2025 南京大学操作系统原理 | 虚拟机、容器、微服务和 Serverless

绪论
jyy老师的这节课从full system emulation的黄金时代开始,重点讲解了虚拟机的基本实现原理;再到黄金时代过后的Linux Namespace(操作系统自己就可以虚拟化自己);最后到今日,容器的出现开启了云原生,微服务,Serverless等一系列概念;
最终展望,计算机是否会消失?只有终端和云的时代
虚拟机 full system emulation
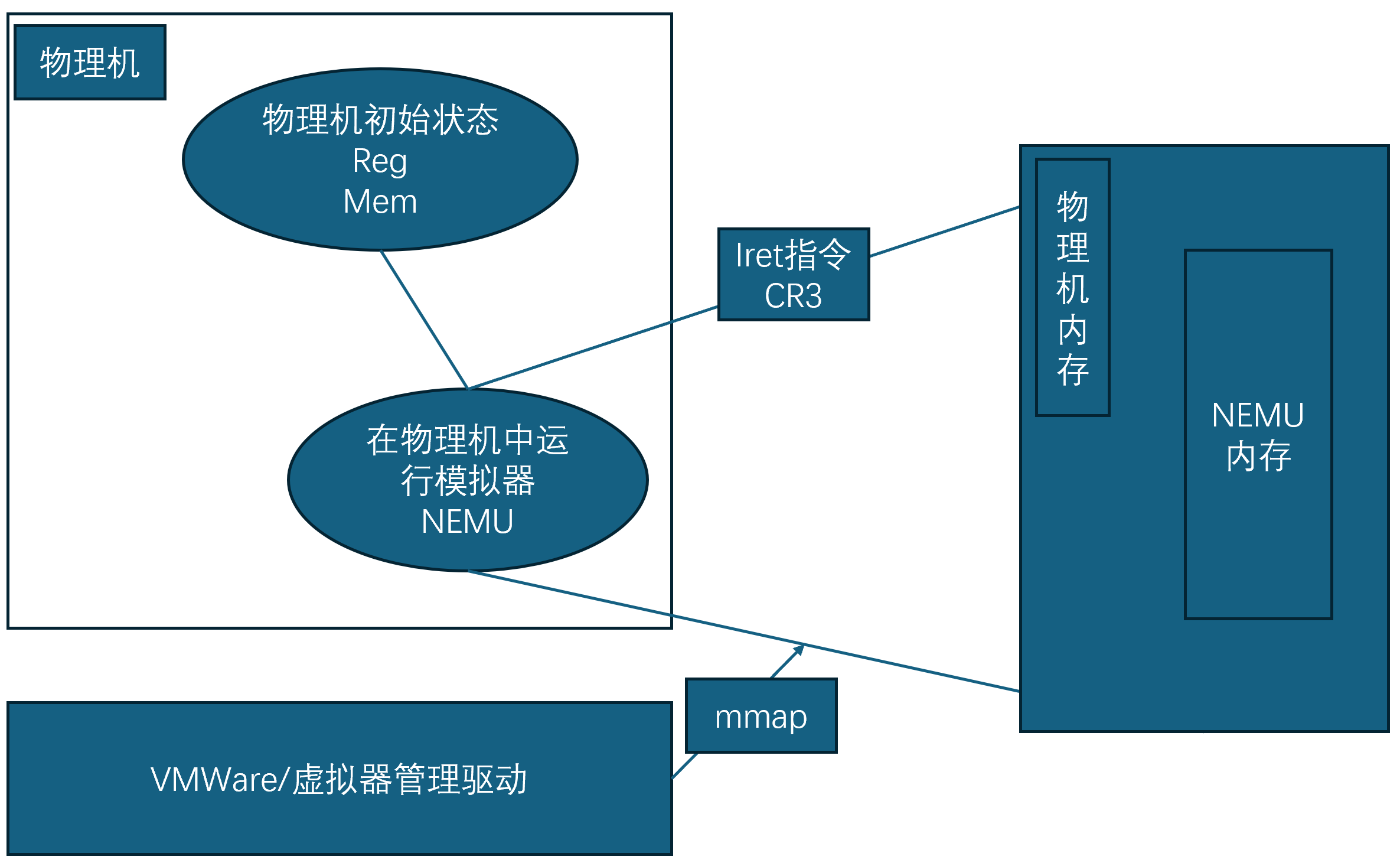
最初虚拟机的想法就像我们实现的NEMU一样,通过模拟底层硬件,解释执行二进制指令实现一个模拟系统。
但是这样的虚拟机很慢,有没有提高虚拟机速度的方法?
