Perf Linux性能事件(性能计数)器 与 Flame Graph

性能分析基础知识
Benchmark
Benchmarks are designed to mimic a particular type of workload on a component or system.
基准旨在模拟组件或系统上特定类型的工作负载。
from wiki
Standard Performance Evaluation Corporation (SPEC)
标准性能评估公司(SPEC)是一个非营利性联盟,负责建立和维护新一代计算系统的标准化基准和性能评估工具。

SPECjvm2008就是他们的,其是模拟Java Runtime Environment (JRE)上特定类型的工作负载测试套件
SPECjvm2008 workload names(部分):
startup.helloworld compiler.compiler scimark.fft.small
startup.compiler.compiler compiler.sunflow scimark.lu.small
startup.compiler.sunflow compress scimark.sor.small
...
Workload
"workload" can be broken up into "work+load", referring to the work done with a given load.
“工作量”可以分解为“工作+负载”,指的是在给定负载下完成的工作。
在重量训练方面,“负载”指的是被举起重量的重量(20 公斤的重量比 10 公斤的重量更重),而 “工作”指的是体积,或者说是使用该重量完成的总次数和组数(20 次重复比 10 次重复更费力,但两组 10 次重复的工作量与一组 20 次重复相同)。
-
Benchmark(基准测试):通常指的是一套标准化的测试任务或程序,用来衡量计算机系统(包括硬件和软件)的性能。
-
Workload(工作负载):指的是在真实或模拟环境中,系统实际运行的任务或应用程序的集合。
benchmark往往基于或模拟某类常见的workload,以便测试在标准环境下的系统性能,从而使不同系统或配置之间的性能对比更加公平和准确。
性能分析中的术语和指标
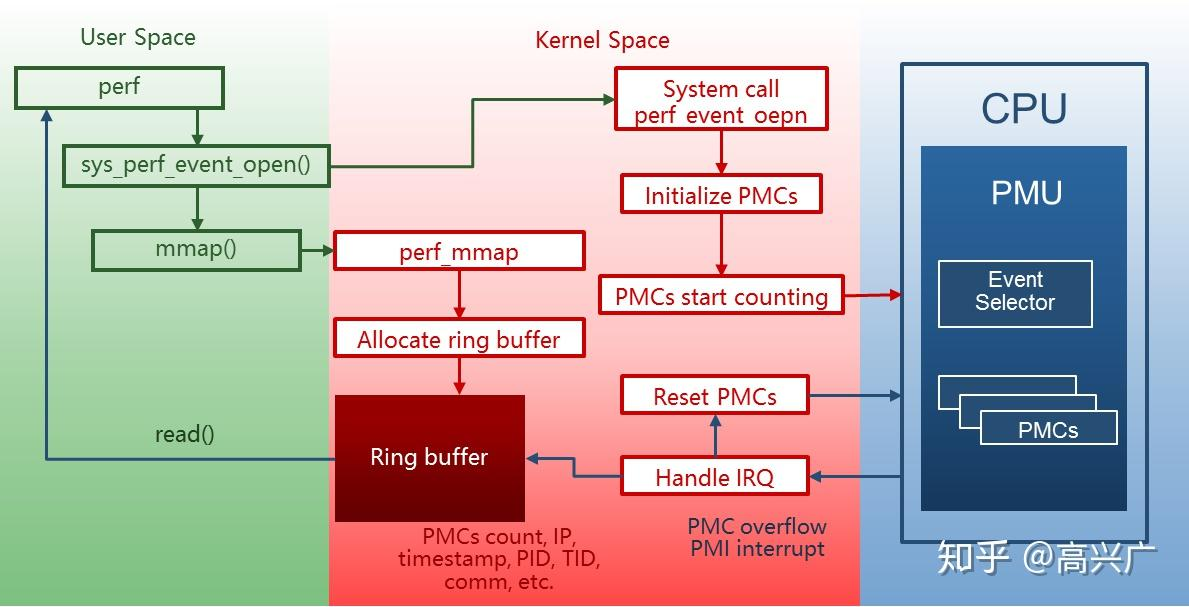
Perf 性能采样和计数原理
PMU counters and profiling basics.
首先要清楚perf是一个面向事件的可观察性工具

perf在中断来临时,获取OS在中断之前所记录的关键性能指标
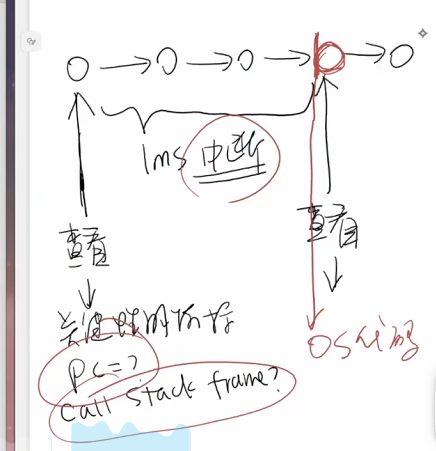
perf工具的数据来源自PMC(Performance Monitoring Counter),PMC 来自 PMU(Performance Monitoring Unit)
-
PMU(性能监控单元) 是处理器中的一个硬件子系统,用于监控和分析 CPU 的运行状况。它负责跟踪各种硬件事件(例如指令执行、缓存命中、分支预测等),并将这些事件的信息存储在 PMC(性能监控计数器)中。
- PMU 的主要组成部分
- 事件选择器(Event Selector):负责选择需要监控的事件,比如“指令完成数”或“缓存未命中数”。每个 PMU 通常支持多种事件,通过配置寄存器来指定目标事件。
- 性能监控计数器(PMC, Performance Monitoring Counter):PMU 的核心部件,用于记录选定事件的发生次数。通常是硬件计数器,以二进制形式累积事件数。
- 数量有限:由于硬件资源限制,PMC 的数量通常较少(例如 4 或 8 个计数器)。
- 事件绑定:每个 PMC 可以绑定一个事件,并记录该事件的累计次数。
- 可复用:通过切换事件绑定,可以在有限的 PMC 中监控更多的事件。
- 控制寄存器:用于设置和控制 PMU 的工作模式,例如启用/禁用事件监控、设置中断阈值等。
- 中断支持:PMU 可以在特定事件计数达到阈值时触发中断(PMI Performance Monitoring Interrupt),便于实时性能分析。
- PMU 的主要组成部分
Perf Stat (性能计数)
stat (statistics) 有统计,计数,获取信息等含义
perf stat <command>对程序运行时所发生的性能事件进行统计:
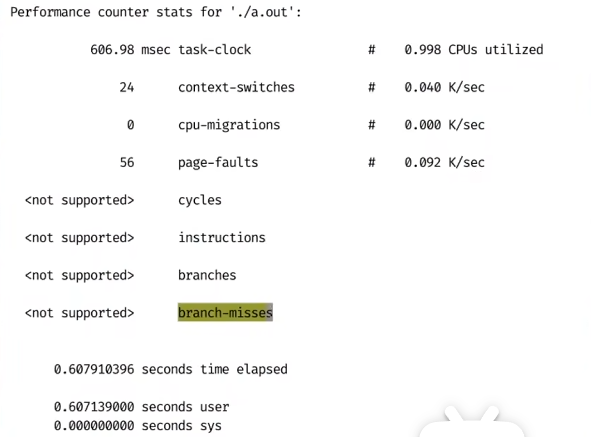
not supported 是因为jyy老师用的虚拟机上一些功能不支持
