NEMU PA2 - 简单复杂的机器: 冯诺依曼计算机系统

请注意你的学术诚信!
本博客只提供个人思路的参考和一些想法, 并非能够抄袭的答案
1.本人水平有限,实现的PA可能有可怕的bug
2.本人思路可能有误,需要各位自行判别
YEMU: 一个简单的CPU模拟器
typedef union {
struct { uint8_t rs : 2, rt : 2, op : 4; } rtype;
struct { uint8_t addr : 4 , op : 4; } mtype;
uint8_t inst;
} inst_t;
#define DECODE_R(inst) uint8_t rt = (inst).rtype.rt, rs = (inst).rtype.rs
#define DECODE_M(inst) uint8_t addr = (inst).mtype.addr
uint8_t pc = 0; // PC, C语言中没有4位的数据类型, 我们采用8位类型来表示
uint8_t R[NREG] = {}; // 寄存器
uint8_t M[NMEM] = { // 内存, 其中包含一个计算z = x + y的程序
0b11100110, // load 6# | R[0] <- M[y]
0b00000100, // mov r1, r0 | R[1] <- R[0]
0b11100101, // load 5# | R[0] <- M[x]
0b00010001, // add r0, r1 | R[0] <- R[0] + R[1]
0b11110111, // store 7# | M[z] <- R[0]
0b00010000, // x = 16
0b00100001, // y = 33
0b00000000, // z = 0
};
int halt = 0; // 结束标志
// 执行一条指令
void exec_once() {
inst_t this;
this.inst = M[pc]; // 取指
switch (this.rtype.op) {
// 操作码译码 操作数译码 执行
case 0b0000: { DECODE_R(this); R[rt] = R[rs]; break; }
case 0b0001: { DECODE_R(this); R[rt] += R[rs]; break; }
case 0b1110: { DECODE_M(this); R[0] = M[addr]; break; }
case 0b1111: { DECODE_M(this); M[addr] = R[0]; break; }
default:
printf("Invalid instruction with opcode = %x, halting...\n", this.rtype.op);
halt = 1;
break;
}
pc ++; // 更新PC
}
int main() {
while (1) {
exec_once();
if (halt) break;
}
printf("The result of 16 + 33 is %d\n", M[7]);
return 0;
}
可以看到其rtype 和 mtype 这两个struct里面的变量是反着放的!这个很违反自觉
但是实际执行起来,确是对的...
op成功匹配到了二进制最前面的4位,rs成功匹配到了二进制最后面的2位,好像二进制是反着放进去一样...
RISC-V32指令集


在RISC-V架构中,RISC-V32指令集(32位RISC-V指令集)定义了以下几种指令格式:
-
R型指令格式(R-type):用于表示寄存器-寄存器操作的指令。这些指令操作两个寄存器,通常用于算术和逻辑操作。
- 例如:ADD、SUB、AND、OR、XOR等。
-
I型指令格式(I-type):用于表示立即数与寄存器之间的操作的指令。这些指令允许一个立即数与一个寄存器进行操作。
- 例如:ADDI(加立即数)、SLTI(设置小于立即数)、LW(加载字)、SW(存储字)等。
-
S型指令格式(S-type):用于表示立即数与寄存器之间的存储操作的指令。这些指令允许一个立即数存储到内存中。
- 例如:SB(存储字节)、SH(存储半字)、SW(存储字)、FENCE(内存屏障)等。
-
B型指令格式(B-type):用于表示分支操作的指令。这些指令用于根据条件测试执行相对于当前指令位置的跳转。
- 例如:BEQ(等于分支)、BNE(不等于分支)、BLT(小于分支)、BGE(大于等于分支)等。
-
U型指令格式(U-type):用于表示无条件操作的指令。这些指令主要用于加载立即数到寄存器中。
- 例如:LUI(加载上半字立即数)、AUIPC(添加上半字立即数到PC)等。
-
J型指令格式(J-type):用于表示跳转操作的指令。这些指令用于无条件跳转或跳转并链接(JAL)。
- 例如:JAL(跳转并链接)、JALR(间接跳转并链接)、(J跳转)等。
RISC-V base instruction formats about R-type

RISC-V指令集中的R-type指令格式是用于表示寄存器-寄存器操作的指令格式。在这个格式中,指令的操作码(opcode)用于指示指令的类型,而操作数字段则包含源操作数寄存器(rs1和rs2)和目标寄存器(rd)。此外,funct3和funct7字段用于进一步细分指令类型。
其中,各字段的含义如下:
- funct7:7位功能码字段,用于细分不同的R-type指令,例如乘法指令和移位指令等。
- rs2和rs1:源操作数寄存器字段,用于存储参与操作的源操作数的寄存器编号。
- funct3:3位功能码字段,用于进一步区分指令的类型,例如不同类型的算术运算、逻辑运算等。
- rd:目标寄存器字段,用于存储操作的结果的目标寄存器编号。
- opcode:操作码字段,用于指示指令的类型。

资源推荐
更新:上述资源RISC-V 手册有指令格式错误等问题,推荐如下新资源

RTFSC(2)
exec_once()函数函数覆盖了指令周期的所有阶段: 取指, 译码, 执行, 更新PC
//nemu/src/isa/riscv32/inst.c
/*
* 可以看到每一次我们都是从内存中取出32位(uint32_t)作为指令,然后也让我们的pc+4,因为我们的内存定义为uint8_t pmem[].
*/
int isa_exec_once(Decode *s) {
s->isa.inst.val = inst_fetch(&s->snpc, 4);
return decode_exec(s);
}
/**********************************************/
//nemu/include/cpu/ifetch.h
static inline uint32_t inst_fetch(vaddr_t *pc, int len) {
uint32_t inst = vaddr_ifetch(*pc, len);
/*每一次取完指后是*snpc+=len!!!,因为传过来的参数为&s->snpc*/
(*pc) += len;
return inst;
}
//nemu/src/memory/vaddr.c
word_t vaddr_ifetch(vaddr_t addr, int len) {
return paddr_read(addr, len);
}
/**********************************************/
//nemu/include/cpu/decode.h
typedef struct Decode {
vaddr_t pc;
vaddr_t snpc; // static next pc
vaddr_t dnpc; // dynamic next pc
ISADecodeInfo isa; //还有一些信息是ISA相关的, NEMU用一个结构类型ISADecodeInfo来对这些信息进行抽象, 具体的定义在nemu/src/isa/$ISA/include/isa-def.h中.
IFDEF(CONFIG_ITRACE, char logbuf[128]);
} Decode;
//nemu/include/isa.h
typedef concat(__GUEST_ISA__, _ISADecodeInfo) ISADecodeInfo;
//nemu/src/isa/riscv32/include/isa-def.h
// decode
typedef struct {
union {
uint32_t val;
} inst;
} MUXDEF(CONFIG_RV64, riscv64_ISADecodeInfo, riscv32_ISADecodeInfo);
/**********************************************/
/*更新pc操作*/
//nemu/src/cpu/cpu-exec.c
static void exec_once(Decode *s, vaddr_t pc) {
s->pc = pc;
s->snpc = pc;
isa_exec_once(s);
/*
* 将s->dnpc赋值给cpu.pc
* snpc是下一条静态指令, 而dnpc是下一条动态指令.
* 对于顺序执行的指令, 它们的snpc和dnpc是一样的; 但对于跳转指令, snpc和dnpc就会有所不同,
* dnpc应该指向跳转目标的指令.
* 显然, 我们应该使用s->dnpc来更新PC, 并且在指令执行的过程中正确地维护s->dnpc.
*/
cpu.pc = s->dnpc;
...
}

对于在GCC编译NEMU时输出预处理结果我倒是不知道,但是我知道可以通过
gcc -E your_source_file.c -o preprocessed_output.i的方式将预处理结果放到preprocessed_output.i中
运行第一个C程序




如何理解riscv32指令格式?
-
为何指令格式有R,I,S,B,U,J?
因为即使是同一个指令类型,也可能有不同的操作对象;
如有两条指令,他们的指令类型都是add(加法),但是一个是
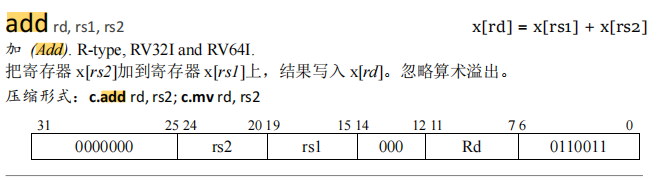
另一个是

可以注意看到他们的opcode是相同的,但是指令的格式却不同,因为他们一个是寄存器-寄存器操作(R类型)
另一个是寄存器-立即数操作(I类型) -
如果理解其中的offer[] 和 imm[]?

offset[20|10:1|11|19:12]表示立即数offset各个下标的位数在哪里
如:offset[20]在指令的第31位
offset[10:1]在指令的第21-30位
offset[11]在指令的第20位
offset[19:12]在指令的第12-19位
offset[0]没有出现在指令中,则默认为0
所以我们想要从这个指令中提取出offset来,我们要得到指令各个相应的位,拼出offset[20]offset[19:12]offset[11]offset[10:1]offset[0] == offset来
像这个imm也是同理的
我受到了背刺!!!
jalr指令如下:

