关于各类扫描器的前期调研工作
1 Zmap
架构的特点
Optimized probe
为了避免扫描发送的探针对发送方的网络和目的网络造成压力从而导致速率下降等不好的结果出现,本文的探针采用随机探针生成技术并且广泛散发的方法,即按照随机的顺序对全网目的地址进行扫描,相邻发送的探针数据包不一定被送至相同的网络。同时 ZMap 按照发送方 NIC 最大速率发送探针,并且跳过 TCP/IP 栈直接生成链路层的帧。
No per-connection state
Nmap 会对每一个连接维护一些状态来帮助程序确认哪些主机被扫描过以及是否需要重新发送。与之不同,ZMap 不保存任何连接的这些状态。首先在解决如何不重复不遗漏扫描全部需要扫描的主机问题上,ZMap主要使用了周期乘法生成地址的随机全排列。此外,ZMap 接受的响应数据包携带有一些状态字段,程序会从中提取尽可能多的有用信息帮助 ZMap 得到扫描结果。为了将探针导致的响应数据包从网络中的其他数据包识别分离出来,ZMap 会重载每一个发送的数据包中未被使用的值来做一些标识,这一点有点像 SYN cookies。
No retransmission
ZMap 总是针对每一个目标发送相同且固定的探针数据包(默认一个),并且不会像 Nmap 那样在超时后重新发送相同探针数据包。也就是说== ZMap 不会重新发送任何数据包,主要是避免维护一些不必要的状态==。放心,文章实验证明了即使在最大的扫描速率下只对每一个目标地址发送一个探针数据包也可以有效的扫描完 98% 的网络空间。
架构

- 蓝色 Packet Generation 和 Response Interpretation: 指出生成和处理多种探针数据包,包括 TCP SYN 扫描的和 ICMP echo 扫描的
- 红色 Output Handler:输出结果并且允许用户处理这些结果
- 设计思想:最重要的架构特点在于扫描过程和接受处理过程是在不同的线程完成的,彼此独立并且连续的进行
Addressing Probes
如果期望遍历 1-6 整数,但是又不想按照顺序去遍历,想使用随机的方法遍历这些整数,一种方法如图所示,即整数模 n 乘法群。
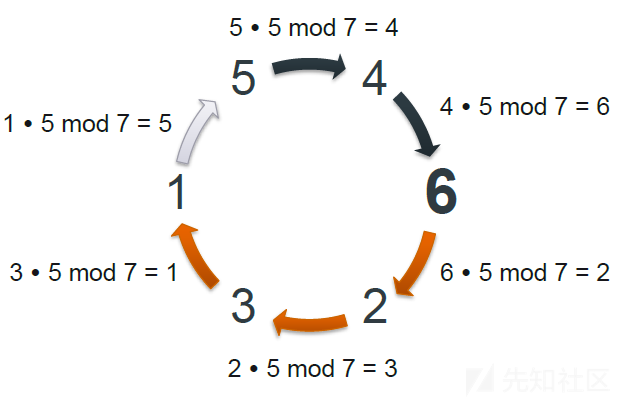
可以看到只要选定一个稍微大于需要遍历的序列最大数的奇质数\(n\)(论文用符号\(p\)表示,此处为 7),那么再选定一个需要遍历的数列其中一个元素 primitive root (此处为\(5\),选择其他的比如\(3\)也可以),通过相乘取余数可以生成数列的一个全排列。
应用在 IPv4 地址中,可以将 128bit 的 IPv4 地址空间看成一个\([1,2^{32}]\)的整数集合(128 位的二进制转换为 10 进制数),每一个整数对应 IPv4 的一个地址(0.0.0.0 地址对应的整数为 0,没有扫描的意义故排除)。然后论文选择了一个稍微大一些奇质数\(2^{32}+15\)作为 p,选择\(3\)作为 primitive root。这样可以用相同的数学原理得到\([1,2^{32}]\)整数的全排列,每一个整数转换位 128 位二进制即可得到 IPv4 地址。
Packet Transmission and Receipt