让我们具体理解perf stat指标的一些含义,以如下数据为例:
perf stat
Performance counter stats for 'system wide':
59487.66 msec cpu-clock # 161.623 CPUs utilized
1226 context-switches # 20.609 /sec
160 cpu-migrations # 2.690 /sec
224 page-faults # 3.765 /sec
100555765 cycles # 0.002 GHz
102916310 instructions # 1.02 insn per cycle
22678744 branches # 381.234 K/sec
742224 branch-misses # 3.27% of all branches
500008275 slots # 8.405 M/sec
103029273 topdown-retiring # 20.6% retiring
55668854 topdown-bad-spec # 11.1% bad speculation
229414328 topdown-fe-bound # 45.9% frontend bound
111895524 topdown-be-bound # 22.4% backend bound
0.368064015 seconds time elapsed
59487.66 msec cpu-clock # 161.623 CPUs utilized 表示总共执行了59487.66毫秒(ms)的cpu-clock,注意这里如果直接使用默认的perf stat是统计全部CPU上的非停顿执行时间。
\(CPUs untilized = \frac{CPU 非停顿执行时间}{执行总时间}\),这里即为\(\frac{59.48766}{0.368064015} \approx 161.623\)
1226 context-switches # 20.609 /sec 表示此次统计出现了1226次上下文切换,平均每秒出现20.609次上下文切换。计算方式为\(1226 / 59.48766 \approx 20/609\)
100555765 cycles # 0.002 GHz 表示程序运行期间消耗的 CPU 时钟周期总数, 其中0.002 GHz表示CPU 的平均有效频率(实际工作频率),计算方法为\(100555765 / 59.48766 \approx 0.002GHz\) (\(频率 = \frac{时钟周期}{时间}\))
102916310 instructions # 1.02 insn per cycle 表示已退役指令的数量
某些指令被识别为惯用语,并且在没有实际执行的情况下被解析。其中一些示例是NOP、移动消除和清零,这些指令不需要执行单元,但仍然被退役。因此,从理论上讲,可能存在已退役指令数量高于已执行指令数量的情况。
虽然没有性能事件来收集已执行的指令,但有一种方法可以收集已执行和已退役的微操作
500008275 slots # 8.405 M/sec 其中slot为管道槽 (pipeline slot),管道槽代表处理一个微操作所需的硬件资源。
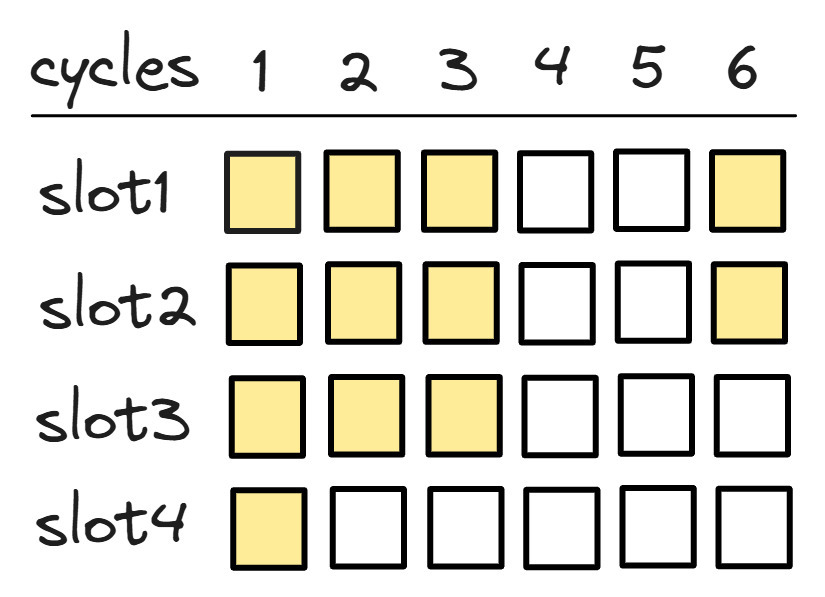
这意味着核心可以在每个周期将执行资源(重命名的源和目标寄存器、执行端口、ROB 条目等)分配给 4 个新的微操作。这样的处理器通常被称为4 宽机器。
Perf Record (性能采样)及其可视化
采样
perf record -o perfData/perf.data -e cycles -g -F 99 ./a
perf report -i perfData/perf.data
-o指定搜集的数据保存地址,需要保证perfData这个目录是存在的-e cycles-e指定采集的事件,cycles表示CPU时钟周期数-g表示开启调用栈采样,便于分析程序中函数调用关系-F表示指定采集频率(HZ 每秒采样次数),这里表示每秒采样 99 次perf report中的-i指定查看采集数据的地址- ctrl + c中断采样,即
kill -SIGINT $pid_prefrecord,主要不能使用kill -9 $pid_prefrecord进行中断,这样会导致记录数据错误
采集频率的设定会影响性能,不能太大或太小:
99次是一种常见的使用频率,但是为何频率设置为100会出现所谓的lock-step sampling呢?
