并行计算架构和编程 | CPU and GPU
Why Parallelism?Why Efficiency?
Why Parallelism?
因为单颗核(core)的处理器性能增长遇到了瓶颈,若想要继续提高处理器的性能,策略是在处理器中放更多的核(core)。
同时为了让应用程序更高效地执行,我们需要利用好处理器中的多核(core),即我们需要写并发程序。
Why Efficiency?
在多核(core)的处理器上,每一个核(core)并非都被高效利用到了,反而是大部分时间处于空闲中,这时我们说核(core)利用效率低下。
有没有什么具体的量化方法?
将处理器想象成一个正方形,其有一定的面积;将核(core)也想象成一个正方形,其也有一定面积且比处理器更小。
一颗处理器上核(core)越多越好,我们将核(core)放置在处理器上需要占用一定面积,那么在处理器面积固定的情况下我们将核(core)面积做得越小肯定越好。
-
一个非常重要的指标是单位面积的性能(performance per area),可用于衡量处理器的效率
-
同时还有能效,单位能源的性能(performance per Watt)
本次课程主要讲解了多核(core)处理器的历史脉络以及随之发展的并发程序,并同时通过实验告知我们为何有时多核(core)执行任务与单核(core)执行任务的加速比并非理想。
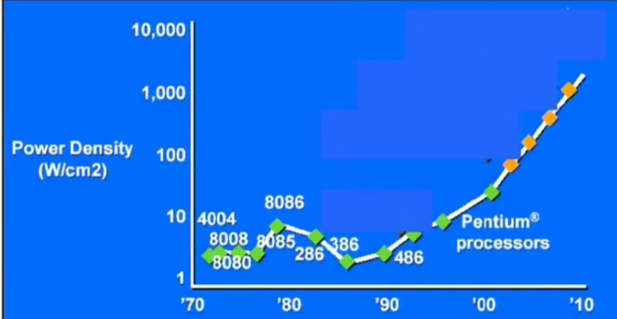
此图横坐标为1970~2010年,纵坐标为处理器的功率密度(处理器表面每平方厘米产生的瓦特量)
Intel当时想要榨干单核(core)处理器的性能:
- 处理器更大的带宽:从4bit->64bit
- ILP((Instruction-Level Parallelism)指令集并行技术
- 处理器更快的时钟频率:从10MHZ->3GHZ
当带宽和ILP都被快榨干时,时钟频率成为了Intel的买点,当时Intel甚至宣称时钟频率 == 速度。
但是正如上图所示,随着Intel不断推出高时钟频率的处理器,处理器的功率密度也越来越大了(处理器产生的热量越来越大),在2000年的处理器上甚至能够煎鸡蛋;图中橙色点为预测点,这些点的热量已经夸张到核反应堆中的热量了。也就是说再以指数形式提高处理器的时钟频率是不太可能了,热量无法散除。
Intel在技术上遇到了瓶颈,转而向让处理器拥有更多的核(core)进发。
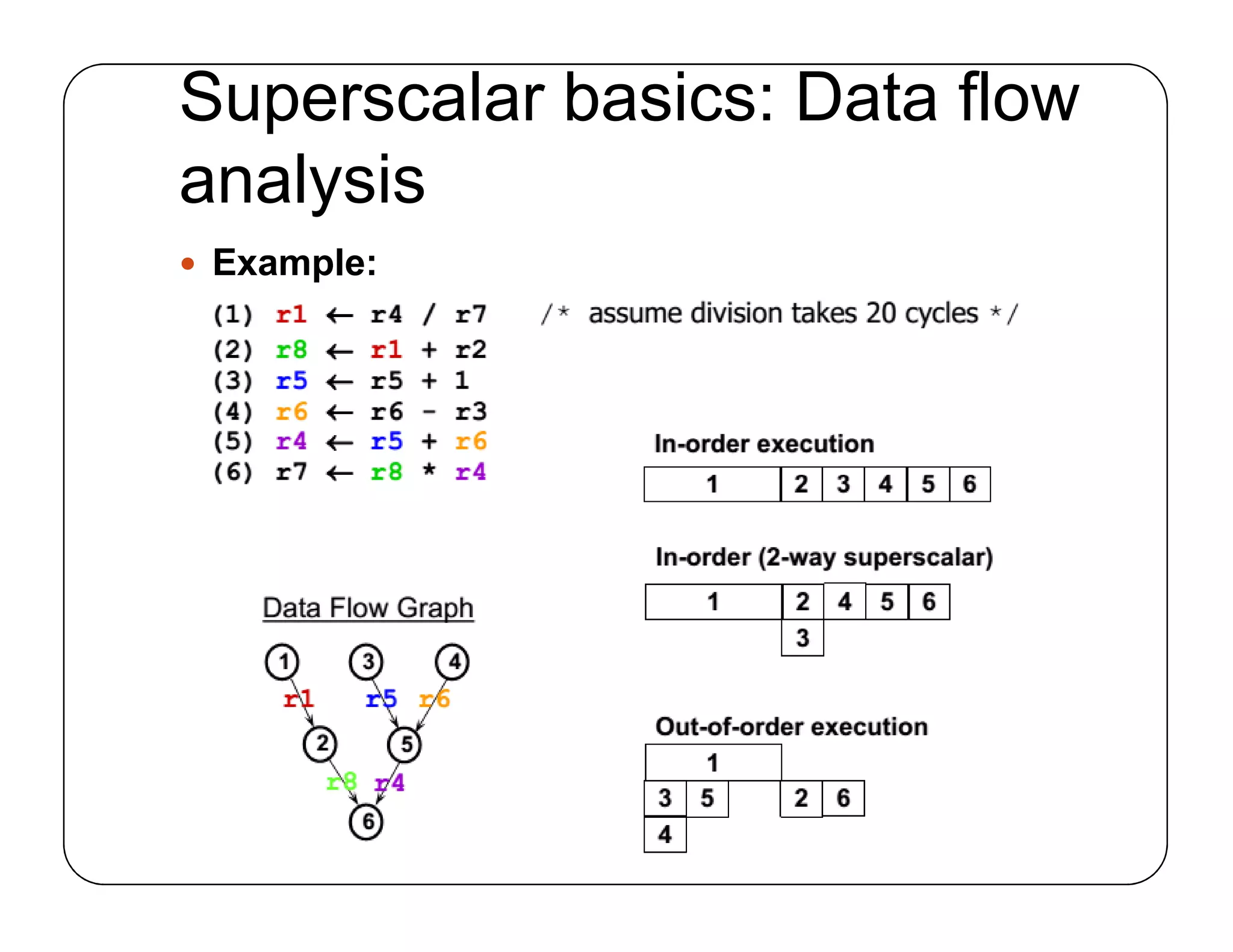
ILP 指令级并行,于《《计算机体系结构:量化研究方法》》一书的第三章重点提及:“大约 1985年之后的所有处理器都使用流水线来重叠指令的执行过程,以提高性能。由于指令可以并行执行,所以指令之间可能实现的这种重叠称为指令级并行(IP)。”
若一个任务A交给单核(core)需要花费56s完成,那么任务A交给4个核(core)完成可能需要34s。
为什么?为什么交给4个核(core)完成不是56/4 = 14s?
- 假设任务A包含了16个计算小任务,核(core)a,b,c,d可能分别被分配了1,1,1,13个小任务,如此核(core)d就成为了瓶颈,这被称为负载不均衡
- 想要达到负载均衡,需要执行一定的策略,需要一定额外时间
- 核(core)之前需要通信,有时甚至需要同步(等待他人完成),也需要一定额外时间。(想象一下1个人完成一个简单的小任务并汇报结果可能很快,但是150个人完成150个小任务并汇报结果并非按照预期所想,因为这150个人中每个人大部分时间是不工作的,而是等待)
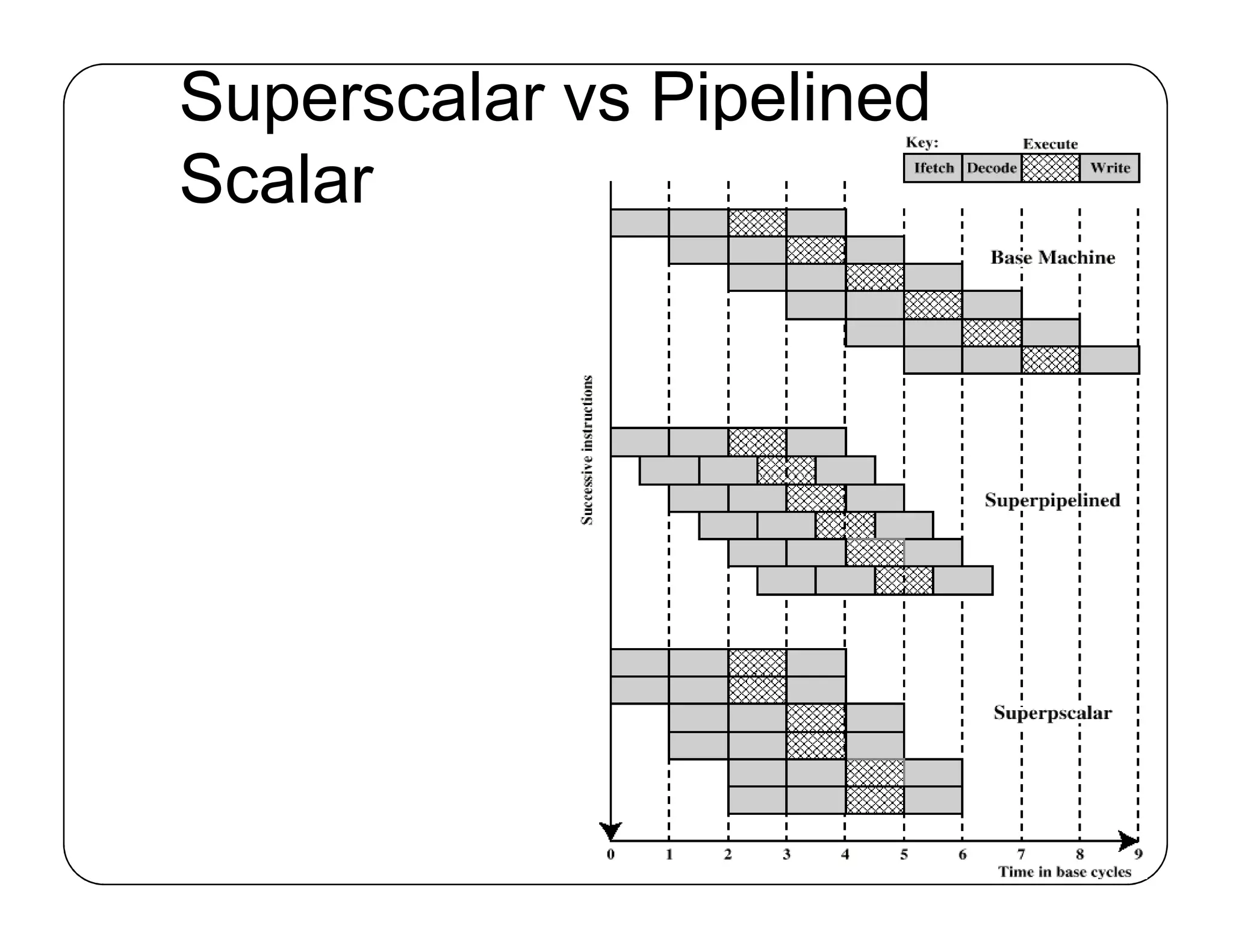
Advanced processor Principles: Pipeline, Superscalar and Superpipelined
本知识点参考CSAPP 第四章 处理器体系结构 ,图来自九曲阑干
Pipeline
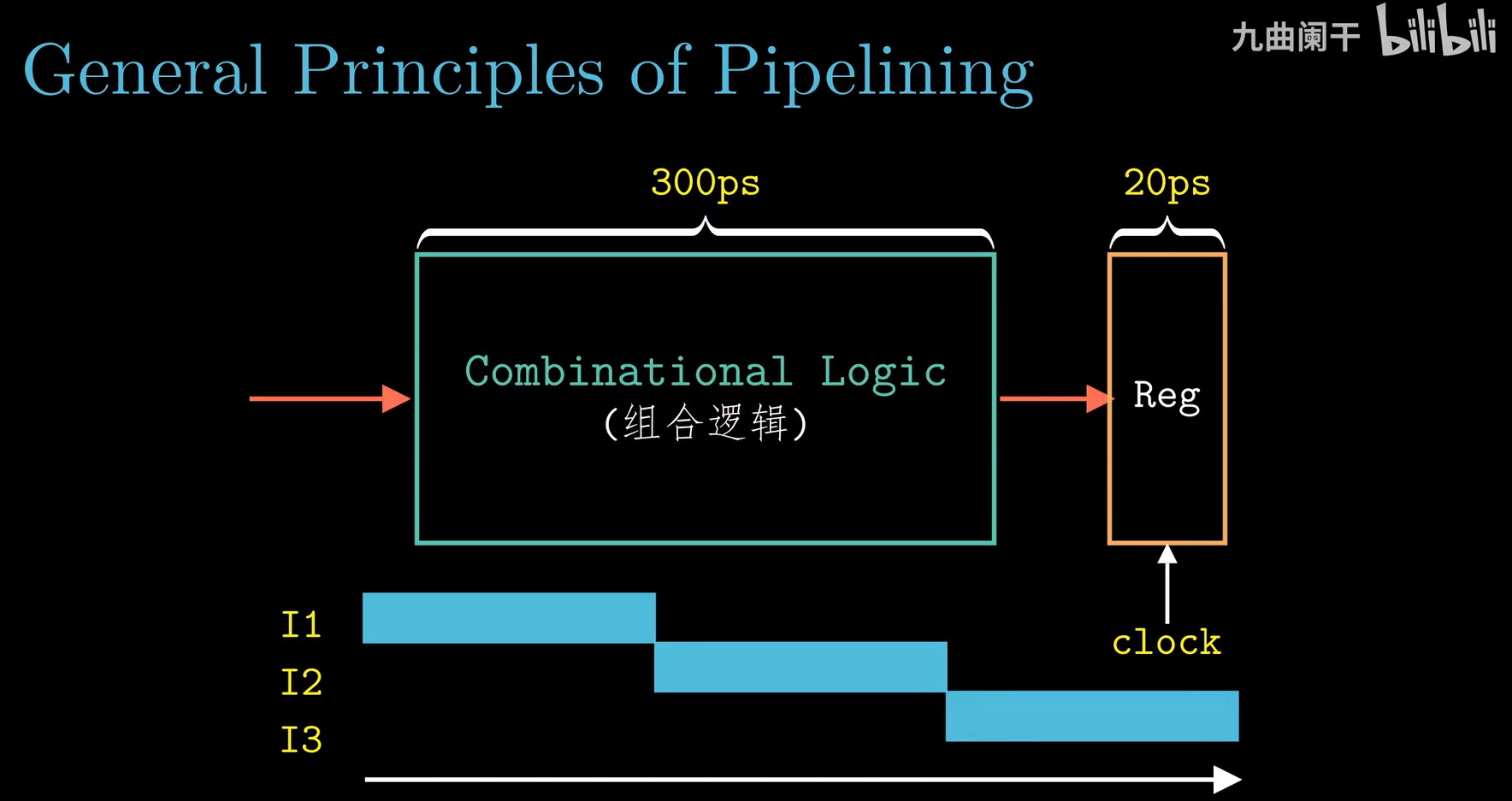
先从非流水线化的计算硬件入手:
-
组合逻辑电路不存储任何信息,它们只是简单地响应输入信号,产生等于输入的某个函数的输出。
-
时序逻辑电路是有状态且在这个状态上进行计算的系统,我们必须引入按位存储信息的设备。
显然我们非流水线化的计算硬件是时序逻辑电路,引入了时钟寄存器(如图中的Reg)。
