

索引
什么是索引、为什么要建立索引?
设想这样一种情况:有一百万条记录,存放在一万个数据块中,这里只考虑顺序查找,他的线性时间复杂度,可以理解为要访问一万个数据块。如果建立索引,取出每条记录的关键字和他对应的指针,组成索引表。索引表存放在一百个数据块中,只需要访问100个数据块。所以,索引极大第提升了检索的效率。
顺序文件上的索引
顺序文件就是记录按照某个关键字存放在块中,块内有序,块间有序(也包括块内无序,块间有序这种情况)。

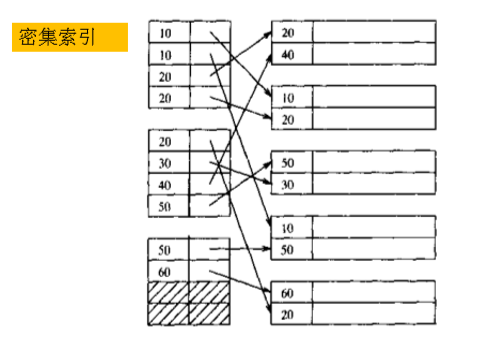
密集索引:每个索引对应一条记录
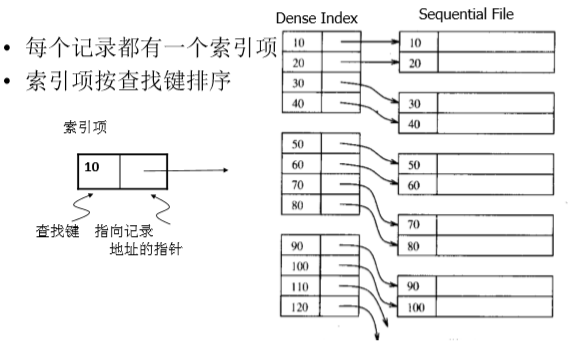
缺点是:索引表可能会占用存储空间。所以出现了稀疏索引。
稀疏索引:一个索引对应一个数据块。数据在块内是无序的,但是在块间是有序的。
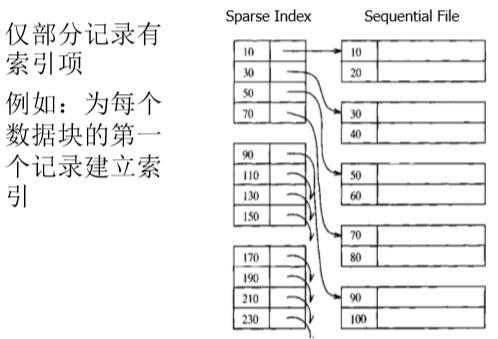
它既提高了检索的速度,又节省了索引表占用的空间。
辅助索引
考虑这样一种状况:记录在块内是无序的,在块间无序的,而且我还想用稀疏索引来提高我的检索速度,但是这个时候,采用稀疏索引是没有意义的。该怎么办呢?
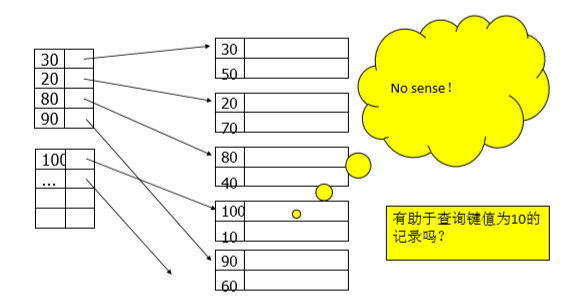