但是在最新的英文The RISC-V Instruction Set Manual Volume I: Unprivileged ISA
Chapter 24
RV32/64G Instruction Set Listings
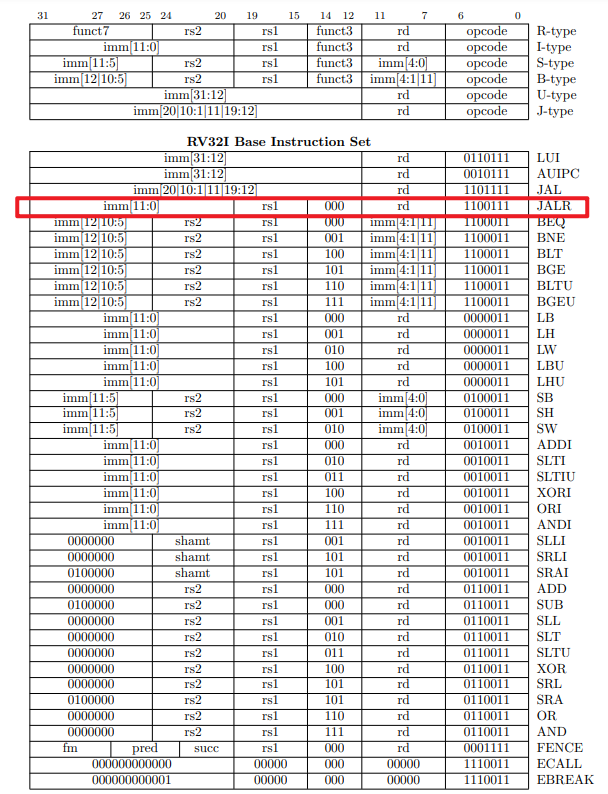
可以看到字段funct3不一样了!
运行更多的程序

srai指令

这个指令很特殊,shamt是个立即数,但是他的指令格式又和R型指令格式很像,所以我不得不重新创建了一个指令格式类型名为I_shamt
同时注意他这里是算数右移,所以我要强制将其转换为int32_t,由于不知道实现的对不对,先记录下。
还需要注意的是。对于RV32I,仅当shamt[5]=0 时,指令才是有效的。
/*
* srai rd, rs1, shamt x[rd] = (x[rs1] ≫𝑠 shamt)
* 立即数算术右移(Shift Right Arithmetic Immediate)
* 把寄存器 x[rs1]右移 shamt 位,空位用 x[rs1]的最高位填充,结果写入 x[rd]。
* 对于 RV32I,仅当 shamt[5]=0 时指令有效。
*/
INSTPAT("0100000 ????? ????? 101 ????? 00100 11", srai , I_shamt, if (BITS(s->isa.inst.val, 24, 24) == 0) R(rd) = (((int32_t)src1) >> imm));
我又又被手册背刺了!!!


这三条指令,最高字段只有6位,但是他这个手册上有7位!!!这个手册还是讲义给的!!!
我是去找到了原作者翻译的pdf才发现了这个问题

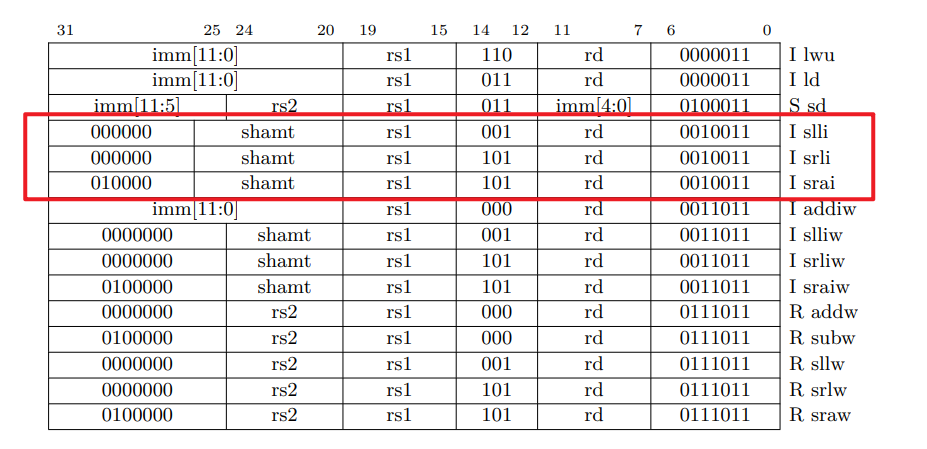
我真是醉了...
程序, 运行时环境与AM
运行时环境


//nemu/src/isa/riscv32/inst.c
INSTPAT("0000000 00001 00000 000 00000 11100 11", ebreak , N, NEMUTRAP(s->pc, R(10))); // R(10) is $a0
//nemu/include/cpu/cpu.h
#ifndef __CPU_CPU_H__
#define __CPU_CPU_H__
#include <common.h>
void cpu_exec(uint64_t n);
void set_nemu_state(int state, vaddr_t pc, int halt_ret);
void invalid_inst(vaddr_t thispc);
#define NEMUTRAP(thispc, code) set_nemu_state(NEMU_END, thispc, code)
#define INV(thispc) invalid_inst(thispc)
#endif
可以看到,当我们在NEMU内存中的程序执行到了ebreak指令(也就是nemu_trap)后,就会执行宏NEMUTRAP,调用set_nemu_state,将NEMU_END,$pc,寄存器$0的状态保存到nemu的状态中
这个状态定义为:
//nemu/include/utils.h
typedef struct {
int state;
vaddr_t halt_pc;
uint32_t halt_ret;
} NEMUState;
并通过nemu的状态来给出提示
//nemu/src/cpu/cpu-exec.c cpu_exec:118
switch (nemu_state.state) {
case NEMU_RUNNING: nemu_state.state = NEMU_STOP; break;
case NEMU_END: case NEMU_ABORT:
Log("nemu: %s at pc = " FMT_WORD,
(nemu_state.state == NEMU_ABORT ? ANSI_FMT("ABORT", ANSI_FG_RED) :
(nemu_state.halt_ret == 0 ? ANSI_FMT("HIT GOOD TRAP", ANSI_FG_GREEN) :
ANSI_FMT("HIT BAD TRAP", ANSI_FG_RED))),
nemu_state.halt_pc);
// fall through
case NEMU_QUIT: statistic();
}
RTFSC(3)

我的做法是:
// abstract-machine/scripts/platform/nemu.mk
//加上-b选项
NEMUFLAGS += -b -l $(shell dirname $(IMAGE).elf)/nemu-log.txt
不知道如何下手咋办?
那就从我们熟悉的开始
在上一个任务我们要不断地填充指令,然后完成am-kernels/tests/cpu-tests/tests/*.c的测试任务
我们要测试就要在am-kernels/tests/cpu-tests键入命令make ARCH=$ISA-nemu ALL=dummy run
RTFSC,这条命令是如何打开我们实现的NEMU,并且真的运行了test/dummy.c
来看看其下的am-kernels/tests/cpu-tests/Makefile
有点蒙,看不懂?还记得讲义交给我们的方法吗?

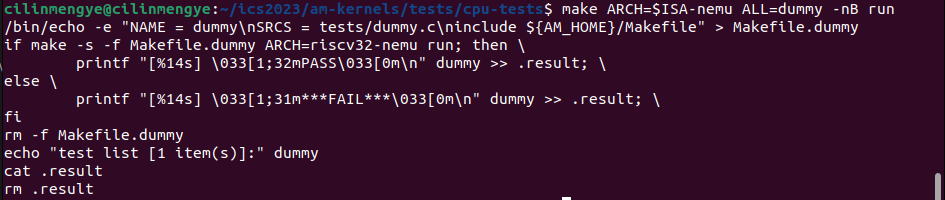
重点关注他的输出顺序和我们源代码的组织顺序,我们会发现,原来当我们键入make run
Makefile中会查看run所需的依赖文件,然后在Makefile中不断寻找
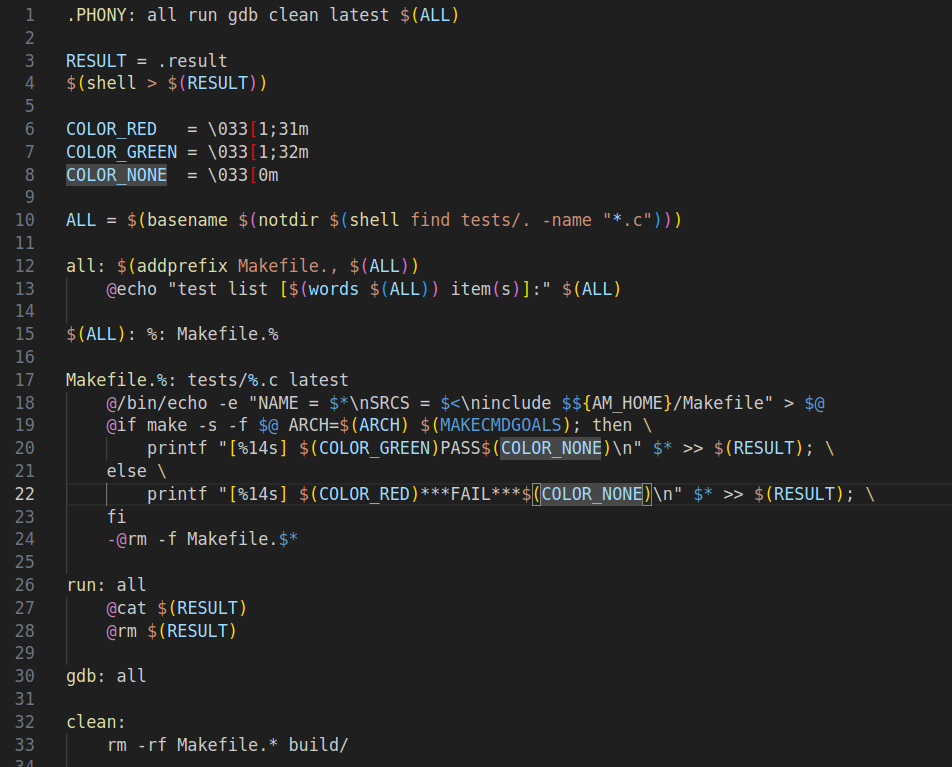
这里run:all,即run依赖的文件(标签)是all
然后去实现all,又发现all依赖着Makefile.xxx(xxx是我们传入.c文件名,有没传入的话就默认是/test/*.c)
然后又发现Makefile.xxx依赖着test/xxx.c和last
...
直到全部的依赖文件都准备好了
还可以发现,其实我们真正执行的make run 还包括abstract-machine/Makefile下的run
/bin/echo -e "NAME = dummy\nSRCS = tests/dummy.c\ninclude ${AM_HOME}/Makefile" > Makefile.dummy
这是一个bash命令,我们相当于在abstract-machine/Makefile中多定义了NAME = dummy,SRCS = tests/dummy.c,然后开始执行abstract-machine/Makefile
这个时候我们再看abstract-machine/Makefile,就会发现原来找不到NAME和SRCS这两个变量 是通过这种方式'传'到abstract-machine/Makefile中的!
那么abstract-machine/Makefile中的run呢?
//abstract-machine/Makefile
-include $(AM_HOME)/scripts/$(ARCH).mk
//abstract-machine/scripts/riscv32-nemu.mk
include $(AM_HOME)/scripts/isa/riscv.mk
include $(AM_HOME)/scripts/platform/nemu.mk
在abstract-machine/scripts/platform/nemu.mk中
//abstract-machine/scripts/platform/nemu.mk
run: image
$(MAKE) -C $(NEMU_HOME) ISA=$(ISA) run ARGS="$(NEMUFLAGS)" IMG=$(IMAGE).bin
可以看到这里的$(NEMU_HOME),-C 选项后面跟着一个目录路径,表示在执行 make 命令之前,先切换到指定的目录路径下,然后再执行 make 命令。
来看看NEMU中的Makefile
//nemu/scripts/native.mk
NEMU_EXEC := $(BINARY) $(ARGS) $(IMG)
run: run-env
$(call git_commit, "run NEMU")
$(NEMU_EXEC)
我们再来看看NEMU中的源码
is_batch_mode? 批处理模式?
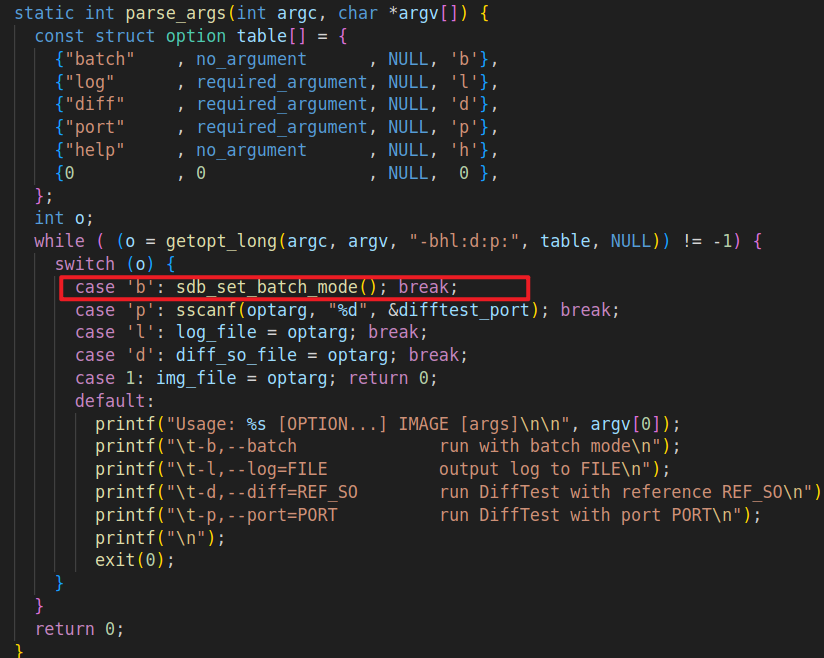
所以我们只要在运行NEMU时传入参数b即可
小小总结
所以我们能够看到abstract-machine还真就全心全意在做一件事情:提供运行时的环境