存储设备都是通过通过一个时钟控制的,时钟是一个周期性信号,决定什么时候将新值加载到设备中。存储设备分为:
- 时钟寄存器
- 随机访问存储器:如内存,寄存器文件
时钟寄存器和寄存器文件中的寄存器是不同的概念,分别对应于硬件和机器级编程来说的。
在硬件中,(时钟)寄存器直接将它的输入和输出线连接到电路的其他部分
在机器级编程中,寄存器(文件)代表CPU中国为数不多的可直接寻址的字
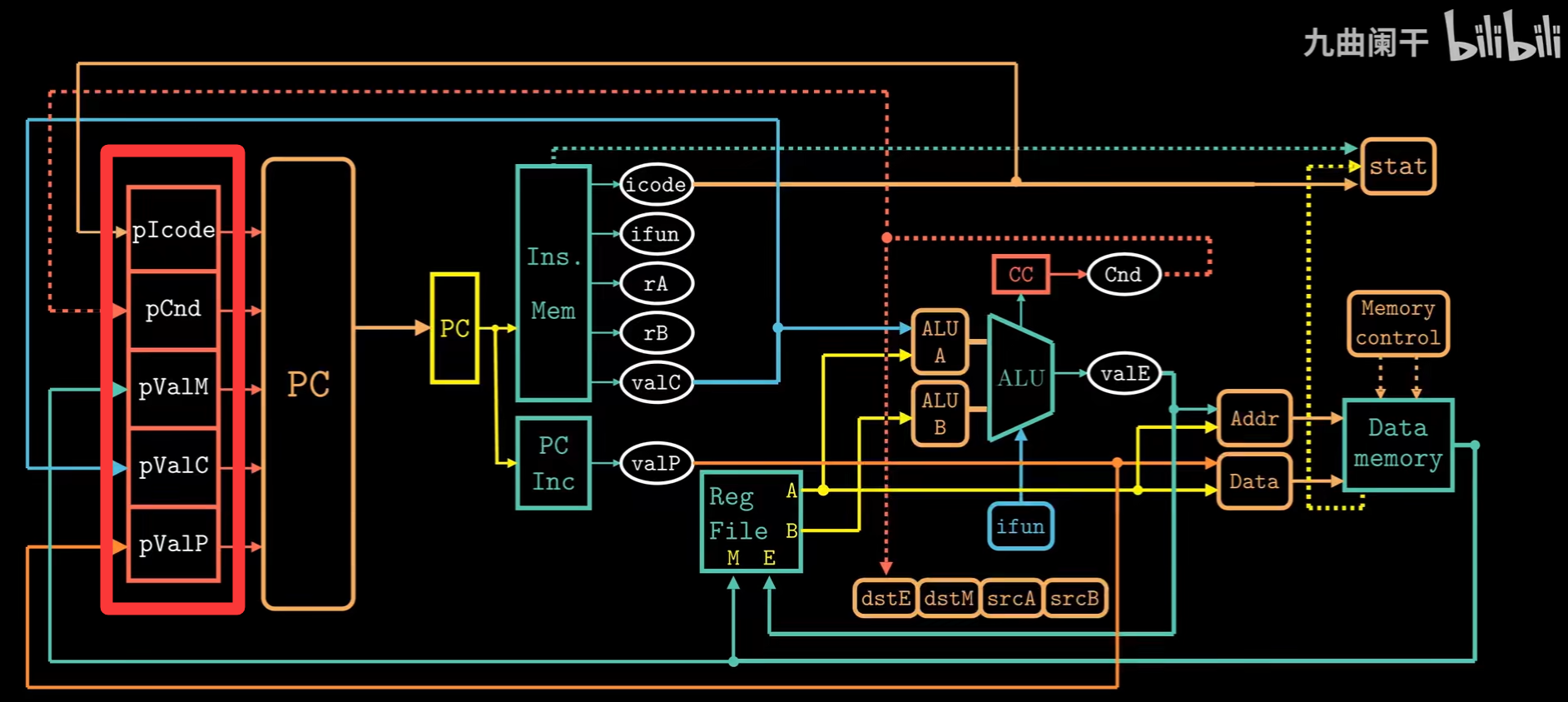
上述图为非流水线计算硬件的电路图表示,大红框中表示时钟寄存器,在其值基础上决定下一条PC的值。
上述非流水线化的计算硬件需要非常慢的时钟周期,因为对于时钟寄存器,需要等到时钟上升沿时才能保存状态。

上图红框中表示时钟信号上升沿。

上图红框中表示一个时钟周期。
非流水线化的计算硬件要执行完一系列组合逻辑后才能将结果写入时钟寄存器(即完成计算的延时较长),这意味着时钟周期要设计的较长。
接下来我们将组合逻辑部分更细地划分为不同阶段(即将延时拆分),并在各个阶段中引入时钟寄存器(流水线寄存器),得到流水线化的计算硬件:
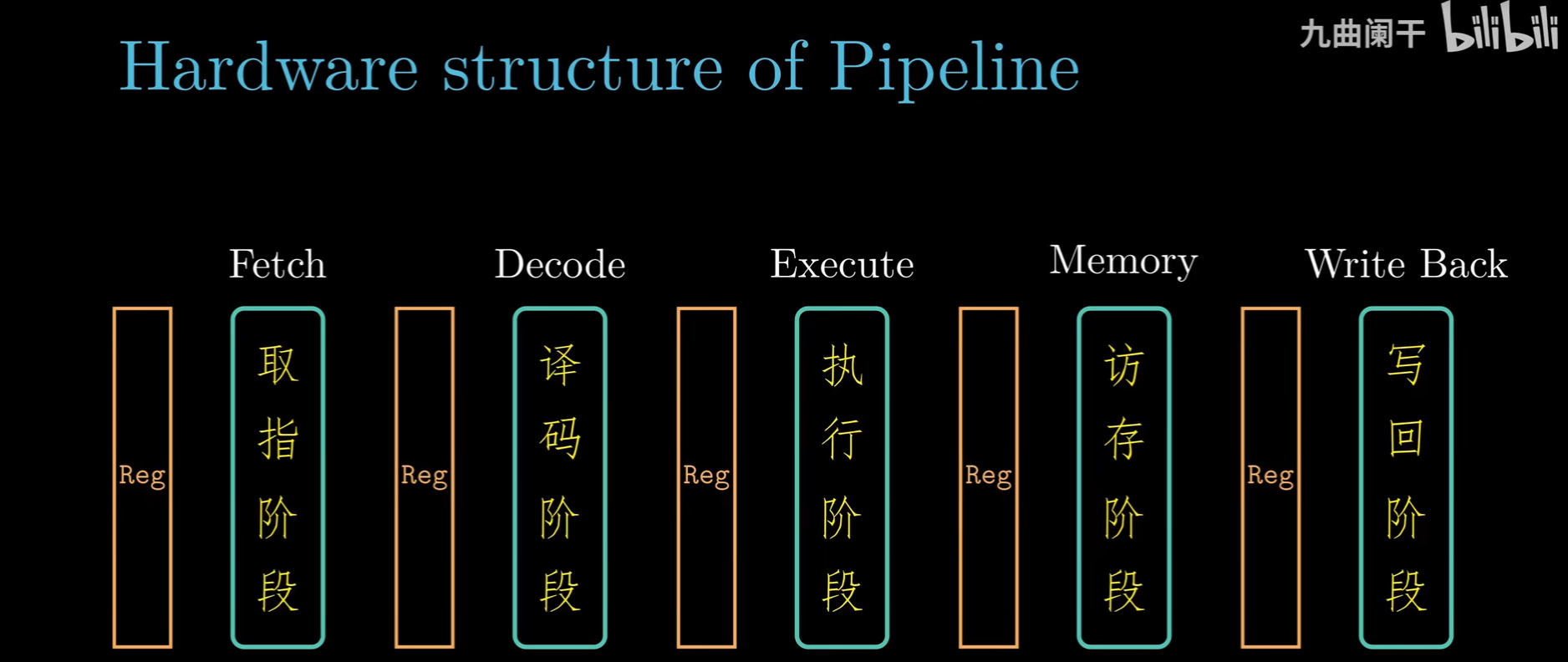
流水线计算硬件的电路图表示:
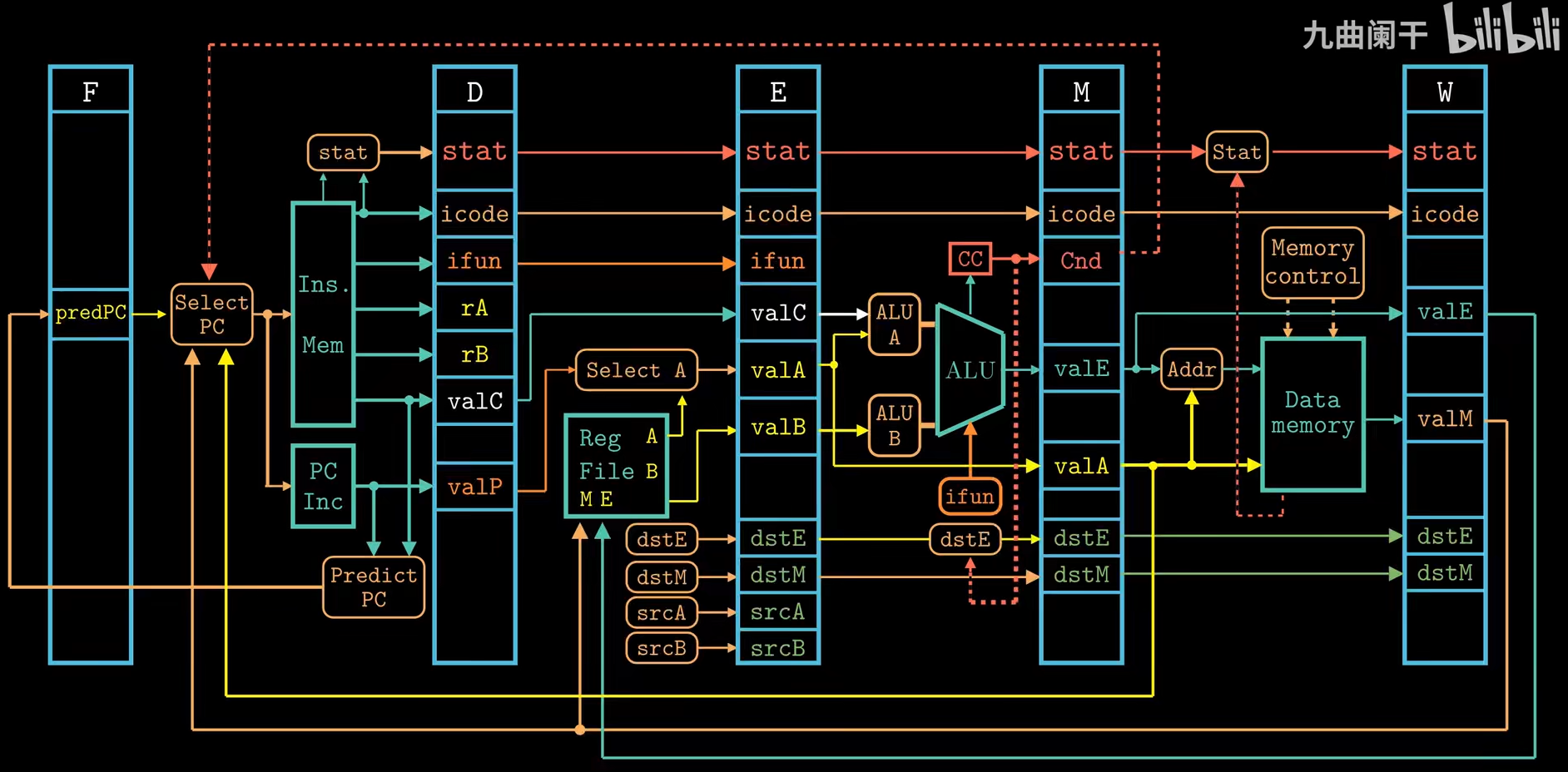
从指令流的角度理解流水线工作原理:
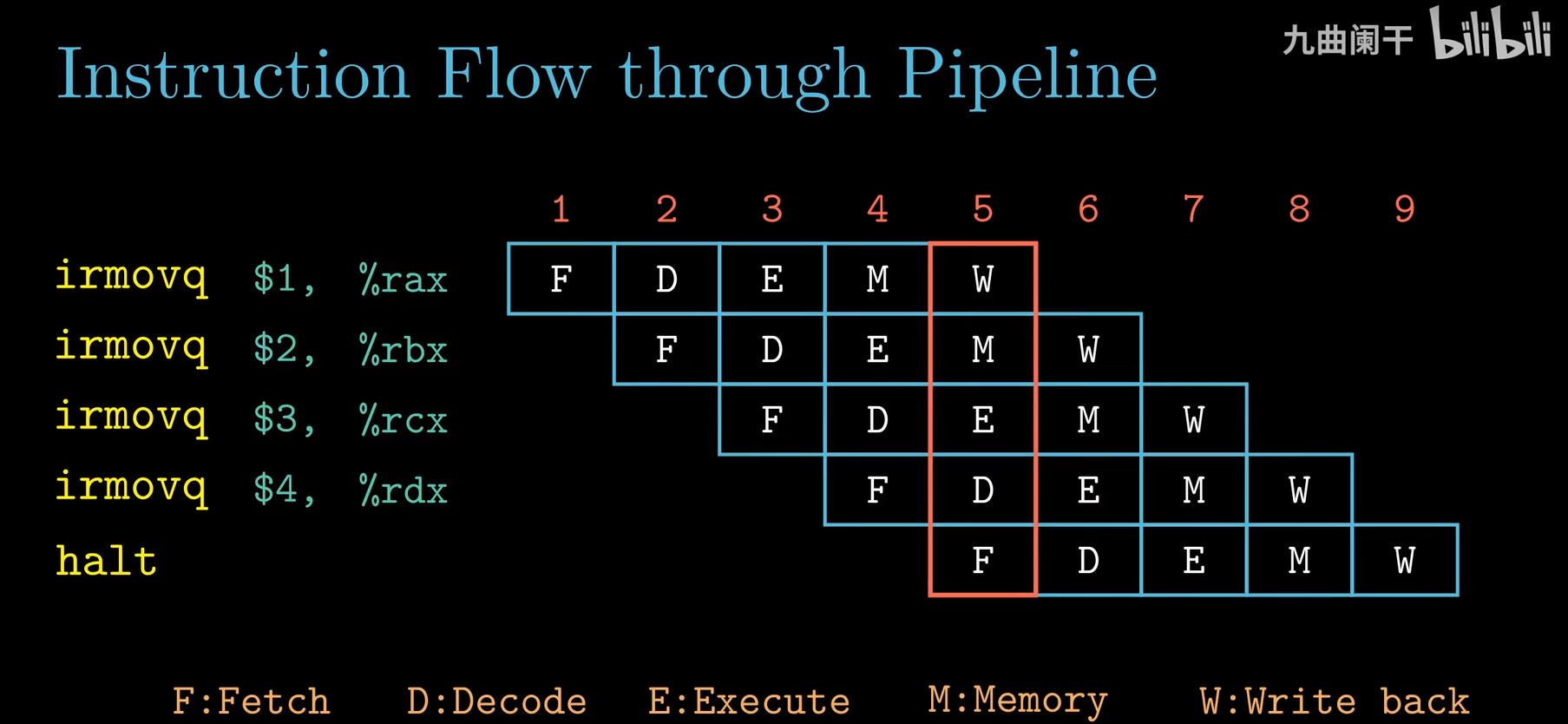
通常我们说上述五级流水线每一个时钟周期能够执行完成一条指令,因为在流水线“忙”时(如红框中所示),一个时钟周期能够同时完成不同指令的不同阶段,且正好完成了五个阶段。
通常我们会忽略流水线“预热”和“完成执行”时非“忙”的时钟周期。
$吞吐量(IPS instruction per second) = 1条指令 * F(时钟频率) $
\(F(时钟频率) = 1s / 时钟周期\)
因为我们将组合逻辑部分更细地划分为不同阶段且在各个阶段中引入时钟寄存器,时钟周期可以设计得更短一些。
那么我们岂不是可以不断将组合逻辑部分更细地划分得到更短的时钟周期,从而得到更大的吞吐量?
- 首先对于硬件设计者来说将系统计算设计划分成一组具有相同延迟的阶段是一个严峻的挑战(若划分成一组延迟差距角度的各阶段那么会有瓶颈,在具有最大延迟阶段上,想想木桶效应)
- 同时对于处理器中的某些硬件单元,如ALU和内存,不能划分成更多延时较小的单元
- 流水线过深,收益效果会逐渐下降:注意是因为时钟寄存器也有一定的延时,在中间不断插入时间寄存器也会增加延时
from CSAPP P286
流水线还有数据冒险和控制冒险问题(CSAPP P295)
- 数据冒险:下一条指令会用到以往指令计算出结果/访存结果,下一条指令在译码阶段若不等待以往指令得出结果会取出错误数据。
- 控制冒险:以往指令的计算结果/访存结果会决定下一条指令的位置,但是我们会通过分支预测先继续执行指令,这可能导致错误。
解决方法:
-
插入气泡(bubble) 暂停(stalling)避免
-
数据转发(旁路)避免
控制冒险需要进一步的考虑,当流水线已经执行了错误分支的指令,我们需要取消这些指令的执行。
案例:
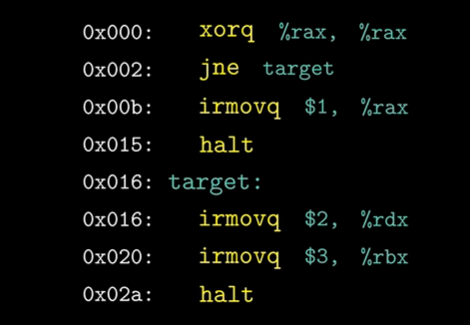
对于如上汇编代码,我们从0x000开始执行,我们的分支预测策略为假设运行分支,那么执行时的流水线示意图为:
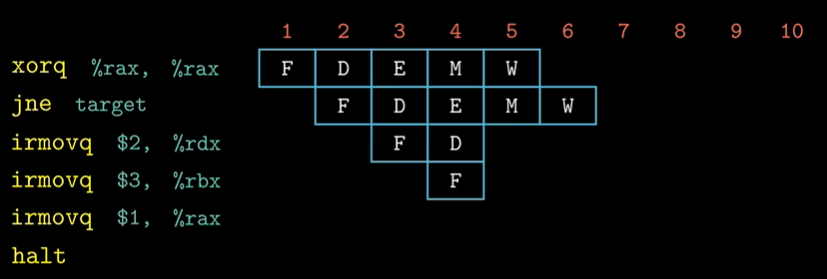
jne 指令需要到Execute阶段才能得到Cnd,然后判断是否需要跳转到target地址执行。
irmovq $2, %rdx和irmovq $3, %rbx指令都是分支预测时提前执行的指令,当发现分支预测错误后,需要取消这两条指令的执行并将这两条指令从流水线中剔除,具体的做法是:
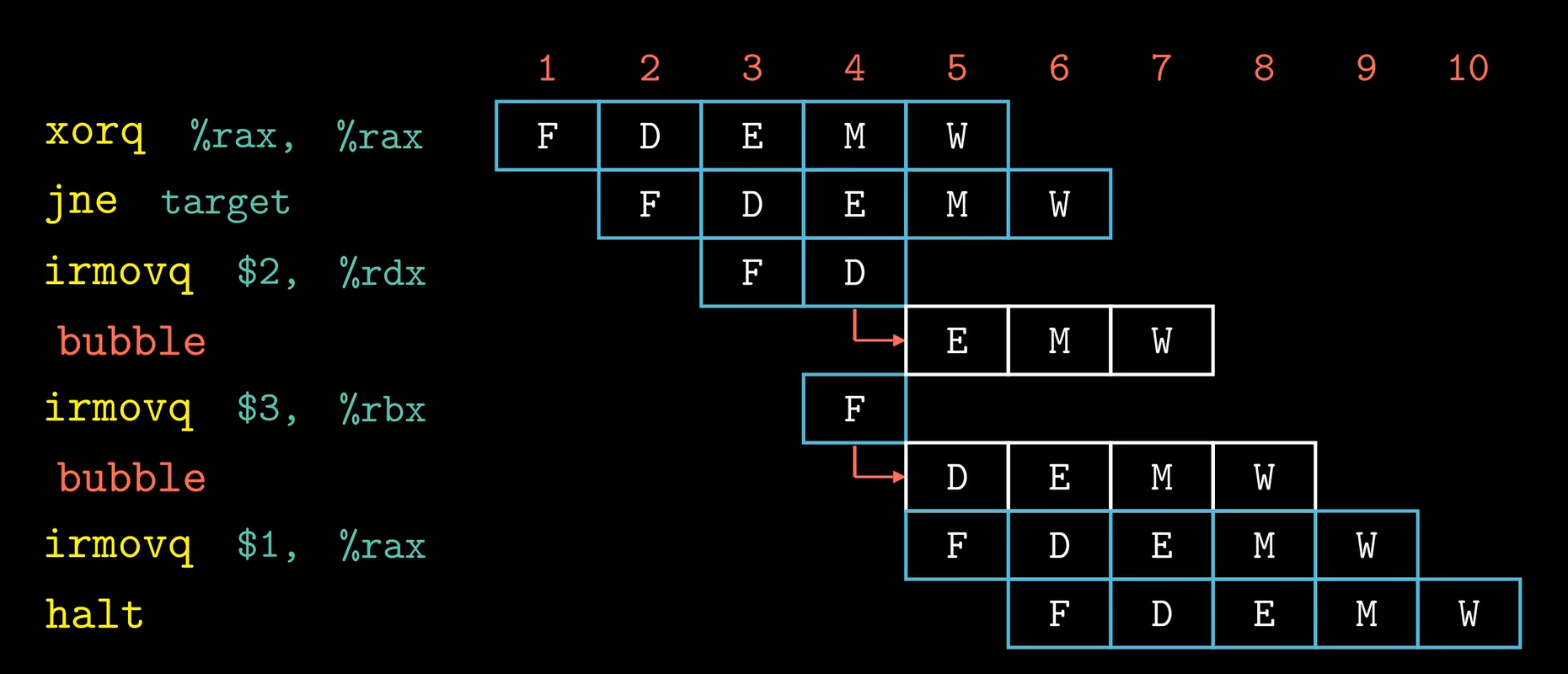
当jne指令执行完Execute阶段后发现分支预测错误,需要在流水线的E时钟寄存器和D时钟寄存器处插入气泡,并接着取出正确分支的指令开始执行。
因为取消这两条指令,我们流水线浪费了两个时钟周期。
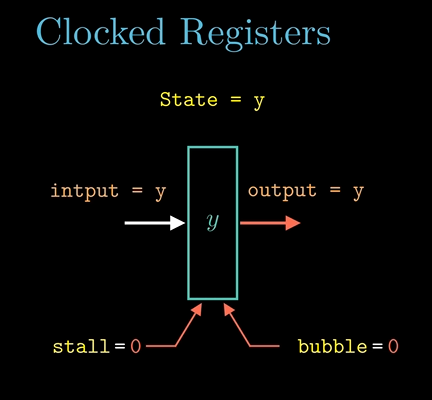
流水线寄存器含有暂停(stall)信号线和气泡(bubble)信号线。
-
