从零开始的nes模拟器-[1] CPU
前言
Nes的cpu的型号是 2A03,8bit,工作频率 1.7897725 MHz。它有 16bit 地址总线,所以它的寻址范围为 0x0000 - 0xFFFF,即 64KB。CPU 支持三种中断:RESET(复位),NMI(不可屏蔽中断),IRQ(可屏蔽中断)。
2A03 可以理解为 6502 cpu 内置一个 Apu ( 音频处理器 ), 先模拟6502。
CPU的引脚
资料来源: CPU pin out and signal description
真实的6502的引脚是这样的
.--\/--.
AD1 <- |01 40| -- +5V
AD2 <- |02 39| -> OUT0
/RST -> |03 38| -> OUT1
A00 <- |04 37| -> OUT2
A01 <- |05 36| -> /OE1
A02 <- |06 35| -> /OE2
A03 <- |07 34| -> R/W
A04 <- |08 33| <- /NMI
A05 <- |09 32| <- /IRQ
A06 <- |10 31| -> M2
A07 <- |11 30| <- TST (usually GND)
A08 <- |12 29| <- CLK
A09 <- |13 28| <> D0
A10 <- |14 27| <> D1
A11 <- |15 26| <> D2
A12 <- |16 25| <> D3
A13 <- |17 24| <> D4
A14 <- |18 23| <> D5
A15 <- |19 22| <> D6
GND -- |20 21| <> D7
`------'
我们可以简化一下,必要的引脚抽象成下面的样子。
┌─────────────────────┐
│ │
────reset────►│ ├──addr───► 16 bit
│ cpu 6502 │
────nmi──────►│ │
│ │◄─data───► 8 bit
────irq──────►│ │
│ │
────clock────►│ ├──r/w────►
│ │
└─────────────────────┘
简单解释一下这些端口
-
addr : 输出数据,外设(总线) 从 addr读地址。
-
data 和 r/w : 在实际的芯片中,r/w是读写使能端,控制 data 是读数据还是输出数据。但我们这里就不模拟那么麻烦了,读数据写数据各写一个对应的函数就好。
-
clock: 接收时钟脉冲的引脚。
6502的运行频率
- NTSC:1.7897725 Mhz
- PAL:1.773447 Mhz。
很难完全模拟这些时钟频率的,只能是模拟个大概
参考:https://blog.csdn.net/duyanbin68/article/details/83863957
-
IRQ/BRK : 中断由两种情况产生:一是软件通过BRK指令产生,一是硬件通过IRQ引脚产生。
-
reset : 在开机的时候触发,这是ROM被装入,6502跳到RESET向量指向的地址没有寄存器被修改,没有内存被清空,这些都只在开机是发生。
-
nmi: 指不可屏蔽中断,它在VBlank即屏幕刷新时发生,持续时间根据系统(NTSC/PAL)不同而不同。NTSC是每秒60次,而PAL是每秒50次。6502的中断延时是7个时钟周期,也就是说,进入和离开中断都需要7个时钟周期。它产生于PPU的每一帧结束,NMI中断可以由$2000的第7位的1/0控制允许/禁止。