ZMap 被设计尽可能使用源主机的 CPU 和 NIC 能支持的最大发包速率去发送探针数据包 (probe)。程序直接在以太网层(即链路层,以太网协议是链路层很重要的一个协议)发送 raw packet,避免过多的内核层面的操作包括路由表查询、arp 缓存查询和 Netfilter 检验。这样链路层头部,包括校验码在整个扫描过程都不会变的,在内核中也不会建立任何 TCP session。
ZMap 的接受模块仍然使用libpcap,虽然这个库很多时候会成为性能的瓶颈,但是考虑到响应的数据包速率不会有发送的那么快,在论文的测试中也验证了这一个观点,所以使用 libpcap 是可行的。
在接收到数据包后,通过源端口和目的端口直接跳过那些明显不是响应我们扫描的数据,将剩下的数据包传送到 probe module 进一步解析。由于发送和接受主线程是独立的,在发送结束后接受线程仍然额外持续 8 秒。
Zmap的优势不是从超参数优化来的,更多的是系统设计的优化
2 Kscan🎈
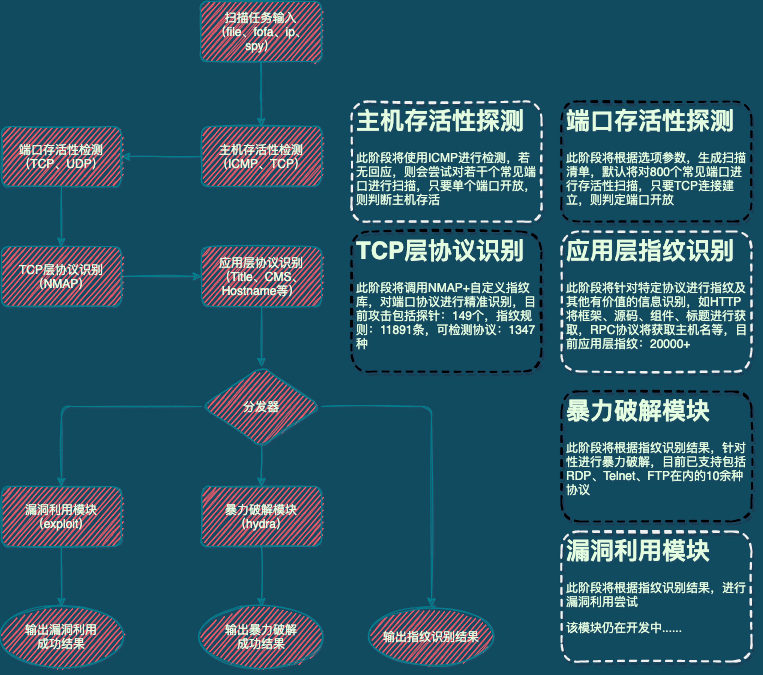
根据端口号与常见协议进行比对来确认端口协议,以端口为单位输出资产信息,比如端口协议为 HTTP,则会自动化进行后续的指纹识别、标题获取,端口协议为 RPC,则会尝试获取主机名等等。
3 Zscan
开源的内网端口扫描器、爆破工具和其他实用工具的集合体,可以称为工具包。它可以对内网网段发现、主机发现和端口扫描进行快速的探测和利用。使用 go 语言编写,利用 goroutine 实现高并发的端口扫描,使用 tcp connect scan 的方式尝试与目标主机建立连接,如果目标主机有回复则说明端口开放。
4 scanless
使用 Python 语言编写,调用第三方端口扫描服务的 API 来实现间接端口扫描。它支持多个在线端口扫描网站,如 ipfingerprints, spiderip, standingtech, viewdns, yougetsignal 等。使用 requests 库发送 HTTP 请求到指定的端口扫描网站,传递目标 ip 或域名作为参数,然后解析返回的 HTML 页面或 JSON 数据,提取出端口扫描的结果,并显示在终端上。优势是可以实现匿名的端口扫描,避免直接暴露自己的 IP 地址。它还可以使用随机或全部的端口扫描网站来增加扫描的准确性和覆盖率。
5 go-portScan
使用 go 语言编写,从 config.txt 文件中读取目的 ip 和端口,对指定的目的服务器进行端口扫描。config.txt 支持配置端口列表,默认为 22、36000、56000、3306。在服务器上连接目的服务器端口,仅做一次 TCP 三次握手。使用 net.DialTimeout 函数尝试与目标主机建立 TCP 连接,如果没有返回错误,则说明端口开放,否则说明端口关闭。它使用 goroutine 实现高并发的端口扫描,提高了扫描效率。
6 Naabu
一款基于 Go 语言开发,对主机/主机列表进行快速的 SYN/CONNECT/UDP 扫描,并列出所有返回了响应信息的端口。是使用 net 库提供的 Dialer 结构体来创建 TCP 或 UDP 连接,并设置超时时间和并发数。它还使用了rawsocket 库来实现 SYN 扫描,即只发送 SYN 包而不进行完整的 TCP 三次握手,从而提高扫描速度和效率。支持多种输入和输出格式,以及与 Nmap 的整合。
7 JFScan
