Web指纹识别总结
学术:关于指纹识别国外的基本上是没有继续研究了,所有的公开论文都是十多年前的了。国内的论文倒是有几篇,但是都不提供开源代码
业界:业内的几款明星软件,都是拼的指纹库和扫描速度
ObserverWard 2023
源码:https://github.com/0x727/ObserverWard
主页:https://0x727.github.io/ObserverWard/
指纹库:https://github.com/gintian/FingerprintHub
结构体What_Web定义fingerprint(存储指纹库)和config(web请求配置)。
指纹库信息为WebFingerPrintLib,该结构将指纹分成首页识别,特殊请求识别和favicon的哈希识别,存储具体的识别字段。
pub async fn what_web( //核心匹配原理
raw_data: Arc<RawData>,
fingerprint: &V3WebFingerPrint,
is_favicon: bool,
debug: bool,
) -> (bool, &V3WebFingerPrint) {
let mut default_result = (false, fingerprint);
if is_favicon { //1 如果raw_data中的favicon字段信息
let mut hash_set = HashSet::new();
for (_key, value) in raw_data.favicon.iter() {
hash_set.insert(value);
}
let mut fph_set = HashSet::new();
for fph in fingerprint.match_rules.favicon_hash.iter() {
fph_set.insert(fph);
}
if hash_set.intersection(&fph_set).count() == 0 { // 统计交集
return default_result;
}
} else {
if fingerprint.match_rules.status_code != 0
&& raw_data.status_code.as_u16() != fingerprint.match_rules.status_code //2 web访问异常,不匹配跳出
{
return default_result;
}
for (k, v) in &fingerprint.match_rules.headers {
let matcher_part = header_to_string(&raw_data.headers);
if k == "set-cookie" && !matcher_part.contains(v) {
return default_result;
}
if raw_data.headers.contains_key(k) {
let is_match = matcher_part.to_lowercase().find(&v.to_lowercase());
if is_match == None && v != "*" {
return default_result;
}
} else {
return default_result;
}
}
for keyword in &fingerprint.match_rules.keyword {
if raw_data.text.find(&keyword.to_lowercase()) == None {
return default_result;
}
}
}
default_result.0 = true;
if debug {
println!("Matching fingerprint{:#?}", fingerprint);
}
default_result
}
Finger 2023
接通过url响应结果获取详情如下:title、server、faviconhash、iscdn、iplist(ip地址地址归属) datas(fofa、quake等第三方检索结果),最后输出结果,支持json和xls格式;

规则显示匹配方法包括keyword和faviconhash,keyword的匹配通过关键字匹配实现,不支持正则表达式;faviconhash即计算网站的icon值来标示网站页面的特征,通过faviconhash可检索出所有一样icon的页面。