API: 引脚
class cpu_6502{
public:
void reset(); // 复位中断
void irq(); // 可屏蔽中断
void nmi(); // 不可屏蔽中断 (实际上还是可以被ppu屏蔽的)
private:
// 负责从总线读写数据
uint8_t read(uint16_t a);
void write(uint16_t a, uint8_t d);
}
各中断函数 和 read 和 write 的实现详见 cpu的内存布局那里
内部寄存器
参考:CPU registers , NES 模拟器开发教程 07 - CPU
2A03 有 6 个寄存器:A,X,Y,PC,SP,P,除了 PC 为 16bit 以外,其他全都是 8bit
-
A
通常作为累加器 -
X,Y
通常作为循环计数器 -
PC
程序计数器,记录下一条指令地址 -
SP
堆栈寄存器,其值为 0x00 ~ 0xFF,对应着 CPU 总线上的 0x100 ~ 0x1FF -
P
标志寄存器比较麻烦,它实际上只有 6bit,但是我们可以看成 8bitBIT 名称 含义 0 C 进位标志,如果计算结果产生进位,则置 1 1 Z 零标志,如果结算结果为 0,则置 1 2 I 中断去使能标志,置 1 则可屏蔽掉 IRQ 中断 3 D 十进制模式,未使用 4 B BRK,后面解释 5 U 未使用,后面解释 6 V 溢出标志,如果结算结果产生了溢出,则置 1 7 N 负标志,如果计算结果为负,则置 1
刚说过标志寄存器只有 6 bit,这是因为 B 和 U 并不是实际位,只不过某些指令执行后,标志位 push 到 stack 的时候,会附加上这两位以区分中断是由 BRK 触发还是 IRQ 触发,下面是详细解释
| 指令或中断 | U 和 B 的值 | push 之后对 P 的影响 |
|---|---|---|
| PHP 指令 | 11 | 无 |
| BRK 指令 | 11 | I 置 1 |
| IRQ 中断 | 10 | I 置 1 |
| MNI 中断 | 10 | I 置 1 |
API: 寄存器
class cpu_6502{
public:
// 方便 状态寄存器(status register) 取/修改状态的枚举类型
enum FLAGS6502 {
C = (1 << 0), //进位
Z = (1 << 1), //零标记位
I = (1 << 2), //中断使能
D = (1 << 3), // 十进制位 (没啥用处)
B = (1 << 4), // break指令标记
U = (1 << 5), // unused
V = (1 << 6), // 溢出
N = (1 << 7), // 负数
};
// 各种寄存器
uint8_t a = 0x00; // 累加寄存器
uint8_t x = 0x00; // x 寄存器
uint8_t y = 0x00; // y 寄存器
uint8_t stkp = 0x00; // 栈顶指针寄存器
uint16_t pc = 0x0000; // 程序计数器
uint8_t status = 0x00; // 状态寄存器
private:
//一些辅助函数
uint8_t GetFlag(FLAGS6502 f);
void SetFlag(FLAGS6502 f, bool v);