VMWare做到了,其基本想法是将虚拟机的用户态程序"拉出"虚拟机到本地物理机的用户态运行,若虚拟机程序需要执行内核态程序则再回到虚拟机的内核态中模拟执行
注意虚拟机也模拟了一个虚拟机的操作系统,也就是说虚拟机也有自己的用户态和内核态
当虚拟机解释执行到"iret"指令时,VMWare驱动会将虚拟机的状态映射到物理机的内存中,实现让虚拟机的用户态直接运行在物理机的用户态。
Guest Ring 3 直接运行在 Host Ring 3 System call 会 trap 到 VMWare驱动中。
Ring 3 表示的是用户态,即虚拟机的用户态直接运行在物理机的用户态,当虚拟机用户态程序触发Syscall指令时,会陷入VMWare驱动中处理,最终回到虚拟机中模拟执行这次Syscall
内核态程序基本都是系统调用:
系统调用是用户程序请求操作系统提供某些服务或操作的接口。操作系统内核提供了很多系统调用,允许用户程序访问硬件资源或进行一些特殊操作。用户程序通常不直接与硬件交互,它通过系统调用来向内核请求服务。
常见的系统调用
-
文件操作相关的系统调用:
open(): 打开一个文件read(): 读取文件write(): 向文件写入数据close(): 关闭文件
-
进程控制相关的系统调用:
fork(): 创建一个子进程exec(): 执行一个程序wait(): 等待子进程结束exit(): 退出进程
-
内存管理相关的系统调用:
mmap(): 映射文件或设备到内存brk(): 调整进程的堆大小munmap(): 解除内存映射
-
设备管理相关的系统调用:
ioctl(): 控制设备read(),write(): 用于设备读写
