

Redis 哨兵(Sentinel)机制
redis的主从复制有个缺点:
master宕机,需要手动把一个slave改为master,这期间master不存在,不能对外提供服务,且不一定能即使发现master宕机了。
主从复制表面上是高可用的,实际上并不是。
哨兵机制:
也叫做哨兵模式,监控master、slave的状态,若master故障,自动从slave中选出一个新的master,并将变化通知到管理员、redis客户端。实现了redis主从复制的高可用。
sentinel 哨兵
实现哨兵模式
实现哨兵要用到2个文件:
- redis的bin下面有一个可执行文件redis-sentinel
- redis的解压目录下有一个配置文件sentinel.conf,复制到/usr/local/redis/conf下,当然放哪儿都行
若多台虚拟机上模拟,无需修改端口号、各种文件保存位置,但太吃内初。
若在一台虚拟机上模拟,将redis复制多份,放到/usr/local/redis下,依次重命名为redis1、redis2....,并修改端口号、文件保存路径。
修改sentinel.conf中的几个参数:
bind 192.168.1.7 172.0.0.1 #绑定本机ip。可同时绑定多个,优先使用前面的,把实际ip写在前面。
#protected-mode no #关闭保护模式(不使用保护模式) port 26379 #修改要使用的端口号
daemonize yes #作为守护线程,后台启动 sentinel monitor mymaster 192.168.1.7 6379 2 #指定要监控的master的ip、port,客观下线指标(阈值)
#sentinel auth-pass mymaster abcd #如果master设置了密码,需要写上master的密码
先启动master、slave,等master、slave都启动了,再启动各个sentinel。
我们在sentinel.conf中配置的是master的ip、port,sentinel是通过master找到该master的slave,所以要先启动master、slave。
启动哨兵:
./redis-sentinel ../conf/sentinel.conf
就是执行redis的bin下面的redis-sentinel,指定配置文件sentinel.conf的位置。
ps -ef | grep sentinel 看到哨兵已经启动:(也可以grep redis)
![]()
连接到某个哨兵节点:
./redis-cli -h 192.168.1.8 -p 26379 #哨兵的ip、port
redis-cli不仅可以连接到redis-server,还可以连接到redis-sentinel,换成对应的端口即可。
关闭方式和redis-server一样,通过redis-cli发送一个shutdown命令。
看下该哨兵节点的监控信息:
info sentinel
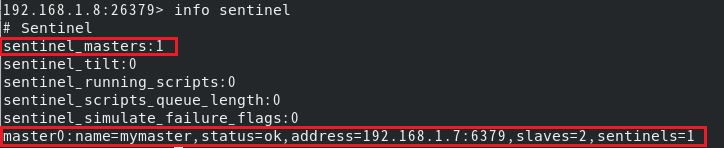
监控的master数量、监控的各master节点的信息都可以看到,包括master的名称、ip、port、slave数量。
sentinels是指该master是否被哨兵监控,1表示正在被哨兵监控,并不是监控此master的哨兵数量。
status为ok,表示该master状态正常。
关闭master,重新执行上面的命令,看到status=sdown,s即subjectively,主观。
每个sentinel每秒都会ping一下监控的所有的master、slave节点,如果在30s内没有收到master的回复,此sentinel节点主观上就认为master down掉了。将其标识为sdown。
如果标识master down掉的sentinel节点达到指定值(阈值),就客观上认为master确实down掉了,所有监控该master的sentinel节点都将master标识为odown。
过一段时间再此执行上面的命令,发现status=odown,o即objectively ,客观。
连接到某个slave,info replication看下主从信息:
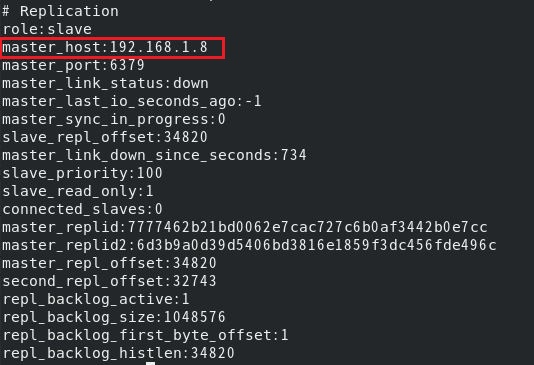
看到master已经从1.7换成了1.8。
看下某个sentinel的sentinel.log:

先是本sentinel将master标识为sdown,主观下线
然后标识为odown,客观下线。quorum即设置的阈值,有多个sentinel节点将其标识为下线就认为master确实down掉了。不小心把阈值改成了1......