}
指令
指令阵列
下面这个图列举了6502所有指令和寻址模式的组合,事实上6502只有56种官方指令。在该模拟器中,我们也只会模拟56条官方指令。
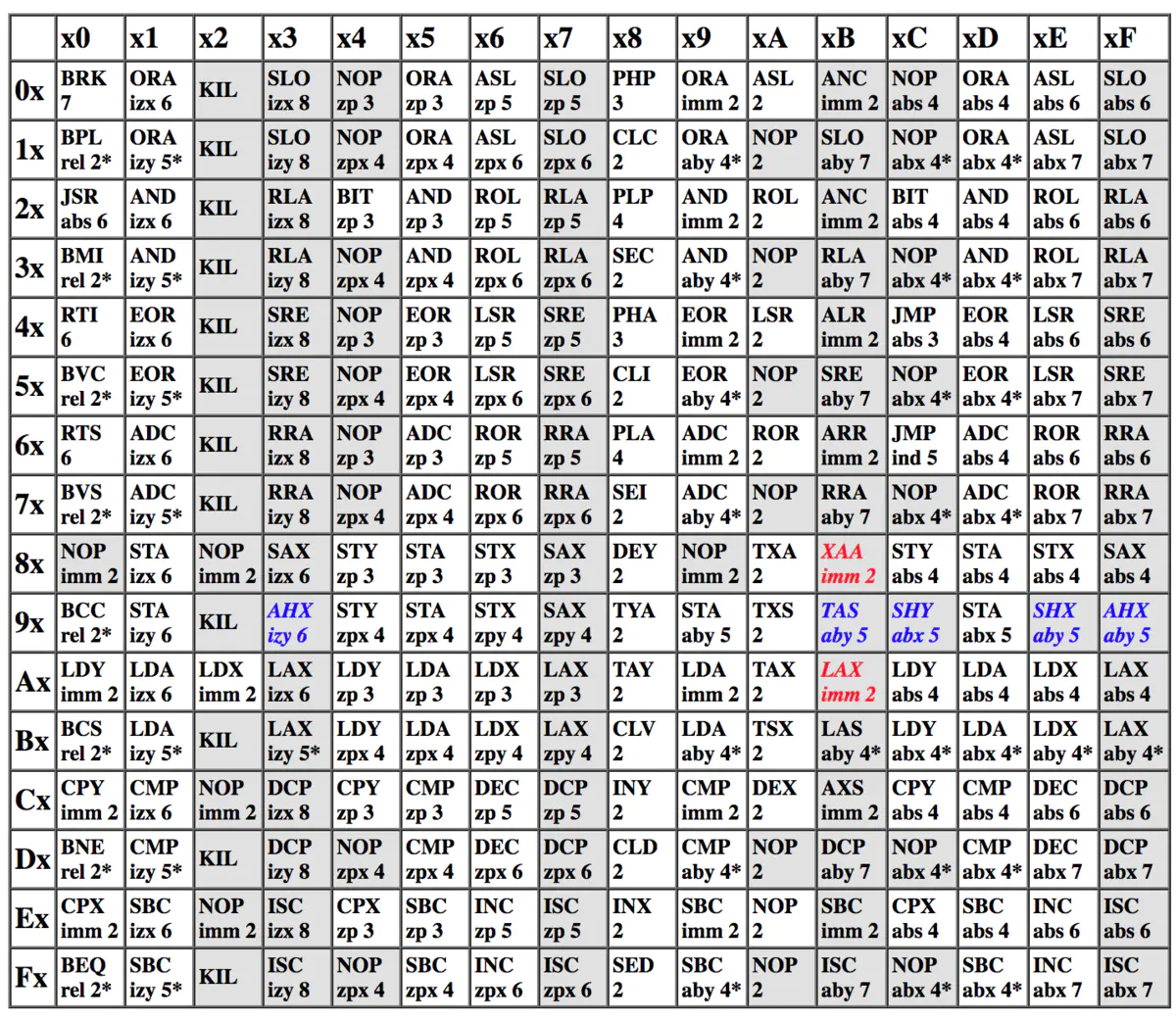
每个方块包含了指令,寻址模式,执行周期,例如:
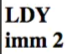
表示:LDY 指令,立即寻址,执行完需要 2 个 CPU 时钟
有些方块执行周期后面有个 * 号,这说明该指令在某些情况下需要额外增加 1 ~ 2 个时钟才能完成,具体等介绍完寻址模式再解释
寻址模式
2A03 支持 13 种寻址模式:
| 寻址模式 | 含义 | 数据长度 | 例子 | 说明 |
|---|---|---|---|---|
| Implicit | 特殊指令的寻址方式 | 0 | CLC | 清除 C 标志 |
| Accumulator | 累加器 A 寻址 | 0 | LSR A | A 右移一位 |
| Immediate | 指定一个字节的数据 | 1 | ADC #$1 | A 增加 1 |
| Zero Page | 指定 Zero Page 地址 | 1 | LDA $00 | 将 0x0000 的值写入 A |
| Zero Page,X | 指定 Zero Page 地址加上 X | 1 | STY $10,X | 将 0x0010 + X 地址上的值写入 Y |
| Zero Page,Y | 指定 Zero Page 地址加上 Y | 1 | LDX $10,Y | 将 0x0010 + X 地址上的值写入 X |
| Relative | 相对寻址 | 1 | BEQ LABEL | 如果 Z 标志置位则跳转到 LABEL 所在地址,跳转范围为当前 PC 的 -128 ~ 127 |
| Absolute | 绝对寻址 | 2 | JMP $1234 | 跳转到地址 0x1234 |
| Absolute,X | 绝对寻址加上 X | 2 | STA $3000,X | 将 0x3000 + X 地址值写入 A |
| Absolute,Y | 绝对寻址加上 Y | 2 | STA $3000,Y | 将 0x3000 + Y 地址值写入 A |
| Indirect | 间接寻址(只有 JMP 使用) | 2 | JMP ($FFFC) | 跳转到 0xFFFC 地址上的值表示的地址处 |
| Indexed Indirect | 变址间接寻址 | 1 | LDA ($40,X) | 首先 X 的值加上 0x40,得到一个地址,再以此地址上的值作为一个新地址,将新地址上的值写入 A |
| Indirect Indexed | 间接变址寻址 | 1 | LDA ($40),Y | 首先获取 0x40 处存储的值,将该值与 Y 相加,得到一个新地址,然后将该地址上的值写入 A |
额外的时钟
前面提到过在指令阵列图中带 * 的需要额外的时钟,有两种情况会额外增加时钟
- 分支指令进行跳转时
分支指令比如 BNE,BEQ 这类指令,如果检测条件为真,这时需要额外增加 1 个时钟 - 跨 Page 访问
新地址和旧地址如果 Page 不一样,即(newAddr & 0xFF00) !== (oldAddr & 0xFF00),则需要额外增加一个时钟。例如0x1234与0x12FF为同一 Page,但是与0x1334为不同 Page