-
网络相关的系统调用:
socket(): 创建一个套接字bind(): 绑定一个地址到套接字send(),recv(): 发送和接收网络数据
-
进程间通信(IPC)相关的系统调用:
pipe(): 创建一个管道msgget(),msgsnd(),msgrcv(): 消息队列操作semop(): 信号量操作
后续Intel下场,让虚拟机更快地运行...
Linux NameSpace 和 容器
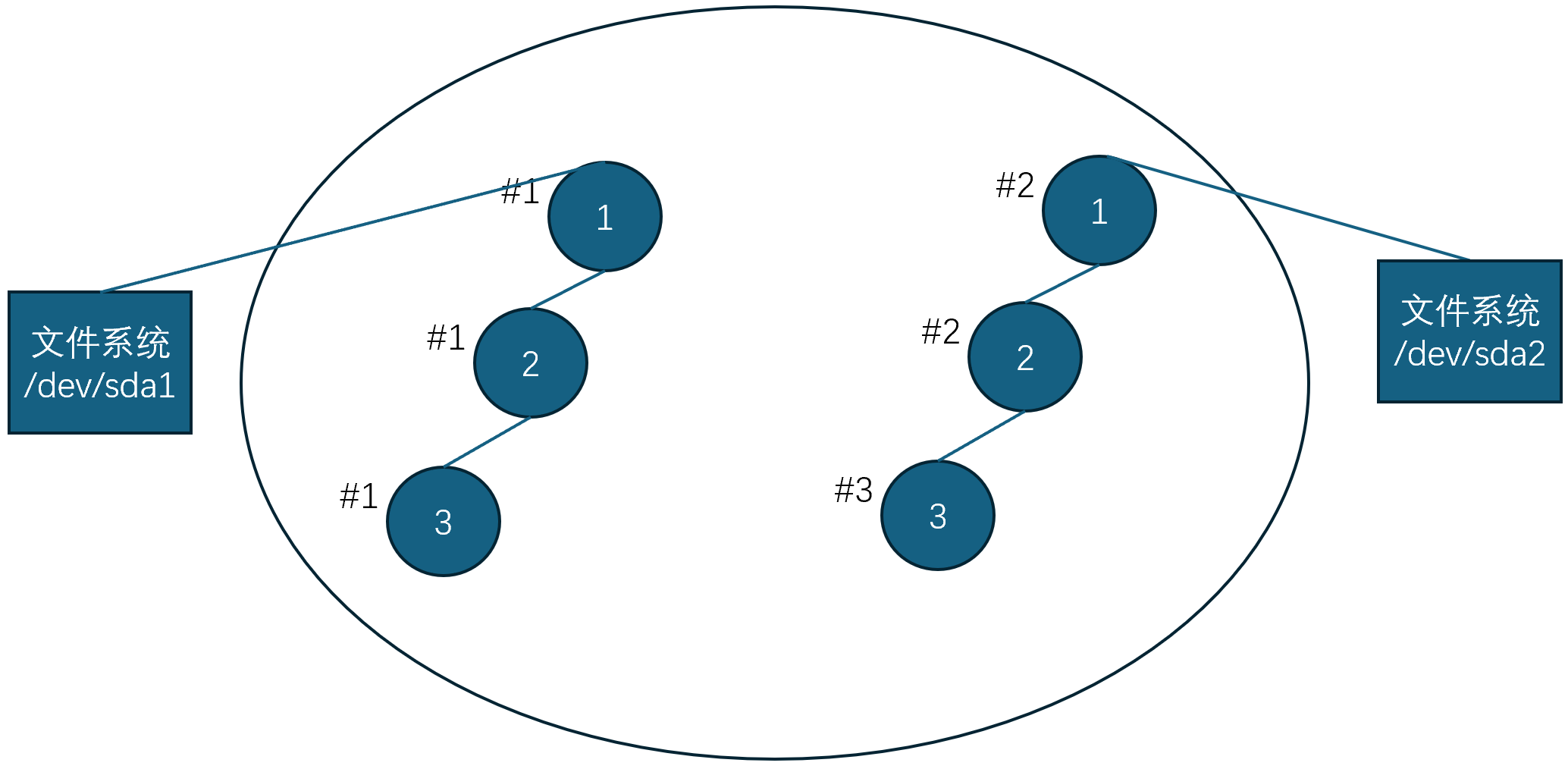
- pid 可以不再是整个操作系统唯一的
- 给每个进程增加一个 “osid”(如图中的#1和#2),增加系统调用 vos(fs_root)
- 创建一个新的 osid,pid 从 1 开始分配
- fork() 继承父进程的 osid
这就是Linux Namespace的基本思想
Linux Namespace 是 Linux 内核提供的一种资源隔离机制,它允许将系统的全局资源划分为多个独立的命名空间(Namespace),使得每个命名空间中的进程只能看到和操作属于该命名空间的资源,从而实现进程之间的隔离。

Linux 系统需要为不同的进程组(不同的osid)提供独立的资源视图(所谓的资源如上图"操作系统里的对象"),例如端口localhost:5000资源需要虚拟化,不仅仅是osid 1的进程组能够监控端口localhost:5000,osid 2的进程组也需要。

使用 ps 命令查看当前终端的进程, 然后查看当前终端进程所属的namespace,我们能够查看到各个操作系统的对象
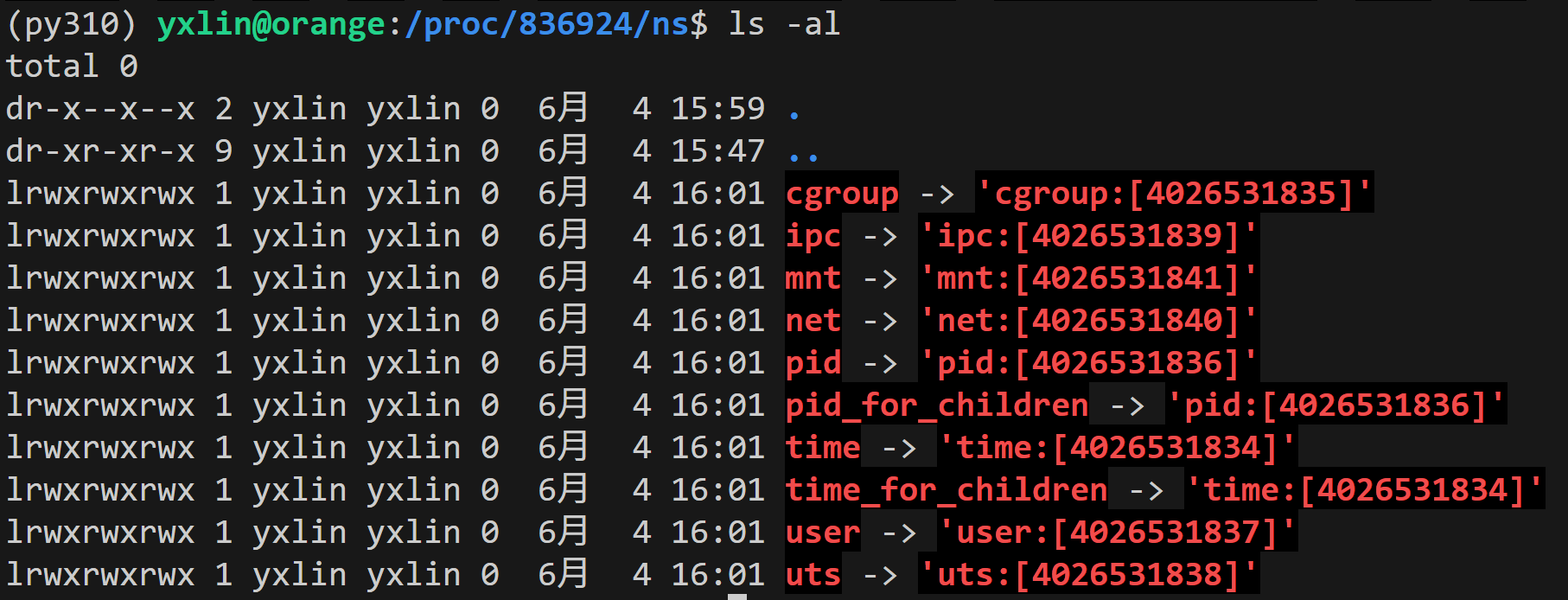