当暂停信号线为1时,时钟寄存器将在时钟信号上升沿时保持其当前状态,可实现指令阻塞在流水线的某个阶段中。
插入暂停流水线示意图:
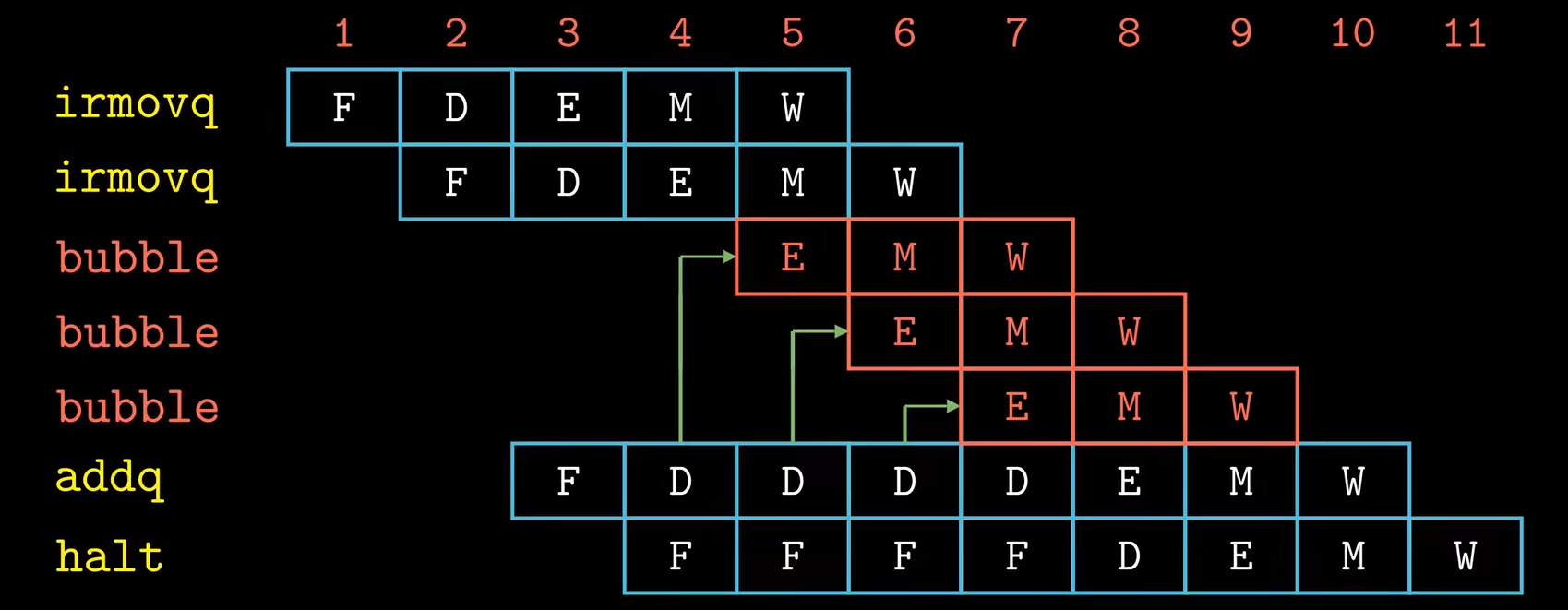
因为addq指令的数据冒险,我们需要将addq指令阻塞在Decode阶段, 即在D时钟寄存器上连续插入三个时钟周期的暂停。我们浪费了三个时钟周期。
-
当气泡信号线为1时,时钟寄存器将在时钟信号上升沿时,时钟寄存器的状态会设置成某个固定的复位配置,可实现无效化指令后续阶段的执行。
What is SIMD?
from slideshare -- Advanced processor Principles
Flynn's Classification(弗林分类法)
Flynn's Classification(弗林分类法)是计算机体系结构领域中最经典的分类方法之一,由 Michael J. Flynn 在 1966 年提出。它根据指令流(Instruction Stream)和数据流(Data Stream)的多重性对计算机体系结构进行分类,将计算机分为四种基本类型:
(1) SISD(Single Instruction, Single Data)
- 定义:
单指令流单数据流,即一次执行一条指令,操作一个数据。 - 特点:
- 典型的串行计算机架构。
- 每个时钟周期执行一条指令,操作一个数据元素。
- 示例:
- 传统的单核 CPU(如早期的 Intel 8086)。
- 简单的嵌入式处理器。
(2) SIMD(Single Instruction, Multiple Data)
- 定义:
单指令流多数据流,即一次执行一条指令,但操作多个数据。 - 特点:
- 适用于数据并行任务(如向量运算)。
- 通过一条指令同时操作多个数据元素(如数组或矩阵)。
- 示例:
- GPU(图形处理器)的着色器核心。
- Intel 的 SSE/AVX 指令集。
- 早期的向量处理器(如 Cray-1)。
(3) MISD(Multiple Instruction, Single Data)
- 定义:
多指令流单数据流,即多个指令同时操作一个数据。 - 特点:
- 理论上存在,但实际应用极少。
- 多个指令流对同一数据进行不同操作,通常用于容错或冗余计算。
- 示例:
- 某些容错系统(如航天器中的冗余计算单元)。
- 实际中 MISD 架构非常罕见,更多是理论上的分类。
(4) MIMD(Multiple Instruction, Multiple Data)
- 定义:
多指令流多数据流,即多个指令流同时操作多个数据流。 - 特点:
- 支持任务并行和数据并行。
- 每个处理器核心可以独立执行不同的指令,操作不同的数据。
- 示例:
- 多核 CPU(如 Intel Core i7、AMD Ryzen)。
- 分布式计算系统(如 Hadoop、Spark)。
- 集群和超级计算机。
现代架构与 Flynn 分类法
现代计算机通常结合多种 Flynn 分类法的特性:
- CPU:
- 多核 CPU 是 MIMD 架构,但每个核心可能支持 SIMD 指令(如 AVX)。
- GPU:
- 本质上是 SIMD/SIMT 架构,但现代 GPU 也支持一定程度的 MIMD 特性。
- 异构计算:
- 结合 CPU(MIMD)和 GPU(SIMD)的优势,适用于高性能计算和机器学习。
Flynn 分类法的扩展
随着计算机体系结构的发展,Flynn 分类法也被扩展和细化,以涵盖更多现代架构:
-
SPMD(Single Program, Multiple Data):
- SIMD 的扩展,多个处理器执行相同的程序,但操作不同的数据。
- 常见于 GPU 编程模型(如 CUDA、OpenCL)。
-
SIMT(Single Instruction, Multiple Threads):
- GPU 的编程模型,单指令流多线程,每个线程操作不同数据。
- 结合了 SIMD 和 MIMD 的特点。
SIMD 和 SSE/AVX
SIMD (Single Instruction, Multiple Data),即单指令多数据,顾名思义,是通过一条指令对多条数据进行同时操作。
据维基百科说,最早得到广泛应用的SIMD指令集是Intel的MMX指令集,共包含57条指令。MMX提供了8个64位的寄存器(MM0 - MM7),每个寄存器可以存放两个32位整数或4个16位整数或8个8位整数,寄存器中“打包”的多个数据可以通过一条指令同时处理,不再需要分成几次分别处理。
