并行计算架构和编程 | Assignment 3: A Simple CUDA Renderer

GPU的编译
使用 nvcc 一步完成编译与链接
nvcc -o vector_add vector_add.cu
nvcc 会自动将设备代码编译为 PTX/Cubin,调用主机编译器(如 g++)编译主机部分,并自动链接 CUDA 运行时库 cudart 等
或者分步编译与手动链接
nvcc vector_add.cu -c -o vector_add.o
g++ vector_add.o -o vector_add \
-L/usr/local/cuda/lib64 -lcudart
一个makefile的案例:
EXECUTABLE := cudaSaxpy
CU_FILES := saxpy.cu
CU_DEPS :=
CC_FILES := main.cpp
###########################################################
ARCH := $(shell uname -m)
ifeq ($(ARCH), aarch64)
CXX = g++
else
CXX = g++ -m64
endif
OBJDIR=objs
CXXFLAGS=-O3 -Wall
ifeq ($(ARCH), Darwin)
# Building on mac
LDFLAGS=-L/usr/local/depot/cuda-8.0/lib/ -lcudart
else
# Building on Linux
LDFLAGS=-L/usr/local/cuda/lib64/ -lcudart
endif
NVCC=nvcc
NVCCFLAGS=-O3 -m64
OBJS=$(OBJDIR)/main.o $(OBJDIR)/saxpy.o
.PHONY: dirs clean
default: $(EXECUTABLE)
dirs:
mkdir -p $(OBJDIR)/
clean:
rm -rf $(OBJDIR) *.ppm *~ $(EXECUTABLE)
$(EXECUTABLE): dirs $(OBJS)
$(CXX) $(CXXFLAGS) -o $@ $(OBJS) $(LDFLAGS)
$(OBJDIR)/%.o: %.cpp
$(CXX) $< $(CXXFLAGS) -c -o $@
$(OBJDIR)/%.o: %.cu
$(NVCC) $< $(NVCCFLAGS) -c -o $@
Part 1: CUDA Warm-Up 1: SAXPY (5 pts)
CUDA Memory Management API
CUDA内核执行的异步性
By defult a CUDA kernel's execution on the GPU is asynchronous with the main application thread running on the CPU.
double startTime = CycleTimer::currentSeconds();
saxpy_kernel<<<blocks, threadsPerBlock>>>(N, alpha, device_x, device_y, device_result);
double endTime = CycleTimer::currentSeconds();
saxpy_kernel<<<blocks, threadsPerBlock>>>(N, alpha, device_x, device_y, device_result);执行是异步的,可以使用cudaDeviceSynchronize()等待GPU上全部的线程执行完成。
结果
# cudaMalloc没有算入计时
Running 3 timing tests:
Effective BW by CUDA saxpy: 33.943 ms [32.926 GB/s]
Effective BW by CUDA saxpy: 2.183 ms [511.949 GB/s]
Effective BW by CUDA saxpy: 2.167 ms [515.745 GB/s]
# cudaMalloc算入计时
Running 3 timing tests:
Effective BW by CUDA saxpy: 257.310 ms [4.343 GB/s]
Effective BW by CUDA saxpy: 241.463 ms [4.628 GB/s]
Effective BW by CUDA saxpy: 126.805 ms [8.813 GB/s]
# CPU顺序执行
[saxpy serial]: [73.333] ms [20.320] GB/s [2.727] GFLOPS
我的GPU为NVIDIA GeForce RTX 4090: SMs: 128, Memory Bandwidth 1008 GB/sec
可以看到即使设置threadsPerBlock = 512(即block = 195313), GPU相比CPU顺序执行加速比似乎也没有那么大。
同时当cudaMalloc算入计时,执行时间明显变大,甚至超过CPU顺序执行,因为大部分时间都用于传输数据了:Optimizing Host-Device Data Communication I - Pinned Host Memory
First, the communication between the host and device are the slowest link of data movement involved in GPU computing, so it is important we optimize transfers.
