




1. Few-Shot Audio Classification with Attentional Graph Neural Networks
使用注意力图神经网络进行少样本音频分类**
- Authors: S Zhang, Y Qin, K Sun, Y Lin作者:张S、秦Y、孙K、林Y
- Summary: This paper employs graph neural networks for few-shot audio classification using Soundnet convolutional neural network pre-trained on unsupervised video data.摘要:本文采用图神经网络进行少镜头音频分类,使用在无监督视频数据上预训练的 Soundnet 卷积神经网络。
- Link: PDF链接:PDF
- Citations: 47 citations引用次数:47 次
2019 interspeech; IBM 公司
摘要
few -shot学习是机器学习中一个非常有前途和具有挑战性的领域,因为它旨在从很少的标记示例中理解新概念。在本文中,我们提出了注意力框架来扩展最近提出的基于图神经网络[1]的音频分类场景的少镜头学习。提出的关注框架的目的是引入一个灵活的框架来实现对每个查询过程的支持示例的选择性集中过程。我们还提出了将网络概率输出的后验概率与归一化熵相结合的方法,用于小概率学习应用的置信度度量的实证研究。用平衡训练集Audio set进行训练,用由约5小时音频数据组成的5路测试集进行测试,验证了所提方法的有效性。索引术语:短镜头学习,音频分类,注意力框架,信心测量。
方法
结论
2. Conversational Emotion Recognition Using Self-Attention Mechanisms and Graph Neural Networks
使用自注意力机制和图神经网络进行会话情感识别
2020 中科院与华为
摘要
与个体话语的情感估计不同,语境敏感依赖和说话人敏感依赖对会话情感分析至关重要。在本文中,我们提出了一个基于图的神经网络来模拟这些依赖关系。具体来说,我们的方法将每个话语和每个说话人表示为一个节点。为了桥接上下文敏感的依赖关系,每个话语节点在同一会话的直接话语之间具有边缘。同时,每个话语节点与其说话人节点之间的有向边桥接了说话人敏感的依赖关系。为了验证我们策略的有效性,我们在MELD数据集上进行了实验。实验结果表明,我们的方法比最先进的策略绝对提高了1% ~ 2%。关键词:深度学习,会话情感识别,自注意机制,图神经网络,
过程: ideal
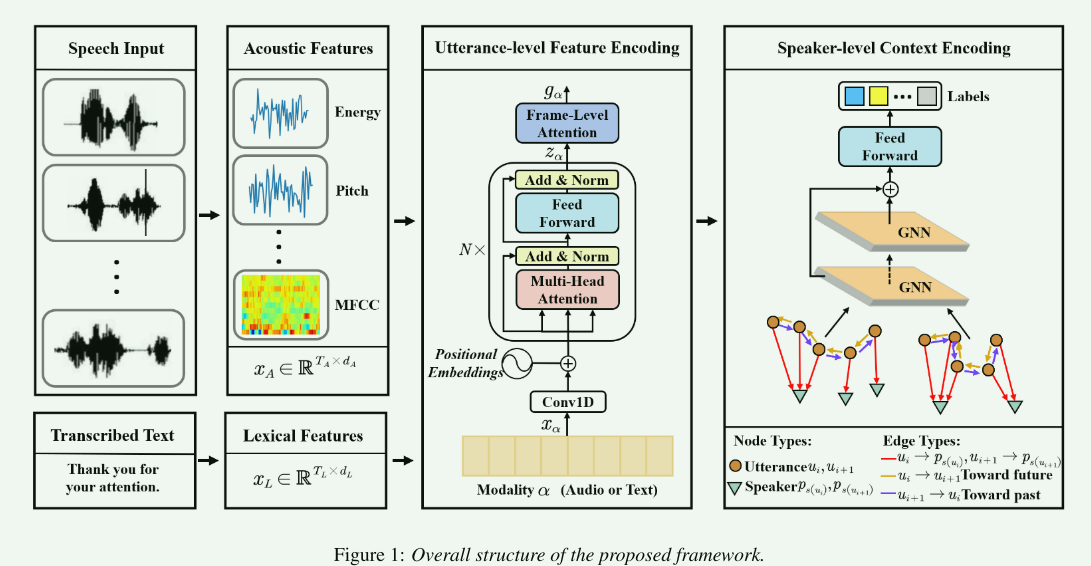
使用openSMILE[29]语音工具包从原始波形中提取帧级声学特征,帧窗大小为25毫秒,帧间隔为10毫秒。具体来说,我们使用了Eyben等人引入的扩展日内瓦极简声学参数集(eGeMAPS)。共提取88维帧级声学特征;词级词汇特征是从口语单词的文本中提取出来的。具体来说,我们使用公共可用的Word2Vec[31]模型获得单词的300维向量表示。
3.3. 在话语级特征编码过程中,Conv1D层将声学和词汇特征映射到大小为d = 30的固定维度,然后映射5个多头注意块(30个维度状态和5个注意头)。为了优化参数,我们使用Adam优化,从0.001的初始学习率开始。我们训练模型100次,批大小为32。为了缓解过度拟合问题,我们还使用了dropout[32],其比率为0.4。在我们的实验中,每个配置都用不同的权重初始化测试了20次。用加权平均精度对实验结果进行评价。
结论