以上两种情况可以同时存在,所以一条指令可能会额外增加 1 ~ 2 个时钟
BUG
NES 硬件存在一些 BUG,这里讲讲间接寻址时的 BUG,因为有些测试 ROM 会测试该行为
间接寻址时,设地址为 x,page 起始地址为 n(即 n = x & 0xFF00),若 x 低 8 位为 0xFF,则寻址地址高位为 n 上的值,低位为 x 上的值,一句话概括,就是地址无法跨 Page
下面举个例子:
Address: 0x0200 0x0201 ... 0x02FF
Value: 0x01 0x02 ... 0x03
针对上述内存,执行 JMP (0x02FF),则会跳转到 0x0103 处
正常情况下,执行 JMP (0x0200),则会跳转到 0x0201 处
API: 辅助变量/函数
一些类内部的辅助变量和辅助函数
class cpu_6502{
private:
//实现指令功能相关的辅助变量
// 表示 ALU 的输入
uint8_t fetched = 0x00;
// 临时全局变量
uint16_t temp = 0x0000;
// 上一次访问的地址
uint16_t addr_abs = 0x0000;
// 遇到分支指令时,表示分支的绝对地址
uint16_t addr_rel = 0x00;
// 指令码
uint8_t opcode;
// 读取数据的位置可以来自两个来源,一个内存地址 或 立即字
// 这个函数根据指令字节的地址模式来决定运行情况,给fetched赋值
uint8_t fetch();
};
API:寻址模式
这些寻址函数在函数内部会组装出数据的目标地址。前面提到遇到跨页的情况会需要多一个时钟周期,如果是跨页,这些函数返回1 , 否则返回0。
private:
//寻址模式
uint8_t IMP(); uint8_t IMM();
uint8_t ZP0(); uint8_t ZPX();
uint8_t ZPY(); uint8_t REL();
uint8_t ABS(); uint8_t ABX();
uint8_t ABY(); uint8_t IND();
uint8_t IZX(); uint8_t IZY();
API:助记符
用函数实现这些助记忆符对应的代码功能。具体的实现就不展示了。
uint8_t ADC(); uint8_t AND(); uint8_t ASL(); uint8_t BCC();
uint8_t BCS(); uint8_t BEQ(); uint8_t BIT(); uint8_t BMI();
uint8_t BNE(); uint8_t BPL(); uint8_t BRK(); uint8_t BVC();
uint8_t BVS(); uint8_t CLC(); uint8_t CLD(); uint8_t CLI();
uint8_t CLV(); uint8_t CMP(); uint8_t CPX(); uint8_t CPY();
uint8_t DEC(); uint8_t DEX(); uint8_t DEY(); uint8_t EOR();
uint8_t INC(); uint8_t INX(); uint8_t INY(); uint8_t JMP();
uint8_t JSR(); uint8_t LDA(); uint8_t LDX(); uint8_t LDY();