之后,SSE出现了,提供了8个128位寄存器(XMM0 - XMM7),并且有了处理浮点数的能力。可以同时处理两个双精度浮点数或四个单精度浮点数,或者同时处理四个32位整数或者八个16位整数又或者十六个8位整数。
再后来,又升级了AVX。AVX将SSE的每个128位寄存器扩展到256位,并增加了8个256寄存器。16个256位寄存器称作(YMM0 - YMM15)。再后来Intel又推出了AVX512,把YMM扩展到512位,又新增16个寄存器,共32个512位寄存器(ZMM0 - ZMM31)。
SuperScalar 超标量
Superscalar 处理器的核心思想是 在一个时钟周期内发射(Issue)并执行多条指令,而不是传统的单指令发射(如标量处理器)。
Superscalar的核心技术包含:
-
多发射(Multiple Issue):每个时钟周期从指令流中取出多条指令,并分派到不同的执行单元。
-
寄存器重命名(Register Renaming):通过动态分配物理寄存器,消除指令间的 WAW(写后写) 和 WAR(写后读) 冒险。
-
动态调度(Dynamic Scheduling):在运行时检测指令间的依赖关系,并动态调整指令执行顺序,最大化资源利用率。
-
乱序执行(Out-of-Order Execution, OoOE):允许指令在不违反数据依赖的前提下乱序执行,以减少流水线停顿。
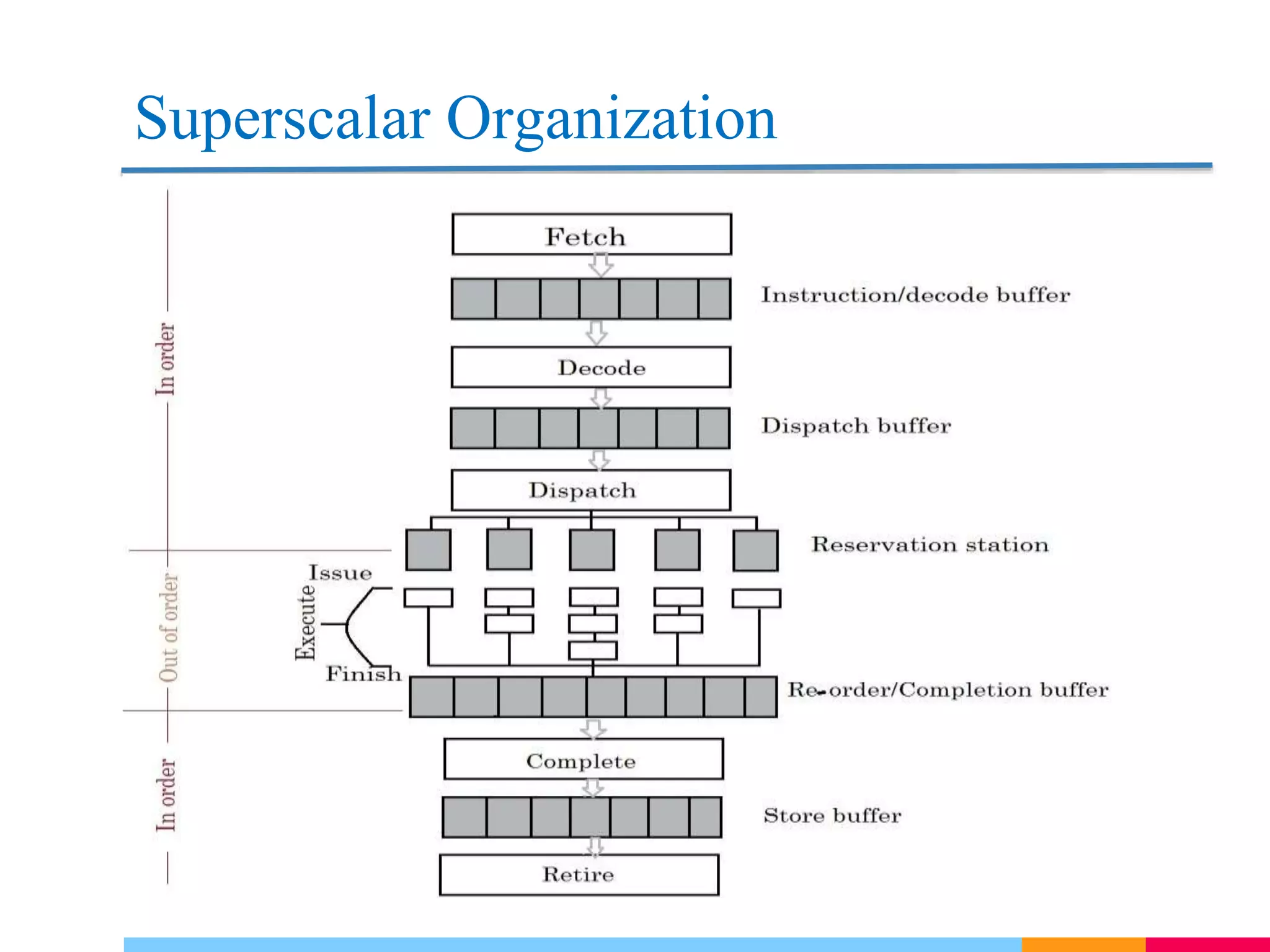
-
Decode阶段输出多条解码后的指令,存入Dispatch Buffer。
-
Dispatch从Dispatch Buffer中选择可执行指令(操作数就绪、目标单元空闲),按策略分派到保留站(Reservation Stations)或执行单元。
-
Reservation Stations 是每个执行单元(如ALU、FPU)前的小型缓冲队列,用于暂存已分派但尚未执行的指令,并管理操作数的动态就绪状态。
-
在 Superscalar流水线 中,重排序缓冲区(Re-order Buffer, ROB)是管理指令乱序执行与顺序提交的核心组件。
ROB 为每条指令维护一个条目,状态标记:
- 未执行(Issued):指令已分派到保留站,等待执行。
- 已执行未提交(Executed):指令执行完成,但结果尚未提交。
- 已提交(Committed):结果已写入架构寄存器或内存。
ROB 包含的三类指令:
- Instruction RS(保留站中的指令)
- Instruction executing in FUs(功能单元中执行的指令)
- Instruction finished execution but waiting to be completed in program order(执行完成但等待按序提交的指令)
ROB 头部指针始终指向程序顺序最早的未提交指令。仅当头部指令状态为 已执行未提交 时,才允许进入提交阶段。
-
Complete 阶段表示指令的 执行阶段已结束,即指令在功能单元(如ALU、FPU)中完成了计算或内存访问,结果已经生成。完成后的结果通常写入 重排序缓冲区(ROB) 或 物理寄存器文件,但尚未对架构状态(如用户可见的寄存器或内存)生效。
-
Retire 阶段表示指令的 结果被正式提交,即更新架构状态(如用户可见的寄存器或内存),并保证该指令的效果对后续程序可见。
-
Store Buffer 确保存储指令 按程序顺序提交到内存(即使它们乱序执行)。
超标量在一个指令流中发掘指令级并行(ILP):在同一指令流中并行执行不同的指令。
A Modern Multi-Core Processor
Multi-Core
我们上述介绍的SuperScalar 超标量处理器极大地挖掘和利用了ILP(Instruction-Level Parallelism,指令级并行性),但是可以看到为实现SuperScalar我们用硬件实现了许多复杂的机制,最终导致越来越复杂的控制逻辑电路和增大的缓存。
同时ILP提升速度的效果是有限的,困境在于我们只实现了底层指令的并行性,但是程序依旧是按照顺序写的,未考虑到并行计算。
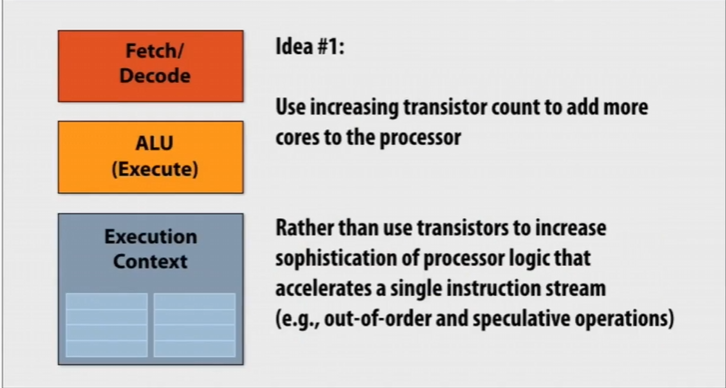