Lock-step sampling 指的是当采样事件与系统或程序的周期性行为锁定(lock in)时,采样可能总是在特定的执行状态或代码路径中触发,导致采样结果不能反映程序的全局行为。这会引入以下问题:
- 偏差(Bias):采样可能总是在某些特定的函数、线程或代码路径上触发,遗漏其他关键路径。
- 不准确:分析结果可能错误地将某些函数误判为性能瓶颈,或者完全忽视实际的热点。
导致可能有:
-
(a) 系统周期性行为的同步
现代计算机系统中的许多事件是周期性发生的,例如:- CPU 时钟信号的周期(Clock Cycle)。
- 定时中断的触发频率(例如,操作系统调度器的时间片通常是 10ms,即 100Hz)。
- 硬件计数器的刷新频率。
如果采样频率(100Hz)与这些周期性事件的频率相同或成整数倍关系(同步),采样点就会总是落在这些事件的同一个状态上。例如: - 每次采样可能总是捕获到某些特定线程正在运行,而忽略了其他线程。
- 如果某个函数在每个周期开始时被频繁调用,采样可能总是在捕获它,而忽略其他部分。
-
(b) 系统时间片的默认设置
许多操作系统的任务调度器时间片默认是 10ms(100Hz)。如果采样频率也设为 100Hz,就会导致采样事件总是发生在时间片的开始或结束时。这种情况可能导致:- 采样总是在线程切换之前或之后触发,而无法反映线程运行中的真实状态。
- 某些短时间运行的函数可能被完全忽略,因为它们总是在采样事件之间执行。
-
(c) 代码自身的周期性
某些代码可能具有周期性行为,例如:- 循环内的操作可能具有固定执行时间。
- 网络或 IO 轮询任务每隔固定时间运行一次。
-
(d) 将内核(系统)代码采样进去了,导致污染
- 单位时间内采样的次数 比如1000Hz, 4000Hz; 我们在perf采样的时候要尽量避免这些频率,因为这会和操作系统内核的频率撞车;
- 如果撞车了,会导致将一些内核的活动如中断等采样进去,这是我们不希望的, 我们perf可以设置999HZ,3999HZ进行采样
更加具体的以数学计算表示:


Perf-Record and Perf-Script
通过Perf record可以得到perf.data二进制文件,我们可以通过perf report和perf script得到人类可读信息。
perf report的信息主要侧重在总结:perf report --no-call-graph --header -i perf.data -F overhead,pid,dso,sym > perf-nogF.report
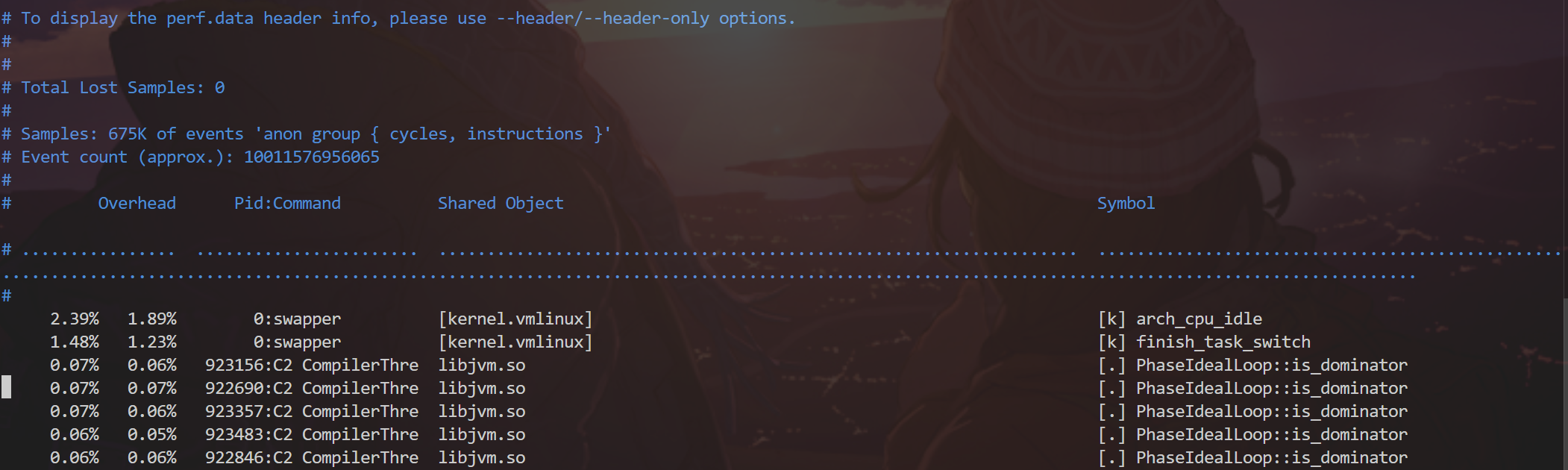
让我来解释下每个参数的含义:
因为这里我利用perf record采集的是两个事件:cycles和instructions。所以在perf record中会记录采集到的某个函数某次消耗cycles和instructions的值。
然后累积总结得到上述信息,在这里以第一行为例子,即进程0所执行的swapper进程,在执行arch_cpu_idle函数时所消耗的cycles为2.39%, 所消耗的instructions为1.89%
[k] 表示这是一个内核空间(kernel space)符号。[.] 表示这是一个用户空间(user space)符号。
Symbol:函数或符号名称,表示性能事件发生的代码位置。
Shared Object:共享对象(动态链接库或内核模块)名称。
如果去除--no-call-graph参数可以更详细地看到在函数执行时各个子调用所消耗的事件占比
perf script 侧重于事件:perf script -i perf.data --hide-call-graph > perf-nog.script

从左到右值的含义分别为:
- command
- PID
- CPU
- 时间戳
- 事件值
- 事件
- 事件发生时的指令地址
- 事件发生时的函数+偏移量(函数表明在哪个函数发生的,偏移量是从汇编的视角进行理解的,可以通过函数名地址+偏移量得到在哪条汇编指令上发生的事件)
- 函数所在的文件路径
符号缺失是个非常严重的问题,这会导致函数名未知,而显示出[unknown]。如果想要查看栈信息那么栈帧缺失也是个非常严重的问题。
栈帧和符号
参考巨佬写的博客:The Return of the Frame Pointers
总得来说就是在查看report和火焰图时符号出现了unknow

符号是通过栈帧得到的,栈帧是什么?