基于 Masscan 和 Nmap 实现,旨在简化各种形式的端口扫描任务,并且能够接收 URL、域名或 IP(包括 CIDR)等形式的扫描目标。它还可以将扫描结果与 Nuclei 等工具进行整合,形成工具链。使用 Masscan 进行快速的端口探测,然后使用 Nmap 对开放的端口进行服务发现和指纹识别。它还可以使用 Nmap 的脚本功能来进行漏洞检测和其他操作。它使用 Python 语言编写。
8 Masscan🎈
一个互联网规模的端口扫描程序。可以在5分钟内扫描整个互联网,每秒从一台机器传输1000万个数据包。支持对多台计算机进行广泛扫描的功能,使用异步传输,允许任意端口和地址范围。比nmap这些扫描器更快,而且masscan更加灵活,它允许自定义任意的地址范围和端口范围。masscan 使用自己的TCP/IP 堆栈。
Masscan对每一块网卡建立一个异步处理的线程对,分别是发送数据包线程和接收数据包线程。系统启动后发送线程根据扫描任务,对任务范围内的所有的TP和PORT组成的目标地址进行随机化,组装数据包发送建立连接的请求。如果目标地址的探测端口打开就会返回响应数据包,这个返回数据包就由接收线程接收,接收线程解析收到的数据包。如果Masscan需要进行漏洞扫描,就需要在接收线程中,分配新的内存空间、组装并填充用于漏洞扫描的数据包,最后将组装好的探测数据包放到发送线程的发送队列中,发送线程及时将发送队列中的数据包发送出去。接收线程不负责发送数据包,只是将需要处理的数据包组装完毕,并放到发送线程的发送队列中由发送线程发送,工作流程如图3.2所示。
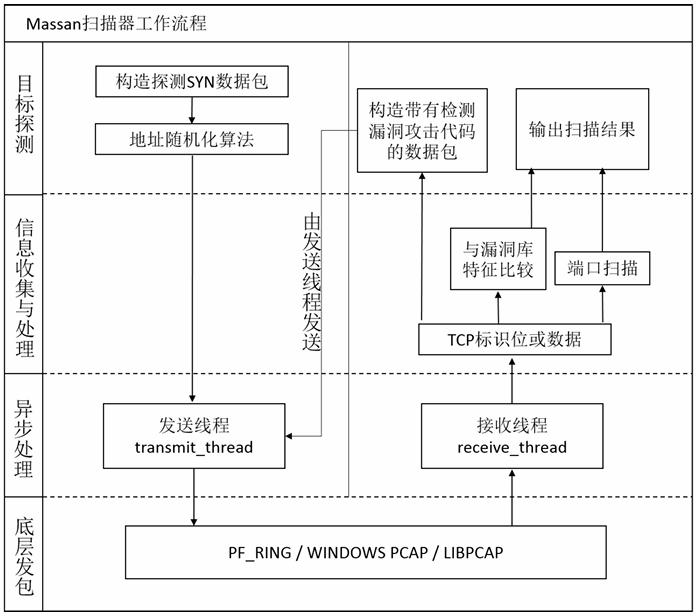
1)发送线程执行过程:
- 初始化本次扫描任务发送线程所需要的一些基本变量;
- 在线程内创建一个指向外部变量的指针,用于通知外部系统,线程内的发送数据包的具体数量及当前发送速度信息;
- 初始化本机器的源IP和源端口;
- 限制发送数据包的最大发送速度;
- 每一次扫描任务数量为本次扫描IP数乘以端口数的乘积,即NUMrp*NUMPoRT,确定本次扫描任务的数量;
- 根据扫描任务计算出本次扫描地址的上界和下界;
- 依次循环本次任务内的任务数量:
- 将对一个地址的扫描任务视为一次批处理,首先需要确认批处理中数据包的数量,一般端口扫描任务数量为1;
- 将接收队列内的所有数据包发送出去;
- 对目标地址进行随机化处理,取出扫描范围内的一个未扫描过的目标地址;
- 根据已存变量得到发送源的IP&PORT,还有本次发送数据包的cookie值,用于在接收线程中识别出是哪次发送得到的相应;
- 构造所需数据包,并发送该数据包探针;
- 检测是否有CTRL+C命令中止循环;
- 执行完本次任务后执行下一扫描范围循环;
- 将发送队列中的所有剩余数据包发送出去;
2)接收线程执行过程:
- 初始化本次扫描任务接收线程所需要的一些基本变量;
- 在线程内创建一个指向外部变量的指针,用于通知外部系统,线程内的接收数据包的具体数量及当前的接收速度信息;
- 将发送线程分配到偶数编号的CPU,将接收线程分配到奇数编号的CPU,实现了Masscan更好的异步操作﹔
- 打开一个pcap文件,用于接收原生数据包,并通过创建一个接收表对异步操作导致的重复响应,进行最优程度的去重,系统运行时只对相同地址的第一个进行响应;
- 如果为离线模式,等待发送线程结束后就关闭;6接收数据包部分,执行一个while死循环;