目前为止,我看到了abstract-machine能够将我们再linux中写的c代码转为我们NEMU中以riscv32为架构的可执行代码,并调用我们再NEMU中实现的TRM(图灵机)(我们再NEMU中实现了简易调试器sdb和图灵机TRM),完成了在NEMU上运行代码!
Makefile推荐入门资源
实现常用的库函数


记录下,我在实现的时候全部都加了类似
assert(s != NULL)
基础设施(2)
bug诊断的利器 - 踪迹
指令执行的踪迹 - itrace
// nemu/src/cpu/cpu-exec.c
static void exec_once(Decode *s, vaddr_t pc) {
s->pc = pc;
s->snpc = pc;
isa_exec_once(s);
cpu.pc = s->dnpc;
#ifdef CONFIG_ITRACE
char *p = s->logbuf;
/*
* p += snprintf(p, sizeof(s->logbuf), "0x%08x:", s->pc);
* 以十六进制的形式打印出当前pc的值
* sizeof(s->logbuf) 写入的最大字符数
* such as : 0x80000000:
*/
p += snprintf(p, sizeof(s->logbuf), FMT_WORD ":", s->pc);
/*
* ilen always = 4
*/
int ilen = s->snpc - s->pc;
int i;
uint8_t *inst = (uint8_t *)&s->isa.inst.val;
/*
* 每次以十六进制的形式打印出8bit出来, 因为 uint8_t *inst
* all time of print is ilen = 4
* such as: 00 00 04 13
*/
for (i = ilen - 1; i >= 0; i --) {
p += snprintf(p, 4, " %02x", inst[i]);
}
int ilen_max = MUXDEF(CONFIG_ISA_x86, 8, 4);
int space_len = ilen_max - ilen;
if (space_len < 0) space_len = 0;
space_len = space_len * 3 + 1;
memset(p, ' ', space_len);
p += space_len;
#ifndef CONFIG_ISA_loongarch32r
void disassemble(char *str, int size, uint64_t pc, uint8_t *code, int nbyte);
disassemble(p, s->logbuf + sizeof(s->logbuf) - p,
MUXDEF(CONFIG_ISA_x86, s->snpc, s->pc), (uint8_t *)&s->isa.inst.val, ilen);
#else
p[0] = '\0'; // the upstream llvm does not support loongarch32r
#endif
#endif
}
/**********************************************/
//nemu/src/utils/disasm.cc
/*
* disassemble(p, s->logbuf + sizeof(s->logbuf) - p,
MUXDEF(CONFIG_ISA_x86, s->snpc, s->pc), (uint8_t *)&s->isa.inst.val, ilen);
* from nemu/src/cpu/cpu-exec.c
* char *str is logbuf which string buf writed to build/nemu-log.txt
* int size is the remaining memory of logbuf
* uint64_t pc is the pc当前指向的地址(have not +4)
* uint8_t *code is 指向指令的指针
* int nbyte is 指令的字节长度
*/
extern "C" void disassemble(char *str, int size, uint64_t pc, uint8_t *code, int nbyte) {
MCInst inst;
llvm::ArrayRef<uint8_t> arr(code, nbyte);
uint64_t dummy_size = 0;
gDisassembler->getInstruction(inst, dummy_size, arr, pc, llvm::nulls());
std::string s;
raw_string_ostream os(s);
gIP->printInst(&inst, pc, "", *gSTI, os);
int skip = s.find_first_not_of('\t');
const char *p = s.c_str() + skip;
assert((int)s.length() - skip < size);
strcpy(str, p);
}
我们能够看到,在exec_once函数中,每次执行完一条指令,我们就会将这个条指令的地址,指令本身,以及通过disassemble函数得到的指令反汇编保存到s->logbuf中
那么s->logbuf是如何写到build/nemu-log中的呢?
// First: 使用Makefile在编译链接的时候传人参数-l(跟我们上面传入参数使得开启批处理模式相同)
// Second: 解析-l的参数
//nemu/src/monitor/monitor.c
static int parse_args(int argc, char *argv[]) {
const struct option table[] = {
{"batch" , no_argument , NULL, 'b'},
{"log" , required_argument, NULL, 'l'},
{"diff" , required_argument, NULL, 'd'},
{"port" , required_argument, NULL, 'p'},
{"help" , no_argument , NULL, 'h'},
{0 , 0 , NULL, 0 },
};
int o;
while ( (o = getopt_long(argc, argv, "-bhl:d:p:", table, NULL)) != -1) {
switch (o) {
case 'b': sdb_set_batch_mode(); break;
case 'p': sscanf(optarg, "%d", &difftest_port); break;
case 'l': log_file = optarg; break;
case 'd': diff_so_file = optarg; break;
case 1: img_file = optarg; return 0;
default:
printf("Usage: %s [OPTION...] IMAGE [args]\n\n", argv[0]);
printf("\t-b,--batch run with batch mode\n");
printf("\t-l,--log=FILE output log to FILE\n");
printf("\t-d,--diff=REF_SO run DiffTest with reference REF_SO\n");
printf("\t-p,--port=PORT run DiffTest with port PORT\n");
printf("\n");
exit(0);
}
}
return 0;
}
//third:
//nemu/src/cpu/cpu-exec.c
//在execut中执行trace_and_difftest(&s, cpu.pc);
static void execute(uint64_t n) {
Decode s;
for (;n > 0; n --) {
exec_once(&s, cpu.pc);
g_nr_guest_inst ++;
trace_and_difftest(&s, cpu.pc);
if (nemu_state.state != NEMU_RUNNING) break;
IFDEF(CONFIG_DEVICE, device_update());
}
}
static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {
#ifdef CONFIG_ITRACE_COND
if (ITRACE_COND) { log_write("%s\n", _this->logbuf); }
#endif
if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); }
IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
IFDEF(CONFIG_WATCHPOINT, checkWatchPoint());
}
在trace_and_difftest函数中
ITRACE_COND这个宏是通过我们使用gcc -D ITRACE_COND=true传过来的,源代码中并未定义
-D 选项是 GCC 编译器的一个选项,用于定义预处理器宏。通过 -D 选项,我们可以在编译时为源代码中的宏指定一个值。
log_write("%s\n", _this->logbuf);这条语句的作用便是将我们s->logbuf中的内容写到我们通过-l传入的文件中了
if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); }这条语句是通过g_print_step判断是否要直接打印到终端中,一个例子是当我们再NEMU中使用命令si的时候可以看到我们将s->logbuf的内容打印到终端了
指令环形缓冲区 - iringbuf
在哪添加代码?
想想当出现访问物理内存越界的时候是哪里在报错?
//nemu/src/memory/paddr.c
static void out_of_bound(paddr_t addr) {
panic("address = " FMT_PADDR " is out of bound of pmem [" FMT_PADDR ", " FMT_PADDR "] at pc = " FMT_WORD,
addr, PMEM_LEFT, PMEM_RIGHT, cpu.pc);
}
//nemu/include/debug.h
#define panic(format, ...) Assert(0, format, ## __VA_ARGS__)
/*
* 看来是通过Assert来实现的报错的,我们不妨看看Assert中的内容
*/
//nemu/include/debug.h
#define Assert(cond, format, ...) \
do { \
if (!(cond)) { \
MUXDEF(CONFIG_TARGET_AM, printf(ANSI_FMT(format, ANSI_FG_RED) "\n", ## __VA_ARGS__), \
(fflush(stdout), fprintf(stderr, ANSI_FMT(format, ANSI_FG_RED) "\n", ## __VA_ARGS__))); \
IFNDEF(CONFIG_TARGET_AM, extern FILE* log_fp; fflush(log_fp)); \
extern void assert_fail_msg(); \
assert_fail_msg(); \
assert(cond); \
} \
} while (0)
// 出现了个assert_fail_msg()函数,有点眼熟
//nemu/src/cpu/cpu-exec.c
void assert_fail_msg() {
isa_reg_display();
statistic();
}
看来我们要在
assert_fail_msg输出它
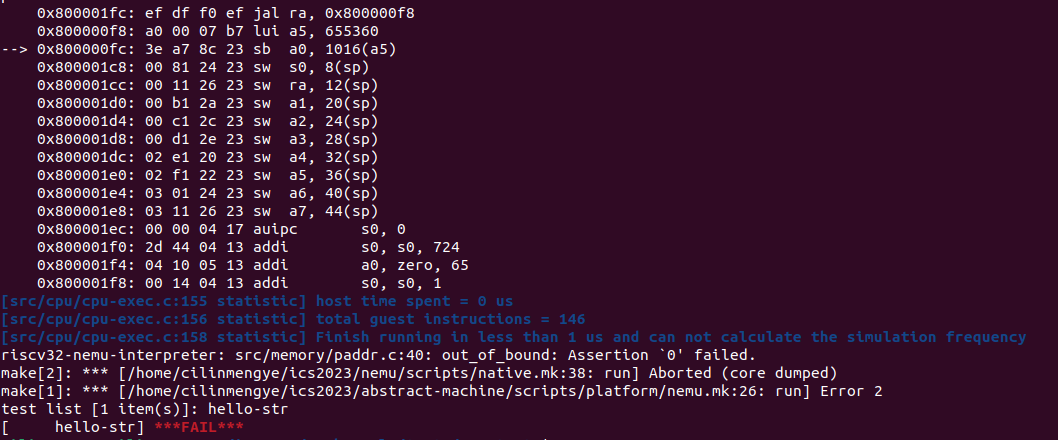
我将开启IRINGTRACE这个选项配置在了nemu/Kconfig上
然后有如下改变:
//nemu/src/cpu/cpu-exec.c
void assert_fail_msg() {
isa_reg_display();
IFDEF(CONFIG_IRINGTRACE, iringbuf_display());
statistic();
}
//nemu/src/isa/riscv32/inst.c
int isa_exec_once(Decode *s) {
s->isa.inst.val = inst_fetch(&s->snpc, 4);
IFDEF(CONFIG_IRINGTRACE, iringbuf_get(*s));
return decode_exec(s);
}
//nemu/src/utils/trace.c 我自己新建立的文件
#include <common.h>
#include <cpu/decode.h>
#define IRINGBUF_SIZE 16
static Decode iringbuf[IRINGBUF_SIZE];
/*The next instruction should be placed at the index in iringbuf*/
static int iringbuf_nextIdx = 0;
void iringbuf_get(Decode s){
iringbuf[iringbuf_nextIdx++] = s;
if (iringbuf_nextIdx >= IRINGBUF_SIZE)
iringbuf_nextIdx = 0;
}
static void iringbuf_translate(Decode *s){
char *p = s->logbuf;
p += snprintf(p, sizeof(s->logbuf), FMT_WORD ":", s->pc);
int ilen = s->snpc - s->pc;
int i;
uint8_t *inst = (uint8_t *)&s->isa.inst.val;
for (i = ilen - 1; i >= 0; i --) {
p += snprintf(p, 4, " %02x", inst[i]);
}
int ilen_max = MUXDEF(CONFIG_ISA_x86, 8, 4);
int space_len = ilen_max - ilen;
if (space_len < 0) space_len = 0;
space_len = space_len * 3 + 1;
memset(p, ' ', space_len);
p += space_len;
#ifndef CONFIG_ISA_loongarch32r
void disassemble(char *str, int size, uint64_t pc, uint8_t *code, int nbyte);
disassemble(p, s->logbuf + sizeof(s->logbuf) - p,
MUXDEF(CONFIG_ISA_x86, s->snpc, s->pc), (uint8_t *)&s->isa.inst.val, ilen);
#else
p[0] = '\0'; // the upstream llvm does not support loongarch32r
#endif
}
/*
* 一般来说, 我们只会关心出错现场前的trace, 在运行一些大程序的时候, 运行前期的trace大多时候没有查看甚至输出的必要.
* 一个很自然的想法就是, 我们能不能在客户程序出错(例如访问物理内存越界)的时候输出最近执行的若干条指令呢?
* 要实现这个功能其实并不困难, 我们只需要维护一个很简单的数据结构 - 环形缓冲区(ring buffer)即可
*/
void iringbuf_display(){
int iringbuf_nowIdx = (iringbuf_nextIdx - 1) < 0 ? 31 : iringbuf_nextIdx - 1;
int i;
for (i = 0; i < IRINGBUF_SIZE; i++){
if (i == iringbuf_nowIdx)
printf("%-4s","-->");
else
printf("%-4s"," ");
iringbuf_translate(&iringbuf[i]);
printf("%s\n",iringbuf[i].logbuf);
}
}
内存访问的踪迹 - mtrace