这个时候就出现了辅助索引:
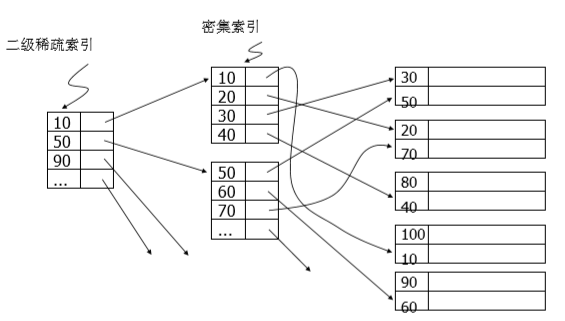
在二级稀疏索引与数据块之间,引入了密集索引,其实也可以理解为二级索引。稀疏索引与密集索引,都存放在磁盘。
思考一个问题:索引值是否可以重复?答案是肯定,索引值可以重复。来看看辅助索引是如何来处理重复索引值的:
没有间接桶的情况:
引入了间接桶之后:
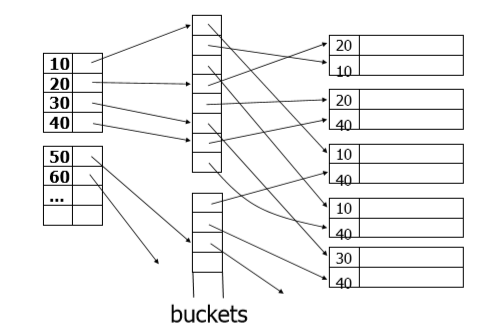
辅助索引中的间接桶应用
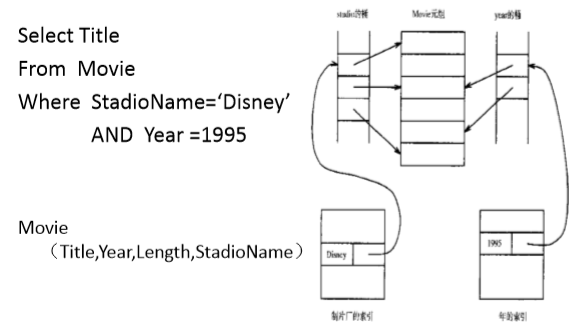
在StdioName和Year两个属性检索上建立索引。显然他们的索引值都是重复的,而且还是大量重复。根据间接桶中的指针,将各自的记录加载进内存。然后取两个集合的交集即可。
索引表的维护:
显然,无论是插入一条记录,还是删除一条记录,都有可能出发索引表的插入与删除:
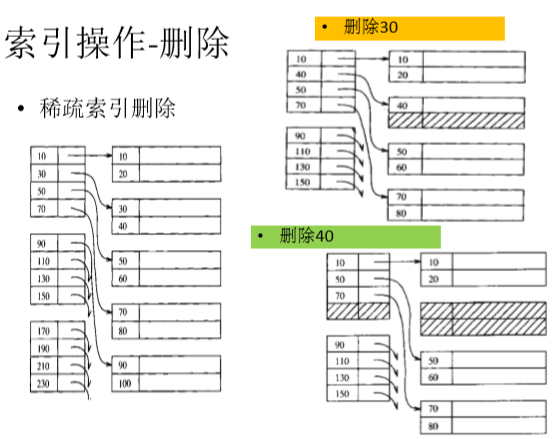
而索引表又是顺序组织的,所以也会涉及到索引表元素的移动。效率比较低。而且索引表的访问也只能采用顺序访问,即一块一块地读入内存,从中查找索引项。效率不高。
B+树索引
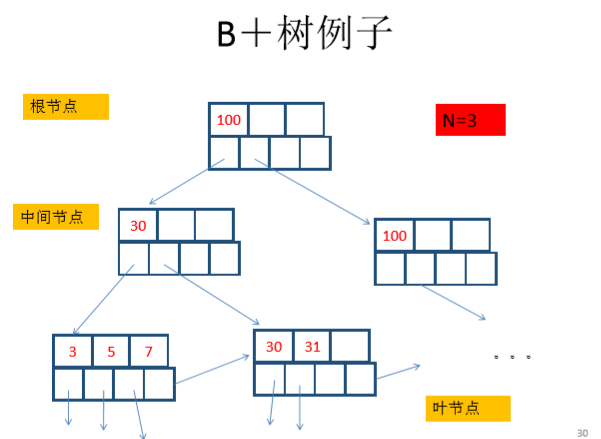
什么是B+树?