try-failover 尝试进行故障转移,认为1.7发生故障不能再工作,需要把master这个位子转交给某个slave。failover 故障转移,fail over。
elected-leader 开始在slave中选新的master
selected-slave 选中了1.8作为新的master
failover-state 是故障转移的状态、进程,包括:
send-slaveof-noone 向1.8发送slaveof no one,即摆脱slave的地位
wait-promotion 等待1.8晋升为master,promotion 促进、提升、晋升
promoted 晋升完成,1.8成为新的master
之后就是其它slave从新的master处同步数据。
日志是很重要的,发生了错误,看下日志基本都能发现问题所在。
比如你把master down掉了,但一直没有选举新的master,日志中显示master、各个slave都是sdown,一直没有标识odown,
slave明明是正常的,却显示sdown,多半是链路不通,看一下能不能ping通,能ping通就再看下端口有没有弄好。
master down掉了,sentinel从哪里获取slave的ip、port?
sentinel刚连接master的时候,就会通过master获取到slave的节点信息,保存在sentinel本身的节点上,
并每秒ping一次各个slave,确定各个slave的状态,sentinel本身来维护各slave的节点信息。
master down掉,sentinel节点上是有slave节点信息的,不影响。
晋升机制
redis.conf中可以配置slave的优先级:

10,25,100,数值越大优先级越高,自动选择优先级大的。
如果优先级相同,看偏移量,偏移量小的说明数据新,自动选择偏移量小的。
说明
- 选举期间的写指令仍会全部丢失,但比手动配置新的master效率要高很多
- 如果原来的master重新上线,会作为新master的slave
- slave晋升为master后会获得写权限,可以执行写指令
sentinel.conf 参数详解
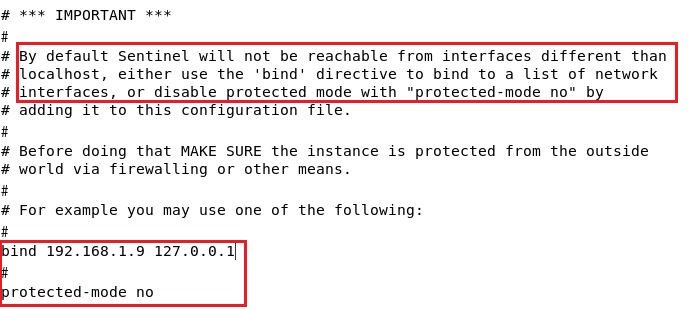
默认开启值保护模式,只能本地访问,即只能以127.0.0.1来访问redis-sentinel。
默认都是注释掉的,如果只在一个虚拟机中模拟,不用配置,