pid:[数字]中的数字表示当前namespace id,当然我们除了这个namespace id,我们是看不到其他namespace id的
当我们"圈"一些进程,设定资源使用策略时,那么我们就实现了cgroups
cgroups(Control Groups)是 Linux 内核提供的一项功能,允许管理员和程序对系统资源的分配进行限制和管理。它的主要目的是对一组进程(包括线程)进行资源隔离、分配、优先级控制等操作。通过 cgroups,系统管理员可以控制进程使用的资源,如 CPU、内存、磁盘 I/O 和网络带宽等。
cgroups 通过将进程分组到不同的控制组(Control Group)中来管理资源。每个控制组可以设定特定的资源限制(如 CPU、内存等),进程只能在这些限制范围内运行。
cgroups 是以层次结构组织的,意味着一个控制组可以包含多个子组。这些组可以继承父组的资源限制。每个控制组可以管理不同类型的资源控制子系统(如 CPU、内存、I/O 等)。
namespace(资源隔离) + cgroup(资源控制) 就得到了容器,我们为每个容器在用户态下提供Linux 用户态环境(如busybox)即系统中的系统, 我们就得到了docker
BusyBox 并不是一个完整的操作系统,而是一个集成了多个常用 Unix/Linux 命令和工具的轻量级可执行程序。它通常被用于构建嵌入式系统或资源受限环境中的最小化用户空间。
云原生与微服务
- 如果只需要 Linux
- 容器就和虚拟机完全一样
- 开销比虚拟机低很多,安全性略低