- 调用底层网卡接收数据包的函数,将收到的数据包通过发送线程相同的方法哈希得到接收包的cookie值;
- 检测是否是发往本机的数据包;
- 处理非TCP协议的数据包,如ARP、UDP、DNS、ICMP、STCP;
- 如果检测命令中记录了banner信息,则需要创建一个“TCPControl Block”对 TCP连接进行记录:
- 如果收到一个SYN-ACK数据包,说明目标主机在该端口打开了服务,紧接着建立一个维持连接的TCB连接控制块;
- 如果连接已经建立,说明需要处理一下其它的数据包,比如带有payloads的其他状态的数据包,例如ACK, FIN, RST;
- 处理一般端口扫描的SYN-ACK包或RST包,修改整个连接的状态位;
- 输出扫描结果、发送RST 数据包结束连接;
Masscan 在漏洞扫方面的局限性主要表现的问题是扩展性太差,每次若要检测新的漏洞都需要对 Masscan 的 banner 字段添加新的候选项,并添加相应的漏洞探测、检测结果判定等模块,还要对 Masscan 重新编译运行。
https://xueshu.baidu.com/usercenter/paper/show?paperid=a55991998968a29c7198fa87782ab47b
9 Rustscan🎈
https://mp.weixin.qq.com/s/-dVXxYV4qlt9YJNh60dtWw
https://github.com/RustScan/RustScan
基于 Rust 语言开发,可以在 3 秒内扫描所有 65k 个端口,并且支持脚本引擎,可以自动将结果通过管道传输到 Nmap 或者执行其他操作。使用 Rust 的标准库中的 net 模块来创建 TCP 套接字,并设置超时时间和并发数。使用 SYN 扫描的方式,即只发送 SYN 包而不进行完整的 TCP 三次握手,从而提高扫描速度和效率。可以自适应学习,根据网络环境和目标主机的响应情况,动态调整扫描参数,例如超时时间(timeout)、并发数(batch size)和重试次数(tries)。这样可以避免因为参数设置不合理而导致的扫描失败或者效率低下。
Rustscan的自适应参数调整的逻辑主要在 src/scanner/mod.rs 文件中。其中有以下几个函数或者结构体与之相关:
Scanner:结构体(struct)定义了 Rustscan 的扫描器类型,包含了一些属性,例如 ips, batch_size, timeout, tries 等。它也实现了一些方法(method),例如 new, run, scan_socket, connect 等。
Scanner::run:这是一个方法,它用于运行端口扫描,并返回一个包含所有开放端口的 SocketAddr 类型的向量(vector)。它使用了一些异步编程(async programming)的特性,例如 FuturesUnordered 和 await 关键字,来提高扫描效率和并发性。
Scanner::scan_socket:这也是一个方法,它用于给定一个 SocketAddr 类型的值,也就是一个 IP 地址和端口号的组合,对其进行多次扫描,并返回一个 io::Result 类型的值,也就是一个表示成功或失败的枚举(enum)。如果成功,表示端口开放,返回 SocketAddr 值;如果失败,表示端口关闭或者出现错误,返回错误信息。
