斜率(即无瓶颈下,每个线程能带来的单位吞吐量)
- \(\alpha\):资源争用引起的性能下降
- \(\beta\):一致性开销引起的性能下降
接下来我们会更加详细地讲解这个公式.
USL 可以看作对 Amdahl 定律的扩展,增加了二次项以捕捉通信互斥成本:
- 当\(\alpha = 0, \beta = 0\),表示理想线性可扩展,性能随并发实体数成正比。
- 当\(\alpha > 0, \beta = 0\), 表现为 Amdahl-like 的可扩展性,存在串行部分使得随着 N 增大,增益递减但不会倒退。
- 当\(\beta > 0\), 当 N 足够大时,\(\beta N(N - 1)\)项会主导,导致 C(N) 先增长到顶点,再因为通信/一致性开销增大而下降,即“峰值后倒退”。这解释了为何有些系统在增加更多线程/节点后反而吞吐下降。
同时函数 \(C(N)\)也为归一化(normalized throughput 或 capacity)是指将某个并发度下测得的性能,与单线程(或基准并发度)下的性能做比值,从而得到无量纲的比例值。
以吞吐率为例:
- X(1) 是在单线程(或基准点,比如只有 1 个工作单元)时测得的吞吐(如请求数/秒、任务数/秒等)。
- X(N) 是在并发度为 N(例如 N 个线程并行)时测得的实际吞吐。
- N 是系统负载,可分为软件负载和硬件负载
- 软件负载:N为 并发用户或请求来源数。在固定硬件平台上,逐渐增加用户数或负载发生器数量 N,观察系统在相同硬件配置下的吞吐变化。
- 硬件负载:N为处理器数量。保持每个处理单元上的负载固定(例如每处理器 100 个用户),然后增加处理器数量 N,观察系统总体吞吐如何变化。
由于定义上 \(C(N)\) 就是“相对于单线程吞吐的倍数”,即:
在 USL 模型中,假设单线程吞吐 \(X_1\) 可测且稳定,于是:
- 我们首先测得或假设 \(X_1\)。
- 用 USL 公式计算 \(C(N) = \frac{N}{1 + \alpha (N - 1) + \beta N(N - 1)}\)。
- 由此得出预测吞吐 \(X(N)\approx X_1 \times C(N)\)。
我们直接将\(X_1\)定义为\(\gamma\), 那么就有:
当我们测量出了N和X(N)时,可以通过拟合得到USL中\(\gamma, \alpha, \beta\)三个参数值:
- 若 α 较大,说明资源竞争严重,要优化锁、队列、临界区等;
- 若 β 较大,说明通信/一致性开销占优,要考虑减少跨实体通信、优化缓存策略或批量处理;
- 从拟合曲线可找出最佳并发或最佳节点数(峰值点),避免超出导致吞吐下降。
Thread Count Scaling Case Study
如果我的处理器有四个 P 核和八个 E 核。P 核启用了 SMT(超线程),这意味着该平台上的线程总数为 16 个(只有P核有超线程)。
默认情况下,Linux 调度程序会首先尝试使用空闲的物理 P 核。前四个线程将使用四个空闲 P 核上的四个线程。
当四个 P 核都充分利用后,调度程序将开始在 E 核上调度线程。因此,接下来的八个线程将被调度到八个 E 核上。
最后,剩下的四个线程将被调度到 P 核的四个同级 SMT 线程上。
因为 E 核的性能低于 P 核。一旦开始使用 E 核,性能扩展就会变慢。同级 SMT 线程也无法提供良好的性能扩展。
频率限制是实现良好线程数扩展的主要障碍。任何使用多硬件线程的应用程序都会因热限制而遭遇频率下降。拥有更高 TDP(热设计功耗)处理器和先进液冷解决方案的平台则不太容易受到频率限制的影响。
事实上,频率限制是现代系统中未实现的性能扩展的很大一部分原因。
内存带宽限制。这是许多高性能计算 (HPC) 和人工智能 (AI) 工作负载的常见问题。一旦达到这一限制,其他一切都变得不那么重要,包括代码优化,甚至 CPU 频率。L3 缓存和 I/O 是共享资源的其他例子,它们经常成为瓶颈。
并发应用程序的性能可能会受到线程间同步的限制。有些程序的线程间交互非常复杂,因此在时间轴上可视化工作线程非常有用。此外,您还应该了解如何使用性能分析工具查找竞争锁。
from PERFORMANCE ANALYSIS AND TUNING ON MODERN CPUS -- Denis Bakhvalov

 浙公网安备 33010602011771号
浙公网安备 33010602011771号