在本文中,我们提出了一个用于会话情感识别的多模态多方框架。我们的方法利用图神经网络来模拟对话中上下文敏感和说话人敏感的依赖关系。消融研究验证了我们提出的关系约简过程和话语级特征编码过程的有效性。在MELD数据集上的实验结果证明了该框架的有效性。在词汇和双峰结果方面,我们的方法比最先进的策略表现出1.3% ~ 1.7%的绝对性能提高。
- Authors: Z Lian, J Tao, B Liu, J Huang, Z Yang, R Li作者:Z Lian、J 陶、B Liu、J Huang、Z Yang、R Li
- Summary: This paper proposes a graph-based neural network to model conversational dependencies for emotion recognition.摘要:本文提出了一种基于图的神经网络来模拟情感识别的会话依赖关系。
- Link: PDF链接:PDF
- Citations: 23 citations引用次数:23 次
3. Canonical Cortical Graph Neural Networks and Its Application for Speech Enhancement in Audio-Visual Hearing Aids
典型皮质图神经网络及其在视听助听器语音增强中的应用
2022年 英国伍尔弗汉普顿大学工程与信息学院CMI实验室
规范皮质图神经网络及其在视听助听器语音增强中的应用**
摘要
尽管机器学习算法最近取得了成功,但大多数模型在考虑需要不同来源之间交互的更复杂任务时都面临缺陷,例如多模态输入数据和逻辑时间序列。另一方面,生物大脑在这个意义上是高度敏锐的,被赋予了自动管理和整合这些信息流的能力。在这种背景下,这项工作从大脑皮层回路的最新发现中获得灵感,提出了一种生物学上更合理的自监督机器学习方法。这种方法结合了使用层内调制的多模态信息、典型相关分析和一种记忆机制来跟踪时间数据,这种方法被称为典型皮质图神经网络。在一个基准视听语音数据集的清洁音频重建和能源效率方面,这被证明优于最近最先进的模型。增强的性能通过减少和窒息神经元放电率分布来证明。建议所提出的模型适用于未来视听助听器的语音增强。
本文的主要贡献如下:1。提出典型皮质图神经网络,一种生物学上可行的多模态信息特征提取模型。2. 引入一种新的层内信息融合和内存建模范式。3. 为基于av的干净音频数据重构提供一种自监督节能的相关特征提取模型。4. 促进有关语音增强和AV助听器的文献。
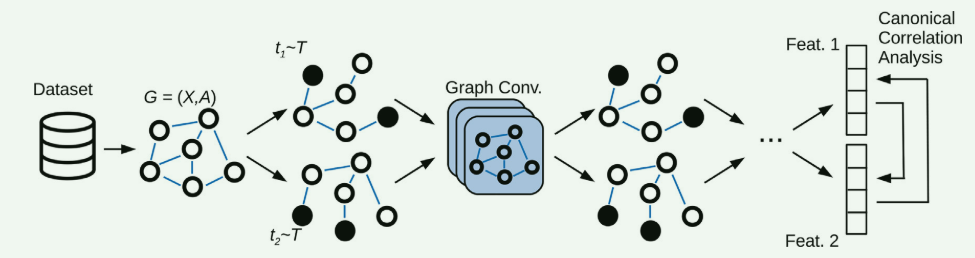
典型相关分析图神经网络。每个样本代表图中的一个节点,其边描述了样本对之间的关系。随机图生成器T生成该图的两个增强版本,用于馈送GNN模型。使用典型相关分析比较两个版本的输出,并调整网络参数以最大化此度量。
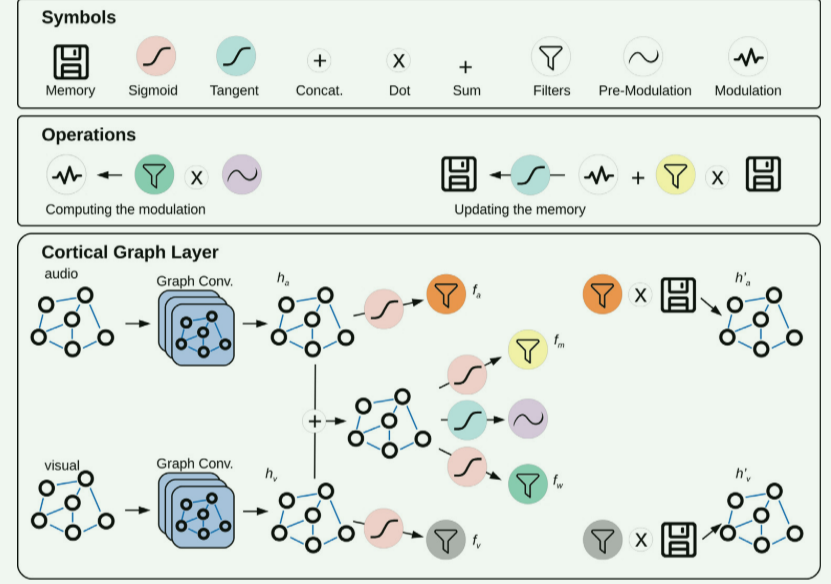
结论
提出了一种基于典型相关分析最大化的多模态相关特征自监督提取方法。所提出的模型包括一个基于块的神经网络,其中每个块包括两个图神经网络层,即一个用于噪声音频,另一个用于视觉特征,一个存储器,以及一组用于过滤,插入,删除和调制输入信号的操作。这种手术的灵感来自于最近有关皮层细胞及其相互作用的发现。在AV ChiME3数据集上进行了实验,该数据集是为考虑噪声音频和干净视觉实例的多模态干净音频重建任务而设计的,并将所提出的方法与最近为该任务提出的类似的最新方法CCA-GNN进行了比较。结果表明,所提出的典型皮质GNN提供了更连贯、质量更好的特征,达到了更高的典型相关分析值。该方法还获得了更精确的重建,生成了更清晰的重建。此外,该模型在能量方面提供了更高的效率,通过神经元的放电率来评估。最后,由于存储器可以存储和跟踪时间信息,因此它也显示出自己较少依赖于更扩展的先验帧序列,即高k值。