Scanner::connect:这也是一个方法,它用于给定一个 SocketAddr 类型的值,尝试与其建立 TCP 连接,并返回一个 io::Result 类型的值。如果成功,表示连接建立,返回 TcpStream 值;如果失败,表示连接超时或者出现错误,返回错误信息。
10 TXPortMap🎈
采用 Golang 编写,可以快速扫描常用的端口或者指定的端口,并且对 http/https 协议进行 title 和报文长度的打印。使用 Golang 的标准库中的 net 模块来创建 TCP 套接字,并设置超时时间和并发数。它使用 SYN 扫描的方式,即只发送 SYN 包而不进行完整的 TCP 三次握手,从而提高扫描速度和效率。它还使用自己开发的指纹库来识别开放端口上的服务。
Paper:Research on the Speed and Accuracy of Full Port Scanning
介绍
端口扫描有多种类型,其中最常用的是全端口扫描,即对目标系统的所有端口进行扫描,以获取最完整的端口信息。然而,由于端口数量庞大,全端口扫描需要消耗大量的时间和资源,这对于渗透测试者来说是不可接受的。为了解决这个问题,本文提出了一种基于抽样的全端口扫描方法,该方法可以在保持扫描准确性的同时,最小化扫描成本。本文的主要贡献如下:
- 提出了一种基于端口使用频率和安全等级的端口分类方法,将端口划分为不同的类别,并给出了每个类别的抽样比例。
- 设计了一种基于随机抽样的全端口扫描算法,对每个类别的端口进行抽样,并根据抽样结果和抽样比例,推断出全端口的开放情况。
- 使用三种常用的端口扫描工具,在受控环境下进行了实验验证,并对不同场景下不同扫描器的扫描准确性和扫描速度进行了定量分析。
- 根据实验结果,给出了不同环境下使用不同扫描器的参数设置。
本文的方法分为两个步骤:端口分类和端口抽样。端口分类是根据端口的使用频率和安全等级,将端口划分为不同的类别,并给出每个类别的抽样比例。端口抽样是对每个类别的端口进行随机抽样,并根据抽样结果和抽样比例,推断出全端口的开放情况。
- 端口分类的目的是为了平衡扫描准确性和扫描速度,即对于重要的端口,需要高抽样比例,以保证扫描准确性;对于不重要的端口,可以低抽样比例,以提高扫描速度。本文参考了RFC 6335和IANA的端口分配规则,将端口划分为四个类别:常用端口、中等端口、不常用端口和保留端口。具体的端口范围和抽样比例如表1所示。
- 端口抽样的目的是为了减少扫描成本,即对于每个类别的端口,只需要扫描一部分,就可以推断出整个类别的端口开放情况。本文采用了一种基于随机抽样的全端口扫描算法,其流程如图1所示。该算法的输入是目标系统的IP地址和每个类别的端口范围和抽样比例,输出是全端口的开放情况。
扫描策略
基于抽样算法的全端口扫描方法总体流程如下:(1) 根据预设的抽样率p,从全端口中抽取一些端口,形成集合Sp,并验证集合Sp中的端口是否开放。(2) 从剩余的端口中重复步骤(1)的方法,进行T次抽样和验证。实验证明,在我们事先知道开放端口的大小时,对于指定的抽样率,迭代T轮就可以在不进行全端口扫描的情况下,挖掘出开放端口。