在 x86-64 架构中,%RBP(Base Pointer) 和 %RIP(Instruction Pointer) 是两个关键寄存器,用于标识栈帧信息和程序的执行位置。同时还有%rsp记录当前栈顶。
CPU 寄存器 %rbp 用作堆栈帧(也称为“帧指针”)的“基指针”。
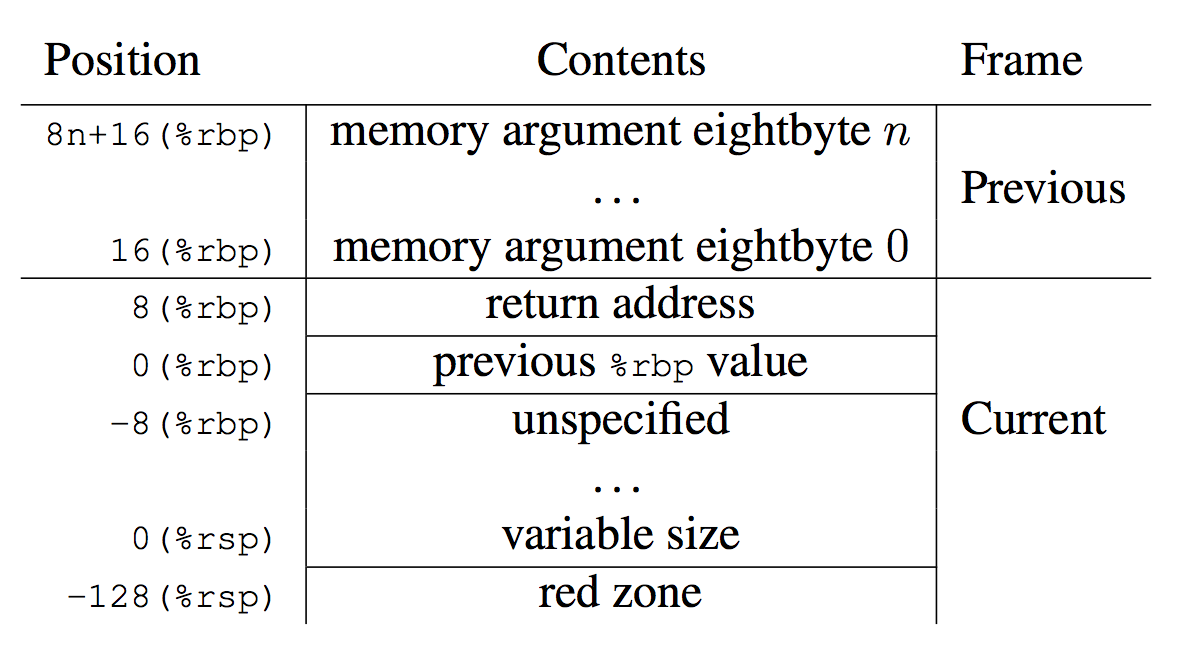
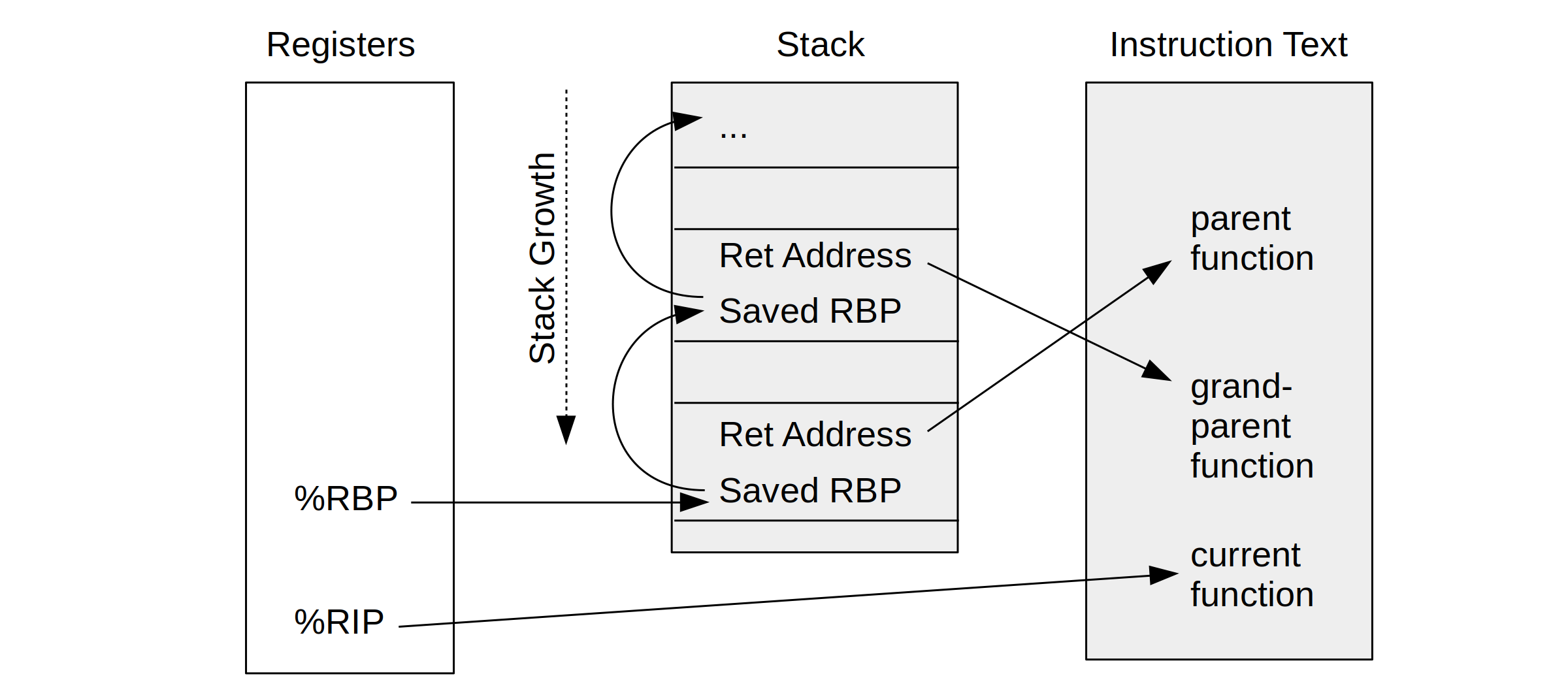
通过 Stack-Walking(栈遍历),可以获取每个栈帧的函数调用关系、调用地址(程序计数器 PC),以及与函数调用相关的其他元信息。具体过程如下:
-
首先由(b)图可知,我们可以通过%rip得到当前正在运行指令的地址,只要能够知道指令的地址,就能够有方法知道这条指令是在那个函数下的,就可以知道函数名等元信息
-
然后(a)图可知可以通过当前%rbp的值得到父函数的栈帧地址,即上一栈帧的地址。
通过对%rbp做位移(即8(%rbp))可以知道父函数的返回后要执行指令的地址,从而得到父函数的元信息。 -
利用
previous %rbp value进行跳转,跳转到父函数的栈帧上,从而可以得到祖父的栈帧信息和返回后要执行指令的地址信息,从而得到祖父函数的元信息。 -
不断如此,可以得到整个函数调用链。
遇到的困难
在上述巨佬写的博客中也描述了遇到的困难:
the flame graph looks ok at first glance. But there are 15% of samples on the left, above "[unknown]", that are in the wrong place and missing frames.
The problem is that this system has a default libc that has been compiled without frame pointers, so any stack walking stops at the libc layer, producing a partial stack that's missing the application frames.