关于未来的工作,我们的目标是将类似的基于皮层的架构扩展到卷积神经网络,并将其应用于二维数据。我们还打算在芯片上实现该模型,用于训练和推理,以便将来在助听器中实现AV语音增强。
- Authors: LA Passos, JP Papa, A Hussain, A Adeel作者:LA Passos、JP Papa、A Hussain、A Adeel
- Summary: This paper introduces canonical cortical graph neural networks for multimodal clean audio reconstruction based on noisy audio and visual inputs.摘要:本文介绍了基于噪声音频和视觉输入的多模态干净音频重建的规范皮质图神经网络。
- Link: HTML链接:HTML
- Citations: 5 citations引用次数:5 次引用
4. Speaker Attribution with Voice Profiles by Graph-Based Semi-Supervised Learning
通过基于图的半监督学习通过语音配置文件进行说话人归因**
摘要
方法
结论
- Authors: J Wang, X Xiao, J Wu, R Ramamurthy作者:J Wang、Xiao、J Wu、R Ramamurthy
- Summary: This paper utilizes graph neural networks to encode graph structures and learn speaker attribution in meetings.摘要:本文利用图神经网络对图结构进行编码并学习会议中的发言者归因。
- Link: PDF链接:PDF
- Citations: 11 citations引用次数:11 次
5. Multi-Channel Speech Enhancement Using Graph Neural Networks
使用图神经网络的多通道语音增强
摘要
方法
结论
- Authors: P Tzirakis, A Kumar, J Donley作者:P Tzirakis、A Kumar、J Donley
- Summary: This research introduces the use of graph neural networks to exploit spatial correlations in multi-channel speech enhancement.摘要:本研究介绍了使用图神经网络来利用多通道语音增强中的空间相关性。
- Link: PDF链接:PDF
- Citations: 38 citations引用次数:38 次
6. Graph-Based Audio Classification Using Pre-Trained Models and Graph Neural Networks
使用预训练模型和图神经网络进行基于图的音频分类
声音分类在提高声学数据的解释、分析和利用方面起着至关重要的作用,导致了广泛的实际应用,其中环境声音分析是最重要的之一。在本文中,我们探讨了在声音分类的背景下音频数据的图形表示。我们提出了一种方法,利用预训练的音频模型从音频文件中提取深度特征,然后将其用作节点信息来构建图。随后,我们训练了各种图神经网络(gnn),特别是图卷积网络(GCNs), GraphSAGE和图注意网络(GATs),以解决多类音频分类问题。我们的研究结果强调了使用图形来表示音频数据的有效性。此外,他们强调了gnn在声音分类方面的竞争表现,其中GAT模型表现最佳,在对环境声音进行分类方面达到了83%的平均准确率,在基于音频记录识别场地土地覆盖方面达到了91%的平均准确率。总之,这项研究为分析音频数据的图形表示学习技术的潜力提供了新的见解。