我听到了两个相矛盾的版本,一个是说:m阶的B+树有m个结点,m棵子树,另一个又说,m阶的B+树有m个结点,m+1棵子树。(也可能是我理解错误,请指正)
这里我采用第二个说法。
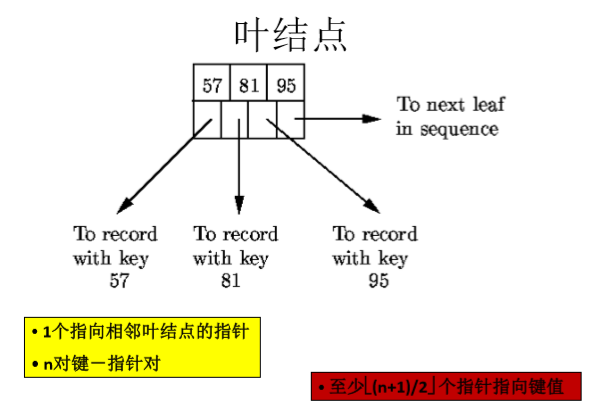
叶结点
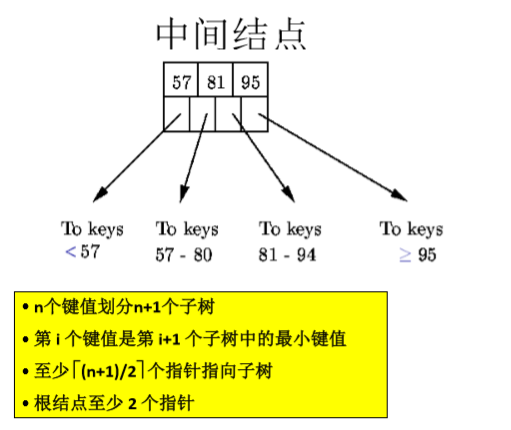
中间结点
其中,所有的关键字都存储在叶结点,并且有指针指向关键字对应的记录。
B+树查找:
根据指针,既可以从上往下,也可以从左往右(顺序查找,但是如果顺序查找就可能不能发挥出B+树的速度优势了)
B+树的分层:一般不超过三层,根结点常驻内存,所以索引的代价不超过2,总代价不超过3.一个叶结点就是一页,一页就是一个数据块。
为什么会得出这个结论?
基于计算。根据你数据据块的大小、 关键字的大小、指针的大小,可以计算出:一个磁盘块能够存放多少条索引。然后进行累乘,基本上,三层B+树就可以达到上亿的数量级。
以InnoDB为例,InnoDB存储引擎默认一个数据页大小为16kb,非叶子节点存放(key,pointer),pointer为6个字节,key为4个字节,即非叶子节点能存放16kb/14左右的key,pointer,而叶子节点如果一条数据大小为100字节,那一个叶子节点大约可存放160条数据。如果高度为3,则可存放数据为:16kb/14 * 16kb/14 * 160大约1亿多数据。因此InnoDB存储引擎b+树的高度基本为2-3.
参考:https://www.cnblogs.com/tangchuanyang/p/6634581.html
B+树可以高效地支持范围查询。
如图:
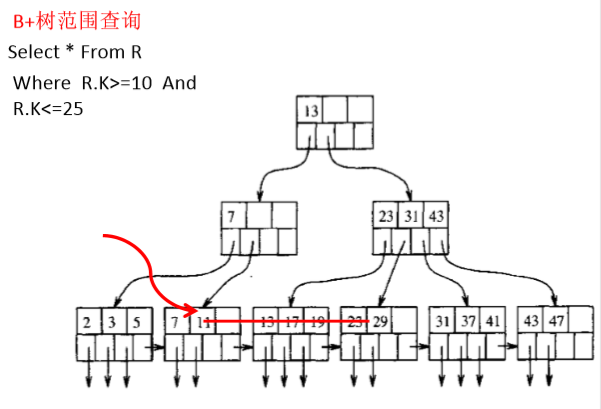