但实际运维时需要用bind绑定实际ip,绑定之后,才能连上指定的redis-sentinel
./redis-cli -h 192.168.1.8 -p 26379
否则只能连接到本地的redis-sentinel,因为默认就是127.0.0.1
可以绑定多个ip,优先使用前面的ip。
![]()
使用bind,会自动关闭保护模式,让protected-mode注释掉即可,不用管。
如果前面使用bind,后面开启保护模式(yes),后面的配置会覆盖前面的配置,同时使用时要注意这个问题。
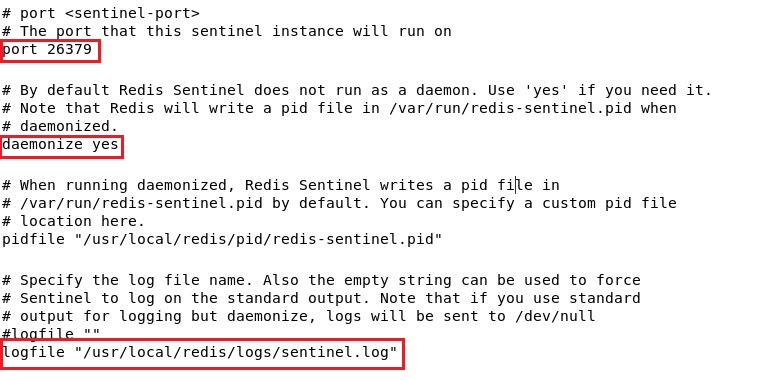
端口有个很大的坑,很多人都是在一台虚拟机上模拟的,修改下端口就行了,不需要开启防火墙,都是127.0.0.1,就在本地,开不开启端口,sentinel之间都可以通信。
但实际运维时,要在防火墙中开启26379端口,各个sentinel节点要用此端口通信,统计将master标识为sdown的节点数、选举新master等等都需要sentinel节点之间交互。
日志文件我习惯就放在redis下,好找。

指定要监测的master的ip、port,master-name只能包含字母、数字、点、短横、下划线。
quorum指定odown阈值,标识master为sdown的sentinel节点数达阈值,就认为master odown,重新选举master。
quorum 一般指定为sentinel节点数的一半+1,比如5=>3,10=>6。
选举出新的master后,会以发布/订阅的方式通知其他的slave,自动修改配置文件,让它们附属于新的master。
如果master设置了密码,需要写上密码。
redis服务器不用设置密码,如果要设置密码,master、slave设置的密码应该一致,不然更换master时,在sentinel中指定的master密码可能与晋升为master的slave的设置的密码不一致。
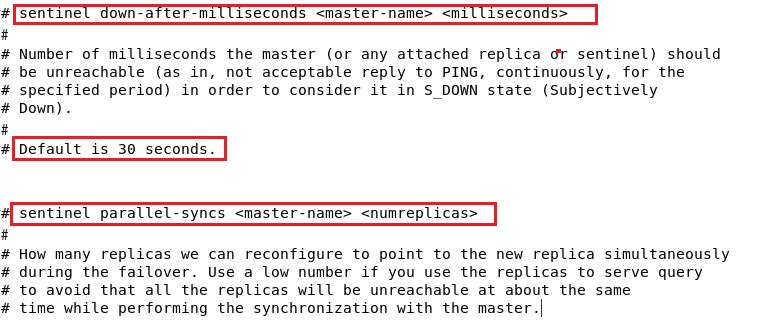
指定sentinel多少秒内没收到master的回复就认为master down掉了,将其标识为sdown。默认30s。
指定并行复制的slave节点数。选举出新的master后,其它slave要从新master处同步数据,所有slave一起复制数据,新master的IO开销很大,所以设置一个限制。