void mtraceRead_display(paddr_t addr, int len){
printf("read address = " FMT_PADDR " at pc = " FMT_WORD " with byte = %d\n",
addr, cpu.pc, len);
}
void mtraceWrite_display(paddr_t addr, int len, word_t data){
printf("write address = " FMT_PADDR " at pc = " FMT_WORD " with byte = %d and data =" FMT_WORD "\n",
addr, cpu.pc, len, data);
}
函数调用的踪迹 - ftrace

// nemu/src/monitor/monitor.c
static char *elf_file = NULL;
void init_monitor(int argc, char *argv[]) {
...
/* 函数调用的踪迹 - ftrace. */
IFDEF(CONFIG_FTRACE, init_ftrace(elf_file));
...
}
static int parse_args(int argc, char *argv[]) {
const struct option table[] = {
{"batch" , no_argument , NULL, 'b'},
{"log" , required_argument, NULL, 'l'},
{"diff" , required_argument, NULL, 'd'},
{"port" , required_argument, NULL, 'p'},
{"help" , no_argument , NULL, 'h'},
{"elf" , required_argument, NULL, 'e'},
{0 , 0 , NULL, 0 },
};
int o;
while ( (o = getopt_long(argc, argv, "-bhl:d:p:e:", table, NULL)) != -1) {
switch (o) {
case 'b': sdb_set_batch_mode(); break;
case 'p': sscanf(optarg, "%d", &difftest_port); break;
case 'l': log_file = optarg; break;
case 'd': diff_so_file = optarg; break;
case 'e': elf_file = optarg; break;
case 1: img_file = optarg; return 0;
default:
printf("Usage: %s [OPTION...] IMAGE [args]\n\n", argv[0]);
printf("\t-b,--batch run with batch mode\n");
printf("\t-l,--log=FILE output log to FILE\n");
printf("\t-d,--diff=REF_SO run DiffTest with reference REF_SO\n");
printf("\t-p,--port=PORT run DiffTest with port PORT\n");
printf("\t-e,--elf=FILE parse elf from FILE\n");
printf("\n");
exit(0);
}
}
return 0;
}
//abstract-machine/scripts/platform/nemu.mk
NEMUFLAGS += -e $(IMAGE).elf


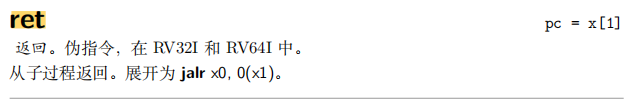

好吧,是真的不会,主要是难以理解

看其他博客说是与尾调用有关
但是我还是不理解,就算这里没有ret f1,但是为何会没有call f0?
AM作为基础设施
在am-kernels/tests/cpu-tests/目录下执行:make ALL=string ARCH=native run,相当于我将真机作为运行时环境
这个一个好处是,当我们以NEMU的riscv作为运行时环境,当出错了,我们不知道是我们的klib中函数实现出错了还是NEMU出错了
但是当我们运行在真机,发现还是出错了,那么就肯定是klib有问题了
前提是我们要在abstract-machine/klib/include/klib.h,将#define __NATIVE_USE_KLIB__的注释解开
这个注释解开后,我们在klib中实现的函数上#if !defined(__ISA_NATIVE__) || defined(__NATIVE_USE_KLIB__)这条语句就为真,那么这将导致在真机上,当调用如strlen函数时,调用的是我们实现的,而不是标准库实现的
Differential Testing
理解指令的执行过程之后, 添加各种指令更多的是工程实现.
工程实现难免会碰到bug, 实现不正确的时候如何快速进行调试, 其实也属于基础设施的范畴
Differential Testing 其实就是拿我们实现的指令,每一次在NEMU中运行得到的状态
与其他实现的正确的模拟器运行得到的状态进行比较
状态包括寄存器状态和pc状态,如果状态相同说明我们的指令实现的没有问题。
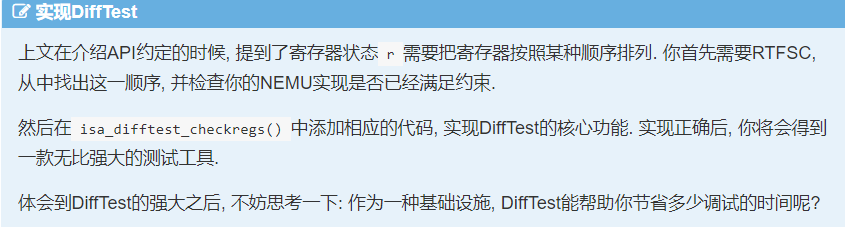
grep -r "difftest_regcpy" ~/ics2023
发现其在nemu/tools/spike-diff/difftest.cc
__EXPORT void difftest_regcpy(void* dut, bool direction) {
if (direction == DIFFTEST_TO_REF) {
s->diff_set_regs(dut);
} else {
s->diff_get_regs(dut);
}
}
void sim_t::diff_get_regs(void* diff_context) {
struct diff_context_t* ctx = (struct diff_context_t*)diff_context;
for (int i = 0; i < NR_GPR; i++) {
ctx->gpr[i] = state->XPR[i];
}
ctx->pc = state->pc;
}
void sim_t::diff_set_regs(void* diff_context) {
struct diff_context_t* ctx = (struct diff_context_t*)diff_context;
for (int i = 0; i < NR_GPR; i++) {
state->XPR.write(i, (sword_t)ctx->gpr[i]);
}
state->pc = ctx->pc;
}
可以知道,不论是获取寄存器状态还是设置寄存器状态都和NEMU中寄存器顺序一样
bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc) {
if (ref_r->pc != cpu.pc) return false;
for (int i = 0; i < NR_GPR; i++) {
if (ref_r->gpr[i] != cpu.gpr[i])
return false;
}
return true;
}
我搞不清这个pc参数传过来干啥的...
输入输出
內存映射I/O
void fun() {
extern unsigned char _end; // _end是什么?
volatile unsigned char *p = &_end;
*p = 0;
while(*p != 0xff);
*p = 0x33;
*p = 0x34;
*p = 0x86;
}
开启O2优化:
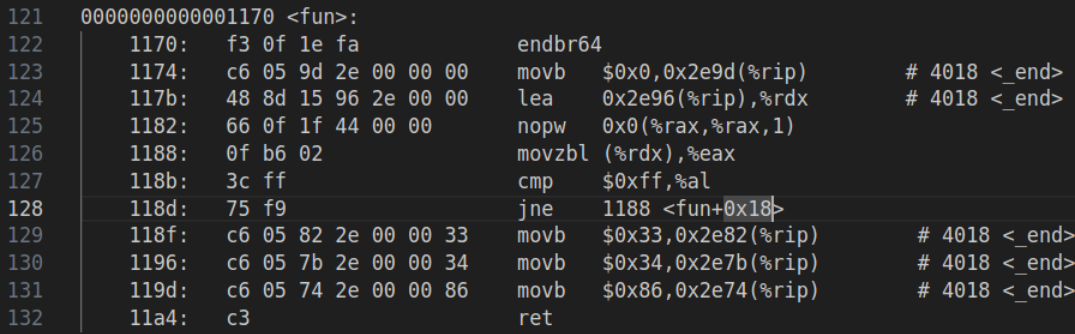
void fun() {
extern unsigned char _end; // _end是什么?
unsigned char *p = &_end;
*p = 0;
while(*p != 0xff);
*p = 0x33;
*p = 0x34;
*p = 0x86;
}
开启O2优化:

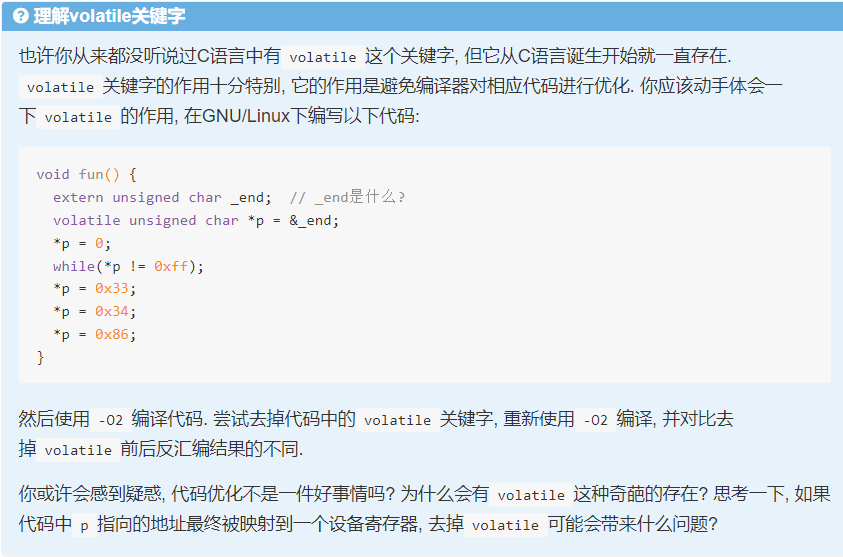
_end是一个标记,用于表示程序的结束位置。在C语言中,它通常是一个指向程序结束位置的符号。这个符号通常由链接器(linker)提供,并在程序的链接过程中确定。
在大多数情况下,_end符号用于确定程序的堆(heap)结束位置。堆是一块动态分配的内存区域,用于存储动态分配的内存对象。程序在运行时会在堆中动态分配内存,而_end符号可以帮助程序确定何时达到了堆的末尾。
如果代码中p指向的地址最终被映射到一个设备寄存器, 去掉volatile可能会带来什么问题?
p就会永远只指向0x0了
NEMU中的输入输出
无论是端口I/O,还是内存映射I/O,本质上都是需要cpu进行读写内存
cpu和内存是我们TRM的事情,我们的NEMU正是模拟了这个过程
所以无论将设备的寄存器(/内存)映射到NEMU中的寄存器(/内存),还是映射后读写内存的操作都是在nemu这个目录下完成的
将输入输出抽象成IOE
设备访问的具体实现是架构相关的, 比如NEMU的VGA显存位于物理地址区间[0xa1000000, 0xa1080000), 但对native的程序来说, 这是一个不可访问的非法区间
自然地, 设备访问这一架构相关的功能, 应该归入AM中. 与TRM不同, 设备访问是为计算机提供输入输出的功能, 因此我们把它们划入一类新的API, 名字叫IOE(I/O Extension).
其实我觉得将设备访问这个归为AM应该主要是因为他是为NEMU提供运行时环境的
同时设备访问也是架构相关的
我们的nemu目录下cpu的一些操作也是架构相关的,如寄存器定义,cpu状态定义等,所以能够看到我们再nemu目录下也有nemu/src/isa

串口
一个我比较好奇的问题:Hello World是如何打印出来的?
这肯定是和串口有关的:
//nemu/src/device/serial.c
static void serial_putc(char ch) {
MUXDEF(CONFIG_TARGET_AM, putch(ch), putc(ch, stderr));
}
static void serial_io_handler(uint32_t offset, int len, bool is_write) {
assert(len == 1);
switch (offset) {
/* We bind the serial port with the host stderr in NEMU. */
case CH_OFFSET:
if (is_write) serial_putc(serial_base[0]);
else panic("do not support read");
break;
default: panic("do not support offset = %d", offset);
}
}
这里有个回调函数serial_io_handler,他的作用是通过变量is_write来判断是否要将一个字符输出到主机的标准错误中
我们到nemu/src/device/io目录下发现有三个c文件:
- 实现端口I/O的
port-io.c,有函数pio_read,pio_write - 实现内存映射I/O的
mmio.c,有函数mmio_read,mmio_write - 上述read,write函数都是调用
mmp.c中的map_read和map_write实现的
其中都会调用invoke_callback(map->callback, offset, len, true/false);,即调用回调函数
也就是说,每次我们使用word_t map_read(paddr_t addr, int len, IOMap *map) { assert(len >= 1 && len <= 8); check_bound(map, addr); paddr_t offset = addr - map->low; invoke_callback(map->callback, offset, len, false); // prepare data to read word_t ret = host_read(map->space + offset, len); return ret; } void map_write(paddr_t addr, int len, word_t data, IOMap *map) { assert(len >= 1 && len <= 8); check_bound(map, addr); paddr_t offset = addr - map->low; host_write(map->space + offset, len, data); invoke_callback(map->callback, offset, len, true); }pio_read,pio_write,mmio_read,mmio_write在端口/内存访问是串口的情况下,都会调用函数serial_io_handler
通过传入参数is_write,来判断这时读串口,写串口。如果是写,那么就输出对应字符到主机的标准错误输出
同时在nemu/src/memory/paddr.c
word_t paddr_read(paddr_t addr, int len) {
if (likely(in_pmem(addr))) return pmem_read(addr, len);
IFDEF(CONFIG_DEVICE, return mmio_read(addr, len));
IFDEF(CONFIG_MTRACE, mtraceRead_display(addr, len));
out_of_bound(addr);
return 0;
}
void paddr_write(paddr_t addr, int len, word_t data) {
if (likely(in_pmem(addr))) { pmem_write(addr, len, data); return; }
IFDEF(CONFIG_DEVICE, mmio_write(addr, len, data); return);
IFDEF(CONFIG_MTRACE, mtraceWrite_display(addr, len, data));
out_of_bound(addr);
}
可以看到会调用mmio_read,mmio_write
nemu/src/memory/vaddr.c中的vaddr_ifetch,vaddr_read,vaddr_write对paddr_read, paddr_write进行了进一步的封装
然后再我们的指令中nemu/src/isa/riscv32/inst.c有宏:
#define Mr vaddr_read
#define Mw vaddr_write
噢!原来我们在进行指令解析的时候,如果发现指令访存,那么我们就调用Mr,Mw进行操作。
如果访问的内存是我们进行端口/内存映射的内存,那么在调用Mr,Mw时就会触发回调函数serial_io_handler的执行,输出字符
理解mainargs

//abstract-machine/am/src/platform/nemu/trm.c
#include <am.h>
#include <nemu.h>
extern char _heap_start;
int main(const char *args);
Area heap = RANGE(&_heap_start, PMEM_END);
#ifndef MAINARGS
#define MAINARGS ""
#endif
static const char mainargs[] = MAINARGS;
void putch(char ch) {
outb(SERIAL_PORT, ch);
}
void halt(int code) {
nemu_trap(code);
// should not reach here
while (1);
}
void _trm_init() {
int ret = main(mainargs);
halt(ret);
}
这个_trm_init()我们经常在反汇编中看到有这个函数,可以看到
mainargs是通过宏MAINARGS定义的
发现这点后,我们能很快在abstract-machine/scripts/platform/nemu.mk,发现如下内容:
/*在GNU Make中,-D选项用于定义宏(macros)。它允许你在运行make时将一个宏传递给makefile文件。*/
CFLAGS += -DMAINARGS=\"$(mainargs)\"
$(mainargs)哪来的?
make ARCH= $ISA-nemu run mainargs=I-love-PA,你执行make命令的时候传入进去的
然后再abstract-machine/Makefile中的编译过程中将参数传入:
### Rule (compile): a single `.c` -> `.o` (gcc)
$(DST_DIR)/%.o: %.c
@mkdir -p $(dir $@) && echo + CC $<
@$(CC) -std=gnu11 $(CFLAGS) -c -o $@ $(realpath $<)
这就是宏MAINARGS的由来
实现printf
一个问题:putch()在哪里?
个人认为是abstract-machine/am/src/platform/nemu/trm.c下的putch
void putch(char ch) {
outb(SERIAL_PORT, ch);
}
其中outb被各个架构实现,比如riscv的在
abstract-machine/am/src/riscv/riscv.h:static inline void outb(uintptr_t addr, uint8_t data) { *(volatile uint8_t *)addr = data; }