{
"cms": "Shiro",
"method": "keyword",
"location": "header",
"keyword": ["rememberMe="]
}, {
"cms": "Shiro",
"method": "keyword",
"location": "header",
"keyword": ["=deleteMe"]
}, {
"cms": "slack-instance",
"method": "faviconhash",
"location": "body",
"keyword": ["99395752"]
}
Wappalyzer 2023
主页:https://www.wappalyzer.com/
源码:https://github.com/wappalyzer/wappalyzer
https://github.com/wappalyzer/wappalyzer
基于正则表达式来识别web应用,它的功能是识别单个url的指纹,其原理就是给指定URI发送HTTP请求,获取响应头与响应体并按指纹规则进行匹配。
这段代码定义了一个名为 _has_technology 的函数,它接受两个参数:technology 和 webpage。这个函数的目的是确定网页是否与技术签名匹配。函数首先定义了一个局部变量 app,并将其值设置为 technology。然后定义了一个布尔变量 has_app,并将其初始值设置为 False。
接下来,函数通过多个循环来检查网页的各个部分(如 URL、headers、scripts、meta 和 html)是否与技术签名匹配。如果匹配,则调用 _set_detected_app 函数,并将 has_app 设置为 True。如果 has_app 为 True,则会计算技术签名的总置信度。这是通过遍历 app['confidence'] 字典中的所有值并将它们相加来实现的。最后,将总和存储在 app['confidenceTotal'] 中。
上匹配,匹配的越多可信度越高
def _has_technology(self, technology, webpage):
"""
Determine whether the web page matches the technology signature.
"""
app = technology
has_app = False
# Search the easiest things first and save the full-text search of the
# HTML for last
for pattern in app['url']:
if pattern['regex'].search(webpage.url):
self._set_detected_app(app, 'url', pattern, webpage.url)
for name, pattern in list(app['headers'].items()):
if name in webpage.headers:
content = webpage.headers[name]
if pattern['regex'].search(content):
self._set_detected_app(app, 'headers', pattern, content, name)
has_app = True
for pattern in technology['scripts']:
for script in webpage.scripts:
if pattern['regex'].search(script):
self._set_detected_app(app, 'scripts', pattern, script)
has_app = True
for name, pattern in list(technology['meta'].items()):
if name in webpage.meta:
content = webpage.meta[name]
if pattern['regex'].search(content):
self._set_detected_app(app, 'meta', pattern, content, name)
has_app = True
for pattern in app['html']:
if pattern['regex'].search(webpage.html):
self._set_detected_app(app, 'html', pattern, webpage.html)
has_app = True
# Set total confidence
if has_app:
total = 0
for index in app['confidence']:
total += app['confidence'][index]
app['confidenceTotal'] = total
return has_app
这段代码定义了一个名为 _set_detected_app 的函数,它接受五个参数:app、app_type、pattern、value 和 key。这个函数的目的是存储检测到的应用程序。函数首先将 app['detected'] 设置为 True,表示应用程序已被检测到。接下来,函数设置置信度水平。如果 key 不为空,则在其后面添加一个空格。如果 app['confidence'] 不存在,则创建一个空字典。如果 pattern['confidence'] 不存在,则将其设置为 100。否则,将其转换为整数以便于后续计算。然后,将置信度存储在 app['confidence'] 字典中。
接下来,函数检测版本号。如果 pattern['version'] 存在,则使用正则表达式在 value 中查找所有匹配项。对于每个匹配项,函数使用三元运算符和反向引用来替换版本字符串中的占位符。如果版本字符串不为空,则将其存储在 app['versions'] 列表中。最后,函数调用 _set_app_version 函数来设置应用程序的版本。
def _set_detected_app(self, app, app_type, pattern, value, key=''):
"""
Store detected app.
"""
app['detected'] = True
# Set confidence level
if key != '':
key += ' '
if 'confidence' not in app:
app['confidence'] = {}
if 'confidence' not in pattern:
pattern['confidence'] = 100
else:
# Convert to int for easy adding later
pattern['confidence'] = int(pattern['confidence'])
app['confidence'][app_type + ' ' + key + pattern['string']] = pattern['confidence']
# Dectect version number
if 'version' in pattern:
allmatches = re.findall(pattern['regex'], value)
for i, matches in enumerate(allmatches):
version = pattern['version']
# Check for a string to avoid enumerating the string
if isinstance(matches, str):
matches = [(matches)]
for index, match in enumerate(matches):
# Parse ternary operator
ternary = re.search(re.compile('\\\\' + str(index + 1) + '\\?([^:]+):(.*)$', re.I), version)
if ternary and len(ternary.groups()) == 2 and ternary.group(1) is not None and ternary.group(2) is not None:
version = version.replace(ternary.group(0), ternary.group(1) if match != ''
else ternary.group(2))
# Replace back references
version = version.replace('\\' + str(index + 1), match)
if version != '':
if 'versions' not in app:
app['versions'] = [version]
elif version not in app['versions']:
app['versions'].append(version)
self._set_app_version(app)
WhatWeb 2022
主页:http://morningstarsecurity.com/research/whatweb
源码:https://github.com/urbanadventurer/whatweb
- 谷歌 dork 检查
- 正则表达式模式匹配
- 文件存在检查器
- 基于文件名的文件内容检查器
- 基于 Md5 的匹配
主函数部分

输入指令之后,会在whatweb文件比对指令信息。根据判断条件进行检测插件的选择。如果没有指定自定义插件,那么就加载默认插件,use_custom_plugin=false; plugin_selection=nil。

此时会调用lib/plugins.rb文件,调用PluginSupport.load_plugins函数,PluginSupport.precompile_regular_expressions是一个优化插件的函数,对插件识别脚本进行进一步细化。