一个想法是我们不只是构建一个巨大的“单片”处理器,而是将其分成多个处理器
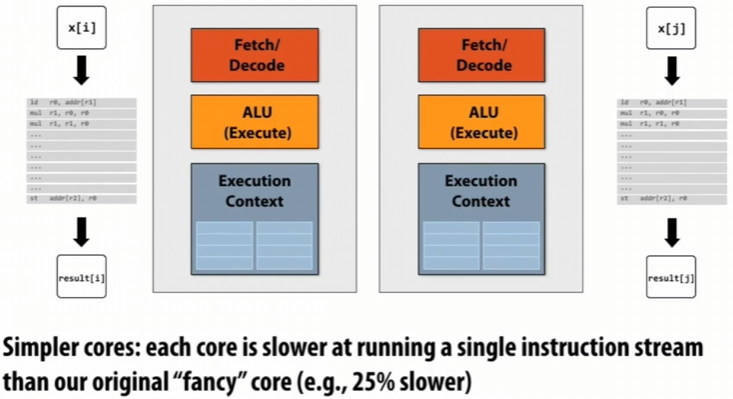
虽然每一个处理器性能比原来的少25%,但是我们现在有两个:\(2 * 0.75 = 1.5\),有加速的潜力!
同时经测试,在处理器上能源通常消耗在电路的信息通信中,缩小处理器可减短通信范围,能够省下能源
于是我们可以利用多核(Multi-core)实现并行执行:
- 线程层面的并行执行:在不同核上同时执行完全不同的指令流
- 软件决定何时创建线程
- 实际运用如C语言中的pthread API
指令流 是一个连续的、按照程序顺序排列的指令序列。
在使用pthread API创建线程执行程序时,可能不同线程执行的程序不同,即使执行相同的程序,执行进度也大概率不相同。
Data-parallel expression
sin(x) 的泰勒展开公式:
\(sin(x) = x - \frac{x^3}{3!} + \frac{x^5}{5!} - \frac{x^7}{7!} + \dots\)

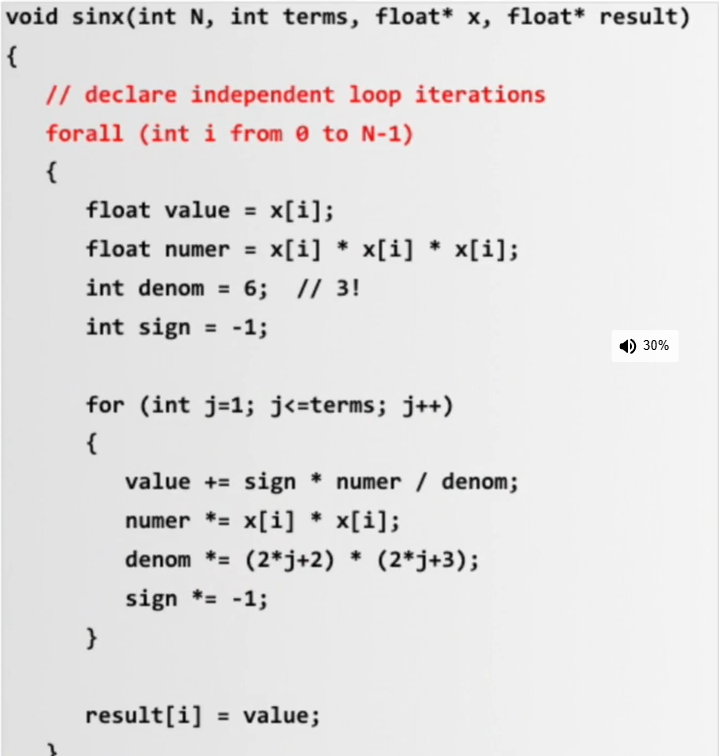
因为x[i]之间是无数据依赖的,所以我们希望全部x[i]数据能够并行地执行相同的代码
硬件上的实现:More ALUs and SIMD
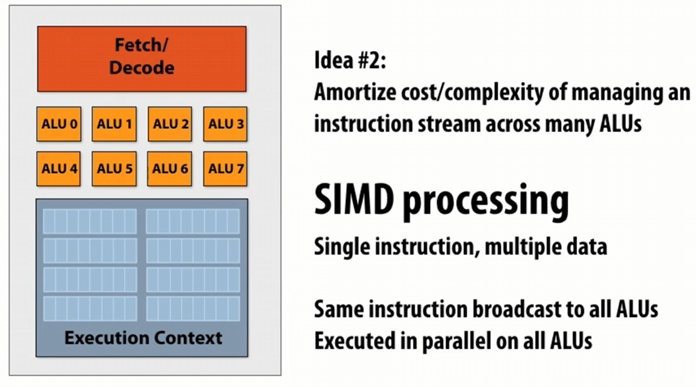
然后我们确实能够使用SIMD指令完善上述伪代码:

SIMD指令运行在一个核中,多个ALUs被相同的指令流控制。
在 SIMD(Single Instruction, Multiple Data) 编程模型中,指令的依赖关系在执行之前通常是已知的:
- 通常由程序员声明:程序员可以通过编写代码时明确指出哪些操作是独立的,或者哪些数据可以并行处理。
- 通过循环分析由高级编译器推断。
想一想当我们有多个核并且每个核有多个ALUs,每一个核同时执行相同的指令流,但是处理不同的数据
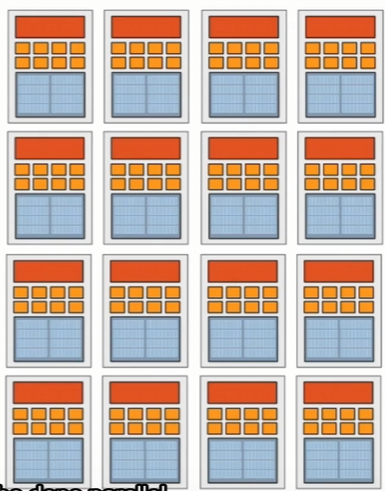
现代CPU和GPU都参考了这一想法,同时GPU 在设计抛弃了 CPU 中许多复杂的分支预测和逻辑电路(如乱序执行的功能)

对于CPU,上图中描述的是SIMD指令对于分支通过掩码的方式进行处理(隐式处理分歧)
如图中共有8个ALUs,其中3个执行if分支,其余5个执行else分支,那么8个ALUs单元需要先全部执行if分支,这时有5个ALUs空闲;再执行else分支,这时有3个ALUs空闲。
对于GPU也差不多,只是有不同的概念:
线程束(Warp)模型
- GPU 将线程分组为线程束(Warp),每个 Warp 包含多个线程(如 NVIDIA GPU 的 Warp 大小为 32 个线程)。
- 同一 Warp 中的线程必须执行相同的指令序列。
线程分歧(Divergence)
-
当 Warp 中的线程遇到分支(如
if-else)时,可能会出现线程分歧:- 部分线程执行
if分支,另一部分执行else分支。
- 部分线程执行
-
GPU 的处理方式:
-
串行化执行:先执行
if分支(其他线程空闲),再执行else分支(之前执行if的线程空闲)。 -
性能损失:线程分歧会导致部分线程空闲,降低计算效率。
-
Hiding stalls with multi-threading
随着时间推移,内存访问的问题并没有得到巨大的进步:
- 内存延时:对于来自处理器的内存请求(如load,store)内存系统处理需要的总时间
- Example:100cycles,100nesc
- 内存带宽:内存系统提供数据给处理器的速率
- Example:20GB/s
Stalls
- 在指令流中下一条指令因为依赖上一条指令而不能运行导致stalls
- 内存访问是stalls的主要来源
为减少(reduce)Stalls现代CPU已经做了不少工作:
-
通过访问caches减少Stalls
-
预取(prefetching)数据到caches中
我们可以通过在同一个core中多线程交替执行来避免(avoid/hide)stalls
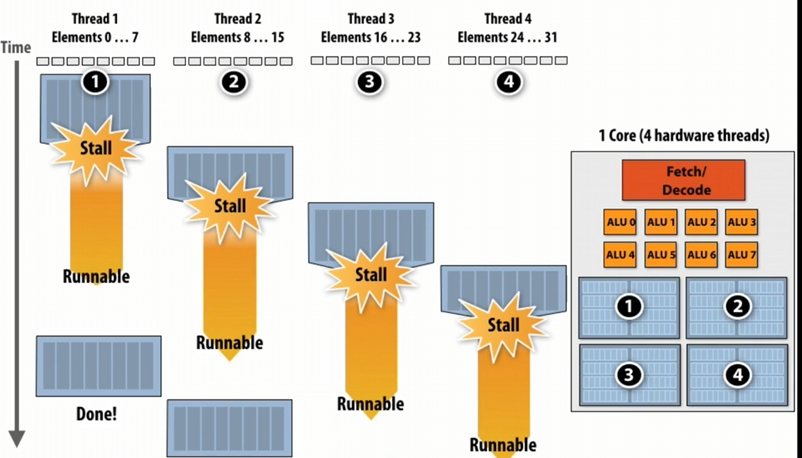
如上图当Thread 1遇到Stall,保存其上下文,让Thread 2继续运行.......