uint8_t LSR(); uint8_t NOP(); uint8_t ORA(); uint8_t PHA();
uint8_t PHP(); uint8_t PLA(); uint8_t PLP(); uint8_t ROL();
uint8_t ROR(); uint8_t RTI(); uint8_t RTS(); uint8_t SBC();
uint8_t SEC(); uint8_t SED(); uint8_t SEI(); uint8_t STA();
uint8_t STX(); uint8_t STY(); uint8_t TAX(); uint8_t TAY();
uint8_t TSX(); uint8_t TXA(); uint8_t TXS(); uint8_t TYA();
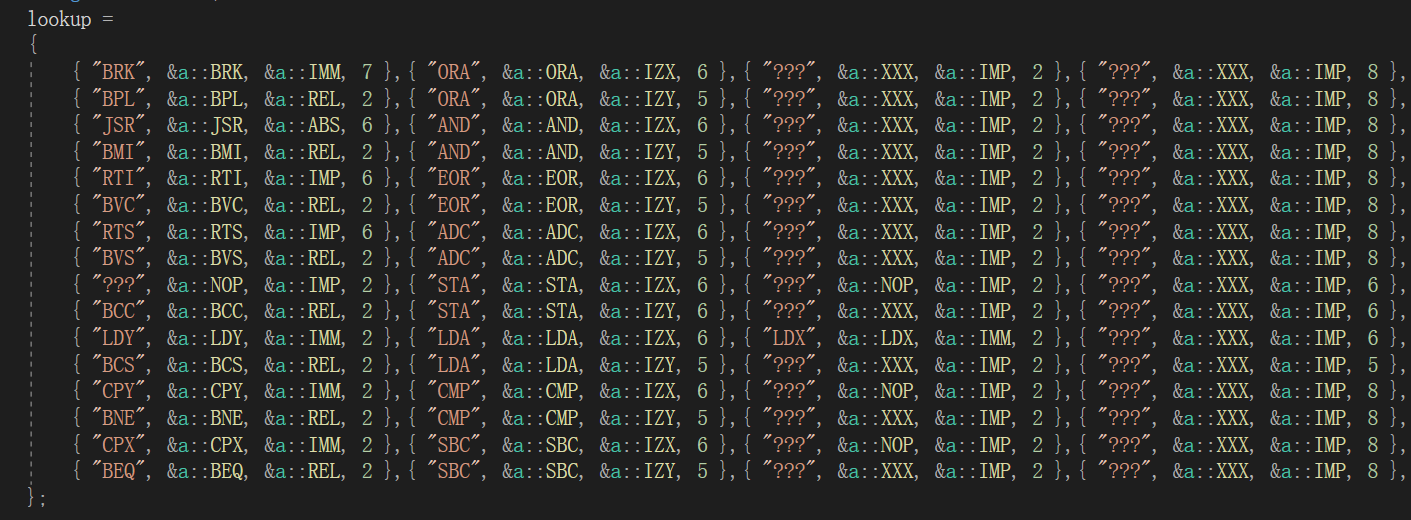
API:指令表
// 这个结构和下面的vector用于 编译 和 存储操作码转换表。
// 6502可以有效地拥有256个不同的指令。
// 每一个都以(它们在表中的)数字顺序存储在一个表中,因此它们可以很容易地查找,而不需要解码。
// 每个表条目包含:
// 名字: 文本表示的指令(用于反汇编)
// 操作码功能:一个函数指针,指向对操作码实现的函数
// 操作码地址模式的实现:一个函数指针, 指向实现这个取址模式的函数
// 循环计数 :一个整数,表示CPU执行指令所需要的基本时钟周期数
struct INSTRUCTION
{
std::string name;
uint8_t(olc6502::*operate)(void) = nullptr;
uint8_t(olc6502::*addrmode)(void) = nullptr;
uint8_t cycles = 0;
};
//查找表
std::vector<INSTRUCTION> lookup;
把上面的信息用一个vector整合起来(代码太长了,不方便贴出来,截一部分图
API: 时序相关
class cpu_6502{
private:
uint8_t cycles = 0; // Counts how many cycles the instruction has remaining 计算指令还剩下多少个周期
uint32_t clock_count = 0; // A global accumulation of the number of clocks 全局时钟数量的累积
public:
/* 返回true,表示当前指令已经完成。这是一个实用函数,可以“一步一步地”执行,而不用手动记录每个周期 */
bool complete();
//组织cpu行为的函数,模拟一个周期
void clock(); // Perform one clock cycle's worth of update
};
这里可以详细看看这两函数来加深一下对cpu运行的理解
// HELPER FUNCTIONS
bool olc6502::complete()
{
return cycles == 0;
}
// Perform one clock cycles worth of emulation
// 执行一个时钟周期的模拟
void olc6502::clock()
{
//每条指令都需要一个可变的时钟周期来执行。
//在我的仿真中,我只关心最终的结果,所以我执行
//一次完成整个计算。在硬件方面,每个时钟周期都会
