spark[源码]-SparkEnv执行环境创建
sparkEnv概述
sparkEnv是spark的执行环境,其中包括众多与Executor执行相关的对象。在local模式下Driver会创建Executor,local-cluster部署模式或者Standalone部署模式下worker另起的CoarseGrainedExecutorBackend进程中也会创建Executor,所以SparkEnv存在于Driver或者CoarseGrainedExecutorBackend进程中。
创建分析
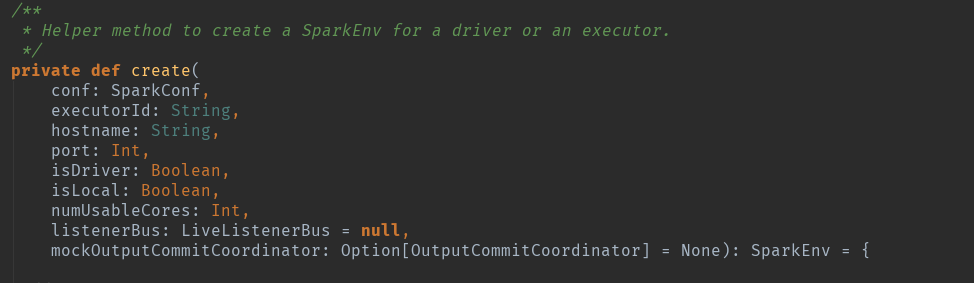
创建方法源码:
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER):请注意这个,其实在spark眼里没有driver的概念,都是Executor,只是id标签标记为了driver而已。

根据源码来看,其实在sparkContext初始化的时候,创建的是DriverEnv环境:457行
conf:sparkConf,spark的环境配置。
isLocal:模式判断。
listenerBus:事件监听总线。
SparkContext.numDriverCores(master):Driver的核数。
跳进方法体:代码很长,自行看吧,不全贴图了,根据开发者提示,dirver和executor都是调用的这个创建方法。
具体构造步骤如下:
创建安全管理器:securityManager。
actorSystem创建。

创建Netty分布式消息系统。这个地方默认应该是netty了:val rpcEnvName = conf.get("spark.rpc", "netty")
调用getRpcEnvFactory(conf).create(config)创建rpcEnv

根据代码来看,默认使用的是netty方式的,对应的实例生成类是:org.apache.spark.rpc.netty.NettyRpcEnvFactory中的create方法:

是driver就启动,这个地方启动的netty方式启动的,用于接受Executor的汇报信息。
Serializer和closureSerializer都是使用Class.forName反射生成的org.apache.spark.serializer.JavaSerializer类的实例。其中closureSerializer实例用来对Scala中的闭包进行序列化。
最后都是调用startServiceOnPort启动监听端口,只不过存在driver的这个节点在启动的时候多一个是用netty启动的,多了一个判断处理而已,但是这个节点仍然被认为是Executor。
dirver的netty方式处理:

executor的处理:

两个处理方式不一样,dirver的是netty的方式,而executor是采用akka的actor方式的。最终都是这个方法启动完成创建:

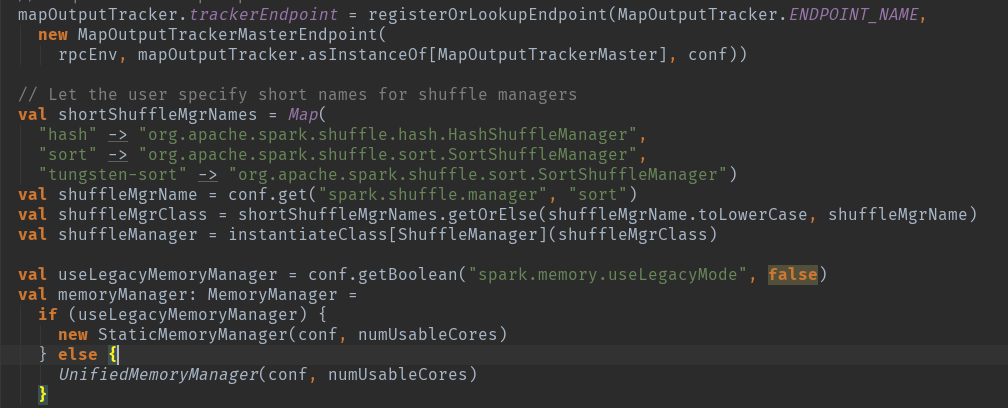
mapOutputTracker创建:
用于跟踪map阶段任务的输出状态,此状态便于reduce阶段任务获取地址及中间输出结果。MapOutputTrackerMaster内部使用mapStatus:TimeStampedHashMap[Int,Array[MapStatus]]来维护跟踪各个map任务的输出状态。其中key对应shuffleId,Array存储各个map任务对应的状态信息MapStatus。

根据代码可以看出,有是根据是否为driver存在不同的创建方式:
如果当前应用程序为Driver,则创建MapOutputTrackerMaster,然后创建MapOutputTrackerMasterEndpoint,并且注册到RpcEndpoint系统中。
如果当前应用程序为Executor,则创建MapOutputTrackerWorker,并从RpcEndpoint持有MapOutputTrackerMasterEndpint的应用。

实例化shuffleManager:
ShuffleManager负责管理本地及远程的block数据的shuffle操作。默认的SortShuffleManager通过持有的IndexShuffleBlockManger间接操作BlockManager中的DiskBlockManger将map结果写入本地,并根据shuffleId,mapId写入索引文件,也能通过MapOutputTrackerMaster中维护的mapStatuses从本地或者其他远程节点读取文件。
块传输服务blockTransferService:
BlockTransferService默认为NettyBlockTransferService,使用Netty提供的异步事件驱动的网络应用框架,提供web服务及客户端,获取远程节点上Block的集合。
BlockManagerMaster介绍:
BlockManagerMaster负责对Block的管理和协调,具体操作依赖于BlockManagerMasterEndpoint。Driver和Executor处理的BlockManagerMaster的方式不同:
·如果当前应用程序为Driver,则创建BlockManagerMasterEndpoint,并且注册到RpcEndpoint中。
·如果当前应用程序为Executor, 则从RpcEndpoint中找到BlockManagerMasterEndpoint。
无论是Driver还是Executor,最后BlockManagerMaster的属性driverEndpoint将持有对BlockManagerMasterEndpoint的引用(RpcEndpointRef)。
创建块管理器BlockManager:
BlockManager负责对Block的管理,只有在BlockManager的初始化方法initialize被调用后,它才是有效地。
创建广播管理器BroadcastManager:
BroadcastManager用户将配置信息和序列化后的RDD、Job以及ShuffleDependency等信息在本地存储。如果为了容灾,也会复制到其他节点上。
BroadcastManager必须在其初始化方法initialize被调用后,才能生效。
创建缓存管理器CacheManager:
CacheManager用户缓存RDD某个分区计算后的中间结果,缓存计算结果发生在迭代计算的时候。
创建测量系统MetricsSystem:
MetricsSystem是Spark的测量系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号