接下来为处理指定的URL,获取指纹信息。run_plugins() 指纹匹配和判断

lib部分
plugins.rb中定义了一个 ScanContext类,用来执行插件扫描的上下文,包含了一些属性和方法,如target, body, headers, status, base_uri, md5sum等。
ScanContext.make_matches方法:根据插件的匹配规则和搜索位置,从目标网站中提取信息,并返回一个结果数组。
-
首先,初始化一个空数组 r 作为结果数组。
-
然后,根据 match 对象中的
:search属性,确定搜索的位置(search_context)。如果没有:search属性,就默认搜索 target 的 body。如果有:search属性,就根据其值选择不同的位置,如all表示搜索 target 的 raw_response,uri.path表示搜索 target 的 uri.path,headers表示搜索 target 的 raw_headers,headers[xxx]表示搜索 target 的 headers 中的 xxx 字段等。

- 接着,根据 match 对象中的其他属性,进行不同的匹配方式,并将匹配成功的 match 对象添加到结果数组 r 中。例如,如果 match 有 :ghdb 属性,就调用 match_ghdb 方法进行谷歌黑客数据库的匹配(函数源码);如果 match 有 :text 属性,就用其对应的正则表达式(:regexp_compiled)进行文本匹配;如果 match 有 :md5 属性,就比较其值和 target 的 md5sum 是否相等;如果 match 有 :tagpattern 属性,就比较其值和 target 的 tag_pattern 是否相等等。

- 最后,如果 match 有 :regexp_compiled 属性,并且有搜索位置(search_context),就遍历以下几个属性:[:regexp, :account, :version, :os, :module, :model, :string, :firmware, :filepath]。对于每个属性,如果 match 也有该属性,并且该属性是一个正则表达式,就用该正则表达式在搜索位置中扫描,并将扫描到的结果赋值给该属性,并添加到结果数组 r 中。如果扫描到的结果是一个数组,并且 match 有 :offset 属性,就取结果数组中的第 offset 个元素作为结果。如果没有 :offset 属性,就取结果数组中的第一个元素作为结果。最后对结果进行去重和排序。

ScanContext.x 方法,它是用来执行插件的主要逻辑,包括调用 passive_scan 和 aggressive_scan 方法(如果存在),以及处理 url 和 status 的匹配(如果存在)。
特点
基于 Ruby 开发的网络指纹识别软件,使用命令参数自定义探测过程,插件多。WhatWeb 在从目标 URL 链接的页面(或递归模式下的多个页面)中搜索错误模式。一些 WhatWeb 插件还使用目标应用程序中已知的信息泄露漏洞提取本地文件路径。WhatWeb 的主要目的是尽可能多地识别应用程序,而不管版本信息。
WhatWeb可以识别的内容有CMS、博客平台、statistic/analytics 包、JavaScript 库、Web 服务器和嵌入式设备。还可以识别版本号、电子邮件地址、帐户 ID、Web 框架模块、SQL 错误等。
httprint 2022
主页:https://net-square.com/httprint.html
论文:https://net-square.com/httprint_paper.html
httprint是一个利用响应中的微小差别进行指纹识别的技术,通过运用统计学原理和模糊逻辑技术,能很有效的确定Http服务器的类型。它用一组存储的签名进行签名分析,并给每个候选签名分配一个信任等级。具有最高信任度的签名被认为与被测试的未知服务器的匹配。
前提假设: 指纹识别引擎使用一组已知的服务器签名进行操作。因此,只能识别它所知道的HTTP服务器。如果一个服务器的签名没有出现在已知的签名集中,指纹识别引擎将报告行为和特征方面最接近的识别结果。在进行HTTP指纹测试时,系统和目标网络服务器之间不应有HTTP代理服务器。