从上到下查找,将(7,11)这个叶结点加载进内存,再将(23,29)这个叶结点加载进内存,再将这两个叶结点中间的所有叶结点都加载进内存,最后在内存就可以找出10到25之间的所有数据。
散列表:
根据key,通过hash函数计算出是哪一个“桶”。在桶中找寻块,在块中查找记录。一般:一个桶对应一个块。
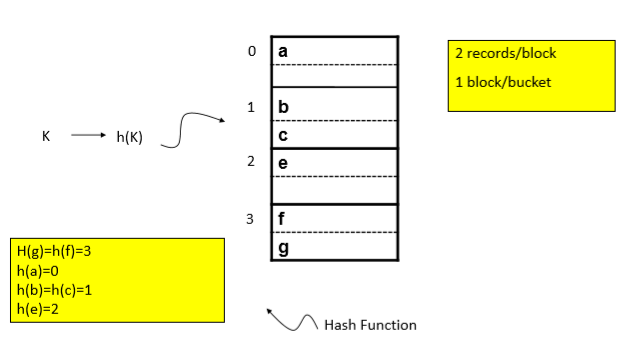
散列表的维护:
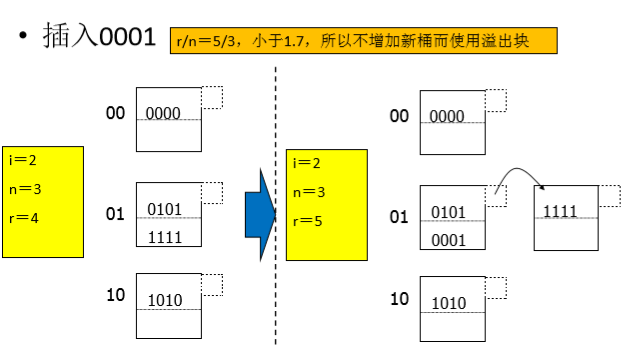
插入:根据key,计算得桶,若桶已满,则建立一个溢出块;将数据存入溢出块。但是,大量溢出块的存在,势必增大io次数。
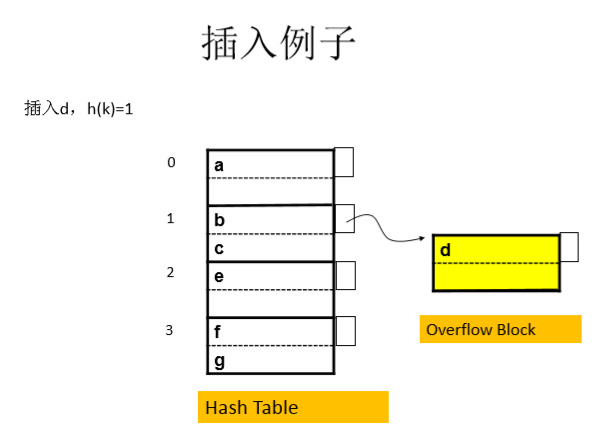
因此需要定期的进行io再散列,涉及到数据的大量移动。
删除:同样是根据key,计算得桶,从桶中将数据删除即可。这样一来,桶中就有额外的空间,可以把溢出块中的记录挪到桶中。
问题一:桶的数目足够大,且每桶一个块,存取 I/O最少。但是会导致很多桶没有放满,导致空间浪费。
问题二:数据的增多,会导致溢出块增多,io次数多。
因此要在时间与空间之间进行折衷。引入了动态散列表:
可扩展散列表-成倍增加
线性散列表-线性增加。
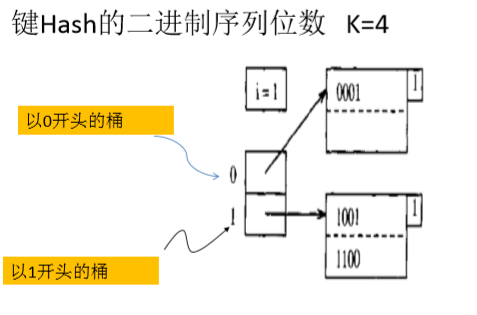
可扩展散列表:
将key通过hash函数,转换为一个b位二进制序列,其中,前i位表示桶的编号,用以区分桶。I的数值随着记录的增多而增大。
插入h(key)=1010的记录:
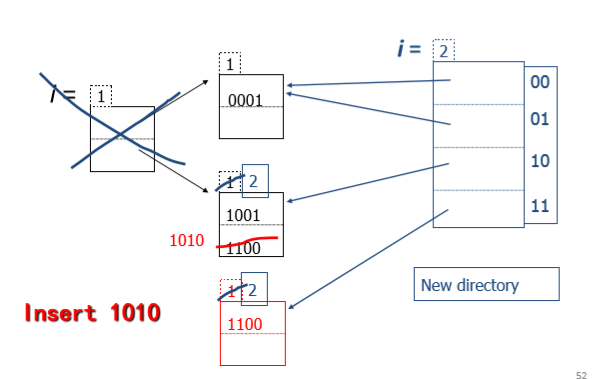
为什么说他是成倍增加的?
