数据的邻近性度量
一、数据的矩阵表示
n个对象,每个对象含p个属性,则数据矩阵表示如下:
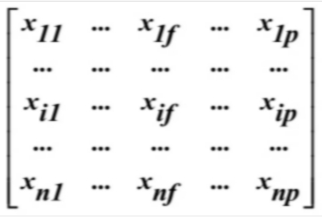
二、数据属性

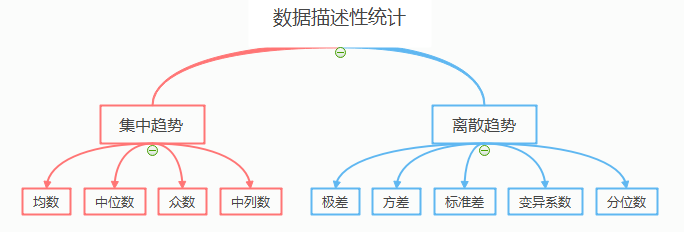
三、数据统计描述
四、数据邻近性度量
- 相似性与相异性称为邻近性,表示如下:
对象i与对象j的相异性,写作d(i,j)
对象i与对象j的相异性,写作sim(i,j)
- 相似性与相异性:
sim(i, j) = 1 - d(i, j)
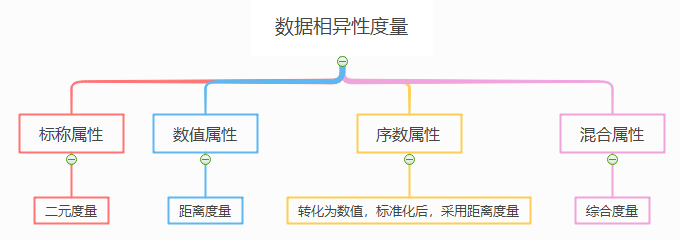
1.数据相异性度量方法
-
标称属性采用列联表(类似混淆矩阵)计算度量
q,t 描述了对象i与对象j的相同点;r,s 描述了对象i与对象j的不同点,则相异性计算,
d(i, j) = ( r + s ) / ( q + r + s + t ) ,对于非对称的二元属性的计算需要去除 t 值。
- 数值属性根据距离度量两者间的相似性,比如采用欧氏距离、曼哈顿距离
- 序数属性需要用排位数代替,标准化处理后采用距离度量的方法
- 混合属性则需要获得单个属性的相异性矩阵后指定一个权值,乘以各属性的相异性值,然后取计算的平均值作为整体相异性值。
2. 余弦相似性
- 计算公式:
![]()
- 特性:
余弦相似性,关注两个文档共有的属性出现的频率,忽略与0匹配的度量。sim(x, y)越接近1,则两者间越相似 - 适用情形:
适用于稀疏结构(矩阵中有太多0值),比如词频统计、文本文档聚类、信息检索、生物学分类等


 浙公网安备 33010602011771号
浙公网安备 33010602011771号