术语和定义
| Term | Description |
|---|---|
| Signature Set 签名集 | \(S =\{s_1, s_2, ..., s_n\}\) n = 指纹识别引擎已知的 Web 服务器签名数。 $ s_i$ = 签名集中的 第 \(i^ {th}\)个签名。 |
| Reported Signature 报告的签名 | $s_R $通过对未知 Web 服务器运行 HTTP 指纹测试而得到的签名。 |
| Comparision function and Weight 比较功能和权重 | \(w_i=fw(s_R, s_i)\) \(w_i\) = 将报告的签名\(s_R\) 与签名集 S 中的第\(i^ {th}\)个签名进行比较时的权重。 $ fw(s_a,s_b)$ = 比较函数,将签名$ s_a$ 与 \(s_b\) 进行比较,并返回结果权重。 |
| Weight Vector 权重向量 | \(W=\{w_1, w_2, ..., w_n\}\) |
| Confidence Rating 置信度 | \(c_i=fc(w_i, W)\) \(c_i\)=权重为\(w_i\)的签名$s_i $是整个签名集S中最佳匹配的可能性,其权重向量由 W 表示。 \(fc(w_a,W)\) = 模糊逻辑函数,以百分比形式计算 \(w_a\) 是权重向量 W 中最佳权重的可能性。 |
| Confidence Vector 置信度向量 | \(C = \{c_1, c_2, ..., c_n\}\) |
| Max Confidence 最大置信度 | \(c_{max}\) 置信向量C中最大的置信度。 |
| Best match Vector 最佳匹配向量 | \(M = \{s_{maxA}, s_{maxB}, ...\}\) \(s_{maxA}, s_{maxB}\) = 置信度等于 \(c_{max}\) 的签名 |
分析逻辑
以下一段伪代码概述了如何从签名集中选择最佳匹配。
- Load the signature set \(S = \{s_1, ..., s_n\}\) # 加载签名集
- Run the fingerprinting tests and obtain \(s_R\) for the unknown web server. #运行指纹测试并获取未知Web的\(s_R\)。
- for i = 1 ... n
\(w_i = fw(s_R, s_i)\) # 比较\(s_R\)与签名集中的每一个元素,返回结果权重\(w_i\)
next- for i = 1 .. n
\(c_i = fc(w_i, W)\) # 计算\(w_i\)有百分之几的可能性是\(W\)集合中的最佳权重,返回每一个\(w_i\)对应的置信度
next- \(c_{max}=max(C)\)
- M = {}
- for i = 1 ... n
if \(c_i = c_{max}\) then # 如果\(c_i = c_{max}\)
\(M = MU\{s_i\}\)
end if
next- print M
特点
httprint不提供开源的代码和算法信息。会自动将计算Http指纹信息保存在一个文档里,当发现那些没有在数据库中的指纹信息时,需要手动将Http指纹信息加入指纹数据库。httprint的缺陷是只适用于识别服务器和容器的信息,对cms应用等信息没有办法精确精确识别。
TideFinger 2021
主页:https://github.com/TideSec/TideFinger/blob/master/Web指纹识别技术研究与优化实现.md
源码:https://github.com/TideSec/TideFinger
先用fofa+Wappalyzer去匹配,获取一定banner

如果banner中识别除了cms,则返回结果,如果未识别到cms,则会调用cms规则库进行匹配各规则。

TideFinger.py
Cmsscanner:一个用于扫描网站指纹的类,它定义了以下方法:
__init__(self, url): 构造函数,接受一个url参数,初始化一些属性,如url、headers、proxies等。get_info(self): request获取网站的基本信息,如title、server、powered by等,并返回一个字典。check_rule(self, rule): 根据给定的正则规则,检查网站是否匹配该正则规则,返回True或False。规则是一个字典,包含title、header、body三个键,分别对应网页的标题、响应头、响应体的特征。
WhatCms用于调用whatcms.org的API来识别网站指纹的类,它定义了以下方法:
__init__(self, url): 构造函数,接受一个url参数,初始化一些属性,如url、api_url、api_key等。request_url(self): 发送请求到whatcms.org的API,获取返回的json数据,并返回一个字典。normalize_target(self): 对目标url进行规范化,去除http或https前缀,去除末尾的斜杠,返回一个字符串。find_powered_by(self): 从网站的响应头中查找X-Powered-By字段,如果存在,则返回该字段的值,否则返回空字符串。find_cms_with_file(self): 从网站的根目录下查找一些常见的CMS相关文件,如readme.txt, license.txt等,如果找到,则返回文件名和文件内容的摘要,否则返回空字符串。start_threads(self): 启动两个线程,分别调用find_powered_by和find_cms_with_file方法,并将结果保存到self.powered_by和self.cms_file属性中。run(self): 主方法,调用normalize_target方法,打印目标url,调用request_url方法,打印API返回的结果,调用start_threads方法,打印线程返回的结果。get_result(self): 返回一个字典,包含目标url、API返回的结果、线程返回的结果等信息。
未知指纹发现
从网站中爬取一些静态文件,如png、ico、jpg、css、js等,提取url地址、文件名、计算md5写入数据库,再爬下一个网站,一旦发现有相同的md5,就把新的url也加入到那条记录中,并把hint值加1,这样爬取10W个站点后,就能得到一个比较客观的不同网站使用相同md5文件的数据了。
excludeext = ['.png', '.ico', '.gif','.svg', '.jpeg','js','css','xml','txt']
def getPageLinks(url):
try:
headers = requests_headers()
content = requests.get(url, timeout=5, headers=headers, verify=False).text.encode('utf-8')
links = []
tags = ['a', 'A', 'link', 'script', 'area', 'iframe', 'form'] # img
tos = ['href', 'src', 'action']
if url[-1:] == '/':
url = url[:-1]
try:
for tag in tags:
for to in tos:
link1 = re.findall(r'<%s.*?%s="(.*?)"' % (tag, to), str(content))
link2 = re.findall(r'<%s.*?%s=\'(.*?)\'' % (tag, to), str(content))
for i in link1:
links.append(i)
for i in link2:
if i not in links:
links.append(i)
except Exception, e:
print e
print '[!] Get link error'
pass
return links
except:
return []