Part2: CUDA Warm-Up 2: Parallel Prefix-Sum (10 pts)
CUDA 对每个线程块(block)中线程数有严格硬件限制
- 对于 Compute Capability < 2.0 的设备,每个 block 最多 512 个线程。
- 对于 Compute Capability ≥ 2.0 的设备,每个 block 最多 1024 个线程。
- 如果启动时 threadsPerBlock > 最大值,CUDA Runtime 会报错并拒绝执行 kernel
即使执行了kernel也会出现计算不正常的情况,要十分小心。
有时候因为设置blockDim超过了硬件的限制,有时用Catching CUDA Erro甚至抓不住。
可以尝试在CUDA的核函数中使用printf打印下,如果在核函数中的printf没有输出,说明核函数没有执行
stack overflow: CUDA max threads in a block
直接在 Host 代码里对 device 指针解引用是否合法?
cudaMemcpy(device_result, inarray, (end - inarray) * sizeof(int), cudaMemcpyHostToDevice);
device_result[N - 1] = 0;
上述操作是否合法?
不可以。
CUDA 的编程模型中,Host(CPU)和 Device(GPU)各自拥有独立的地址空间,cudaMalloc() 分配的指针只能在 Device 上解引用(读写)而不能在 Host 上直接访问。
试图在 Host 上使用 device_result[N-1] = 0; 这种写法,本质上就是在 Host 空间去解引用一个不属于它的地址,会导致未定义行为,通常是奔溃或静默失败
我显示的是段错误
Catching CUDA Errors
stack overflow: What is the canonical way to check for errors using the CUDA runtime API?
#define DEBUG
#ifdef DEBUG
#define cudaCheckError(ans) { cudaAssert((ans), __FILE__, __LINE__); }
inline void cudaAssert(cudaError_t code, const char *file, int line, bool abort=true)
{
if (code != cudaSuccess)