- 水库抽样:在本文利用水库抽样算法来实现端口抽样。水库抽样是一种在未知长度的数据流中,在只能访问一次的条件下,使数据流中的所有数据都以相等的概率被选中的随机抽样方法。如算法1所示,选择策略是在取第i个数据时,从0到n生成一个随机数p,如果p小于k,就用第i个数替换池中的任意一个数;如果p大于或等于k,就继续保持之前的数。直到数据流结束,返回这k个数。通过水库抽样方法,可以在O(n)的时间复杂度和O(1)的空间复杂度下,实现数据流中的等概率抽样。

- 基于抽样的全端口扫描算法:在已知开放端口的规模的前提下,从待扫描的全端口数中,以概率p抽取一定数量的端口进行扫描,通过迭代执行T轮,可以在不扫描全端口数的情况下,挖掘出开放端口。本文中,我们首先根据端口总数设定抽样率,通过实验模拟确定迭代轮数T,然后按照算法2所示的步骤进行端口扫描。具体地,先将待扫描的剩余端口集合\(S_{remain}\)和开放端口集合\(S_o\)分别初始化为全端口集合和空集合。然后,在T轮迭代中,根据算法1从\(S_{remain}\)中随机选择k个端口,加入到集合\(S_s\)中,并扫描它们是否开放,根据扫描结果更新\(S_o\),并更新待扫描的剩余端口集合\(S_{remain}\)。最后,在T轮迭代结束时,得到系统中的开放端口集合。

实验
- 实验设置
为了比较三种工具的扫描速度和准确性,分别测试了局域网和互联网段的单个IP和C段作为扫描测试目标。为了测试工具的准确性,事先用工具确定了存活主机和开放端口的数量,以便后续测试和比较。端口扫描工具和测试目标分别如表1和表2所示。


对于扫描过程中网络段主机存活可能发生变化的情况,使用不同的工具进行扫描时,都事先进行了存活主机检测。
- 单个IP的全端口扫描测试
实验设置如下:测试IP1(局域网):172.*.*.*,开放端口数:28。然后根据本文提出的方法,使用三种端口扫描工具对这种场景的端口进行扫描,扫描结果分别如表3、表4和表5所示。Nmap扫描速度较慢,将消息超时响应时间调整为最小5ms,耗时159秒。
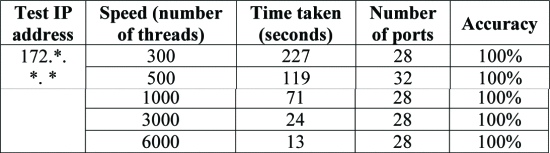
表3可以看出,当线程数等于6000时,剑皇高速端口扫描工具耗时最少,只有13秒。当线程数等于300时,耗时比线程数等于6000时长约17倍。当线程数等于300时,耗时比线程数等于1000时长约3倍。所以,从开销的角度来看,选择线程数等于1000是合理的。
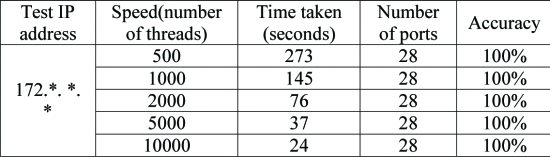
从表4可以看出,当线程数等于10000时,masscan耗时最少,只有24秒。当线程数等于500时,耗时比线程数等于10000时长约11倍。当线程数等于500时,耗时比线程数等于1000时长约2倍。当线程数等于500时,耗时比线程数等于2000时长约3.5倍。所以,从开销的角度来看,选择线程数等于2000是合理的。
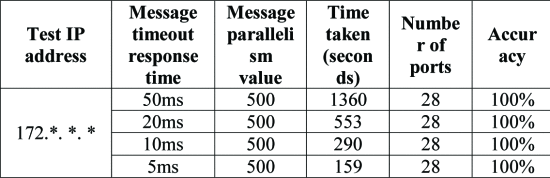
从表5可以看出,当Nmap的消息超时响应时间等于50ms时,耗时为1360秒。与消息超时响应时间等于20ms相比,耗时是50ms的2.5倍。因此,从成本的角度来看,选择消息超时响应时间等于20ms是合理的。
总结
剑皇高速端口扫描工具在扫描速度和扫描准确性的综合排名中位居第一。将线程数设置在500以内,扫描基本准确,不会丢失开放端口数据,同时速度也达到最快,扫描可以与masscan媲美。但是,如果将线程数设置过高,会导致局域网网络瘫痪。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号