其实框架代码已经有个解决案例了:
nemu/include/cpu/decode.h,nemu/src/isa/riscv32/inst.c,其中使用宏INSTPAT_MATCH,INSTPAT将重复的代码提取出来。
所以我们也可以仿照:
#include <am.h>
#include <klib.h>
#include <klib-macros.h>
#include <stdarg.h>
#if !defined(__ISA_NATIVE__) || defined(__NATIVE_USE_KLIB__)
#define PARSE_ARGS(...) assert(fmt != NULL); \
va_list args; \
va_start(args, fmt); \
int cnt = 0; \
char c; \
while (*fmt != '\0'){ \
if (*fmt != '%'){ \
c = *fmt; \
__VA_ARGS__ \
cnt++; \
fmt++; \
continue; \
} \
fmt++; \
switch (*fmt) \
{ \
case 'd': \
int num = va_arg(args, int); \
if (num == 0){ \
c = '0'; \
__VA_ARGS__ \
cnt++; \
break; \
} else if (num < 0){ \
c = '-'; \
__VA_ARGS__ \
cnt++; \
num = -1 * num; \
} \
int div = 1; \
while (num / div >= 10){ \
div *= 10; \
} \
while (div > 0){ \
c = num / div + '0'; \
__VA_ARGS__ \
cnt++; \
num %= div; \
div /= 10; \
} \
break; \
case 's': \
char *s = va_arg(args, char*); \
assert(s != NULL); \
while (*s != '\0'){ \
c = *s \
__VA_ARGS__ \
cnt++; \
s++; \
} \
break; \
default: \
assert(0); \
break; \
} \
fmt++; \
} \
va_end(args);
int printf(const char *fmt, ...) {
//panic("Not implemented");
PARSE_ARGS(; putch(c);)
return cnt;
}
int vsprintf(char *out, const char *fmt, va_list ap) {
panic("Not implemented");
}
int sprintf(char *out, const char *fmt, ...) {
//panic("Not implemented");
assert(out != NULL);
char *p = out;
PARSE_ARGS(; (*p) = c; p++;)
*p = '\0';
return cnt;
}
int snprintf(char *out, size_t n, const char *fmt, ...) {
panic("Not implemented");
}
int vsnprintf(char *out, size_t n, const char *fmt, va_list ap) {
panic("Not implemented");
}
#endif
一个隐患点

没有一点输出到屏幕上...,但是我确实不知道咋解决和原因。但是在cpu-test下使用printf是可以在屏幕上出来的
时钟
实现IOE

一切答案在nemu/src/device/timer.c
当我们访问时钟寄存器映射的端口CONFIG_RTC_PORT/内存CONFIG_RTC_MMIO时,调用回调函数rtc_io_handler
//nemu/src/device/timer.c
static void rtc_io_handler(uint32_t offset, int len, bool is_write) {
assert(offset == 0 || offset == 4);
if (!is_write && offset == 4) {
uint64_t us = get_time();
rtc_port_base[0] = (uint32_t)us;
rtc_port_base[1] = us >> 32;
}
}
其中get_time的作用就是得到(当前时间 - 第一次启动时间),其中rtc_port_base[0],rtc_port_base[1]分别是uint64_t的低32位和高32位
所以我们在abstract-machine/am/src/platform/nemu/ioe/timer.c的__am_timer_uptime实现很简单,只要访问时钟映射的端口CONFIG_RTC_PORT/内存CONFIG_RTC_MMIO即可
abstract-machine/am/src/platform/nemu/include/nemu.h中定义了设备时钟的访问地址,abstract-machine/am/src/riscv/riscv.h提供了访问地址的函数
所以实现如下:
void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) {
uint64_t aft32_t = inl(RTC_ADDR);
uint64_t pre32_t = inl(RTC_ADDR + 4);
uptime->us = (pre32_t << 32) | aft32_t;
}
我这里实现有错误,下面会改正
注意,我们的测试样例
printf("%d-%d-%d %02d:%02d:%02d GMT (", rtc.year, rtc.month, rtc.day, rtc.hour, rtc.minute, rtc.second);,要求我们的printf函数实现了位宽的功能!

am-kernels/tests/am-tests/src/main.c中:
明显是要我们传入参数的节奏,上面其实遇到过这个问题,而且代码中也提示了:make run mainargs=*
看看NEMU跑多快

microbench倒是没啥问题,主要是dhrystone 和 coremark
注意coremark还要求我们的printf实现%x和%u!
同时他们都会爆如下错误:


经过超长时间的调试,
沙了我吧
发现是上面我__am_timer_uptime实现的问题,我们来看看问题的来源
在am-kernels/benchmarks/dhrystone/dry.c:printf("Dhrystone %s %d Marks\n", pass ? "PASS" : "FAIL", 880900 / (int)User_Time * NUMBER_OF_RUNS/ 500000);导致除零错误。
一打印发现原来是我的User_Time为0,而且End_Time,Begin_Time都为0
我一开始还以为是我的指令实现错误了,调了半天...
当然我指令也是有缺陷的,下面再说
//nemu/src/device/timer.c
static void rtc_io_handler(uint32_t offset, int len, bool is_write) {
assert(offset == 0 || offset == 4);
if (!is_write && offset == 4) {
uint64_t us = get_time();
rtc_port_base[0] = (uint32_t)us;
rtc_port_base[1] = us >> 32;
}
}
在这个可以看到
if (!is_write && offset == 4),这个offset表示设备地址的访问偏移量,offset==4表明我们要访问RTC_ADDR + 4(即保存时间高32位的地方)才会更新时间
上面我的实现:
//abstract-machine/am/src/platform/nemu/ioe/timer.c
void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) {
uint64_t aft32_t = inl(RTC_ADDR);
uint64_t pre32_t = inl(RTC_ADDR + 4);
uptime->us = (pre32_t << 32) | aft32_t;
}
我先访问了RTC_ADDR,导致aft32_t得到的还是上次时间低32位值(0),然后可能是运行的比较快,导致高32位也是0,则正好我的uptime->us这个值就为0了
解决方法:
//abstract-machine/am/src/platform/nemu/ioe/timer.c
void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) {
uint64_t pre32_t = inl(RTC_ADDR + 4);
uint64_t aft32_t = inl(RTC_ADDR);
uptime->us = (pre32_t << 32) | aft32_t;
}
实现malloc和free