摘要
方法
结论
- Authors: AE Castro-Ospina, MA Solarte-Sanchez作者:AE Castro-Ospina、MA Solarte-Sanchez
- Summary: This study explores audio data representation as graphs using pre-trained audio models and graph neural networks for classification.摘要:本研究探索使用预先训练的音频模型和图神经网络进行分类,将音频数据表示为图形。
- Link: PDF链接:PDF
- Citations: [Not listed]引文:[未列出]
7. Graph Neural Network for Audio Representation Learning
用于音频表示学习的图神经网络
摘要
方法
结论
- Authors: A Shirian作者: 施里安
- Summary: This paper proposes graph neural network structures for audio representation learning and classification tasks.摘要:本文提出了用于音频表示学习和分类任务的图神经网络结构。
- Link: PDF链接:PDF
- Citations: [Not listed]引文:[未列出]
8.Graph-Based Representation of Audio Signals for Sound Event Classification
用于声音事件分类的基于图形的音频信号表示
摘要
方法
结论
- Authors: C Aironi, S Cornell, E Principi作者:C Aironi、S Cornell、E Principi
- Summary: This research develops graph-based representations for non-speech audio classification.摘要:本研究开发了用于非语音音频分类的基于图形的表示。
- Link: PDF链接:PDF
- Citations: 5 citations引用次数:5 次引用
9. Graph Neural Network for Music Score Data and Modeling Expressive Piano Performance
用于乐谱数据和富有表现力的钢琴演奏建模的图神经网络
摘要
方法
结论
- Authors: D Jeong, T Kwon, Y Kim, J Nam作者:D Jeong、T Kwon、Y Kim、J Nam
- Summary: This study addresses modeling expressive piano performance using graph neural networks.摘要:本研究致力于使用图神经网络对富有表现力的钢琴演奏进行建模。
- Link: PDF链接:PDF
- Citations: 56 citations引用次数:56 次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号