libc 是 C 标准库 (Standard C Library) 的实现,是所有 C 程序运行时的基础库,提供了许多核心功能。
系统中默认的 libc(标准 C 库)没有启用 frame pointers(帧指针) 的编译选项,导致在使用工具进行 栈回溯(stack walking) 时只能获取部分调用栈信息。这种情况下,调用栈在到达 libc 层时中断,无法追溯到应用程序层的调用栈信息。
有些编译器(如 GCC 和 Clang)or 系统默认会启用优化选项(如 -fomit-frame-pointer),省略帧指针 以释放寄存器资源,提高性能。
可视化
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。 注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
采样,perf-events 分组 与 PMC复用
采样(sampling)是一种性能分析模式:不是持续记录所有事件,而是在特定时刻或当某硬件计数器达到预设阈值时,截取一次“样本”数据,用于后续聚合分析。
触发采样的常见机制
-
硬件事件计数器溢出:
- 现代 CPU 的硬件性能监控单元(PMU)可以对如 CPU 周期数、已执行指令数、缓存访问次数等事件计数。用户在 perf 中指定采样周期(sampling period),例如每执行 N 条指令或 N 个周期,就让硬件计数器达到阈值后“溢出”并触发一次中断。
- 当计数器溢出时,CPU 会产生一个中断,perf 的中断处理例程捕获此次中断,读取程序计数器(PC)、调用栈等信息,记录为一次样本。
-
定时采样(timer-based sampling):
- 有时不关心具体硬件事件,而希望按固定频率采样,如每 99Hz(约 10ms)触发一次。Linux perf 可通过周期性定时器生成中断进行采样。在这种模式下,perf 在每个定时间隔到来时触发样本记录,样本通常包括当前执行的地址或栈信息。
- 这种方式的触发条件是时间间隔到达,而不依赖于硬件事件计数。
-
软件/Tracepoint 触发:
- 也可基于特定软件事件或 tracepoint(如函数入口/出口、系统调用等)触发样本,属于事件驱动采样。设置某个 tracepoint,当该事件发生时记录样本。
perf record基于采样实现性能分析,其中perf record -F 99表示按 99 次/秒的“频率”采样,它设置的是 perf_event_attr.sample_freq
- 若监控的是硬件事件:perf 会根据目标频率动态计算一个近似的硬件计数阈值(sample_period),然后让 PMU 硬件计数器在累计到该阈值时溢出并触发中断,从而做一次采样
- 软件事件或默认 cpu-clock 事件则 perf 内核会使用定时器中断来实现近似频率采样,这属于定时采样机制,而非硬件计数器溢出。
perf record -e '{cycles,cache-misses}:S' ./your_app
事件分组(Event Grouping) 是 Linux perf 提供的一种机制,用于 将多个性能事件绑定为一个“原子组”一起采样,从而保证这些事件的统计和采样具有时间上的一致性。
默认情况下,如果你用 perf stat -e cycles,cache-misses, 每个事件会独立调度和统计。由于 CPU 资源有限,多个事件可能不能同时被监控 —— 会导致 某些事件被 multiplex(复用),从而产生统计误差。
比如在某个时刻cycles的计数器因溢出而触发采样,但是cache-misses的计数器还没有溢出不会进行采样;当下一时刻cache-misses计数器溢出了触发采样
每次采样记录可能包含:
- 事件类型:cache-misses
- 当时的程序计数器(IP)、调用栈等上下文
- 事件类型 cache-misses 计数到阈值时的当前值
如果后续想用样本来计算“单位 cycles 的 cache-misses 比率”,理想是同一时间点同时获取 cycles 和 cache-misses 计数,才有意义。但是因为上述采样在不同时间点,“样本对齐”不一致,导致比率或其他联动指标计算失真。
若使用:perf record -e '{cycles,cache-misses}:S' ./your_app
只有分组的 leader 事件(第一个指定的事件)触发采样;在采样时,perf 会通过 PERF_SAMPLE_READ 读取 leader 以及组内其它事件的当前计数值,从而在同一个采样点拿到所有事件的值。这能减少触发采样事件的次数,同时保证同一时刻数据的原子性和一致性
在上述案例中,leader事件为cycles,也就是说只有当 cycles 计数器溢出(或达到指定 period)时才触发中断;采样处理例程会同时读取 cache-misses 的当前计数,把两者作为一个样本保存下来
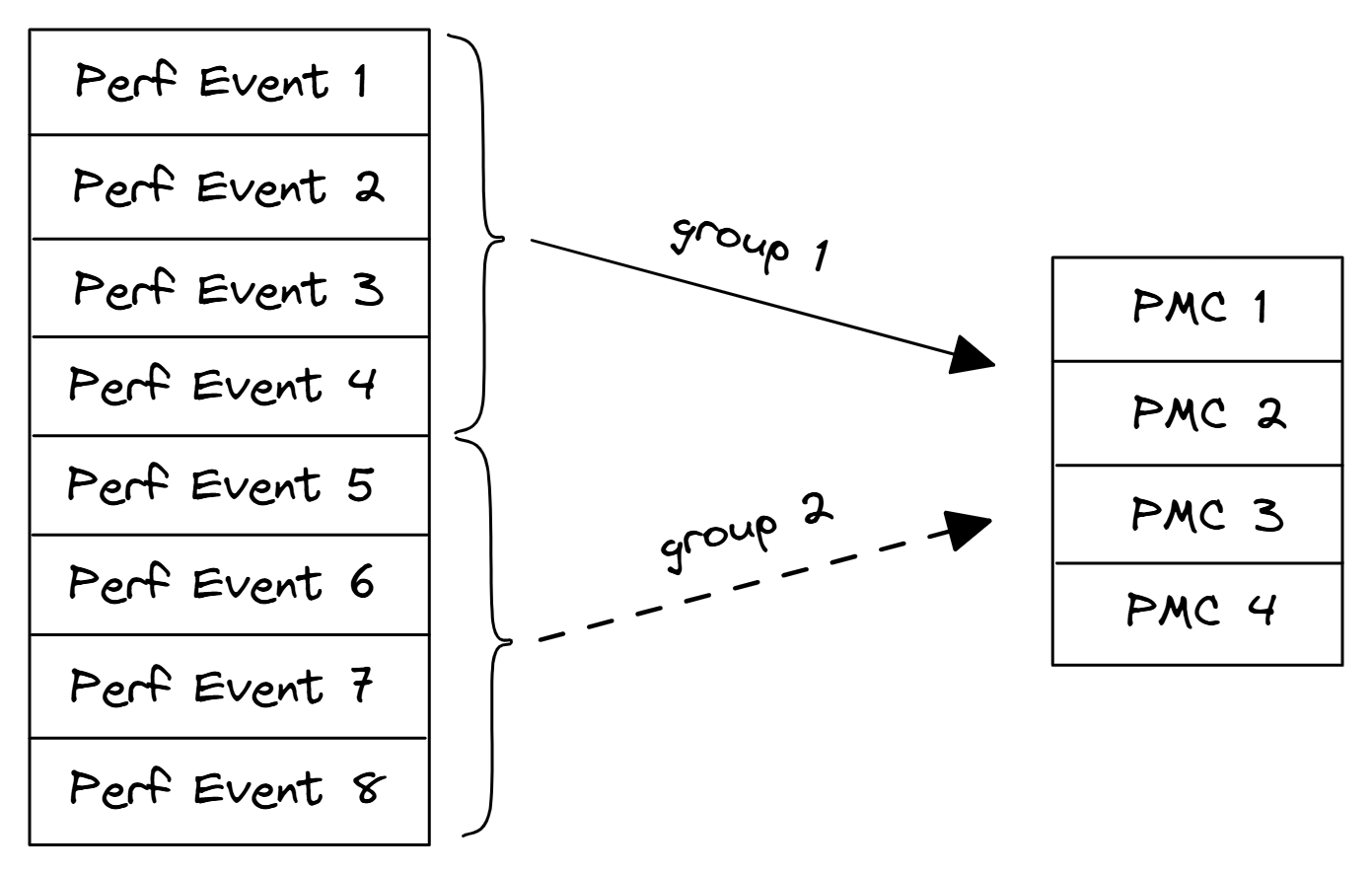
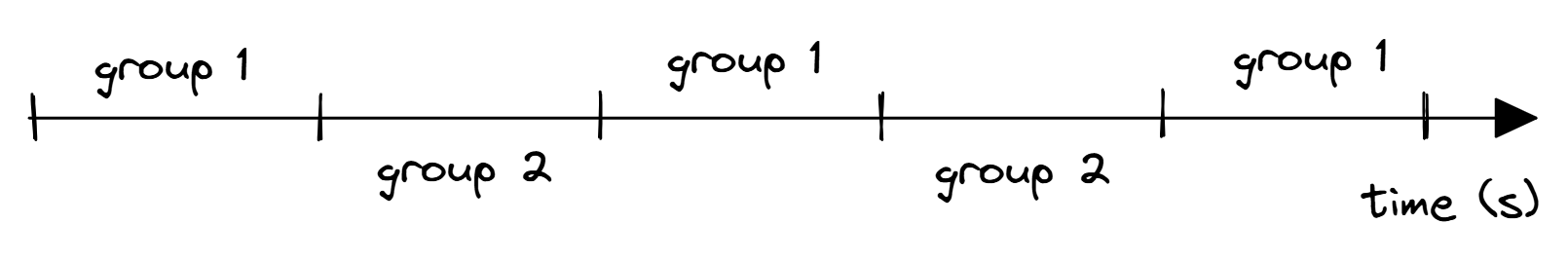
8个性能事件之间的多路复用示例,只有4个PMC可用。最后通过缩放来计算结果:

为了避免缩放,可以尝试将事件的数量减少到不超过可用物理PMC的数量。然而,这将需要多次运行基准测试,以测量感兴趣的所有计数器。
硬件事件滑移 与 精确事件(PEBS)
Understanding performance events skid.
