源码方式本地化部署deepseek和量化
前置条件
1.python环境,安装教程:https://www.python.org/downloads/
2.wsl环境(Windows系统),安装教程:https://learn.microsoft.com/zh-cn/windows/wsl/install
第一步下载大模型
模型仓库:https://huggingface.co/collections/deepseek-ai/deepseek-r1-678e1e131c0169c0bc89728d

第二步配置环境
1.安装cuda
https://www.cnblogs.com/zijie1024/articles/18375637
2.安装pytorch
使用命令nvidia-smi,查看cuda版本
在官网选择对应版本下载
官网:https://pytorch.org/get-started/locally/

得到命令:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu12
如果pip3安装失败就改为pip
3.安装依赖包


pip install bitsandbytes
pip install transformers
pip install accelerate
如果提示:ModuleNotFoundError: No module named 'torch'
执行:pip install --upgrade pip setuptools wheel
第三步运行
1.直接运行
try: from transformers import AutoModelForCausalLM, AutoTokenizer import torch except ImportError as e: print(f"导入库时发生错误: {e},请确保 transformers 和 torch 库已正确安装。") else: try: # 模型和分词器的本地路径 model_path = "." # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_path) # 加载模型 model = AutoModelForCausalLM.from_pretrained(model_path) # 检查是否可以使用 GPU 并设置设备 device = "cuda" if torch.cuda.is_available() else "cpu" if device == "cuda": print("Using GPU for inference.") else: print("Using CPU for inference.") model.to(device) # 示例输入 input_text = "你是哪个模型?" inputs = tokenizer(input_text, return_tensors="pt").to(device) # 模型推理 with torch.no_grad(): # 禁用梯度计算,减少内存占用 outputs = model.generate(**inputs, max_length=2000, num_return_sequences=1, no_repeat_ngram_size=2, temperature=1.0, top_k=50, top_p=0.95) generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True) print("Generated text:", generated_text) except FileNotFoundError: print(f"模型文件未找到,请检查路径: {model_path}") except Exception as e: print(f"发生错误: {e}") finally: # 如果是在 GPU 上运行,尝试清理缓存 if device == "cuda": torch.cuda.empty_cache()
2.量化后运行
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig import torch # 模型路径 model_name = "." quantized_model_dir = "deepseek-1.5b-quantized" # 配置量化参数 quantization_config = BitsAndBytesConfig( load_in_4bit=True, # 使用 4 位量化 bnb_4bit_compute_dtype=torch.float16, # 计算精度 bnb_4bit_use_double_quant=True, # 使用双量化 llm_int8_enable_fp32_cpu_offload=True # 启用 CPU 卸载 ) # 加载模型和分词器 model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=quantization_config, device_map="auto", trust_remote_code=True ) tokenizer = AutoTokenizer.from_pretrained(model_name) # 保存量化后的模型 model.save_pretrained(quantized_model_dir) tokenizer.save_pretrained(quantized_model_dir) print(f"Quantized model saved to: {quantized_model_dir}") # 执行运行模型的py,也可以手动运行,注意修改模型路径为量化后的模型路径 with open("run.py", "r") as file: script_content = file.read() exec(script_content)
运行效果
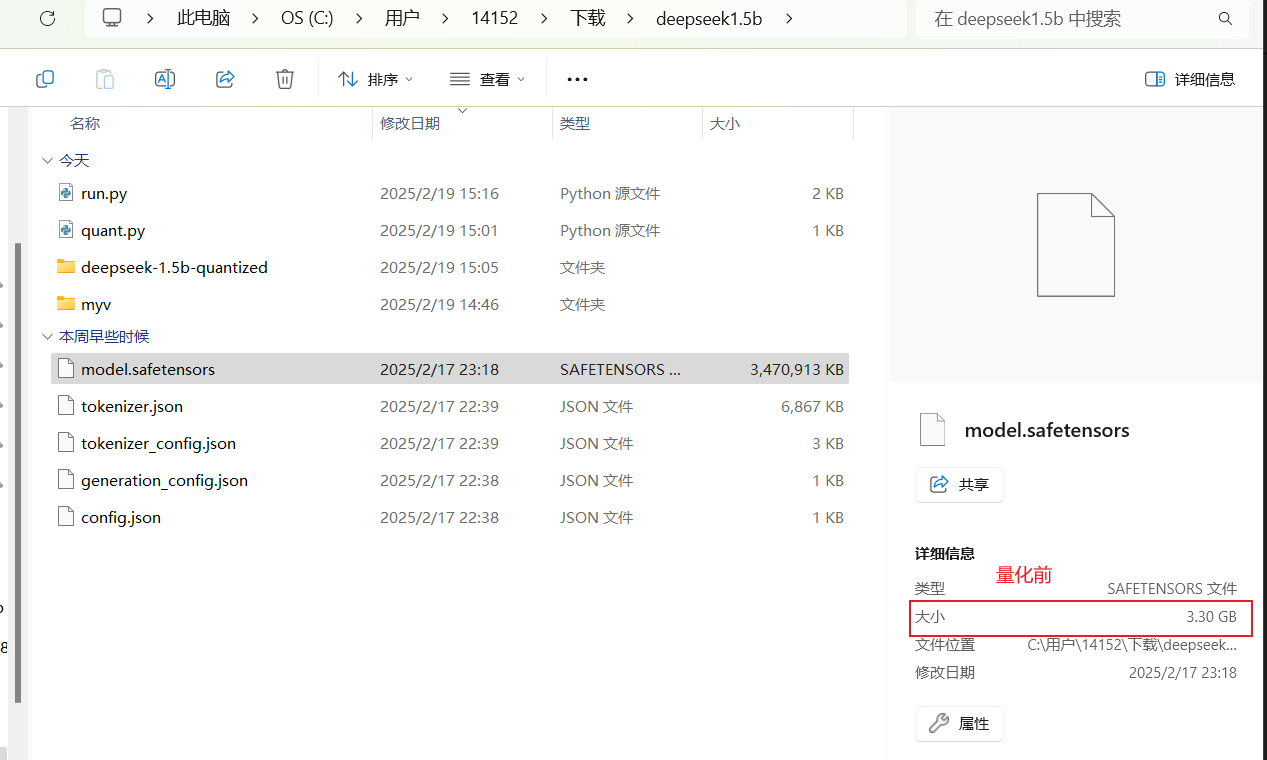
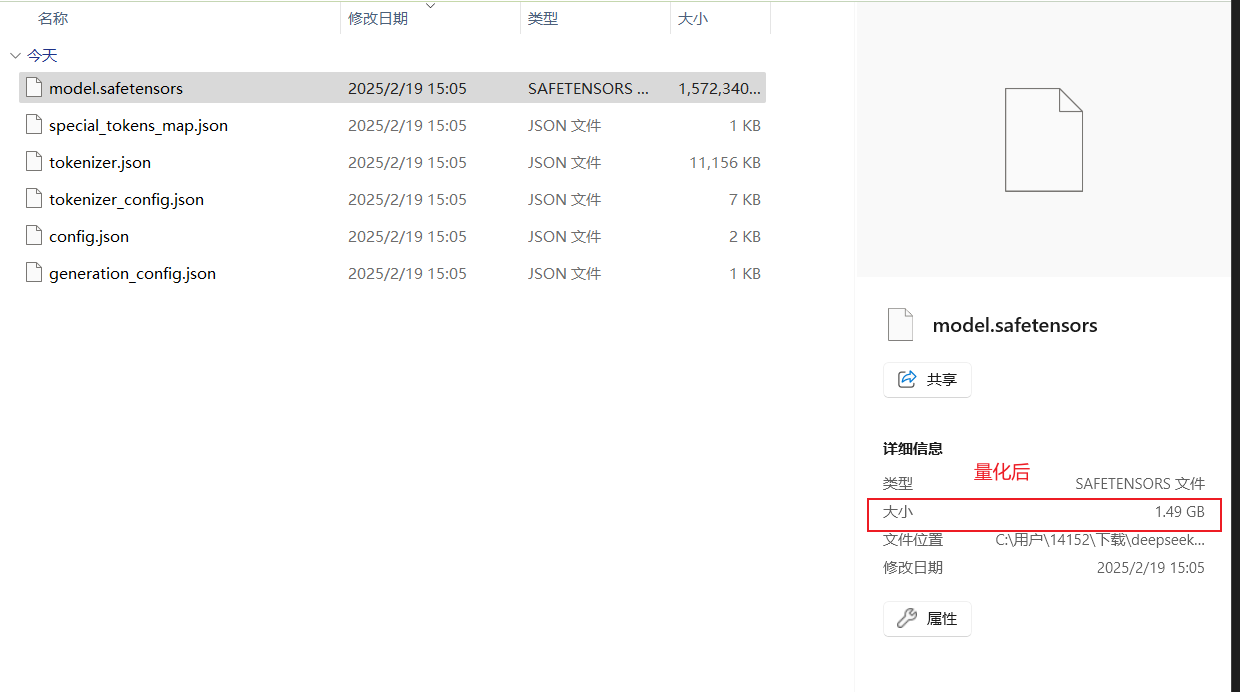
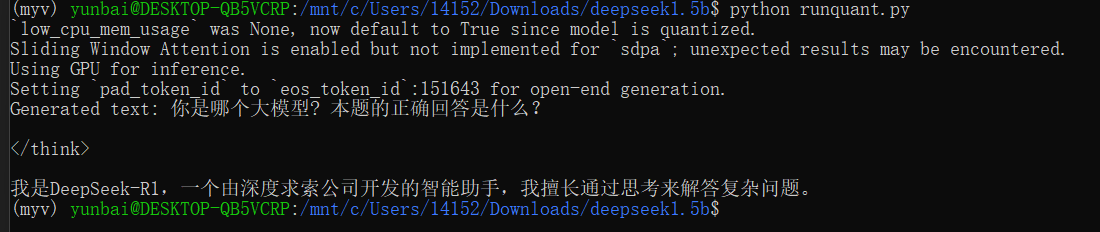

 浙公网安备 33010602011771号
浙公网安备 33010602011771号