
2021OO第三单元总结
第三单元总结
19231142 李靖尧
一、第一次作业:
本单元第一次作业是要实现一个简单的线上交流系统,实现难度不大,重点在于JML规格语言的理解上面,难点在实现算法的优化上。一共需要两个基本类,根据Person和NetWork接口实现自己相对应的类,类中的方法需要根据JML的描述进行书写。同时在各种查询中可能出现异常情况,因此还应实现对应的异常类和异常计数器。
本次作业的失误之处在于对JML规格的理解偏差,主要体现在两个方面上。第一是对语法理解的失误,比如在NetWork类中有一个isCircle方法,判断两人是否相联(用图论的说法就是两个点是否联通)。在JML中是这样判断的:

翻译成大白话就是是否存在一个长度大于二Person数组,首尾元素分别是需要判断的两个人,数组中前后两人需要“有边”。我理解成是否能在NetWork类属性Person数组中挑选元素构成新的数组满足上述关系,比JML要求的Person数组新增了“数组元素两两不同”的要求,因此在查询一个孤立的人是否和自己相联的时候,会误判成False,导致强测挂了一半。
第二个理解误差用不恰当的比喻说就是“温水煮青蛙”。由于JML规格在描述一个方法时,已经说明了一种可行的实现办法(算法),在我自己实现时,就像对照说明书一样,完全照抄或者翻译JML语言。这样,对于简单的方法例如最基本的getter方法是没有问题的,然而对于复杂度较高的方法就会有超时的风险。最典型的就是queryBlockSum(计算连通块数量)方法,接口中的JML将算法描述为双层循环,循环内部调用isCircle方法,如果完全照搬翻译的话,这个方法的复杂度可能会到O(n^3),多次调用该方法,2s 的CPU运行时间是完全打不住的。
二、规格再理解
以上这两个错误让我加深了对“规格”的理解。那么什么是规格呢?举个三角函数的例子:定义(规格描述):在直角三角形中,∠α(不是直角)的对边与斜边的比叫做∠α的正弦,记作sinα。在这个规格中,对于正弦下了定义,那么是怎么定义的呢?——所对的直角边/斜边。