Advanced profiling topics. PEBS and LBR.
Event skid is caused by a number of factors:
- The delay in propagating the event out of the processor's microcode through the interrupt controller (APIC) and back into the processor.
中断触发与处理的延迟:当 PMU(Performance Monitoring Unit)计数器溢出或满足某条件时,会生成中断请求。但从事件发生到 CPU 真正进入中断处理例程,这期间还要完成当前指令的流水线处理、上下文保存等步骤。这段时间里,CPU 可能已经执行了后续指令。最后记录的 IP 往往是中断到达并被处理时的指令地址,而非事件刚发生那刻的地址。
- The current instruction retirement cycle must be completed.
指令退休(retirement)机制与乱序执行:现代处理器通常是乱序执行、深度流水线设计。某条指令触发的事件,在底层可能要等它退休(commit)后,或者通过硬件缓冲才能安全记录。如果事件只能在 instruction retire 时才能被安全捕获,就会出现“等待退休”导致的偏移;或者在 retire 之后、下一个 retire 点记录,都引入不确定的滑移范围。
- When the interrupt is received, the processor must serialize its instruction stream which causes a flushing of the execution pipeline.
流水线清空与串行化(serialization)开销: 为了进入中断处理,处理器会对流水线做一定的清空/串行化操作,这本身需要时间,也会让更多指令在事件和记录之间执行,进一步扩大滑移范围。
- 滑移通常在指令或基本块级别发生,跨函数的概率较低
- 函数级聚合平滑了滑移造成的小幅误差
- 可能会出现滑移跨函数边界导致调用者函数的事件被记录到被调用者函数。
这导致调用者函数少了几个样本、被调用者函数多了几个样本。但只要这种跨函数滑移样本占整个采样总量的比例极低,就无法显著改变两个函数在全局热点排名中的位置。
通过让处理器本身存储指令指针(以及其他信息)可以缓解滑移问题。使用 Intel PEBS 时,PEBS 记录中的 EventingIP 字段指示导致事件的指令。这通常仅适用于受支持事件的一个子集,称为“精确事件”。

在 Linux perf 中,针对支持精确采样的硬件事件(Intel PEBS、AMD IBS 等),可以在事件名后加 :p 修饰,表示对采样的 IP 精度提出更高要求。多次添加 p(如 :pp、:ppp)对应不同的精确级别:
- 0 个 p:允许任意 skid(SAMPLE_IP 可以有任意偏移)。
- 1 个 p:要求 SAMPLE_IP skid 是常量范围。
- 2 个 p (:pp):请求 0 skid(SAMPLE_IP 尽可能精确为触发事件的指令地址)。
- 3 个 p (:ppp):要求 0 skid,或在某些平台上使用随机化以避免样本“阴影”效应。
这一语义来源于 perf 的文档说明:Intel PEBS 通常支持到精确级别 2,某些特殊情况可支持到级别 3;AMD IBS 通常也支持到级别 2(多余的 p 与少量 p 同义于 IBS)。
PEBS 原理
为何普通的基于中断的会导致event skip?
在现代乱序执行(OOO)的处理器下,只有指令退休时才会更新架构的状态(计数器,寄存器等);例如许多 PMU 事件(如 “指令退休数”)通常是在指令退休(instruction retirement)阶段对计数器加一。也就是说,只有当一条指令真正完成所有阶段并提交(commit/retire)到架构状态时,该事件才计入。
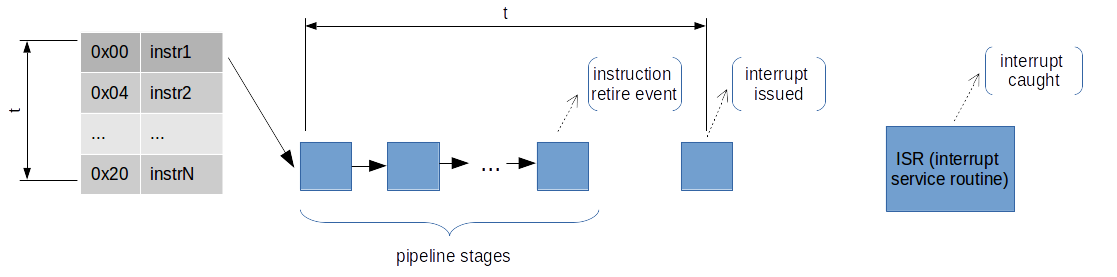
当某次退休使得计数器达到或超过设定阈值(overflow threshold)时,PMU 逻辑会“记录”该溢出,并生成一个中断请求信号(performance interrupt request)。
从发送中断请求信号到中断来临后,这个过程到底发生了什么?