我们能够较为轻松地知道容器的状态。并且移动容器的状态,例如当一个容器a运行在A机器上,当A机器资源不足时,我们可以关闭容器a复制其状态到B机器上运行
- Kubernetes: “容器编排”
- 跨主机、弹性自动编排
- 自动容错:这是云厂商最爱看到的
云原生是一种构建和运行应用程序的方法,充分利用云计算的弹性、可扩展性和自动化特性。
微服务是一种架构风格,将应用程序拆分为一组小型、独立的服务,每个服务运行在自己的进程中,并通过轻量级的通信机制(如 HTTP API)相互协作。
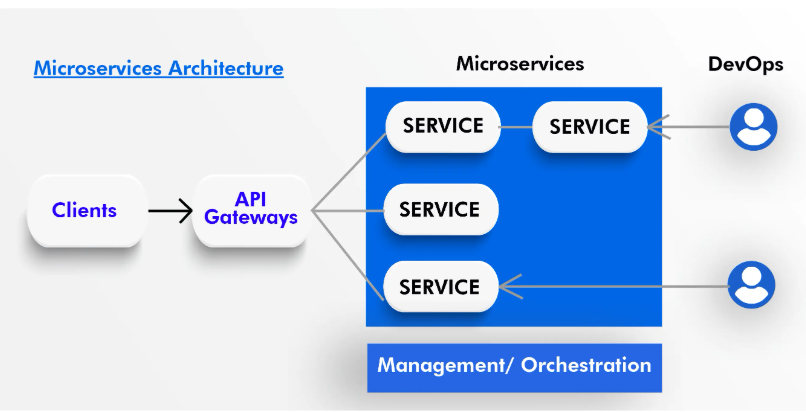
其实就是将程序拆成 Microservices,运行在容器中,Cloud Native:云会负责容器管理、API Gateway、负载均衡
所谓的serverless即是舍弃容器的概念,将用户所写的函数按照调用次数/流量计费
之前是按照卖整个机器赚钱(实际上云厂商买给的是超额预售的容器),现在卖服务流量
Cgroup
虽然讲解的案例和实践方案是cgroup v1的,但是核心知识点还是一样的
The Linux Kernel Control Group v2
man 7 cgroups 可以查看 cgroup 的整体概念以及 v1/v2 的区别
cgroup重点要理解的是cgroups子系统(控制器),cgroups 层级结构(Hierarchy)和cgroups文件系统
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
- cpu 子系统,主要限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
...