我们可以看出,其实规格中的定义其实就是一种实现方法,它描述这个量是什么含义,但是在具体实现时2,可以有不同的方法,比如按定义计算:将一个角放入直角坐标系中,使角的始边与X轴的非负半轴重合,在角的终边上取一点A(x,y),过A做X轴的垂线,则r=SQRT(x^2+y^2 ), sinα=y/r。或者,Taylor展开:sin(x) = x – x^3 /3!+ x^5/5!- x^7/7!+……(计算精度可预期)。因此用大白话来讲,规格就是描述了这个量到底是什么意义,怎么来的,实现时的算法还需要具体问题具体分析。但需要注意一点,虽说实现可以多样,但是结果还需要和规格中描述一致。比如说第二次作业加入了计算组内人员的年龄方差,规格描述为,但是有的同学为了简化计算,结合了概率统计课上的知识,用E(age^2)-E(age)^2计算方差,强测出了问题。原因出现在精度上,方法返回int,因此按照规格描述中的做法最后会向下取整,而这个同学在计算中就向下取整了,导致精度不够,出现问题。综上,方法千万条,规格第一条。结果有偏差,强测苦哇哇。
三、第二次作业
在第一次作业基础上,本次作业增加了聊条系统对于群组的支持,可以实现组内发消息,添加,人员,剔除人员的功能。
本次作业出现的问题还在于qbs的复杂度上。第一次作业后,我在NetWork类中增加了blockSum的属性,每增加一个人时,blockSum++。增加关系时,先判断两个人是否相联,如果不相联,blockSum--。问题就出现在每次增加关系时都要进行广度优先算法的isCircle判断,如果ar指令过多,时间又会爆表。因此,我们需要一种能够“记忆”的算法,记住每个人和谁联通,联通的人又和谁联通,这样只需要一次类似“查表”工作即可判断两人是否相联。结合数据结构课上的知识,我采用了“并查集”的算法,在程序中具体使用了HashMap进行存储和查询,速度较快。其思想就是每个人就记住和自己相联的一个人就好,如果谁也不相联,那就记住自己。处理ar指令时,需要更新其中一个人记忆的信息,和另外一个人建立关系。这样,一个完整的树形人物关系图就呈现在眼前了。当我们查找一个人时,即可“纲举而目张”,所有和它相联的“父节点”都可得知,一直“追本溯源”,可以找到类似图论中的根节点。进一步优化性能,可以在处理ar时进行“压缩路径”的操作,即让person A的所有“父节点”都成为person B“父节点”的“亲生子节点”,这样可以使后续的查询操作大大减少时间。