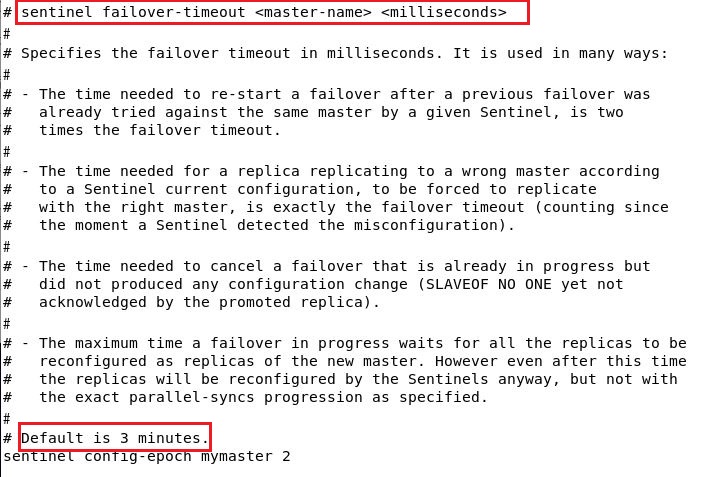
指定故障迁移的超时时间,在指定时间内未完成故障迁移,就认为故障迁移失败。默认3min。
master-name代表这一组主从复制节点中的master,不是代表某个固定的节点。
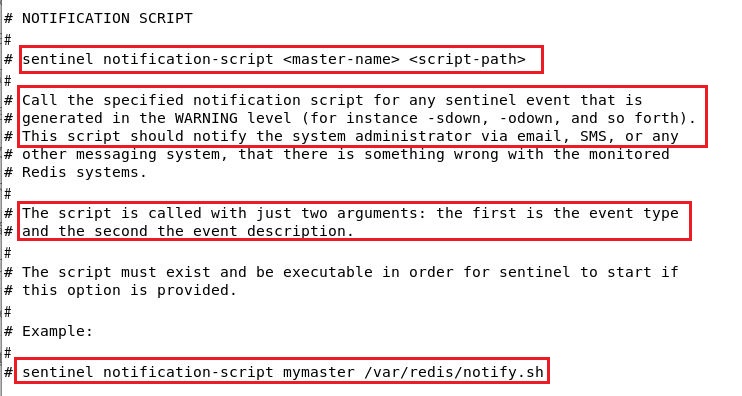
发生WARNING级别的问题,比如sdown、odown,会自动调用此参数指定的脚本,传入事件类型、事件描述。
我们可以自己写脚本,通过email等方式将信息通知给管理员,使用此参数指定脚本路径即可。
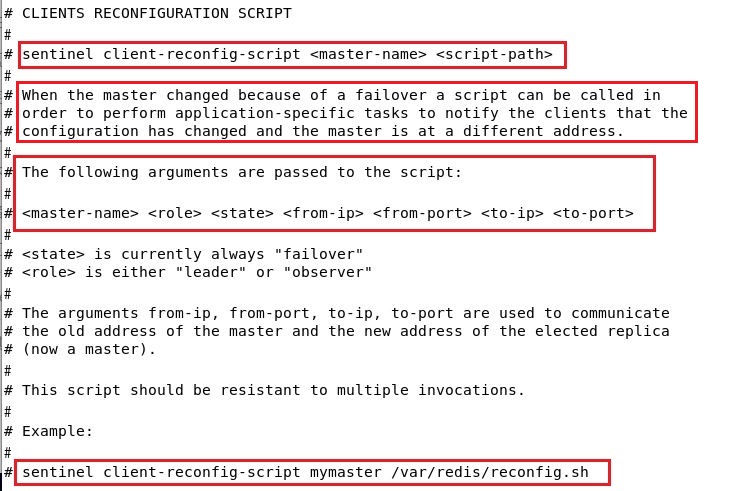
当选举出新的master时,会自动执行此参数执行的脚本,传入上一任master的ip、port和新master的ip、port。
我们可以自己写脚本,把这个变化通知给redis客户端,让客户端改下master的配置,以后把请求发给新的master。
sentinel往往是集群的,以达到高可用,某个sentinel节点挂掉也不影响。
一个sentinel集群用来监控单个主从复制,redis集群(即多个主从复制)需要用多个sentinel集群来监控。
哨兵只是配置提供者,向redis客户端、主从复制节点提供master节点的配置信息(ip、port),并非代理。
redis-cli的常见用法:
./redis-cli -h 192.168.1.7 #端口默认值是6379
auth abcd #验证密码,密码会加密传输 ./redis-cli -h 192.168.1.7 -a abcd #-a或-u指定redis-server的密码,这种是使用http明文传输,不安全,会提示不安全,但仍可以用
./redis-cli -h 192.168.1.7 shutdown #关闭127.168.1.7上的redis-server,如果redis-server没密码,可以这么做,但有密码就需要先连上,auth验证密码,再shutdown关闭
./redis-cli -h 192.168.1.7 -p 26379 #连接到redis-sentinel,端口很好记,就是redis的端口6379前面加个2
./redis-cli -h 192.168.1.7 -p 26379 shutdown #关闭192.168.1.7上的redis-sentinel