“中断请求”标志,通常通过专用总线或控制线向核心控制逻辑(interrupt controller)通知。
这一通知并非瞬时完成,可能需要若干周期:包括从退休单元传递到 PMU control,再到中断处理单元(IC)。此外,CPU 可能正忙于 retire/commit、分支预测、乱序调度等微架构活动,中断请求在硬件上要先挂起,等待合适的点插入到流水线的中断处理流程。
-
只能在某些“安全”点响应中断:现代 CPU 在乱序执行环境中,不会在任意微操作上突然停下,而是要在能够“正确”保存和恢复上下文的位置响应。
-
可能的额外延迟:在检测到请求后,如果当前正在执行的指令或流水线上还有尚未退休的指令,CPU 可能继续执行、退休这些指令,直到到达下一个检查点才进入中断服务(ISR)。因此从“实际导致溢出的那条指令退休”到“CPU 停下来跳转进行中断处理”,之间可能还执行了数条或数十条指令。
一旦确定要响应中断,CPU 会将必要的寄存器(包括通用寄存器、程序计数器 IP、状态寄存器等)保存到中断堆栈或特定寄存器组,然后跳转到固件/内核中断处理入口。此时的 IP 就是“打断点”时的 IP,而非溢出指令的 IP。
这就解释了为何基于中断的采样会导致event skip。
一些额外话题IP(Instruction Pointer)的本质与内部机制
-
架构视角下只有一个 IP: 从程序员/操作系统的视角,每个硬件线程(logical core)都有一个唯一的程序计数寄存器(在 x86-64 上称 RIP,在其他架构上称 PC 或 IP)。这个寄存器存放下一条要执行指令的地址或当前指令地址,代表程序的进行位置。(只有在指令退休时才会更新此IP)
- 操作系统和调试、采样都会使用此 IP 作为“当前执行点”或“断点点”。
-
微架构内部的多重跟踪IP: 重排序缓冲区(Reorder Buffer, ROB):乱序 CPU 会同时在不同阶段执行多条指令,ROB 中会为每条在飞指令维护对应的架构状态(如目的寄存器、以及程序计数信息)。 不过这些只是内部追踪,未提交的指令不会更新架构寄存器。
- 但对外可见只有一个:直到某条指令退休,才会把其结果和对应的 PC 更新到架构状态(即更新 RIP 到下一指令地址)。
PEBS是如何缓解event skip的?
当某硬件事件计数器即将或刚刚发生溢出时,硬件会先将触发该事件的指令对应的状态写入预先配置好的内存缓冲区(PEBS buffer),而不是在发生中断时再去读取当前的架构寄存器状态,从而大幅减小由于中断响应延迟引起的偏移
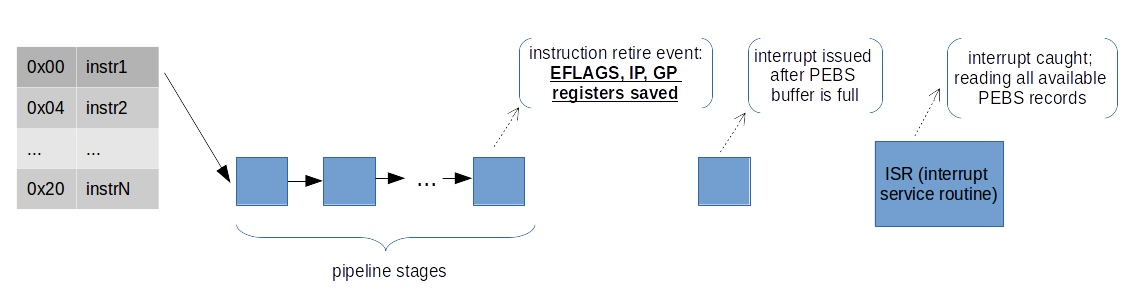
-
在传统中断采样中,PMU 计数器溢出后需经过信号传播、等待安全中断点等过程,此时处理器流水线可能已经执行了多条指令,导致 ISR 内读取的 IP 并非真正触发事件的指令地址,产生 skid。
-
PEBS 则在事件发生时“主动”将机器状态写入缓冲,不依赖后续中断读取当前 IP,从而在硬件层面捕获更接近触发点的上下文
PEBS 的记录流程:
当 PMU 事件支持 PEBS 且计数器接近溢出阈值时,硬件在执行导致溢出的指令退休时,会触发一个所谓的 “PEBS assist”:
- 内部指令退休检测:当某条指令退休且使计数器达到或超过阈值,PMU logic 在内部检测到溢出条件。
- 状态捕获写缓冲:硬件立即(或在非常短的延迟内)将此时的机器状态(如该指令的 PC/IP、相关寄存器值、TSC、性能事件寄存器等)写入预配置的 PEBS 缓冲区,而不立刻触发可见中断处理。
- 继续执行:写缓冲操作通常由硬件在后台完成,流水线可继续执行后续指令。
- 中断生成与批量提交:当缓冲区达到一定填充量,或者在适当时机,PMU 会生成中断通知操作系统来读取、清理缓冲区中的已记录条目。同样,即便中断响应有延迟,已记录的上下文仍然保存在内存,不受中断延迟影响
为什么只能缓解而非彻底消除 Skid?
- 支持事件有限
- 微架构复杂性与内部延迟:即便是支持 PEBS 的事件,硬件捕获仍需在指令退休、内部缓冲写入等环节完成,这中间仍有极短延迟。在高乱序和深流水线设计下,某些边缘场景(如跨核心同步、深度流水线失速恢复等)可能导致捕获点略有偏移。
perf采样因自身实现上导致的误差

-
当我们要用perf采样事件的时候,内核会依据perf采集的频率,估计出事件次数PMU Count(以保证能够在1s中确实采样了频率的次数); 然后每次事件发生了Count--, 当Count == 0时,发生中断,采样数据
-
这里会出现一些错误,因为Count是估计的,可能不准确,可能之前我程序运行的比较快,导致估计出PMU Count可能会偏大,但是真实情况下程序运行的比较慢了,导致事件发生的也比较慢,这让我们在固定时间内采样到的事件变少了
当前性能分析工具的缺陷
- Q1 :为何某个函数的 CPU 执行时间非常短,但对延迟或吞吐量影响极大?
- Q2 :为什么典型的性能分析器无法发现这类问题?
A1
-
处于关键路径(Critical Path)且被频繁调用:尽管函数本身执行时间短,但它在应用程序的关键路径上——也就是说,程序的整体响应时间取决于它何时完成。哪怕它只耗费了几微秒,如果它被频繁调用或成为瓶颈,那么它的延迟会被放大。
-
参与协调(如锁/同步):
- 例如一个获取锁的函数 acquire_lock() 自身执行时间短(尝试加锁)。但如果锁竞争严重,它可能导致其他线程阻塞等待,整个程序的延迟大大上升。
- 性能分析器可能只看到这段代码在 CPU 上停留很短,却未能捕捉到它引发的系统级延迟(如等待、阻塞)。
-
与硬件资源竞争:某些函数可能访问缓存敏感的数据、使用共享总线、NUMA节点等资源,对性能的微妙影响不会直接出现在 CPU 时间上,但会对整个系统的资源调度和局部性造成破坏。
A2
-
分析指标过于片面(以 CPU 时间为主)典型分析器忽视了等待时间、锁竞争、调度延迟、I/O 等待等非 CPU 的瓶颈。这会导致关键性短函数被掩盖,看起来“不重要”。
-
线程间因果关系未建模,多线程系统中,线程间的依赖关系很复杂。典型分析器通常不追踪“哪个线程在等待谁”,因此无法发现一个函数虽然短小,却让其他线程长时间阻塞。
-
无法关联上下文切换或排队时间,某些函数影响系统调度,比如唤醒其他线程、提交任务到队列,但本身不是热点。分析器看不到这种“延迟因果链”。
最佳实践
参考资料
- The Flame Graph This visualization of software execution is a new necessity for performance profiling and debugging -- 详细介绍火焰图在性能分析上的运用 -- 文章
- Java Performance Analysis on Linux with Flame Graphs -- 详细介绍火焰图在性能分析上的运用 -- 文章所对应的PPT
基于Perf测试SpecJvm2008基准测试
Brendan GreggFollow(上述资料的作者)给出的建议是:

为什么我们需要perf-map-agent?