上下文保存到哪?
core的L1 cache 或者专门的Context storage(在core里面)中
如上图的右图部分,我们将core中Context storage分成了4个部分(因为这个core有4个hardware threads), 每一个部分运用存储对应线程的上下文/数据
超线程(Hyper-threading)即运用了上述思想: 在同一核心上同时多路复用多个指令流(simultaneous instruction streams, SMT)
-
core管理多线程的上下文
-
每一个时钟,core从多个线程中选择指令运行在ALUs
-
如Intel Hyper-threading , 2 threads per core
Main Idea
- benefit: 更高效地利用了core'ALU资源
- Costs:
- 需要额外的空间存储线程上下文
- 对内存带宽要求更高了:More threads --> lager working set --> less cache space per thread --> more higher ratio to access memory
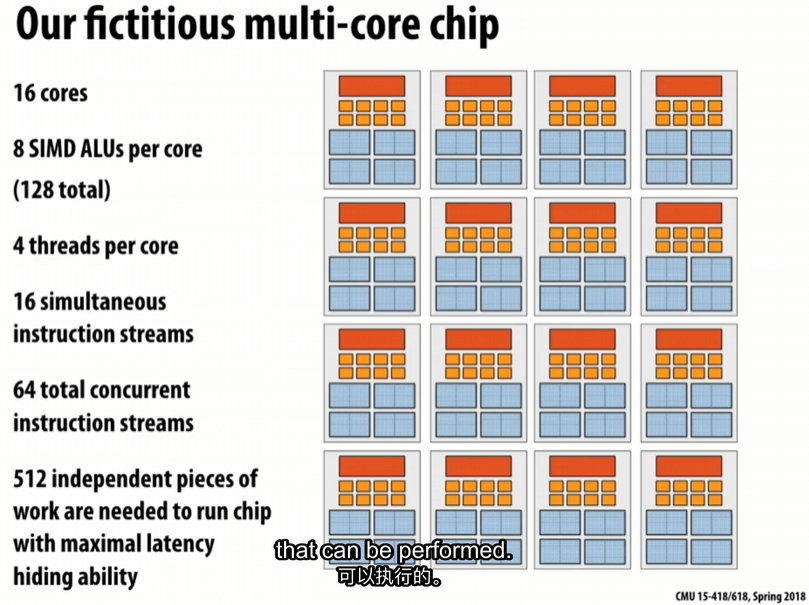
每个核有8个ALUs,即指令流可以同时处理8个不相关的数据片段;
同时每个核有4个线程,每一个线程运行不同的指令流,所以一个core可以处理32个不相关的数据片段;
有16个core,则总共可以并行处理512个不相关的数据片段;
再来看看GPU:

对于NVIDIA GTX 480 core,同样也使用了超线程思想,每个core可以处理48个warp的数据,每一个warp有32个线程,总共有15个core
那么其可以并行处理48 * 32 * 15 = 23040个数据片段
假设:

需要6.4TB/sec的带宽,但是实际上只有177GB/sec,即使GPU具有优越的性能,但是带宽更不上那么只能发挥出其\(\frac{177GB/sec}{6.4TB/sec} = 3\%\)的效率
所以Bandwidth is a critical resource,作为程序员需要尽量让CPU/GPU少访问内存,多计算
Parallel Programing Abstractions
SPMD programming abstraction
SPMD(Single Program, Multiple Data,单程序多数据):
(1) Single Program(单程序)
- 定义:所有处理单元(如MPI进程、GPU线程块)运行同一份代码。
- 代码逻辑统一:代码中可能包含条件分支,通过运行时参数(如进程ID、线程ID)区分不同处理单元的行为。
(2) Multiple Data(多数据)
- 数据划分:全局数据被划分为多个子集,每个处理单元操作不同的数据分区。
- 数据本地性:处理单元优先访问本地数据,必要时通过通信获取远程数据。
ISPC
ISPC(Intel SPMD Program Compiler)是由 Intel 开发的一种开源编译器,专门用于编写高性能的 SIMD(单指令多数据)并行代码
- 隐式 SIMD 编程:开发者无需手动编写 SIMD 内联汇编或 intrinsics,只需编写类似单线程的代码,ISPC 编译器会自动生成优化的 SIMD 指令。
- 多核并行支持:通过任务并行模型(如
launch语法)将任务分配到多个 CPU 核心。
ISPC 的编程模型:Gang 和 Program Instances
-
Gang(组): Gang 是 ISPC 中的基本并行执行单元,表示一组 并发的 SIMD 程序实例(Program Instances)。
- 类似于 GPU 编程中的 线程束(Warp),但运行在 CPU 的 SIMD 硬件单元上。
- 一个 Gang 中的多个 Program Instances 会共享同一组 SIMD 寄存器,通过单条 SIMD 指令并行处理多个数据元素。
-
Program Instance(程序实例): Program Instance 是 ISPC 中的一个逻辑执行单元,每个实例对应处理 SIMD 指令中的一个数据。
- 比如若使用 AVX2(256 位寄存器),我需要并行处理double类型数组,那么Program Instance个数为\(256 / 8 / 8 = 4\)

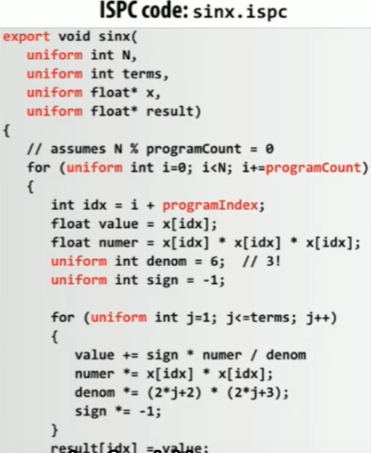
-
uniform表示变量在所有 Program Instances 中共享(标量)。 -
programCount表示在一个gang中Program Instances的个数 -
programIndex表示在一个gang中当前Program Instances的id
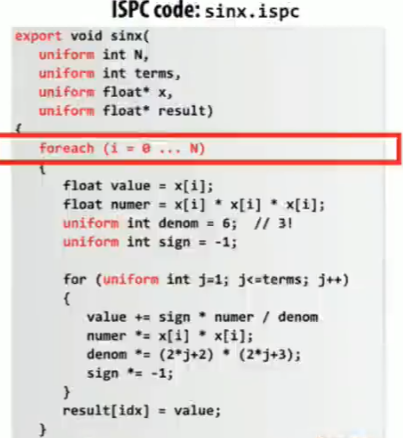
这里使用的是AVX/AVX2(256位寄存器),且数据为float,所以一个gang中有8个Program Instances。
上述sinx.ispc代码会被同时执行在各个Program Instances中,流程示意图为:
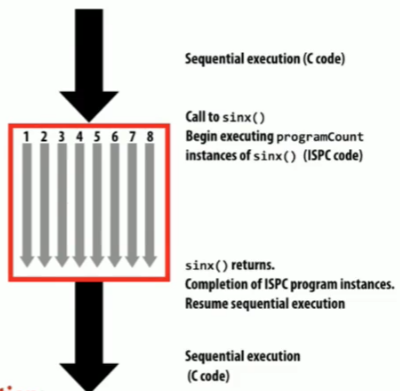
其中红框中有8个指令执行流,id分别为0,1,2....,7
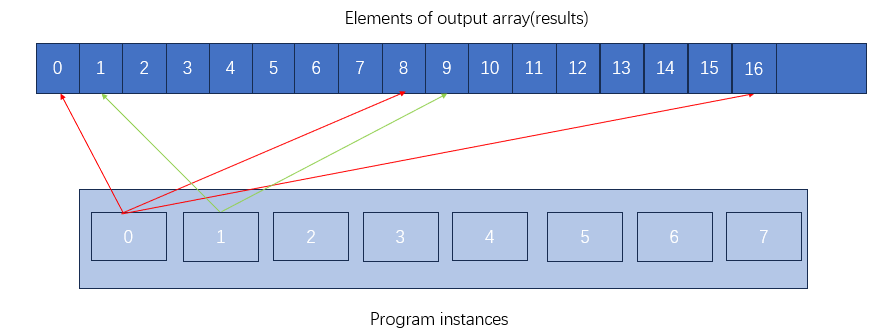
在SPMD编程模型中,程序员认为程序运行在programCount个逻辑指令流中,每个逻辑指令流具有不同的programIndex
这是SPMD编程模型提供的抽象
foreach 是 ISPC 的并行循环语法,效果和上述等价
Three parallel programming models and Three machine architectures
共享地址空间(shared address space)Model
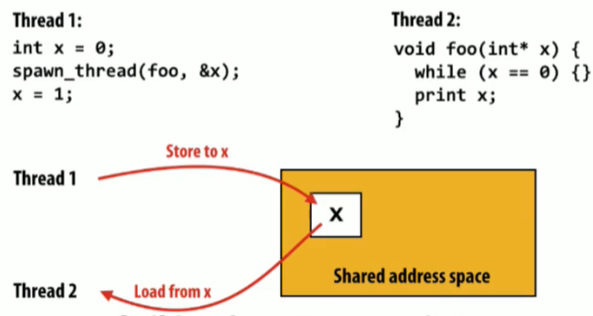
- 线程通过读/写共享变量进行交流
- 共享变量如同在公告板(shared address space)上的张贴
- 共享变量通过同步原语(locks,sempahors,etc)来保证同步
具体的实现方法有SMP(Symmetric multi-processor 对称多处理器,即处理器到内存的距离均相等),通过直接分享物理内存
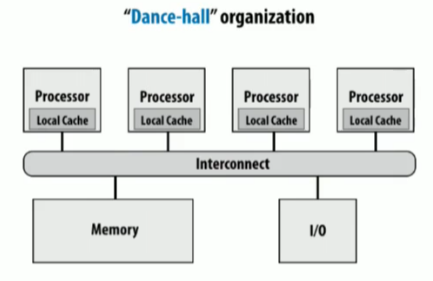
NUMA(Non-uniform memory access)非统一内存访问
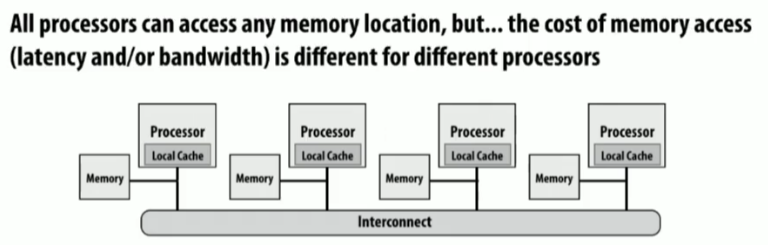
缓存一致性保证了本地数据和全局数据的一致
消息转发(Message passing)Model
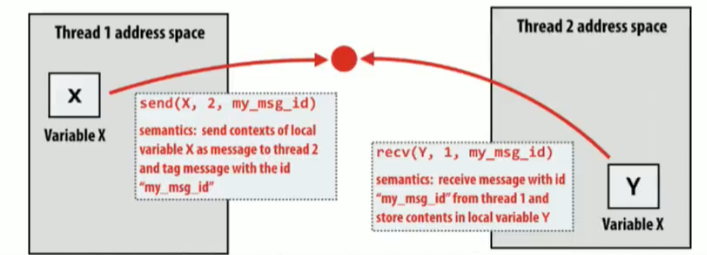
现在只有它们自己的私有地址空间,线程直接使用send/receive交换消息
- 不需要任何特殊硬件支持,需要网络
- 适合大型服务器中节点与节点之间沟通
实现方式为在机器上开辟一段共享地址空间:
- sending message = 将消息从存放消息的地址空间复制到消息库缓存区(message library buffers)
- receiving message = 将消息从消息库缓存区复制到存放消息的地址空间
- 软件实现即可无需硬件实现
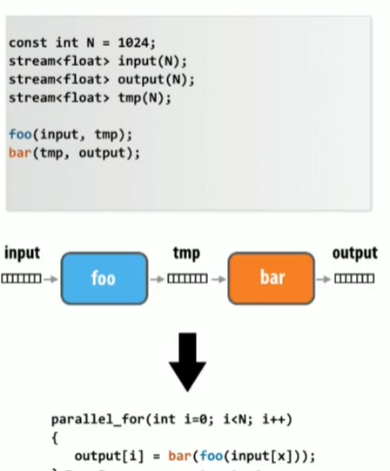
数据并行(Data parallel)Model
数据并行模型将某个函数或计算映射(map)到一组数据(collection)上。
如Data parallelism in ISPC:
- Think of loop body as function
- foreach construct is a map
- Collection is implicitly defned by array indexing logic
我们需要避免数据竞争和非确定性问题:

这里由于程序是同时执行的,可能会有同时写y[i-1]的可能,这就有非确定性问题。
流模型:通过流来处理数据并应用纯函数,需要避免数据竞争和非确定性问题。
- 函数需要避免数据竞争和非确定性问题。
- 每一个函数调用的输入和输出都能够提前被知晓,能够通过预取数据来hide latency
- 生成者-消费者的地点能够被提前知晓:第一个kernel的输出能够立刻被第二个kernel处理,值保存到core buffer/cache中无需写入内存,可以节省带宽
总结
在实践中,要充分利用高端机器,通常需要同时使用共享地址空间、消息传递和数据并行等多种编程模型。
总之需要在心中默想:编程模型是什么?硬件是如何实现的?