我们有个根cgroup,一般为cgroups文件系统的挂载点/sys/fs/cgroup,cgroups文件系统是一种虚拟文件系统(VFS (Virtual File System)),以统一的文件系统API将cgroup的功能暴露出来给用户态的进程使用
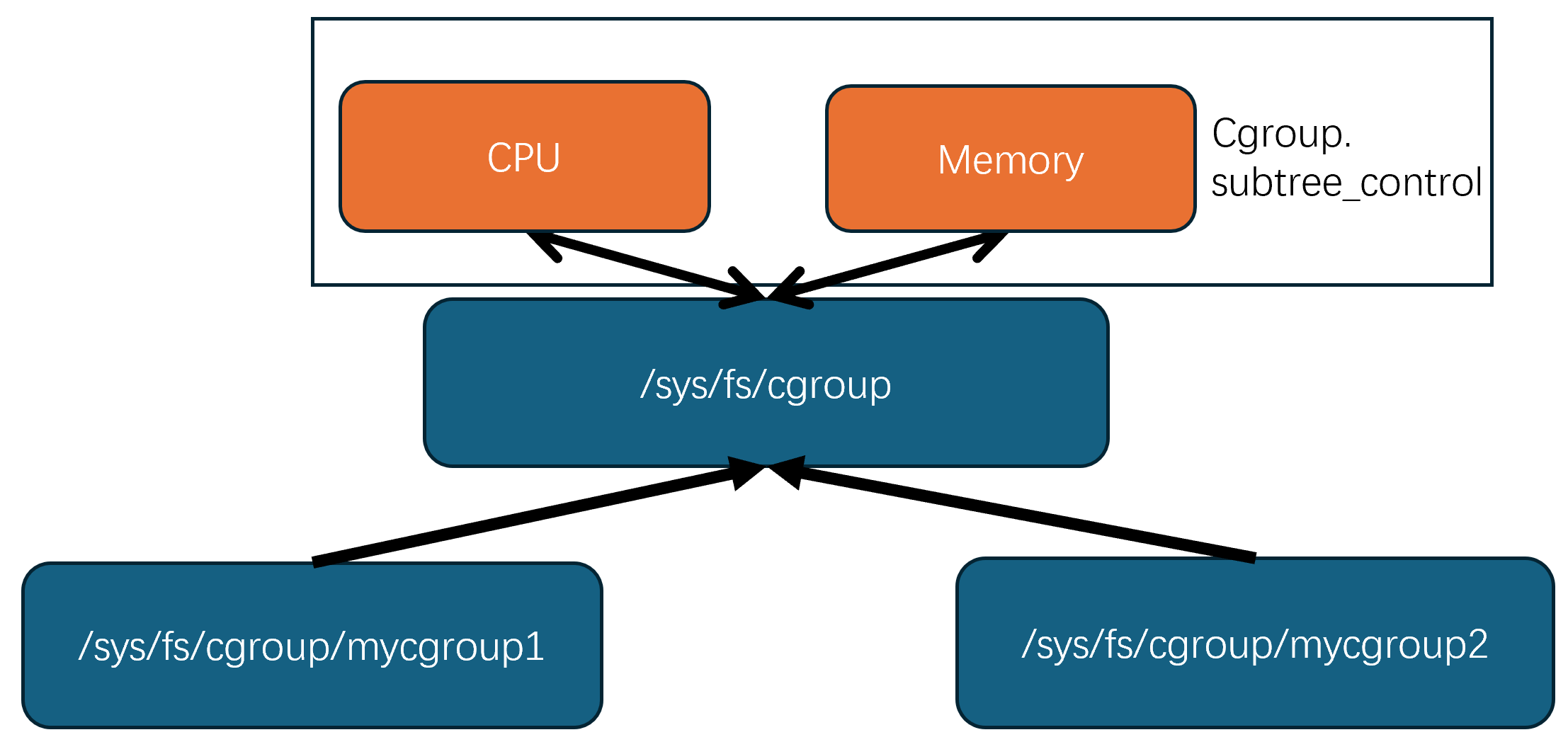
在cgroup v2中,根cgroup下可以创建多个子cgroup组,子cgroup组同样可以创建其子cgroup组,形成树的层次结构
cgroup控制器通过写入/sys/fs/cgroup/cgroup.subtree_control来与根cgroup attach
在 cgroup v2 中,控制器(如 memory、cpu 等)必须逐级向下启用,即:
你必须先在 父 cgroup 的 cgroup.subtree_control 中启用控制器,
然后才能在 子 cgroup 中使用这些控制器。
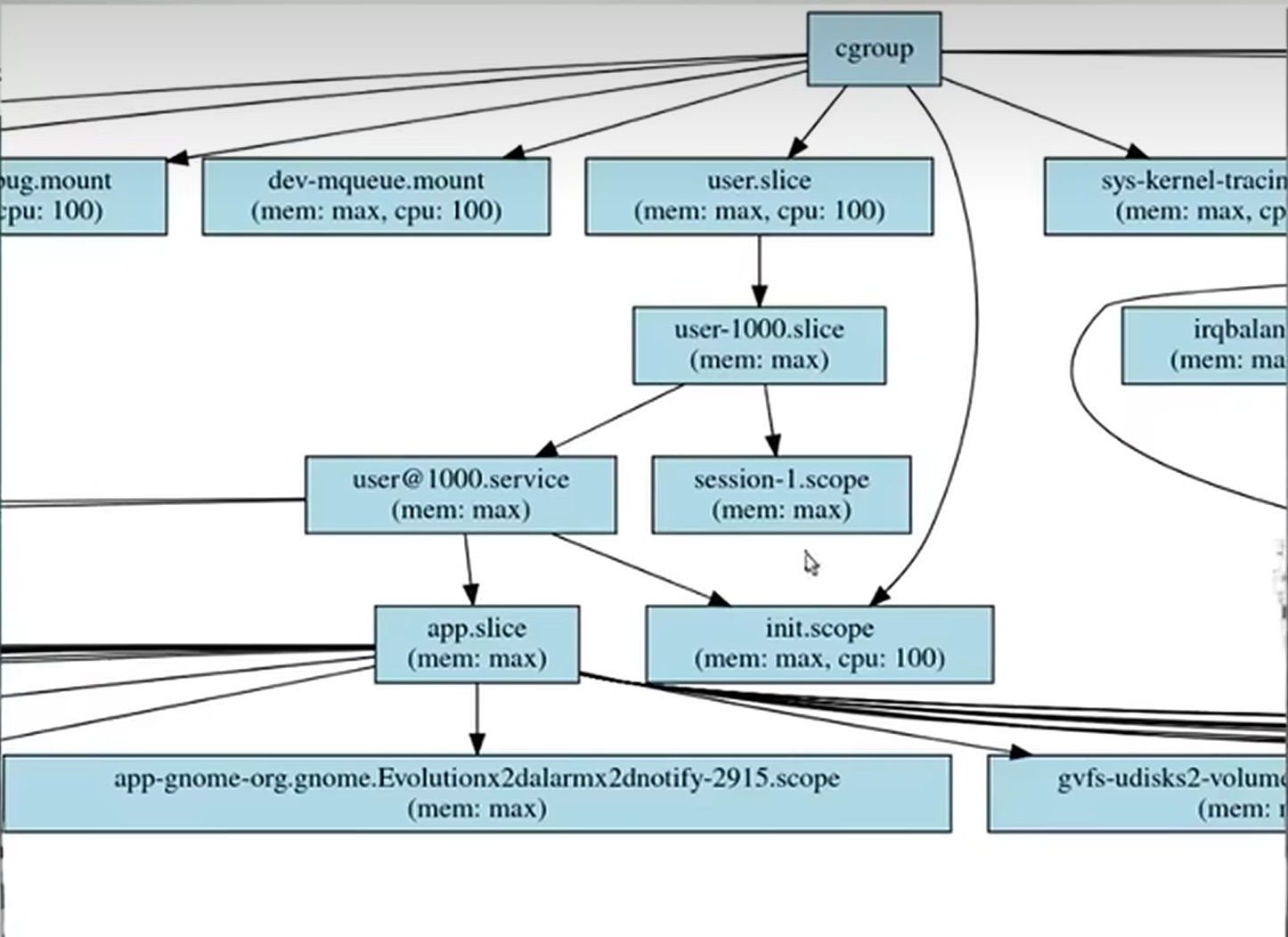
为了展现cgroup的层次结构,我也模仿jyy老师让GPT给我氛围编程了下,让其写了个python脚本解析/sys/fs/cgroup下的层次结构和文件内容,并生成.dot文件,并最终转为.svg图片
.dot 文件是 Graphviz 图形可视化软件使用的一种文本文件格式,描述图(graph)的结构
.svg 文件是一种 可缩放矢量图形(Scalable Vector Graphics)格式,用于在网页或其他环境中以矢量形式显示图像。
/sys/fs/cgroup$ ls
cgroup.controllers cgroup.stat cpuset.mems.effective io.cost.model memory.numa_stat proc-sys-fs-binfmt_misc.mount system.slice
cgroup.max.depth cgroup.subtree_control cpu.stat io.cost.qos memory.pressure sys-fs-fuse-connections.mount user.slice
cgroup.max.descendants cgroup.threads dev-hugepages.mount io.pressure memory.reclaim sys-kernel-config.mount