//执行cpu状态的“微码”样式转换。
//为了保持与连接设备的兼容,重要的是
//模拟也需要“时间”来执行指令,所以我
//通过简单地倒数所需的周期来实现延迟
//指导。当它达到0时,指令完成,并且
//下一个已经准备好执行。
if (cycles == 0)
{
//读取下一个指令字节。这个8位的值用于索引
//翻译表中获取的相关信息
opcode = read(pc);
// Always set the unused status flag bit to 1
SetFlag(U, true);
// Increment program counter, we read the opcode byte
pc++;
// Get Starting number of cycles
cycles = lookup[opcode].cycles;
// 取地址模式
// 地址模式 返回 0/1
uint8_t additional_cycle1 = (this->*lookup[opcode].addrmode)();
// Perform operation 操作码
// 操作码需要更多周期 返回 1 否则 0
uint8_t additional_cycle2 = (this->*lookup[opcode].operate)();
// 编址模式和操作码可能改变了这条指令完成前所需的循环数
cycles += (additional_cycle1 & additional_cycle2);
// Always set the unused status flag bit to 1
SetFlag(U, true);
}
// Decrement the number of cycles remaining for this instruction
// 时钟周期减1
cycles--;
}
cpu的内存布局
ref: NES 模拟器开发教程 01 - NES 系统结构
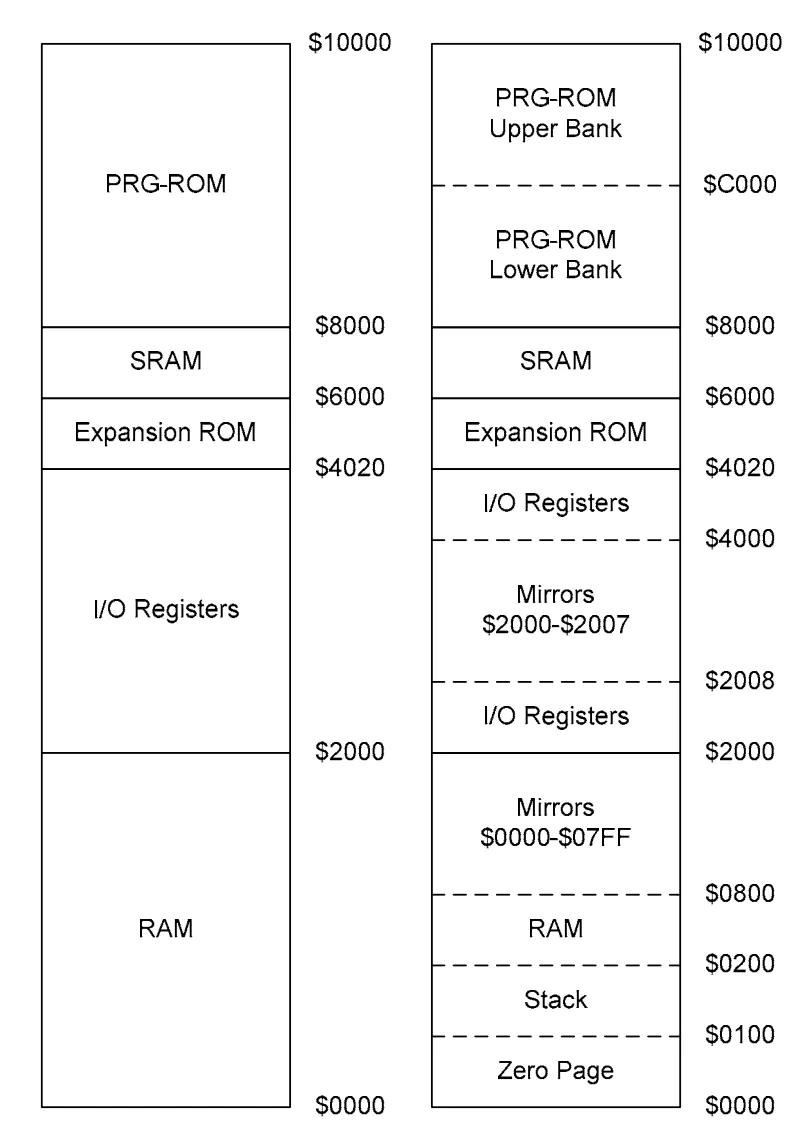
0x0000 - 0x0800 ( RAM )
这是主机中 2KB RAM 的数据,分成了 3 块
- 0x0000 - 0x00FF ( Zero page )
前 256 字节划分为 Zero page,这块内存相比其他区域不同点在于能让 CPU 以更快的速度访问,所以需要频繁读写的数据会优先放入此区域 - 0x0100 - 0x01FF ( Stack )
这一块区域用于栈数据的存储,SP(栈指针) 从 0x1FF 处向下增长 - 0x0200 - 0x07FF ( 剩余 RAM )
这是 2KB 被 Zero page 和 Sack 瓜分后剩余的区域
0x0800 - 0x2000 ( Mirrors )
你可能会感觉到奇怪这个 Mirror 到底是干什么的。实际上它是 0x0000 - 0x07FF 数据的镜像,总共重复 3 次
例如:0x0001, 0x0801, 0x1001, 0x1801 都指向了同样的数据,用程序来解释的话,就是:
address &= 0x07FF
对应到硬件上的话,就是 bit11 - 13 的线不接
至于为什么任天堂要这样设计?我猜可能是考虑到成本原因,2KB RAM 够用了,不需要更大的 RAM,但是地址空间得用完啊,所以才有了 Mirror 效果
0x2000 - 0x401F ( IO Registers )