现代CPU架构
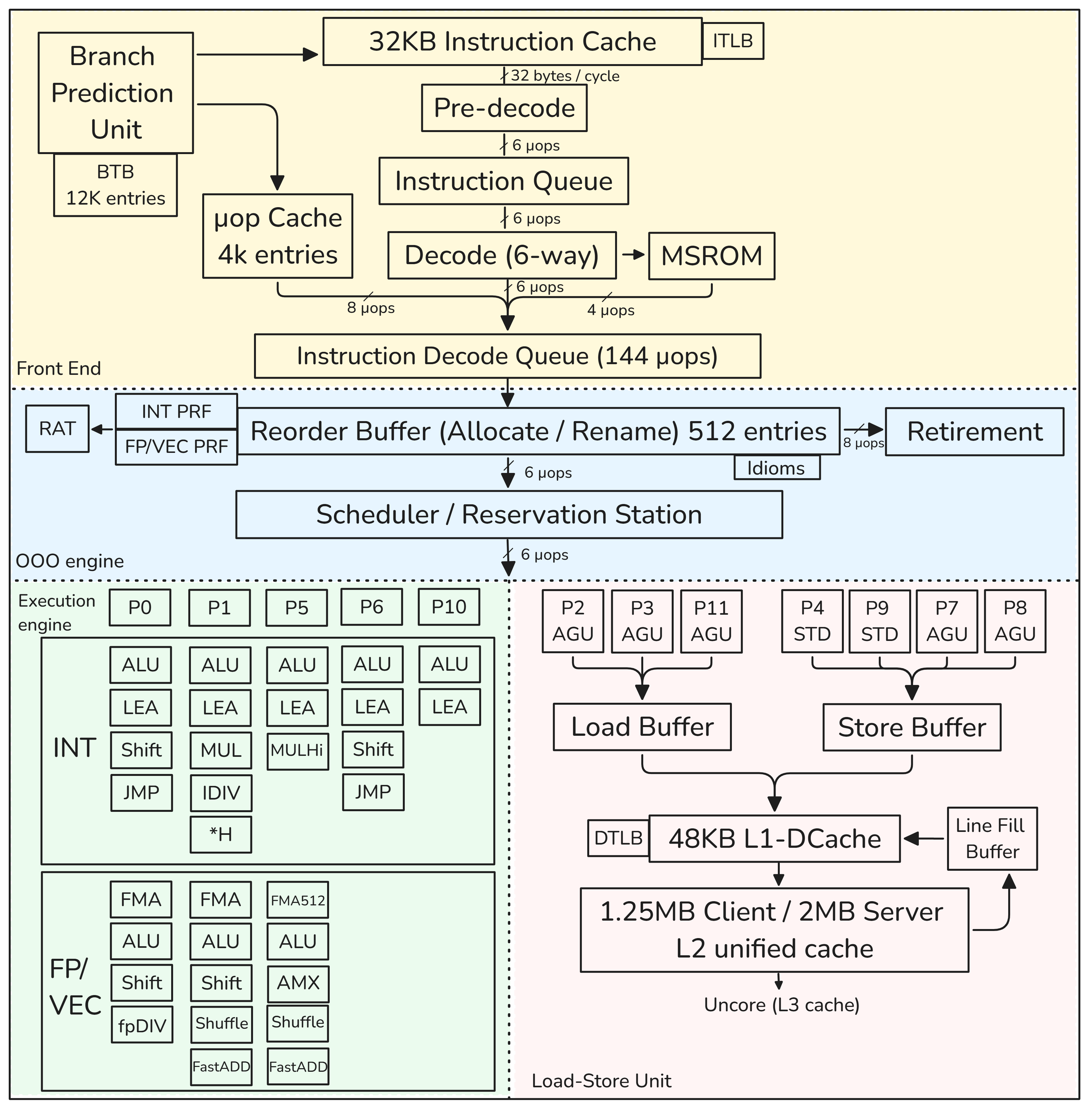
本节内容可以和上文中的超标量技术相互对比理解,即使图在某些地方不同也没关系,图本身也是抽象出来方便理解的。
本节仅描述了单个核心,而不是整个处理器。因此,我们将跳过关于频率、核心数量、L3缓存、核心互连、内存延迟和带宽以及其他内容的讨论:
- 顺序执行的前端,负责从内存中提取和解码x86指令为μops
- 一个6宽度的超标量、乱序执行的后端
- Goldencove核心支持2路SMT(同步多线程,即超线程技术)
CPU前端
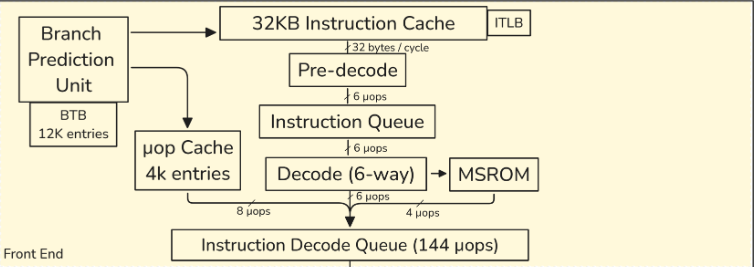
- 用于从内存中提取和解码指令。其主要目的是向CPU后端提供准备好的指令
- 指令提取是执行指令的第一阶段。但一旦程序达到稳定状态,分支预测单元(BPU)就会引导CPU前端的工作,BPU预测所有分支指令的方向,并根据这个预测引导下一个指令提取。
- BPU的核心是一个包含12K条目的分支目标缓冲区(BTB),其中包含有关分支及其目标的信息。
- 这些信息被预测算法使用。每个周期,BPU生成下一个提取地址,并将其传递给CPU前端。
- 预解码阶段通过检查指令来确定和标记可变指令的边界(x86指令是可变长度的,指令长度可以从1字节到15字节不等)。预解码阶段将多达6条指令(也称为宏指令)移动到指令队列
- 多达六个预解码指令每个周期从指令队列发送到解码器单元。6路解码器将复杂的宏操作转换为固定长度的μops。
- 解码流缓冲区(DSB)或μop缓存。其动机是在与L1 I-cache并行工作的单独结构中缓存宏操作到μops的转换。
- 一些非常复杂的指令可能需要比解码器处理的μops更多。这些指令的μops来自微码顺序器(MSROM)。这些指令的示例包括用于字符串操作、加密、同步等的HW操作支持。
- 指令解码队列(IDQ)提供了顺序CPU前端和乱序CPU后端之间的接口。这是顺序CPU前端结束并且乱序CPU后端开始的地方。
CPU后端
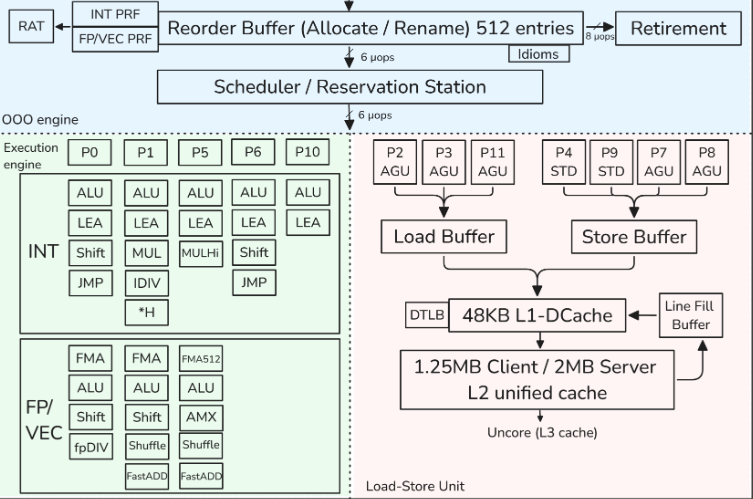
- CPU后端采用乱序执行引擎执行指令并存储结果。
- CPU后端的核心是512条目的重排序缓冲区(ROB),在图表中被称为"分配/重命名(Allocate / Rename)":
- 提供寄存器重命名。逻辑寄存器(程序员可见的寄存器)只有16个通用整数寄存器和32个向量/SIMD体系结构寄存器,但是物理寄存器的数量要多得多。
物理寄存器位于称为物理寄存器文件(PRF)的结构中。从体系结构可见寄存器到物理寄存器的映射保存在寄存器别名表(RAT)中。 - ROB分配执行资源。当一条指令进入ROB时,将分配一个新条目,并为其分配资源,主要是一个执行单元和目标物理寄存器。
- ROB跟踪推测执行。当一条指令完成其执行时,其状态会更新,并且会保留在那里,直到前面的指令也完成。之所以这样做,是因为指令总是按程序顺序退役。
一旦一条指令退役,其ROB条目将被释放,并且指令的结果变得可见。退役阶段比分配阶段更宽:ROB每个周期可以退役8条指令。
- 提供寄存器重命名。逻辑寄存器(程序员可见的寄存器)只有16个通用整数寄存器和32个向量/SIMD体系结构寄存器,但是物理寄存器的数量要多得多。
- "调度器/保留站(Scheduler / Reservation Station)"(RS)是跟踪给定μop的所有资源可用性并在准备就绪时将μop分派到分配端口的结构。
当一条指令进入RS时,调度器开始跟踪其数据依赖关系。一旦所有源操作数可用,RS尝试将μop分派到空闲的执行端口。
GPU Architecture
将从三个方面层次渐进地讲解GPU,以及运行在其上的CUDA language:
- CUDA programming language语法
- CUDA 提供的抽象
- GPU 具体硬件架构
CUDA programming language syntax
代码被清楚地分为:Host code 和 Device coede
- Host code: serial execution on CPU
- Device code: SPMD execution on GPU
其中有个概念被称为“Kernel”,所谓kernel function即是在空间的每个点上执行的某种计算/函数
CPU上缓存对编程者而言有点隐藏,基本是是由硬件控制;但是GPU上的缓存更多地受到软件控制。
#include <cstdio>
#include <cstdlib>
#include <cuda_runtime.h>
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error at %s:%d - %s\n", __FILE__, __LINE__, cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while (0)
const int Nx = 12;
const int Ny = 6;
// Device function: 仅在 GPU 内部可调用
__device__ float doubleValue(float x)
{
return 2.0f * x;
}
// Kernel function: 在 GPU 上并行执行
__global__ void matrixAddDouble(float A[Ny][Nx],
float B[Ny][Nx],
float C[Ny][Nx])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
// 检查索引范围,避免越界
if (i < Nx && j < Ny) {
C[j][i] = A[j][i] + doubleValue(B[j][i]);
}
}
int main()
{
// 分配主机内存(使用行优先顺序的二维数组转换为一维数组存储)
size_t size = sizeof(float) * Nx * Ny;
float *h_A = (float*)malloc(size);
float *h_B = (float*)malloc(size);
float *h_C = (float*)malloc(size);
// 初始化主机数据(例如 A 全部为 1.0f, B 全部为 2.0f)
for (int j = 0; j < Ny; j++) {
for (int i = 0; i < Nx; i++) {
h_A[j * Nx + i] = 1.0f;
h_B[j * Nx + i] = 2.0f;
}
}
// 分配设备内存
float *d_A, *d_B, *d_C;
CUDA_CHECK(cudaMalloc((void**)&d_A, size));
CUDA_CHECK(cudaMalloc((void**)&d_B, size));
CUDA_CHECK(cudaMalloc((void**)&d_C, size));
// 拷贝数据从主机到设备
CUDA_CHECK(cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice));
// 设置 CUDA 网格和线程块尺寸
dim3 threadsPerBlock(4, 3); // 每个 block 4x3 = 12 个线程
dim3 numBlocks((Nx + threadsPerBlock.x - 1) / threadsPerBlock.x,
(Ny + threadsPerBlock.y - 1) / threadsPerBlock.y,
1);
// 调用 kernel, 注意传递二维数组时,内存布局必须与 kernel 中一致
// 这里将设备内存强制转换为二维数组指针
matrixAddDouble<<<numBlocks, threadsPerBlock>>>(
reinterpret_cast<float (*)[Nx]>(d_A),
reinterpret_cast<float (*)[Nx]>(d_B),
reinterpret_cast<float (*)[Nx]>(d_C));
// 检查 kernel 执行是否有错误
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaDeviceSynchronize());
// 拷贝结果从设备回主机
CUDA_CHECK(cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost));
// 打印部分结果
printf("Result matrix C:\n");
for (int j = 0; j < Ny; j++) {
for (int i = 0; i < Nx; i++) {
printf("%5.1f ", h_C[j * Nx + i]);
}
printf("\n");
}
// 释放设备内存和主机内存
CUDA_CHECK(cudaFree(d_A));
CUDA_CHECK(cudaFree(d_B));
CUDA_CHECK(cudaFree(d_C));
free(h_A);
free(h_B);
free(h_C);
return 0;
}
-
global 核函数:只能由 CPU 调用,运行在 GPU 上,必须使用 <<< >>> 语法启动。返回类型必须是 void。代码在 GPU 上执行,但调用由 CPU 发起。
-
device 函数:只能在 GPU 上被其它 device 或 global 函数调用。只能在其它设备函数或核函数中调用。
-
host 函数:用于声明 仅能在 CPU 主机端执行 的函数(通常不显式写出来,因为默认就是 host)。
注意核函数调用参数:<<<numBlocks, threadsPerBlock>>>
- numBlocks:网格(grid) 维度,表示需要多少个线程块。
- threadsPerBlock:线程块(block) 的维度,表示每个块有多少线程。
- 每个线程通过 内置变量 blockIdx, threadIdx, blockDim来计算自己在数据中的全局索引,从而并行处理数据。
- blockIdx:从下标0开始,contains the block index within the grid.
- threadIdx: 从下标0开始, contains the thread index within the block.