下图为传统的BFS算法判断是否两人相联:
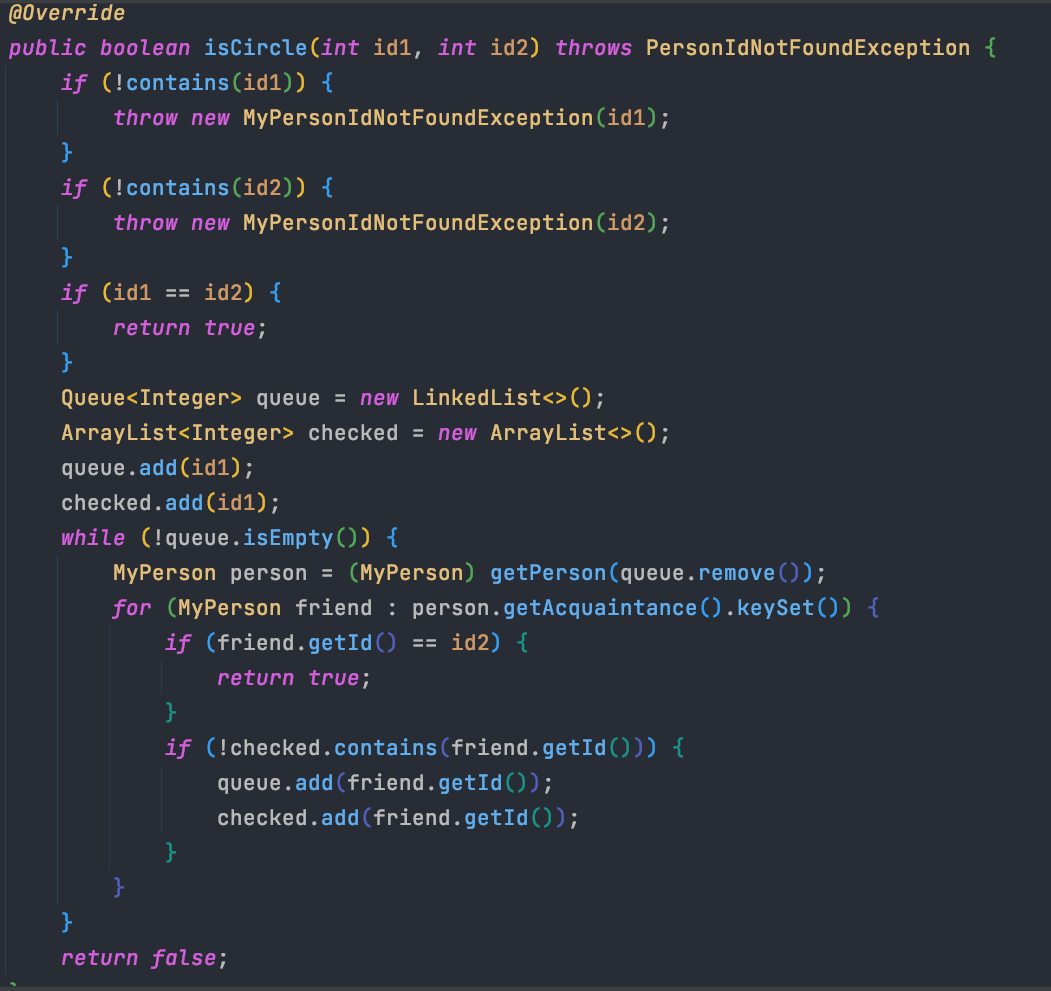
优化后的算法采用并查集,具体为两个方法:
1、追本溯源,找根结点:

2、压缩路径,认祖归宗:

至此,有关ar、ap、qbs指令的优化就告一段落了。
四、第三次作业
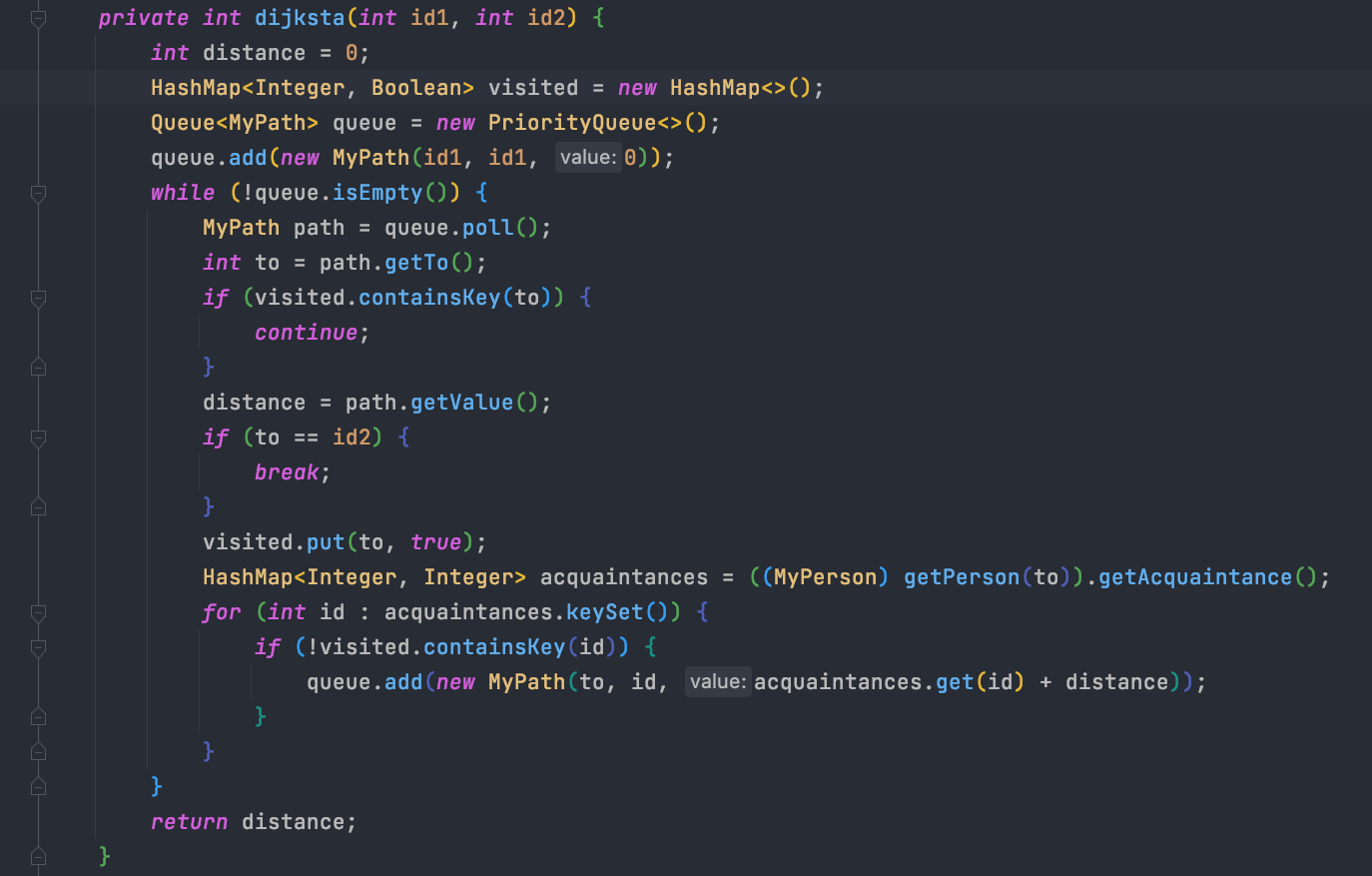
第三次作业在前两次的基础上对于Message的种类和操作做了进一步的扩展,其中难度最大的莫过于sendIndirectMessage了,该方法要求寻找两人之间的最短路径。根据图论的知识,最短路径问题的皇家算法莫过于“狄杰斯特拉”算法了。简而言之,将图中所有点分为两组,一组用过点集,一组没用过点集。首先将所有的边进行排序,每次从最短的边开始扫描,如果这个边的一个定点被用,另一个未被用,则加入这条边,并更新两个点集。在具体实现时,可以考虑堆优化,具体到java语言,可以考虑采用优先队列PriorityQueue,其底层是通过小顶堆实现的。具体到算法上,当队列不空时,每次从队列中pop一条边,“边”需要自己单独构造类实现,并实现Comparable接口重写compare方法,这样pop时会自动弹出一条最短的边。判断边的终点是否已经被使用过,可以构造一个Hashmap存放已经使用过的点,若终点不在其中,将这个点相连的所有边push到队列里,并在Hashmap中添加这个点。有一点需要注意,狄杰斯特拉算法中,往队列里push的边的长度应该是当前距离之和加上这条边的权重。
图为实现的方法:
说到了Hashmap,就不得不说说这几次作业中的容器的使用。由于作业对性能有要求,因此在存储数据的数据结构的选取上,应该尤为谨慎。我们知道,Hashmap的查找和遍历速度是最快的,尤其是查找操作可使复杂度降为O(1)。因此在程序中,用数组(静态的或者动态的ArrayList)的地方都应该尽可能替换为Hashmap,以减少多次查找带来的时间开销。
五、总结
通过这单元的三次作业,让我深刻理解了JML规格的语法和意义,对于Junit的调试进一步有了熟练,另外在研讨课上讲的黑盒、白盒测试也加深了我对程序测试的了解。