这里包含了部分外设的数据,包括 PPU,APU,输入设备的寄存器。比如 CPU 如果想读写 VRAM 的数据,就得靠 PPU 寄存器作为中介
0x4020 - 0x5FFF ( Expansion ROM )
Nesdev 的论坛上有篇解释这块区域的帖子,简单来讲,该区域用于一些 Mapper 扩展用,大部分情况用不到
0x6000 - 0x7FFF ( SRAM )
这就是之前说过的带电池的 RAM 了,该区域位于卡带上
0x8000 - 0xFFFF ( Program ROM )
这里对应了程序的数据,一般 CPU 就在这块区域中执行指令,该区域位于卡带上
API: 从总线读写
我这里设计成cpu委托总线类来访问连接在总线上的各个设备的数据
class cpu_6502{
private:
//指向一个总线对象的指针
Bus *bus = nullptr;
uint8_t read(uint16_t a);
void write(uint16_t a, uint8_t d);
public:
// Link this CPU to a communications bus
// 连接cpu 和 总线
void ConnectBus(Bus *n) { bus = n; }
}
///////////////////////////////////////////////////////////////////////////////
// BUS CONNECTIVITY
// 连接总线
// Reads an 8-bit byte from the bus, located at the specified 16-bit address
// 根据16位的地址 , 从总线读1字节
uint8_t olc6502::read(uint16_t a)
{
//正常情况下,read only设置为false。这似乎有些奇怪。一些
//总线上的设备在读取时可能会改变状态
//在正常情况下是故意的。但是反汇编者会
//想要读取一个地址的数据而不改变状态
//总线上的设备
return bus->cpuRead(a, false);
}
// Writes a byte to the bus at the specified address
// 写数据
void olc6502::write(uint16_t a, uint8_t d)
{
bus->cpuWrite(a, d);
}
中断行为
中断向量表位于 0xFFFA ~ 0xFFFF,共 6 字节,分别对应 3 个中断:
- 0xFFFA, 0xFFFB: NMI 中断地址
- 0xFFFC, 0xFFFD: RESET 中断地址
- 0xFFFE, 0xFFFF: IRQ 中断地址
2A03 支持 3 种中断:
- RESET
复位中断,RESET 按钮按下后或者系统刚上电时产生 - NMI
不可屏蔽中断,该中断不能通过 P 的 I 标志屏蔽,所以它一定能触发。比如 PPU 在进入 VBlank 时就会产生 NMI 中断 - IRQ
可屏蔽中断,如果 P 的 I 标志置 1,则可以屏蔽该中断,同时也可以通过 BRK 指令由软件自行触发
产生中断时,CPU 会将 PC 和 P 压栈,之后 CPU 读取中断向量表对应地址,赋给 PC,同时设置相应的标志位。当程序执行 RTI(中断返回) 后,CPU 将 P 和 PC 出栈,恢复 P 和 PC,从中断产生前的地址处继续执行