- blockDim: contains the dimensions of the block.
- gridDim: contains the dimensions of the grid.
- 其中的类型为
dim3,dim3 是一个内置的数据类型,用于表示三维的尺寸信息。
它的结构类似于一个拥有三个无符号整数成员(x、y、z)的结构体,常用于指定并行执行的组织方式。
若传入类型为int,则会被自动转换为dim3类型:int gridSize = 16; // 将被转换为 dim3(16, 1, 1) int blockSize = 128; // 将被转换为 dim3(128, 1, 1) myKernel<<<gridSize, blockSize>>>(...);
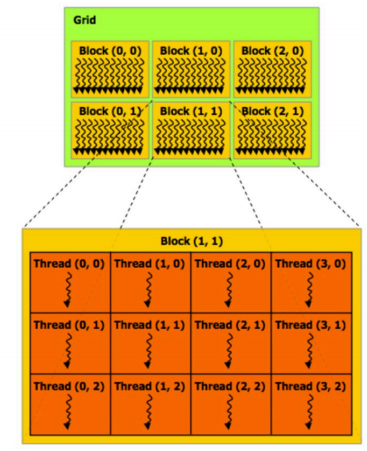
上述代码具体的一个抽象线程块,线程的层次展示为:
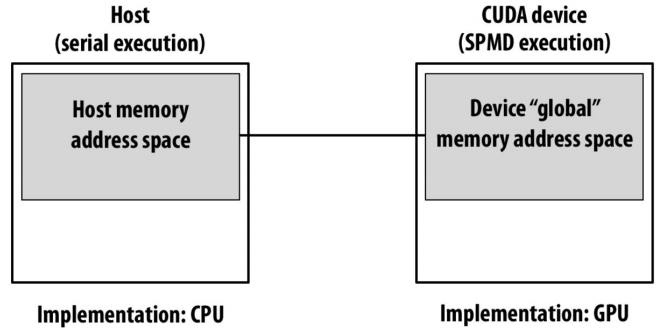
CUDA memory model
- 使用 cudaMalloc 为 A、B、C 分配设备内存。
- 使用 cudaMemcpy 将主机数组 h_A、h_B 拷贝到设备数组 d_A、d_B。
- 使用 cudaMemcpy 将结果 d_C 拷贝回主机 h_C,并打印部分结果。
- 使用 cudaFree 释放设备内存
注意cuda在使用上述cudaMalloc和cudaMemcpy等API都是基于Device global memory address space,实际上每个线程块也有共享内存,每个线程也有私有内存。
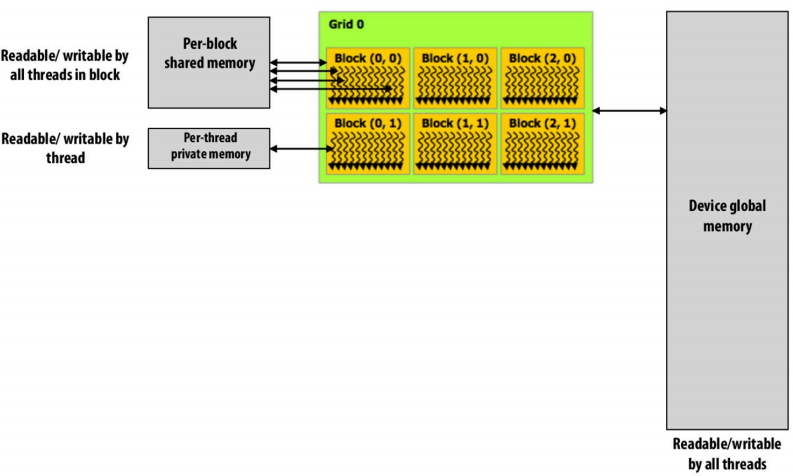
在__device__和__global__代码中__shared__ 标识的变量表示每个线程块中都有且在线程块中对于每个线程共享。而普通变量则是线程内独有的。
CUDA synchronization
__global__ void exampleKernel(float *input, float *output) {
__shared__ float sdata[128];
int tid = threadIdx.x;
int index = blockIdx.x * blockDim.x + threadIdx.x;
// 每个线程将全局内存数据加载到共享内存中
sdata[tid] = input[index];
// 同步所有线程,确保共享内存加载完毕
__syncthreads();
// 后续操作依赖于共享内存中所有线程的数据
output[index] = sdata[tid] + sdata[(tid + 1) % 128];
}
在 CUDA 编程中,__syncthreads() 是一种线程同步原语,主要用于同一个线程块(block)内的所有线程之间进行同步。
为何需要__syncthreads()? 同一个线程块(block)内的所有线程难道不是同时读写完吗?
这其实和CUDA提供的抽象相关:
- 在同一个线程块内,线程是并行执行的,并行执行并不意味着同时开始,也意味着它们在任何时候都“同时”完成。
- CUDA 将线程组织成 warps(通常32个线程一组),同一个 warp 内的线程会锁步执行,即同时完成。
- 但一个线程块中可能有许多个warp,但不同 warp 之间并不一定完全同步。
- 这和ISPC还是很不一样的。
除__syncthreads()外,同步语法还有Atomic operations,作用于device global memory 和 block share memory variables.
Host和Device之间的同步是隐式的,在kernel function返回时自动帮我们处理好了。
CUDA abstractions
#define THREADS_PER_BLK 128
__global__ void convolve(int N, float* input, float* output) {
__shared__ float support[THREADS_PER_BLK+2]; // per-block allocation
int index = blockIdx.x * blockDim.x + threadIdx.x; // thread local variable
support[threadIdx.x] = input[index];
if (threadIdx.x < 2) {
support[THREADS_PER_BLK + threadIdx.x] = input[index + THREADS_PER_BLK];
}
__syncthreads();
float result = 0.0f; // thread-local variable
for (int i = 0; i < 3; i++)
result += support[threadIdx.x + i];
output[index] = result / 3.f;
}
// host code
int N = 1024 * 1024
cudaMalloc(&devInput, N+2);
cudaMalloc(&devOutput, N);
// property initialize contents of devInput here...
convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, devInput, devOutput);
现在想象一种情况,我的N非常大,在核函数调用参数中,设置的Thread Block为8K(8000)个(即总共启动的Thread为\(8000 * 128 = 1024000\),超过了1million个线程)会如何?
真的会有8000个block share variable(即上述代码中的support)分配给我吗?真的会有1024000个线程(意味着1024000个局部变量和栈)分配给我吗?
答案是不会的
在C API中我们如果用pthread启动了线程,操作系统会实打实地为每个线程分配对应资源,然后运行,如果我们启动超过1million个线程,我们的程序会终止,因为资源根本不够我们使用。
在ISPC中,我们启动超过1million个tasks会发生什么?(Assignment 1 Prog5中的一个问题):
当然不会真正地启动1million个线程处理每个tasks,而是基于线程池的思想:
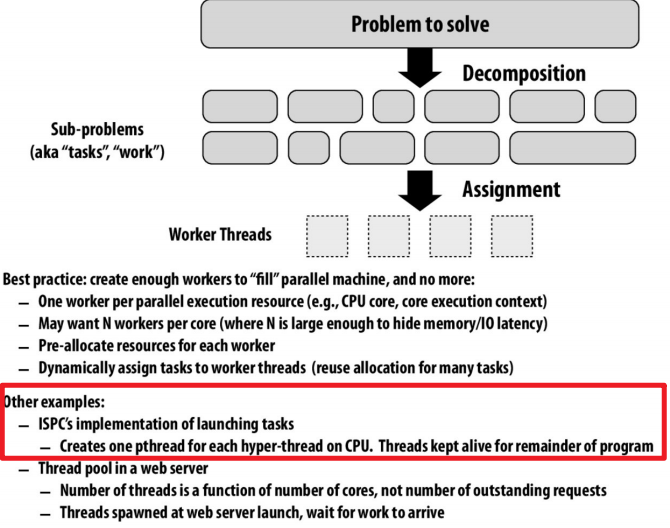
CUDA 线程由 GPU 的硬件调度器(SIMT 架构)管理。
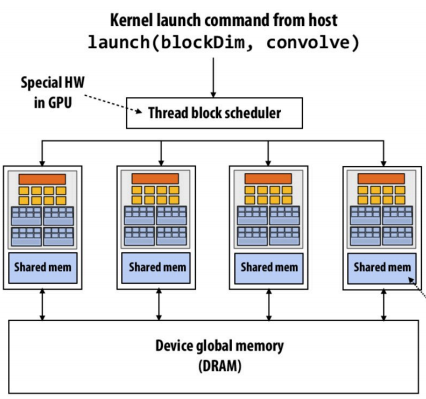
CUDA以thread block为任务单位,将任务分配给GPU Core:
- 虽然逻辑上可以声明 1 million(1,000,000)个线程,但 GPU 不会为每个线程都分配独立栈,也不会立即调度所有线程同时执行。
- 不同块可以分时复用共享内存。只有同时活跃的线程块才会占用共享内存。如果共享内存不够,则排队等待。
示意图be like:
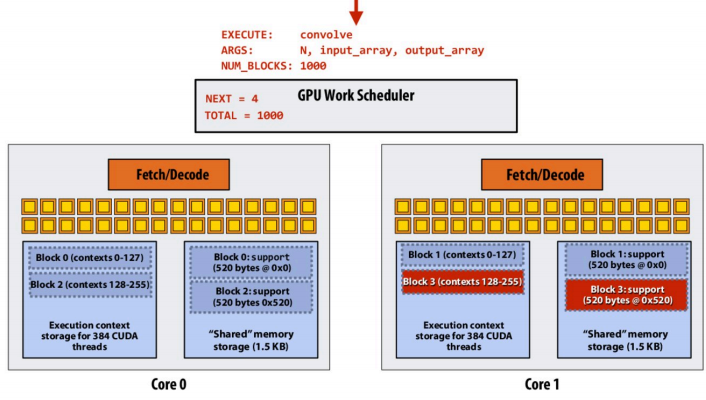
当Block 0中的数据在Core 0中执行完成后,排队的Block 4到Core 0中继续执行:
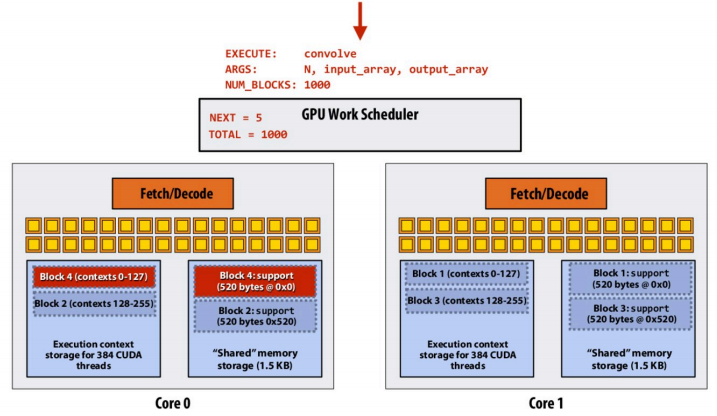
Warps

GPU Architecture
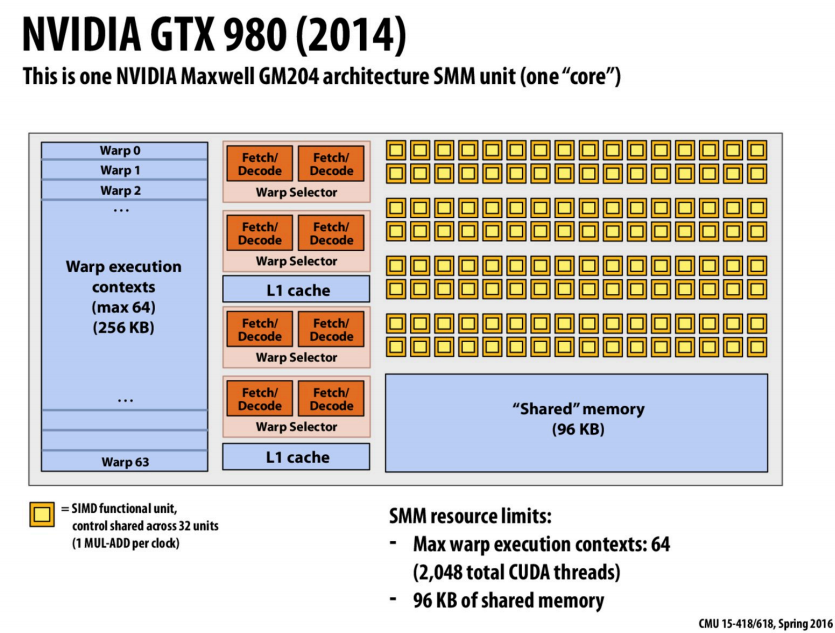
- 32个SIMD functional unit共享控制
- “Shared” memory用于存储使用
__shared__声明的变量 - 一个warp有32个thread,这里一个core有64个Warp execution contexts,则一个core最多2048个线程并行(线程级并行)
- 对于每个warp每个时钟周期有两条指令可执行(指令级并行)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号