cgroup.pressure cpu.pressure dev-mqueue.mount io.prio.class memory.stat sys-kernel-debug.mount
cgroup.procs cpuset.cpus.effective init.scope io.stat misc.capacity sys-kernel-tracing.mount
在其下的user.slice/user-1024.slice
在 systemd 的 cgroup 层级中,user.slice 用来承载各个用户的资源分组,每个登录或激活的用户会对应一个子 slice,命名为 user-
.slice。
ps
PID TTY TIME CMD
2780895 pts/13 00:00:00 bash
2797709 pts/13 00:00:00 ps
cat /proc/2780895/cgroup
0::/user.slice/user-1024.slice/session-26872.scope
可知通过/proc/$pid/cgroup我们能够知道进程在cgroup层次结构下的路径
下面给出一个从头到尾的 cgroup v2 创建及资源限制设置示例,以 Bash 命令行操作为主。
1. 确认 cgroup v2 已挂载
$ mount | grep cgroup2
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime)
若没有挂载,可执行:
sudo mkdir -p /sys/fs/cgroup
sudo mount -t cgroup2 none /sys/fs/cgroup
2. 在根 cgroup 下创建一个子组
这里我们创建一个名为 mygroup 的控制组目录:
cd /sys/fs/cgroup
sudo mkdir mygroup
3. 打开子控制器(subtree_control)
要让 mygroup 接受 CPU 和 memory 两个控制器的管理,需要在根组或上级目录开启它们:
# 先到根组开启
cd /sys/fs/cgroup
sudo sh -c 'echo "+cpu +memory" > cgroup.subtree_control'