答: 修复Perf所需的Java Symbols
For JlT'd code, Linux perf already looks for an externally provided symbol file: /tmp/perf-PlD.map, andwarns if it doesn't exist
Linux perf 工具 在分析 JIT 编译的代码时,会自动查找一个外部提供的符号文件,该文件的默认路径是 /tmp/perf-PlD.map。如果这个文件不存在,perf 会发出警告,提示符号文件缺失。
JIT 编译后的代码通常没有传统的符号信息,因此需要额外的符号文件来帮助 perf 正确地解码和解析程序的执行数据。
perf-map-agent就能够生成/tmp/perf-PlD.map这个文件,作者使用的方式:

注意这个代码需要运行在root用户下
-
~/.bashrc普通用户目录下的环境变量配置文件 -
/etc/profileroot用户的环境变量配置文件 -
/etc/sudoers使用sudo命令时的环境变量配置文件
当没有sudo权限时,我们运行不了jmaps代码,直接在java opt中加入-agent:一般会有如下报错:
Error occurred during initialization of VM
Could not find Agent_OnLoad function in the agent library: /home/yxlin/opt/tools/perf-map-agent/out/libperfmap.so
解决方案:
- async-profiler,目前
java -agentpath:/path/to/libasyncProfiler.so=start,event=cpu,file=profile.html ...这种使用方式并不能解决perf script中出现symbol缺失的问题 - perf-map-agent的补丁,可以使用-agentpath,从这位老哥github上拉perf-map-agent的代码
然后就可以使用在java opt中加入-agent:这种方法了,案例:
# $HADOOP_HOME/etc/hadoop/hadoop-env.sh 为例
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -XX:+PrintGCDetails -XX:+PrintFlagsFinal -XX:+PreserveFramePointer -agentpath:/home/yxlin/opt/tools/perf-map-agent/out/libperfmap.so"
为什么我们需要Set -XX:+PreserveFramePointer
答:为了修复破损的栈

其他
还有如stack depth过低,导致超过此深度的栈信息被忽略的问题,inline导致栈帧丢失的问题,均有说明
执行的命令
# SPECjvm2008运行基准测试的命令行的一般形式是
java [<jvm options>] -jar SPECjvm2008.jar [<SPECjvm2008 options>] [<benchmark name> ...]
其中<SPECjvm2008 options>可以通过 props/specjvm.properties and props/specjvm.reporter.properties 这两个文件指定或者手动写在命令中。具体SPECjvm2008参数见
通过-pf <string> 来使用properties file.
./run-specjvm.sh startup.helloworld -pf props/specjvm.properties
./run-specjvm.sh startup.helloworld -pf /home/cilinmengye/java_perf/SPECjvm2008/props/specjvm.properties
SPECjvm2008 结果可以存储在哪里?
SPECjvm2008可以从任何目录运行;但是,specjvm.home.dir 必须指定为系统属性并指向 SPECjvm2008 位置(SPECjvm2008.jar 所在位置)。
-Dspecjvm.home.dir=/home/tests/SPECjvm2008指定,如:
java -Dspecjvm.home.dir=/home/tests/SPECjvm2008 -jar /home/tests/SPECjvm2008/SPECjvm2008.jar
SPECjvm2008 结果可以存储在哪里?
-Dspecjvm.result.dir指定,如:
java -Dspecjvm.home.dir=/home/tests/SPECjvm2008 -Dspecjvm.result.dir=/home/results/jvm08-results/ -jar /home/tests/SPECjvm2008/SPECjvm2008.jar
如何禁用报告生成
默认情况下,该工具将生成一个原始文件(xml 格式),其中包含基准测试运行的结果。每次迭代后都会存储结果,以免对测量周期产生影响,而且还会连续进行,以免在基准测试之间甚至迭代之间存储任何额外的数据,这可能会影响基准测试结果。
为了跳过生成所有结果,可以使用命令“-crf false”,以免将任何结果打印到文件中。这意味着不会有原始文件,并且无法后期生成任何 html 报告或文本报告。
Perf + Specjvm2008基准测试
taskset -c 0-3 perf record -o $PERFDATA_PATH -e cycles -g -F 99 -T -- \
java -XX:+PrintGC -XX:+PreserveFramePointer \
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps \
-XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC \
-Dspecjvm.home.dir=/home/cilinmengye/java_perf/SPECjvm2008 \
-jar /home/cilinmengye/java_perf/SPECjvm2008/SPECjvm2008.jar \
-crf false -ikv -ict -i 10 -it 240s -bt 4 scimark.sparse.large >$TMPDATA_NAME 2>&1; ./jmaps
-
taskset -c 0-3指定CPU -
perf record -o $PERFDATA_PATH -e cycles -g -F 99 -Tperf-record的参数 -
-crf false -ikv -ict -i 10 -it 240s -bt 4 scimark.sparse.largeSPECjvm2008的参数
报错
很奇怪,如果
-pf /home/cilinmengye/java_perf/SPECjvm2008/props/specjvm.properties不在$SPECJVM2008目录下使用就会报错:Error reading properites file '/home/cilinmengye/java_perf/SPECjvm2008/props/specjvm.properties'
null
WARNING: Kernel address maps (/proc/{kallsyms,modules}) are restricted,
check /proc/sys/kernel/kptr_restrict and /proc/sys/kernel/perf_event_paranoid.
Samples in kernel functions may not be resolved if a suitable vmlinux
file is not found in the buildid cache or in the vmlinux path.
Samples in kernel modules won't be resolved at all.
If some relocation was applied (e.g. kexec) symbols may be misresolved
even with a suitable vmlinux or kallsyms file.
Couldn't record kernel reference relocation symbol
Symbol resolution may be skewed if relocation was used (e.g. kexec).
Check /proc/kallsyms permission or run as root.
如果perf record没有在sudo或root下运行很有可能会爆如上错误,解决方案:
sudo sh -c " echo 0 > /proc/sys/kernel/kptr_restrict"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号