假设b=4;目前i= 2,有一个序列:11
现在把第三位也纳入桶的编号,110,111;
110也可以继续扩展:1101,1100;
111也可以继续扩展:1110,1111;
所以它的增长速度是线性的,原因在于用的是前i位来区分桶;
如果用的后i位,则可以延缓增长速度。
规则如下:
h(k)仍是二进制位序列,但使用右边(低)i位 区分桶
1)桶数=n,h(k)的右i位=m
2)若m<n,则记录位于第m个桶
3)若n <= m < 2i(2的i次方),则记录位于第 m-2i-1(仍然是2的i次方)个桶 什么时候增加新桶:总是使n与当前记录总数r保持某个固定比例,意味着只有当桶的填充度达到或者超过某个比例后桶数才开始增长。
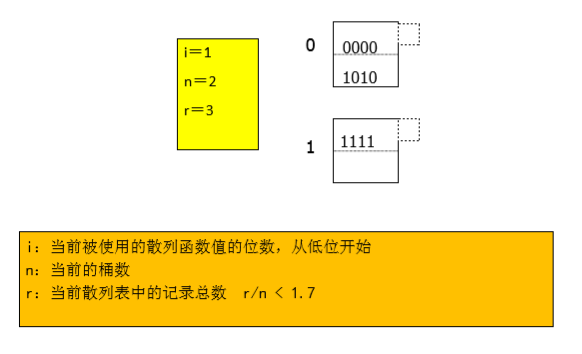
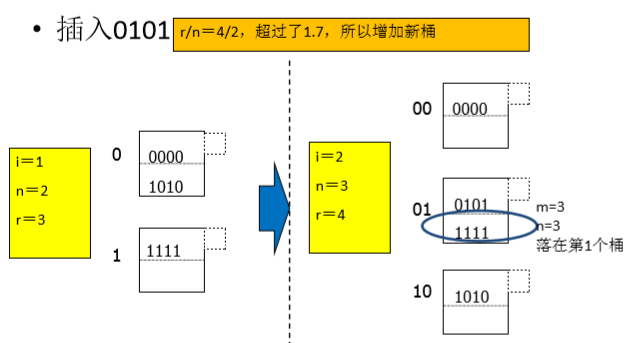
插入h(key)=0101的记录:
插入h(key)=0001的记录:
查找过程:仍然是先根据key计算出h(key),根据h(key)得到桶,在去桶中取数据。
注意:散列表天生不支持范围查询。
位图索引
转载自:https://www.cnblogs.com/LBSer/p/3322630.html
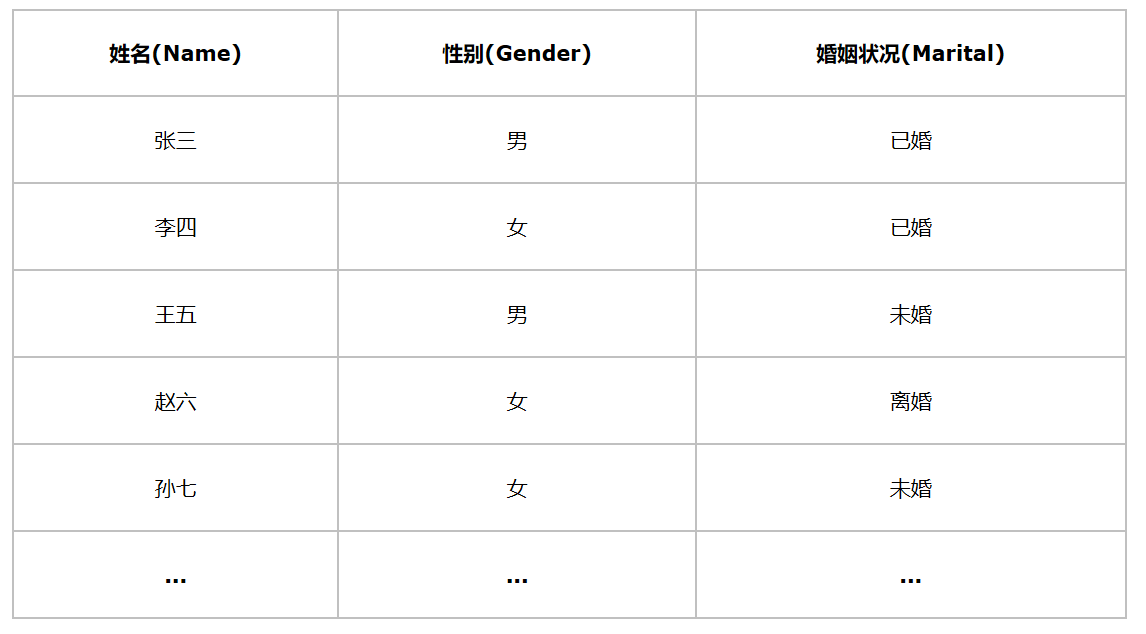
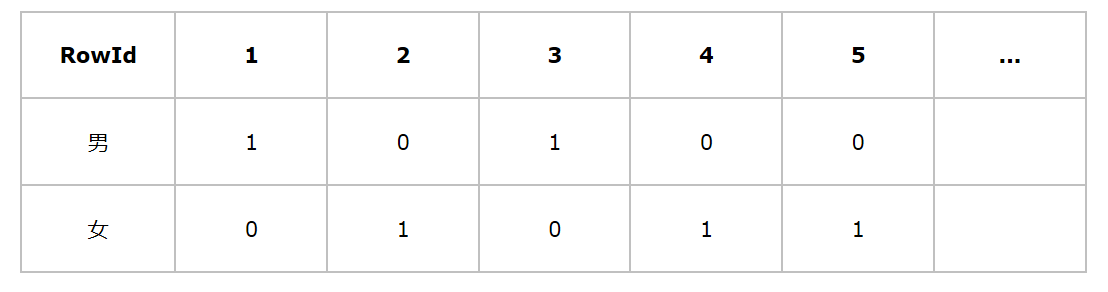
有张表名为table的表,由三列组成,分别是姓名、性别和婚姻状况,其中性别只有男和女两项,婚姻状况由已婚、未婚、离婚这三项,该表共有100w个记录。现在有这样的查询: select * from table where Gender=‘男’ and Marital=“未婚”;