特点
简易,提取了多个开源指纹识别工具的规则库并进行了规则重组
BlindElephant 2017
主页:https://blindelephant.sourceforge.net/
源码:https://sourceforge.net/p/blindelephant/code/HEAD/tree/trunk/src/blindelephant/DifferencesTables.py#l41
https://sourceforge.net/p/blindelephant/code/HEAD/tree/trunk/src/blindelephant/Fingerprinters.py#l264
工作原理是基于静态文件校验的版本差异。运行BlindElephant的人需要获得源代码来映射所有静态文件指纹。
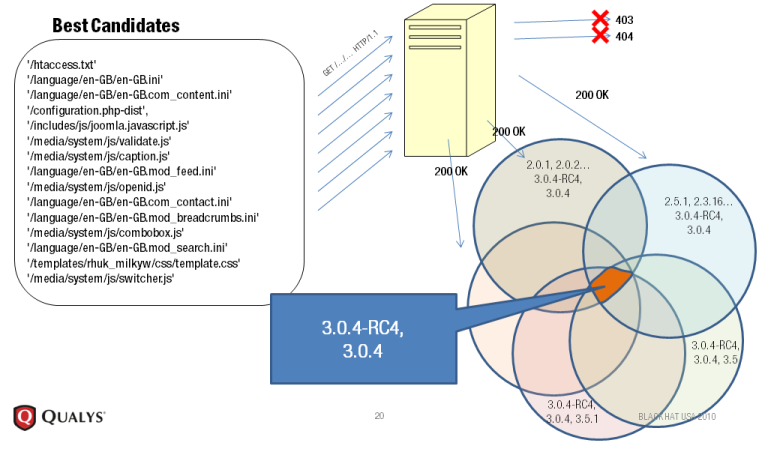
通过将已知位置的静态文件与所有可用版本中这些文件版本的预先计算哈希进行比较来发现(已知)Web 应用程序的版本。
computeTables
遍历版本目录(basepath中与versionDirectoryRegex匹配的所有目录)并计算所有文件的哈希值,然后使用这些哈希值,创建并返回pathNodes和versionNodes元组:(pathNodes, versionNodes, versions)