{
fprintf(stderr, "CUDA Error: %s at %s:%d\n",
cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
#else
#define cudaCheckError(ans) ans
#endif
cudaCheckError( cudaMalloc(&a, size*sizeof(int)) );
数据并行模型
所谓数据并行模型定义为将计算组织为元素序列上的运算,即对一个序列上的全部元素执行函数。如Numpy。
基于CUDA同样可以使用数据并行模型的思维,将要操作的数据组织成序列,对于序列中的每个元素使用一个线程执行操作。
Exclusive Prefix Sum
实现一个无数据依赖的扩展前缀和算法:
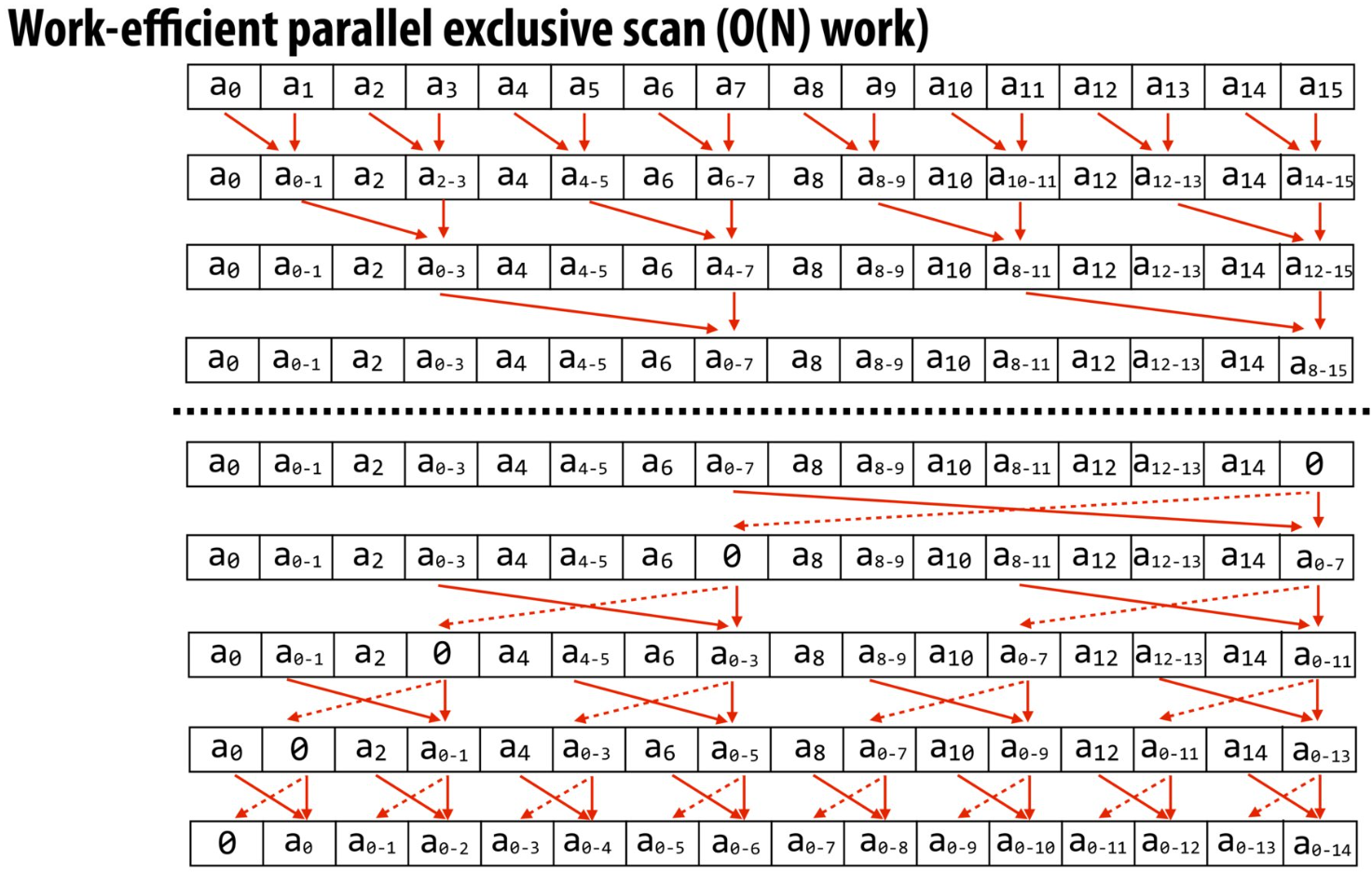
我们的并行机会在于每一行的序列元素,正如讲义所提及到的:
void exclusive_scan_iterative(int* start, int* end, int* output) {
int N = end - start;
memmove(output, start, N*sizeof(int));
// upsweep phase
for (int two_d = 1; two_d <= N/2; two_d*=2) {
int two_dplus1 = 2*two_d;
parallel_for (int i = 0; i < N; i += two_dplus1) {
output[i+two_dplus1-1] += output[i+two_d-1];
}
}
output[N-1] = 0;
// downsweep phase
for (int two_d = N/2; two_d >= 1; two_d /= 2) {
int two_dplus1 = 2*two_d;
parallel_for (int i = 0; i < N; i += two_dplus1) {
int t = output[i+two_d-1];
output[i+two_d-1] = output[i+two_dplus1-1];
output[i+two_dplus1-1] += t;
}
}
}
我们可以对将for循环对元素的操作利用CUDA改造成序列操作,对于每一个元素使用一个线程。
对于每个序列需要操作的元素个数是不一样的,这要求我们动态地计算kernel的blockNum和threadPerBlock.