如果你的系统已经在更高层级(如 system.slice)管理,需相应地在上级目录开启。
4. 设置资源限制
4.1 CPU 限制
cpu.max接受两个参数:quota period(微秒)。- 例如:
100000 100000表示在每 100 ms 周期内允许最多 100 ms 的 CPU 时间(即 100% 单核)。
cd /sys/fs/cgroup/mygroup
sudo sh -c 'echo "100000 100000" > cpu.max'
4.2 内存限制
memory.max:最大可用内存(字节),写入max表示不限制。memory.high:软限制,当使用超过时会触发回收,但不直接 OOM。
sudo sh -c 'echo $((512*1024*1024)) > memory.max' # 限制为 512 MiB
sudo sh -c 'echo $((400*1024*1024)) > memory.high' # 400 MiB 软限制
5. 将进程加入 cgroup
假设要把当前 shell(PID=$$)加入 mygroup,以后在此 shell 启动的所有命令都受限:
sudo sh -c 'echo $$ > cgroup.procs'
或者指定其他进程:
sudo sh -c 'echo 12345 > /sys/fs/cgroup/mygroup/cgroup.procs'
6. 验证限制生效
-
CPU 使用情况(
cpu.stat):cat /sys/fs/cgroup/mygroup/cpu.stat -
内存使用情况(
memory.current):cat /sys/fs/cgroup/mygroup/memory.current -
进程列表:
cat /sys/fs/cgroup/mygroup/cgroup.procs
7. 示例:在受限环境中运行工作负载
# 在 mygroup 下启动一个持续占用 CPU 的示例脚本
sudo sh -c 'echo $$ > /sys/fs/cgroup/mygroup/cgroup.procs'
yes > /dev/null &
再查看 CPU 使用:
watch -n1 cat /sys/fs/cgroup/mygroup/cpu.stat

 浙公网安备 33010602011771号
浙公网安备 33010602011771号