中断可以理解为一个函数调用,区别在于该函数可以通过其他硬件随时通过中断来调用
API: 中断
展示一下中断的实现
//强制6502回到一个已知的状态。这是CPU内部的硬连线。
//寄存器设置为0x00 , 状态寄存器被清除, 除了未用位。
//触发 RESET 中断,CPU 从 0xFFFA 和 0xFFFB 存储的地址处(2byte)开始取指令运行
void Cpu_6502:: reset()
{
// 设置 pc 到中断程序地址
addr_abs = 0xFFFC;
uint16_t lo = read(addr_abs + 0);
uint16_t hi = read(addr_abs + 1);
pc = (hi << 8) | lo;
// 重置内部寄存器
a = 0;
x = 0;
y = 0;
stkp = 0xFD;
status = 0x00 | U;
// 重置辅助变量
addr_rel = 0x0000;
addr_abs = 0x0000;
fetched = 0x00;
// 中断需要8个周期
cycles = 8;
}
// 中断请求是一个复杂的操作,只有当"disable Interrupt "标志为0时才会发生。irq可以在任何时候发生
// 注意要备份控制流的状态, 以便中断结束后恢复
// 这是由“RTI”指令实现的,也可以由 break 指令触发 。一旦IRQ发生,以类似于复位的方式,从硬编码位置0xFFFE读取可编程地址,随后将其设置为程序计数器。
void Cpu_6502::irq()
{
// 如果中断没有屏蔽
if (GetFlag(I) == 0)
{
// 把pc的值入栈
write(0x0100 + stkp, (pc >> 8) & 0x00FF);
stkp--;
write(0x0100 + stkp, pc & 0x00FF);
stkp--;
// 先设置一些中断标志位,然后将状态寄存器入栈
SetFlag(B, 0);
SetFlag(U, 1);
SetFlag(I, 1);
write(0x0100 + stkp, status);
stkp--;
// 在中断表读中断程序地址
addr_abs = 0xFFFE;
uint16_t lo = read(addr_abs + 0);
uint16_t hi = read(addr_abs + 1);
pc = (hi << 8) | lo;
// IRQs 需要 7 个周期
cycles = 7;
}
}
//不可屏蔽中断不能被忽略。它在与常规IRQ的方式相同
void Cpu_6502::nmi()
{
write(0x0100 + stkp, (pc >> 8) & 0x00FF);
stkp--;
write(0x0100 + stkp, pc & 0x00FF);
stkp--;
SetFlag(B, 0);
SetFlag(U, 1);
SetFlag(I, 1);
write(0x0100 + stkp, status);
stkp--;
addr_abs = 0xFFFA;
uint16_t lo = read(addr_abs + 0);
uint16_t hi = read(addr_abs + 1);
pc = (hi << 8) | lo;
cycles = 8;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号