对于性别这个列,位图索引形成两个向量,男向量为10100...,向量的每一位表示该行是否是男,如果是则位1,否为0,同理,女向量位01011。
对于婚姻状况这一列,位图索引生成三个向量,已婚为11000...,未婚为00100...,离婚为00010...。
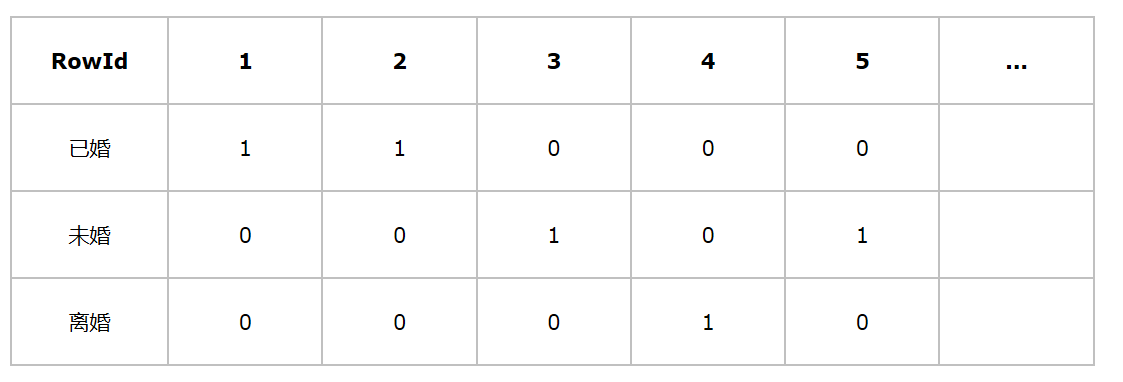
当我们使用查询语句“select * from table where Gender=‘男’ and Marital=“未婚”;”的时候 首先取出男向量10100...,然后取出未婚向量00101...,将两个向量做and操作,这时生成新向量00100...,可以发现第三位为1,表示该表的第三行数据就是我们需要查询的结果。
如果查询语句中的and改为or呢?
相应地,上述两个向量的与操作,改为或操作,得到的结果是10101,即第1,3,5个记录,他们或者是男或者是未婚。
什么时候适合用位图索引:
列的取值固定,易于编码;
查询的条件带有or或者and
更新操作不频繁,原因简单来说就是更新操作会导致整个向量被封锁住,影响并发。比如说:婚姻状况这个列(当然,只是举例子)频繁发生改变,当事务A将一号用户的婚姻状态由已婚改为未婚,那么已婚向量和未婚向量将同时被事务A锁定,其他事务若相修改/访问这两个向量,只能等待。因此会严重影响系统的并发度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号