-
microbench中有个alloc的代码是一个很好的提示 -
heap的宏展开如下:
Area heap = (Area) { .start = (void *)(&_heap_start), .end = (void *)(((uintptr_t)&_pmem_start + (128 * 1024 * 1024))) }
一个我比较好奇的地方,我们NEMU设备相关的内存在哪里?
//nemu/src/device/io/map.c
#define IO_SPACE_MAX (2 * 1024 * 1024)
/*实现了映射的管理, 包括I/O空间的分配及其映射, 还有映射的访问接口.*/
static uint8_t *io_space = NULL;
static uint8_t *p_space = NULL;
uint8_t* new_space(int size) {
uint8_t *p = p_space;
// page aligned;
size = (size + (PAGE_SIZE - 1)) & ~PAGE_MASK;
p_space += size;
assert(p_space - io_space < IO_SPACE_MAX);
return p;
}
void init_map() {
io_space = malloc(IO_SPACE_MAX);
assert(io_space);
p_space = io_space;
}
可以看到设备的内存算是新用malloc创建了一块地方了,每一次有新的内存I/O映射或端口I/O映射都会在这里调用
new_space
一个我比较好奇的地方,我们的heap和我们NEMU的pmem有啥关系?
//abstract-machine/am/include/am.h
// Memory area for [@start, @end)
typedef struct {
void *start, *end;
} Area;
extern Area heap;
//abstract-machine/am/src/platform/nemu/trm.c
Area heap = RANGE(&_heap_start, PMEM_END);
//abstract-machine/klib/include/klib-macros.h
#define RANGE(st, ed) (Area) { .start = (void *)(st), .end = (void *)(ed) }
//abstract-machine/am/src/platform/nemu/include/nemu.h
extern char _pmem_start;
#define PMEM_SIZE (128 * 1024 * 1024)
#define PMEM_END ((uintptr_t)&_pmem_start + PMEM_SIZE)
//./abstract-machine/scripts/platform/nemu.mk: --defsym=_pmem_start=0x80000000 --defsym=_entry_offset=0x0
//./abstract-machine/scripts/linker.ld: _heap_start = ALIGN(0x1000);
PMEM_SIZE和我们NEMU中的pmem大小是一样的,而且_pmem_start也确实是我们NEMU中的pmem的逻辑开始地址。
等等extern char _pmem_start;用char*可能是因为char是一个字节的类型,char* 指针每次++,只会移动一个字节
而且真实的内存又在哪里?目前我不太清楚,算是一个谜团...可能和后面的虚拟地址有关?
设备访问的踪迹 - dtrace
//nemu/src/utils/trace.c
void dtraceRead_display(void *addr, int len, IOMap *map){
printf("dtrace: Drive Name = %s : read address = %p at pc = "FMT_WORD" with byte = %d\n",
map->name, addr, cpu.pc, len);
}
void dtraceWrite_display(void *addr, int len, word_t data, IOMap *map){
printf("dtrace: Drive Name = %s : write address = %p at pc = "FMT_WORD" with byte = %d and data = "FMT_WORD" \n",
map->name, addr, cpu.pc, len, data);
}
//nemu/src/device/io/map.c
word_t map_read(paddr_t addr, int len, IOMap *map) {
assert(len >= 1 && len <= 8);
check_bound(map, addr);
paddr_t offset = addr - map->low;
invoke_callback(map->callback, offset, len, false); // prepare data to read
word_t ret = host_read(map->space + offset, len);
IFDEF(CONFIG_DTRACE, dtraceRead_display(map->space + offset, len, map));
return ret;
}
void map_write(paddr_t addr, int len, word_t data, IOMap *map) {
assert(len >= 1 && len <= 8);
check_bound(map, addr);
paddr_t offset = addr - map->low;
host_write(map->space + offset, len, data);
IFDEF(CONFIG_DTRACE, dtraceWrite_display(map->space + offset, len, data, map));
invoke_callback(map->callback, offset, len, true);
}
//nemu/Kconfig
config DTRACE
bool "Enable dtrace"
default n
效果是每一次通过map_read和map_write访问设备内存,如果定义了宏
CONFIG_DTRACE都会打印出相关信息
键盘
答案在nemu/src/device/keyboard.c中
函数void send_key(uint8_t scancode, bool is_keydown) ,在nemu/src/device/device.c void device_update()中被调用
void device_update()通过事件中断,检查设备更新情况,其通过SDL_Event event;这个变量得到
uint8_t k = event.key.keysym.scancode;
bool is_keydown = (event.key.type == SDL_KEYDOWN);
send_key(k, is_keydown);
uint8_t k = event.key.keysym.scancode;中的scancode定义在usr/include/SDL2/SDL_scancode.h 43行
然后重点是send_key(k, is_keydown)中的处理:
void send_key(uint8_t scancode, bool is_keydown) {
if (nemu_state.state == NEMU_RUNNING && keymap[scancode] != NEMU_KEY_NONE) {
uint32_t am_scancode = keymap[scancode] | (is_keydown ? KEYDOWN_MASK : 0);
key_enqueue(am_scancode);
}
}
注意我们的keymap只有256,而KEYDOWN_MASK为0x8000,通过查看am_scancode二进制的第16位是否为1,可知是否是按下了键盘
根据 key_enqueue的语义我们可以知道这是进栈操作
同时还有key_dequeue(),这是出栈操作
static int key_queue[KEY_QUEUE_LEN] = {}; //存放key的栈
static int key_f = 0, key_r = 0; //key_f是栈顶的下标,key_r是栈尾的下标
可以看出这是个循环栈,和上面要我们实现的指令环形缓冲区 - iringbuf有异曲同工之妙
在我们访问键盘映射的I/O内存时
//nemu/src/device/keyboard.c
static void i8042_data_io_handler(uint32_t offset, int len, bool is_write) {
assert(!is_write);
assert(offset == 0);
i8042_data_port_base[0] = key_dequeue();
}
可以看到其从栈中取出一个码,并保存到数据寄存器中
结合讲义描述的需求AM_INPUT_KEYBRD, AM键盘控制器, 可读出按键信息. keydown为true时表示按下按键, 否则表示释放按键. keycode为按键的断码, 没有按键时, keycode为AM_KEY_NONE.
我们需要读取键盘映射的I/O内存
同时在NEMU中,通过keymap得到的键盘编码为:
//nemu/src/device/keyboard.c
#define NEMU_KEYS(f) \
f(ESCAPE) f(F1) f(F2) f(F3) f(F4) f(F5) f(F6) f(F7) f(F8) f(F9) f(F10) f(F11) f(F12) \
f(GRAVE) f(1) f(2) f(3) f(4) f(5) f(6) f(7) f(8) f(9) f(0) f(MINUS) f(EQUALS) f(BACKSPACE) \
f(TAB) f(Q) f(W) f(E) f(R) f(T) f(Y) f(U) f(I) f(O) f(P) f(LEFTBRACKET) f(RIGHTBRACKET) f(BACKSLASH) \
f(CAPSLOCK) f(A) f(S) f(D) f(F) f(G) f(H) f(J) f(K) f(L) f(SEMICOLON) f(APOSTROPHE) f(RETURN) \
f(LSHIFT) f(Z) f(X) f(C) f(V) f(B) f(N) f(M) f(COMMA) f(PERIOD) f(SLASH) f(RSHIFT) \
f(LCTRL) f(APPLICATION) f(LALT) f(SPACE) f(RALT) f(RCTRL) \
f(UP) f(DOWN) f(LEFT) f(RIGHT) f(INSERT) f(DELETE) f(HOME) f(END) f(PAGEUP) f(PAGEDOWN)
#define NEMU_KEY_NAME(k) NEMU_KEY_ ## k,
在AM中键盘编码为:
//abstract-machine/am/include/amdev.h
#define AM_KEYS(_) \
_(ESCAPE) _(F1) _(F2) _(F3) _(F4) _(F5) _(F6) _(F7) _(F8) _(F9) _(F10) _(F11) _(F12) \
_(GRAVE) _(1) _(2) _(3) _(4) _(5) _(6) _(7) _(8) _(9) _(0) _(MINUS) _(EQUALS) _(BACKSPACE) \
_(TAB) _(Q) _(W) _(E) _(R) _(T) _(Y) _(U) _(I) _(O) _(P) _(LEFTBRACKET) _(RIGHTBRACKET) _(BACKSLASH) \
_(CAPSLOCK) _(A) _(S) _(D) _(F) _(G) _(H) _(J) _(K) _(L) _(SEMICOLON) _(APOSTROPHE) _(RETURN) \
_(LSHIFT) _(Z) _(X) _(C) _(V) _(B) _(N) _(M) _(COMMA) _(PERIOD) _(SLASH) _(RSHIFT) \
_(LCTRL) _(APPLICATION) _(LALT) _(SPACE) _(RALT) _(RCTRL) \
_(UP) _(DOWN) _(LEFT) _(RIGHT) _(INSERT) _(DELETE) _(HOME) _(END) _(PAGEUP) _(PAGEDOWN)
#define AM_KEY_NAMES(key) AM_KEY_##key,
enum {
AM_KEY_NONE = 0,
AM_KEYS(AM_KEY_NAMES)
};
两者是一样的,所以我们啥也不用改动,直接读取就行了
void __am_input_keybrd(AM_INPUT_KEYBRD_T *kbd) {
uint32_t am_scancode = inl(KBD_ADDR);
kbd->keydown = am_scancode & 0x8000;
kbd->keycode = am_scancode & 0xff;
}
如何检测多个键同时被按下?