static inline std::pair<int, int> calGridBlock(int N, int two_d) {
// 注意到threadPerBlock == 512 == 2^9,totalThread一定是2的倍数(因为我们保证N是2的倍数)
// 所以除了totalThread <= threadPerBlock外,blockNum = totalThread / threadPerBlock一定是整数
const int threadPerBlock = 512;
int two_dplus1 = 2 * two_d;
int totalThread = N / two_dplus1;
int blockNum;
if (totalThread <= threadPerBlock) return {1, totalThread};
blockNum = totalThread / threadPerBlock;
return {blockNum, threadPerBlock};
}
__global__ void Parallel_Upsweep(int two_d, int *output) {
int two_dplus1 = 2 * two_d;
int i = two_dplus1 * (blockIdx.x * blockDim.x + threadIdx.x);
output[i + two_dplus1 - 1] += output[i + two_d - 1];
}
__global__ void Set_Zero(int N, int *output) {
output[N - 1] = 0;
}
__global__ void Parallel_Downsweep(int two_d, int *output) {
int two_dplus1 = 2 * two_d;
int i = two_dplus1 * (blockIdx.x * blockDim.x + threadIdx.x);
int t = output[i + two_d - 1];
output[i + two_d - 1] = output[i + two_dplus1 - 1];
output[i + two_dplus1 - 1] += t;
}
void exclusive_scan(int* input, int N, int* result)
{
//由算法所要求的,N必须为2的倍数。
N = nextPow2(N);
for (int two_d = 1; two_d <= N / 2; two_d *= 2) {
auto [blockNum, threadPerBlock] = calGridBlock(N, two_d);
Parallel_Upsweep<<<blockNum, threadPerBlock>>>(two_d, result);
cudaDeviceSynchronize();
}
Set_Zero<<<1, 1>>>(N, result);
cudaDeviceSynchronize();
for (int two_d = N / 2; two_d >= 1; two_d /= 2) {
auto [blockNum, threadPerBlock] = calGridBlock(N, two_d);
Parallel_Downsweep<<<blockNum, threadPerBlock>>>(two_d, result);
cudaDeviceSynchronize();
}
}
Implementing "Find Repeats" Using Prefix Sum
本质上是要求我们基于数据并行模型实现一个无锁的“查找A[i] == A[i+1]的i下标”的功能
__global__ void findRepeat_Flag(int *input, int N, int *output) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N - 1) output[i] = (input[i] == input[i + 1]);
}
__global__ void findRepeat_Set(int *flags, int *idxs, int N, int *output) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N - 1 && flags[i] == 1) output[idxs[i]] = i;
}
// find_repeats --
//
// Given an array of integers `device_input`, returns an array of all
// indices `i` for which `device_input[i] == device_input[i+1]`.
//
// Returns the total number of pairs found
int find_repeats(int* device_input, int length, int* device_output) {
int res;
int *device_flag, *device_idx;
int rounded_length = nextPow2(length);
cudaMalloc((void **)&device_flag, sizeof(int) * rounded_length);
cudaMalloc((void **)&device_idx, sizeof(int) * rounded_length);
const int threadPerBlock = 512;
int blockNum = (length + threadPerBlock - 1) / threadPerBlock;
// GPU并行计算数组元素是否满足device_input[i] == device_input[i + 1]
findRepeat_Flag<<<blockNum, threadPerBlock>>>(device_input, length, device_flag);
cudaDeviceSynchronize();
cudaMemcpy(device_idx, device_flag, sizeof(int) * length, cudaMemcpyDeviceToDevice);
// 对device_flag求扩展前缀和
// 最大问题是我们如何将符合device_input[i] == device_input[i + 1]的i并行地放入device_input中?
// 通过对device_flag求扩展前缀和得到的device_idx就可以知道放入device_input下标了
// 即满足device_flag[i] == 1时的i,在device_idx[i]中的值即是device_input的下标
// 即if (device_flag[i] == 1) device_input[device_idx[i]] = i;
exclusive_scan(device_flag, length, device_idx);
cudaDeviceSynchronize();
findRepeat_Set<<<blockNum, threadPerBlock>>>(device_flag, device_idx, length, device_output);
cudaMemcpy(&res, device_idx + length - 1, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(device_flag);
cudaFree(device_idx);
return res;
}
Part 3: A Simple Circle Renderer (85 pts)
CUDA原子操作
CUDA 在全局(global)和共享(shared)内存上提供了一整套原子(atomic)操作函数,涵盖算术运算、位操作和比较-交换等多种原子读–改–写原语,保证在多线程并发访问同一内存地址时不会发生竞态条件。
- atomicAdd(address, val):对 *address 执行原子加法,返回操作前的旧值;支持 int、unsigned int、unsigned long long 以及 float 重载。
CUDA核函数中能不能使用二维数组?