basepath是解包应用的根目录(等同于前端扫描器指向的应用根目录)versionDirectoryRegex捕获用于哈希和报告的版本号directoryExcludeRegex和fileExcludeRegex用于删除不应该用于指纹识别的项目(因为它们通常不可读,经常更改/不可靠,无论什么)pathNodes是一个由path索引的字典,并包含一个由(文件+路径)哈希到该哈希所隐含的LooseVersions列表的字典。
Fingerprinters
https://github.com/lokifer/BlindElephant/blob/master/src/blindelephant/Fingerprinters.py
用于实现WebAppFingerprinter和PluginFingerprinter两个类,它们可以用盲象指纹数据库来识别一个网站上安装的web应用程序和插件的版本。它还实现了WebAppGuesser和PluginGuesser两个类,它们可以用少量的指示文件来快速检测一个网站上是否存在某个web应用程序或插件,但不确定版本。它使用了一些其他模块,如DifferencesTables, Configuration, FileMassagers和FingerprintUtils,以及一些标准库,如urllib2, hashlib, itertools等。它定义了一些常量,如HOST_DOWN_THRESHOLD,表示在放弃之前可以容忍的低级通信失败的次数。它还定义了一些方法,如_load_db, fingerprint, fingerprint_file, winnow_versions等,来执行不同的指纹识别任务。
特点
技术快速、低带宽、非侵入性、通用且高度自动化。
先决条件:Python 2.6.x(首选 2.6.5);早期版本的用户可能难以安装或运行BlindElephant。
w3af 2015
主页:http://w3af.org/blog http://docs.w3af.org/en/latest/
源码:https://github.com/andresriancho/w3af https://github.com/andresriancho/w3af/tree/master/w3af/plugins/infrastructure
w3af是一个Web应用程序攻击和审计框架,它旨在识别和利用所有的Web应用程序漏洞。它通过增加插件来对功能进行扩展,支持图形用户界面(GUI)和命令行模式。
特点
w3af框架中共有九大类近150个插件,每个插件都被包含在模块中。这些模块包括:Audit类的插件,用于完成所有的扫描及发现漏洞的操作;Infrastructure类的插件,用于扫描目标服务器的基础架构信息;Grep类的插件,类似于被动扫描,根据已有请求去发现一些可能存在的漏洞;Evasion类的插件,用来逃避IDS、IPS以及WAF的检测功能;Mangle类的插件,基于正则表达式去修改请求和响应;Broutforce类的插件,在爬取阶段进行暴力登陆;Output类的插件,将数据保存到文本、xml或html文件中;Crawl类的插件,通过爬取网站站点来获得新的URL地址;Attack类的插件,如果Audit插件发现了漏洞,Attack将会进行攻击。
inspathx 2012
主页:https://code.google.com/archive/p/inspathx/
源码:https://github.com/emilyanncr/inspathx
一种使用本地源代码树向 url 发出请求并搜索路径包含错误消息的工具。
Qualys web 2023
主页:Qualys Security Blog --- 使用 Qualys Web 应用程序扫描对 Web 应用程序和 API 进行指纹识别 | Qualys 安全博客

总结评价
- https://github.com/urbanadventurer/WhatWeb/wiki/Related-Projects
- 网页应用指纹 |阿南特·什里瓦斯塔瓦 (anantshri.info)
当前自动化工具设计的先天缺陷:
- 所有工具都在假设下工作,且交叉验证自己的机会非常小。
他们假设:文件名 X 表示 Z 插件或者站点中的Q文件夹表示使用软件,而不管实际产品的使用情况如何;设计的工具是非常可靠的(盲象除外,它给出了概率)- 过度自信是危险的。这些工具为我们提供了结果,每个人都需要明白,自动化解决方案也可能被愚弄。因此,这些工具在提供输出方面也应该是非权威的。
- 他们声称是动态的,但在很大程度上仍然保持静态(动态仅在替换前端域名方面)。
观察每个扫描解决方案的讨论,会发现全都是静态路径或者依赖于静态的文件名。即使基于校验和的方法,也无法消除上述两个限制,并且在此方法中还存在根本性问题,例如:“比较已知位置的静态文件”,已知位置并不总是相同的,例如在WordPress中,可以更改wp-content文件夹的位置,并且在将来还将能够更改其他文件夹的位置(即wp-admin,wp-include)。预先计算的哈希值,并不考虑用户是否会对文件进行操作
新工具的方法:现在的工具过于依赖正则表达式,因此很容易被提供的虚假文本或类似格式所击败。解析引擎应该更加智能,应该查看实际内容而不是整个文本。另一种可部署的方法是,我们应该有实际的差异和加权分数来验证差异,但这将是一种资源密集型的方法,但可能会产生一些好的结果,但问题在于版本识别。
交叉参考其他技术和在工具中使用人类常识:我们应该始终交叉参考其他输入,例如检测到Apache服务器并带有aspx扩展名,我们通过所有自动检查发现“SharePoint服务器”存在。这对人类思维来说似乎不正确。类似的方法应嵌入到自动化工具的逻辑部分中。每个框架在实现各种协议时都提供了微妙的提示,类似于http指纹识别[2],该方法也可用于检测特定应用程序的存在。这样的实现示例可能是RSS / ATOM,XMLRPC。