使用循环缓冲栈,将多个键保存到缓冲栈中
VGA
吐槽

事实上, VGA设备还有两个寄存器,这个还有就很魔性,我还以为又哪里冒出来了啥寄存器,其实这两个寄存器就是AM_GPU_CONFIG,AM_GPU_FBDRAW
AM_GPU_CONFIG,屏幕大小寄存器的硬件(NEMU)功能已经实现, 但软件(AM)还没有去使用它;
其中AM_GPU_FBDRAW, 软件(AM)已经实现了同步屏幕的功能, 但硬件(NEMU)尚未添加相应的支持.
实现
nemu/src/device/vga.c void vga_update_screen()中调用static inline void update_screen()重绘屏幕
在nemu/src/device/device.c void device_update()中调用vga_update_screen()
同时nemu/src/device/vga.c add_mmio_map("vmem", CONFIG_FB_ADDR, vmem, screen_size(), NULL);,回调函数为NULL。
看来是我们再AMabstract-machine/am/src/platform/nemu/ioe/gpu.c __am_gpu_fbdraw中实现写数据,然后NEMU中读写进去的数据,每一次device_update时重绘屏幕
注意,我们这里屏幕的左上角为(0,0),而且enum { AM_GPU_FBDRAW = (11) }; typedef struct { int x, y; void *pixels; int w, h; _Bool sync; } AM_GPU_FBDRAW_T;其含义为:
- 在坐标(x,y)开始,即作为左上角
- 绘制一个h行,w列的矩阵
- 矩阵每一个像素的数据保存在pixels中,而且是按行优先方式存储(即就是我们二维数组在内存中的存放方法)
//abstract-machine/am/src/platform/nemu/ioe/gpu.c
void __am_gpu_config(AM_GPU_CONFIG_T *cfg) {
uint32_t screen = inl(VGACTL_ADDR);
uint32_t screen_width = screen >> 16;
uint32_t screen_height = screen & 0xffff;
uint32_t screen_size = screen_width * screen_height * sizeof(uint32_t);
*cfg = (AM_GPU_CONFIG_T) {
.present = true, .has_accel = false,
.width = screen_width, .height = screen_height,
.vmemsz = screen_size
};
}
void __am_gpu_fbdraw(AM_GPU_FBDRAW_T *ctl) {
int x = ctl->x, y = ctl->y, w = ctl->w, h = ctl->h;
uint32_t *pixels = ctl->pixels;
uint32_t *fb = (uint32_t *)FB_ADDR;
uint32_t screen_width = inl(VGACTL_ADDR) >> 16;
for (int i = y; i < y + h; i++)
for (int j = x; j < x + w; j++)
fb[j + i * screen_width] = pixels[(j - x) + (i - y) * w];
if (ctl->sync) {
outl(SYNC_ADDR, 1);
}
}
声卡
我的声卡加上后马里奥不能跑了...,但是将声卡的实现代码注释掉就行又可以了
而且Bad apple必须将帧数降低才能流畅运行...
但是声音确实是有了,可能是本来要并发的地方用循环,导致效率低下的问题
小星星的声音用我实现的声卡有问题,可能是太短了,播的时候很快,像开了二倍速,但是长点的如bad-apple确还好
AM中的软件支持:
#include <am.h>
#include <nemu.h>
#include <stdio.h>
#define AUDIO_FREQ_ADDR (AUDIO_ADDR + 0x00)
#define AUDIO_CHANNELS_ADDR (AUDIO_ADDR + 0x04)
#define AUDIO_SAMPLES_ADDR (AUDIO_ADDR + 0x08)
#define AUDIO_SBUF_SIZE_ADDR (AUDIO_ADDR + 0x0c)
#define AUDIO_INIT_ADDR (AUDIO_ADDR + 0x10)
#define AUDIO_COUNT_ADDR (AUDIO_ADDR + 0x14)
/*init寄存器用于初始化, 写入后将根据设置好的freq, channels和samples来对SDL的音频子系统进行初始化*/
void __am_audio_init() {
outl(AUDIO_INIT_ADDR, 1);
}
void __am_audio_config(AM_AUDIO_CONFIG_T *cfg) {
cfg->present = true;
cfg->bufsize = inl(AUDIO_SBUF_SIZE_ADDR);
}
void __am_audio_ctrl(AM_AUDIO_CTRL_T *ctrl) {
outl(AUDIO_FREQ_ADDR, ctrl->freq);
outl(AUDIO_CHANNELS_ADDR, ctrl->channels);
outl(AUDIO_SAMPLES_ADDR, ctrl->samples);
__am_audio_init();
}
void __am_audio_status(AM_AUDIO_STATUS_T *stat) {
stat->count = inl(AUDIO_COUNT_ADDR);
}
/*
* AM_AUDIO_PLAY, AM声卡播放寄存器, 可将[buf.start, buf.end)区间的内容作为音频数据写入流缓冲区.
* 若当前流缓冲区的空闲空间少于即将写入的音频数据, 此次写入将会一直等待, 直到有足够的空闲空间将音频数据完全写入流缓冲区才会返回.
*
* 维护流缓冲区. 我们可以把流缓冲区可以看成是一个队列, 程序通过AM_AUDIO_PLAY的抽象往流缓冲区里面写入音频数据,
*/
void __am_audio_play(AM_AUDIO_PLAY_T *ctl) {
int len = ctl->buf.end - ctl->buf.start;
int bufsize = io_read(AM_AUDIO_CONFIG).bufsize;
int remainlen = bufsize - io_read(AM_AUDIO_STATUS).count;
while (remainlen < len){
remainlen = bufsize - io_read(AM_AUDIO_STATUS).count;
}
uintptr_t sbufAddr = (uintptr_t)AUDIO_SBUF_ADDR + io_read(AM_AUDIO_STATUS).count;
for (int i = 0; i < len; i++){
outb(sbufAddr + i, *(uint8_t *)(ctl->buf.start + i));
//outl(AUDIO_COUNT_ADDR, io_read(AM_AUDIO_STATUS).count + 1);
//sbufAddr = (uintptr_t)AUDIO_SBUF_ADDR + io_read(AM_AUDIO_STATUS).count;
}
outl(AUDIO_COUNT_ADDR, io_read(AM_AUDIO_STATUS).count + len);
}
NEMU硬件支持
/***************************************************************************************
* Copyright (c) 2014-2022 Zihao Yu, Nanjing University
*
* NEMU is licensed under Mulan PSL v2.
* You can use this software according to the terms and conditions of the Mulan PSL v2.
* You may obtain a copy of Mulan PSL v2 at:
* http://license.coscl.org.cn/MulanPSL2
*
* THIS SOFTWARE IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND,
* EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO NON-INFRINGEMENT,
* MERCHANTABILITY OR FIT FOR A PARTICULAR PURPOSE.
*
* See the Mulan PSL v2 for more details.
***************************************************************************************/
#include <common.h>
#include <device/map.h>
#include <SDL2/SDL.h>
#define INIT_OFFSET 16
/*
* 声卡不能独立播放音频, 它需要接受来自客户程序的设置和音频数据. 程序要和设备交互
* 我们需要定义一些寄存器和 MMIO空间来让程序访问
*
* freq, channels和samples这三个寄存器可写入相应的初始化参数
* init寄存器用于初始化, 写入后将根据设置好的freq, channels和samples来对SDL的音频子系统进行初始化
* sbuf_size寄存器可读出流缓冲区的大小
* count寄存器可以读出当前流缓冲区已经使用的大小
*/
enum {
reg_freq,
reg_channels,
reg_samples,
reg_sbuf_size,
reg_init,
reg_count,
nr_reg
};
static uint8_t *sbuf = NULL;
static uint32_t *audio_base = NULL;
/*
* 通过SDL_OpenAudio()来初始化音频子系统, 需要提供频率, 格式等参数, 还需要注册一个用于将来填充音频数据的回调函数
* SDL库会定期调用初始化时注册的回调函数, 并提供一个缓冲区, 请求回调函数往缓冲区中写入音频数据
* 回调函数返回后, SDL库就会按照初始化时提供的参数来播放缓冲区中的音频数据
*
* 维护流缓冲区. 我们可以把流缓冲区可以看成是一个队列
* 如果回调函数需要的数据量大于当前流缓冲区中的数据量, 你还需要把SDL提供的缓冲区剩余的部分清零,
*/
static void audio_callback(void *userdata, Uint8 *stream, int len){
SDL_memset(stream, 0, len);
if (audio_base[reg_count] > len){
SDL_memcpy(stream, sbuf, len);
audio_base[reg_count] = audio_base[reg_count] - len;
/*去除掉以及拷贝到SDL缓冲区的内容*/
for (uint32_t i = 0; i < audio_base[reg_count]; i++)
sbuf[i] = sbuf[len + i];
} else {
SDL_memcpy(stream, sbuf, audio_base[reg_count]);
SDL_memset(stream + audio_base[reg_count], 0, len - audio_base[reg_count]);
audio_base[reg_count] = 0;
}
}
static void audio_init(){
SDL_AudioSpec s = {};
s.format = AUDIO_S16SYS; // 假设系统中音频数据的格式总是使用16位有符号数来表示
s.userdata = NULL; // 不使用
s.freq = audio_base[reg_freq]; // 采样频率
s.channels = audio_base[reg_channels]; // 声道数
s.samples = audio_base[reg_samples]; // 缓冲区大小
s.callback = audio_callback; // 回调函数
// if (SDL_InitSubSystem(SDL_INIT_AUDIO) < 0)
// panic("Failed to initialize SDL audio: %s\n", SDL_GetError());
// if (SDL_OpenAudio(&s, NULL) < 0)
// panic("Failed to open audio device: %s\n", SDL_GetError());
SDL_InitSubSystem(SDL_INIT_AUDIO);
SDL_OpenAudio(&s, NULL);
SDL_PauseAudio(0);
}
static void audio_io_handler(uint32_t offset, int len, bool is_write) {
assert(offset == 0 || offset == 4 || offset == 8 || offset == 12 ||
offset == 16 || offset == 20 || offset == 24);
switch (offset)
{
case INIT_OFFSET:
if (is_write && audio_base[4]){
audio_init();
audio_base[reg_init] = 0;
}
break;
default:
break;
}
}
void init_audio() {
uint32_t space_size = sizeof(uint32_t) * nr_reg;
audio_base = (uint32_t *)new_space(space_size);
audio_base[reg_sbuf_size] = CONFIG_SB_SIZE;
audio_base[reg_count] = 0;
audio_base[nr_reg] = 7;
/*
* NEMU的简单声卡在初始化时会分别注册0x200处长度为24个字节的端口,
* 以及0xa0000200处长度为24字节的MMIO空间, 它们都会映射到上述寄存器
*/
#ifdef CONFIG_HAS_PORT_IO
add_pio_map ("audio", CONFIG_AUDIO_CTL_PORT, audio_base, space_size, audio_io_handler);
#else
add_mmio_map("audio", CONFIG_AUDIO_CTL_MMIO, audio_base, space_size, audio_io_handler);
#endif
/*
* 流缓冲区STREAM_BUF是一段MMIO空间, 用于存放来自程序的音频数据, 这些音频数据会在将来写入到SDL库中
*/
sbuf = (uint8_t *)new_space(CONFIG_SB_SIZE);
add_mmio_map("audio-sbuf", CONFIG_SB_ADDR, sbuf, CONFIG_SB_SIZE, NULL);
}
Bad Apple
冯诺依曼计算机系统

-
NEMU 模拟了我们底层硬件:
图灵机(TRM,即模拟了cpu和内存达到不断地取指,译码,执行,更新pc这个过程)
设备(通过一些库如SDL获取了我们真实世界中设备的状态),如我们的键盘,当我们按下一个键时,通过SDL我们的NEMU可以知道这是哪个键,是否是按下的。然后将这个状态保存到我们NEMU模拟的图灵机中 -
AM 为我们编写程序提供了各种运行环境
- 这里的运行环境我认为包括提供了一些方便的库(如string.h,stdio.h,stdlib.h等,他们能够与我们NEMU的内存等进行交互)
- 提供了感知设备状态的接口(如提供了
io_read(AM_INPUT_KEYBRD),通过这个接口我们很容易知道在NEMU中键盘这个设备的状态,可以读取到我们按下了哪个键) - 当然这里不管是库还是接口,都是通过我们访问NEMU这个模拟的图灵机内存实现的。在图灵机中也很给力地当我们访问某一段内存时,就会调用回调函数执行相应操作满足我们的需求
-
ISA
- 我们的AM和程序,最后都会编译链接成$ISA-NEMU架构下的指令
- 因为我们按照$ISA-NEMU手册中,当匹配到了某一指令,那么我们会在NEMU中执行相应改变NEMU状态的操作(这里的状态改变指寄存器,内存,pc等的改变)
具体地, 当我按下一个字母并命中的时候
NEMU中键盘I/O映射内存就保存了我按下的键
程序中通过AM提供的运行时环境接口,要求得到按下的键盘值
AM通过访问NEMU中键盘I/O映射内存,很轻松地从NEMU中得到了我按下的键,并返回给了程序
程序逻辑判断我按下的键,进行分支跳转等操作,改变的程序状态
非改变源码,配置命令记录
sudo -i
apt-get install g++-riscv64-linux-gnu binutils-riscv64-linux-gnu
exit
解开__NATIVE_USE_KLIB__宏

make menuconfig

Differential Testing

注释掉HAS_GUI宏

运行红白机模拟器
设备

报错
*** Expected $ARCH in {loongarch32r-nemu mips32-nemu native riscv32e-nemu riscv32e-npc riscv32-nemu riscv64-nemu spike x86_64-qemu x86-nemu x86-qemu}, Got "-nemu". Stop.
echo $ISA发现为空
vim ~/.bashrc
export ISA=riscv32
source ~/.bashrc
指令隐患
我有两条指令实现的很危险:
//nemu/src/isa/riscv32/inst.c
/*
* div rd, rs1, rs2 x[rd] = x[rs1] ÷s x[rs2]
* 将这些数视为二进制补码
*/
INSTPAT("0000001 ????? ????? 100 ????? 01100 11", div , R, R(rd) = ((int32_t)src1 / (int32_t)src2) );
/*
* rem rd, rs1, rs2 x[rd] = x[rs1] %𝑠 x[rs2]
* x[rs1]除以 x[rs2],向 0 舍入,都视为 2 的补码,余数写入 x[rd]。
*/
INSTPAT("0000001 ????? ????? 110 ????? 01100 11", rem , R, R(rd) = ((int32_t)src1 % (int32_t)src2) );
因为是要将他们看做二进制补码,所以我将其转换为了
int32_t(原来为uint32_t),但是模和除都有可能发现有符号整数溢出的问题
比如:
c uint32_t a = -2147483648; uint32_t b = -1; uint32_t c = (int32_t)a / (int32_t)b;
本来结果是2147483648(231),但是int32_t有一位是符号位,那么能用的只有31位,最大也就(231-1),所以溢出了,这个时候也会报错:Arithmetic Exception,还有可能会有除零问题之类的,现在我不知道咋解决...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号