在 CUDA 编程中,主机端(CPU)可以像在普通 C/C++ 一样声明 T array[H][W] 的二维数组;但在 设备端(GPU),由于内存模型限制,通常需要将二维逻辑映射到一维连续内存
CUDA传递单个简单变量
在 CUDA 中你完全可以像在普通 C/C++ 中那样,将单个标量变量(如 int、float 等)按值传递给核函数(kernel)
无需显式拷贝或 cudaMalloc
CUDA核函数中也能够使用assert进行断言
CUDA核函数中为何难以实现动态数据结构(链表,树等)
-
动态内存分配的限制:
- CUDA核函数中无法直接调用malloc或cudaMalloc,动态内存需预先在主机端分配。
- 设备端内存操作需通过全局内存,频繁的指针跳转会显著降低性能。
-
内存访问效率低下:
- 链表的非连续内存访问模式与GPU的SIMT(单指令多线程)架构不兼容,导致内存延迟高。
.cu_inl文件
为什么会有 .cu_inl?
-
分离接口与实现
与C++ 中常见的 .inl(inline)文件作用一致, .cu_inl 文件用来存放那些需要在编译单元(Translation Unit)内可见的内联(inline)或模板化 CUDA 设备函数实现 -
便于 CUDA 编译
虽然 NVCC 只关心 .cu、.cuh、.cpp 等后缀,但编译器并不会拒绝其它扩展名的文件。只要在主 .cu 或头文件中 #include "foo.cu_inl",编译器就会将其当作普通源码处理
所以编写在.cu_inl文件中的函数,只要在.cu中通过#include "foo.cu_inl"的方式直接引入即可
CUDA中的时间复杂度分析
理论复杂度分析(Big-O):并行算法的渐近复杂度通常与串行相同,只是常数因子不同,可初步筛选算法类别
What is the time complexity of CUDA's 'thrust::min_element' function?
Running things in parallel simply divides the overall execution time by the number of parallel executions. In other words, it only affects the "constant factor" which is omitted from the "Big-O" analysis.
实现
串行实现的圆形渲染器主要逻辑为:
for 每个圆形:
计算圆形的边界框
for 圆形的每个像素点:
shadePixel(像素点)
一个简单的并行实现为:
parallel_for 每个像素:
for 每个圆形:
计算圆形的位置
shadePixel(像素点)
但是这并没有重视到圆形的并行,对于每个像素只要顺序循环在这个像素上重叠的圆形即可,无需顺序循环全部圆形
如何找到每个像素上重叠的圆形数量和下标呢?
我的复杂实现
parallel_for 每个圆形:
get circleIdx
for 这个圆形上的每个像素
get pixelsIdx
对于像素pixelsIdx,记录圆形circleIdx在此重叠
parallel_for 每个像素:
get pixelsIdx
从小到大地排序pixelsIdx上重叠的circleIdx
parallel_for 每个像素:
get pixelsIdx
for 在这个pixelsIdx上重叠圆形排序后的circleIdx:
计算圆形的位置
shadePixel(像素点)
但是这里有个严重的问题首先是要对每个像素点记录重叠圆的circleIdx,这个大小很大,比如像素点有numPixels = 1024 * 1024,numCircles = 10 0000, 那么我们开个int类型的数组,需要memory = numPixels * numCircles * sizeof(int) = 40 0000MB
差点的单卡显存根本没有这么大!而且在极端情况下一个圆的像素点可能很多(即圆面积大),若有多个这样的圆会导致我第一个步骤很慢。
正确的实现
parallel_for 每个像素:
计算该线程块负责的矩形区域
// 线程块内并行,即线程块中的每个线程负责一部分圆形,全部线程负责的圆形加起来就是全部的圆形了
block_parallel_for 每个圆形:
结合__syncthreads()计算出部分圆形在此像素重叠的数量与下标
shadePixel(像素点)
具体的代码实现和思路参考:Stanford CS149 -- Assignment 3: A Simple CUDA Renderer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号