常见的指纹识别方式:
1. 特定文件的md5: 一些网站的特定图片文件、js文件、CSS等静态文件,如favicon.ico、css、logo.ico、js等文件一般不会修改,通过爬虫对这些文件进行抓取并比对md5值,如果和规则库中的Md5一致则说明是同一CMS。这种方式速度比较快,误报率相对低一些,但也不排除有些二次开发的CMS会修改这些文件。
2. 正常页面或错误网页中包含的关键字: 先访问首页或特定页面如robots.txt等,通过正则的方式去匹配某些关键字,如Powered by Discuz、dedecms等。或者可以构造错误页面,根据报错信息来判断使用的CMS或者中间件信息,比较常见的如tomcat的报错页面。
3. 请求头信息的关键字匹配: 根据网站response返回头信息进行关键字匹配,whatweb和Wappalyzer就是通过banner信息来快速识别指纹,之前fofa的web指纹库很多都是使用的这种方法,效率非常高,基本请求一次就可以,但搜集这些规则可能会耗时很长。而且这些banner信息有些很容易被改掉。根据response header一般有以下几种识别方式:
- 查看http响应报头的X-Powered-By字段来识别;
- 根据Cookies来进行判断,比如一些waf会在返回头中包含一些信息,如360wzws、Safedog、yunsuo等;
- 根据header中的Server信息来判断,如DVRDVS-Webs、yunjiasu-nginx、Mod_Security、nginx-wallarm等;
- 根据WWW-Authenticate进行判断,一些路由交换设备可能存在这个字段,如NETCORE、huawei、h3c等设备。
4. 部分URL中包含的关键字: 比如wp-includes、dede等URL关键特征:通过规则库去探测是否有相应目录,或者根据爬虫结果对链接url进行分析,或者对robots.txt文件中目录进行检测等等方式,通过url地址来判别是否使用了某CMS,比如wordpress默认存在wp-includes和wp-admin目录,织梦默认管理后台为dede目录,solr平台可能使用/solr目录,weblogic可能使用wls-wsat目录等。
5. 开发语言的识别: web开发语言一般常见的有PHP、jsp、aspx、asp等,常见的识别方式有:
- 通过爬虫获取动态链接进行直接判断是比较简便的方法:asp判别规则如下
]*?href=('|")[^http][^>]*?\.asp(\?|\#|\1),其他语言可替换相应asp即可。- 通过
X-Powered-By进行识别:比较常见的有X-Powered-By: ASP.NET或者X-Powered-By: PHP/7.1.8- 通过
Set-Cookie进行识别:这种方法比较常见也很快捷,比如Set-Cookie中包含PHPSSIONID说明是php、包含JSESSIONID说明是java、包含ASP.NET_SessionId说明是aspx等。
- 78个指纹识别工具大全:fingerprint --- 指纹 (kali.tools)
- 浏览器指纹识别 FP-Inspector/potential_fingerprinting_APIs.md
- 论文+项目集合:abrahamjuliot/web-fingerprinting: 网络指纹研究 (github.com)
github上的小项目
https://github.com/Lucifer1993/AngelSword
做的是cms识别,思想是上payload做匹配。

Web应用组件自动化发现的探索
https://security.tencent.com/index.php/blog/msg/201
https://mp.weixin.qq.com/s/vccQcK2GNqWkGuxEGe22Zg
找新Web组件:对比网页相似度算法实现对同类页面的聚类,而同类页面则基本可以判定为同类组件。成本问题的解决方案:每个页面给几个确定值,根据确定值相同可以确定为相似页面。响应通常包含header和body,首先对body做如下处理,把二次开发会涉及的标签进行删除或者合并得到网页骨架:

网页骨架可以分为上中下三段,计算上段、下段以及全部的MD5值。然后进行页面聚合来发现同类组件,结果分为三种可能:全一致、一段一致、两段一致,分成三段的有一个好处就是可以做分级运营。分段是根据网页骨架字符的总长度来确认,比如总长度在5000-6000之间,那么三段则是0-1000,1000-4xxx,4xxx-5xxx。
我来做的话,会提取最外层同级的body/foot标签,因为网站都是一块一块来的,这样分的就不只是三段
在某些情况下是不用区分三段的,因为有时候骨架的MD5会完全匹配。还有一种是响应返回值为json,这个时候将json的value值置空再来做对比。xml、纯字符这些都需要额外进行特殊处理。利用title等其他信息进行聚合操作,完成之后则可得到N个集合(每个集合又包含N个页面)。

