
RDD(二)——创建
RDD的创建
1)从内存中创建
从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD
val raw: RDD[Int] = sc.parallelize(1 to 16)
val raw: RDD[Int] = sc.makeRDD(1 to 16)
2)从外部文件中创建
val line: RDD[String] = sc.textFile("E:/idea/spark2/in/info.log")
RDD的分区数
从内存中创建RDD的分区,得到分区数的源码如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
/*
如果没有指定分区数量这个参数,那么就采用默认的分区数量defaultParallelism,
那么这个参数如何得到的呢?
*/
override def defaultParallelism(): Int = { conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2)) } def getInt(key: String, defaultValue: Int): Int = catchIllegalValue(key) { getOption(key).map(_.toInt).getOrElse(defaultValue) }
/*
它会拿着spark.default.parallelism这个配置文件中的参数,去配置文件中获取值;
如果这个值没有,也就是没配,那么就由:
math.max(totalCoreCount.get(), 2)来决定;
即核数和2中的最大值;
*/
从文件系统中宏创建分区,得到分区数的原码原码如下:
def textFile( path: String, minPartitions: Int = defaultMinPartitions): RDD[String] = withScope { assertNotStopped() hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minPartitions).map(pair => pair._2.toString).setName(path) }
/*
同样的,如果分区数这个参数没有被指定,就由defaultMinPartitions这个参数决定;
*/ def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
/*
这个参数是由 math.min(defaultParallelism, 2)这个表达式来决定的;
defaultParallelism这个参数的计算方式同上;所以,如果没有指定分区数量,分区数量一般都是2;
*/
接下来验证对上述原码理解
从内存中创建:
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark") .set("spark.default.parallelism","3"))
/*通过sparkconf对象的set方法来配置spark.default.parallelism这一参数*/ val raw: RDD[Int] = sc.makeRDD(Array[Int](1, 2, 3, 4, 5, 6)) raw.saveAsTextFile("E:/idea/spark2/out") }
查看分区数,发现数据被分散在三个分区:
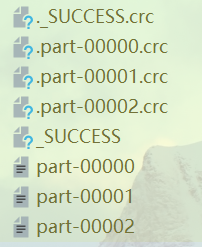
从文件系统创建:
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark") .set("spark.default.parallelism","3")) val raw: RDD[String] = sc.textFile("E:/idea/spark2/in/word.txt") raw.saveAsTextFile("E:/idea/spark2/out/word") }
但是这次的分区数只有两个:
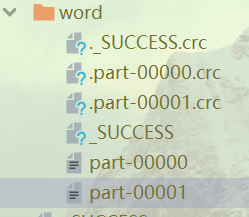

 浙公网安备 33010602011771号
浙公网安备 33010602011771号