论文集合
基于余弦测度的Web指纹识别算法的研究与改进
相当玄乎,没怎么看懂它的建模过程。。。

Web指纹识别分析研究
https://d.wanfangdata.com.cn/thesis/ChJUaGVzaXNOZXdTMjAyMzAxMTISCUQwMjI4MTUzMBoIcnFpd2l3cWY%3D




基于字典的关联组件发现方法
第一种造字典的方式:简而言之就是,上爬虫造字典,从官方发布的信息中提取组件之间的依赖关系(因为有的情况是你使用了组件A时必须先配置组件B),之后利用这种依赖关系来进行web框架识别,说实话,这种情况还挺少见的。


基于组件源码文件特征的关联组件发现方法
第二种造字典的方式:先本地下载cms源码,然后根据源码查用到的js/css这类组件。感觉,也挺武断的。

网站新组件指纹发现方法
通过采集不同域名的网站数据,统计JS文件、CSS文件、图片等静态文件出现的次数。抽取次数达到一定数量的静态文件,将其Hash值与组件的静态文件Hash值进行匹配。若匹配成功,则将该静态文件的Hash值作为组件指纹,在发现组件的静态文件Hash值指纹基础上,进一步发现组件的其他指纹,从而实现自动发现组件指纹。

- 建立
网页数据库、网站静态文件hash(即Hash值的特征库、组件源码文件特征库、网站组件关联库、组件指纹库、待选组件指纹库) - 采集不同域名下的
网站网页数据,存入网页数据库 - 处理网站数据,有如下步骤:
3.1. 计算该网站的JavaScript 、CSS和图片等静态文件的hash
3.2. 将hash存入网站静态文件特征库,若该hash已存在数据库中,则计数count增加1。 - 计算各
开源组件源码文件中独有的静态文件hash,提取特有文件路径特征,将计算提取结果存入组件源码文件特征数据库 - 网站静态文件hash与组件源码文件中的静态文件hash比较匹配:
5.1. 从网站静态文件特征库中提取一条计数count>n的hash,n是大于2的任意自然数字。
5.2. 将5.1提取到的hash与组件源码文件特征数据库中的hash进行匹配,若相同,则匹配成功。
5.3. 若步骤5.2匹配成功,则将匹配成功的hash作为该组件的指纹写入组件指纹库;同时为网站静态文件特征数据库中包含该hash的网站打上该组件标识,使组件与网站关联,将关联结果写入网站组件关联数据库;结束此轮匹配,转入步骤5.1直到所有计数count>n的hash与组件源码文件特征库中的hash匹配完成。若匹配失败,转入步骤5.1。 - 从
网站组件关联库中提取某一组件的所有关联网站信息,并从网页数据库中提取相应的网页数据。 - 提取
组件源码文件特征数据库中该组件的文件路径特征与关键字特征,将提取到的特征依次在上述提取到网站网页数据中进行特征匹配;若匹配成功,则将该特征写入待选组件指纹库中,在不同网站网页数据中,每条特征成功匹配一次, 则该特征计数count增加1。 - 选择待选组件指纹库中命中次数count>m的特征写入组件指纹库,m是大于2的任意自然数字。
机器学习web服务器识别
好像跟上边做的指纹库不太搭配。

根据不同http请求的响应来建立训练数据,包括主流的三种Web服务器,Apache的6个主流版本、Microsof-IIS的6个主流版本、Ngnix的15个版本,共27个具体版本。

从实验结果来看,还可以真的可以进行检测?但是,只能做到识别哪一个组件,然后继续识别组件属于哪一个版本范围,精确识别组件名+版号,做不到。


做之前,需要进行一下特征工程,消除垃圾特征,而且还挺受限制的。文中只对nginx和iis做了组件+版本范围识别。


最终的方案:

网站指纹识别与防御研究综述
从流量中识别特定网站的,不是识别网站的技术栈的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号