VulDeePecker: A Deep Learning-Based System for Vulnerability Detection 分析实践
VulDeePecker: A Deep Learning-Based System for Vulnerability Detection 分析实践
论文内容分析
1. 论文目的
现存的漏洞检测系统(截止到论文发表前)有两个缺点,一是高度依赖专家知识,二是存在较高的假负样本率(false negative rates )。为了解决这两个痛点,本文尝试使用深度学习来构建一个直接面向程序源码的自动漏洞检测系统(很自然的想法,关键在于如何建立起这个工程)。
2. 系统建立需要解决的问题
- 如何转化程序源码为神经网络的输入
- 适合的学习粒度的大小(code gadget)
- 网络的选择(双向lstm)
3. 系统设计
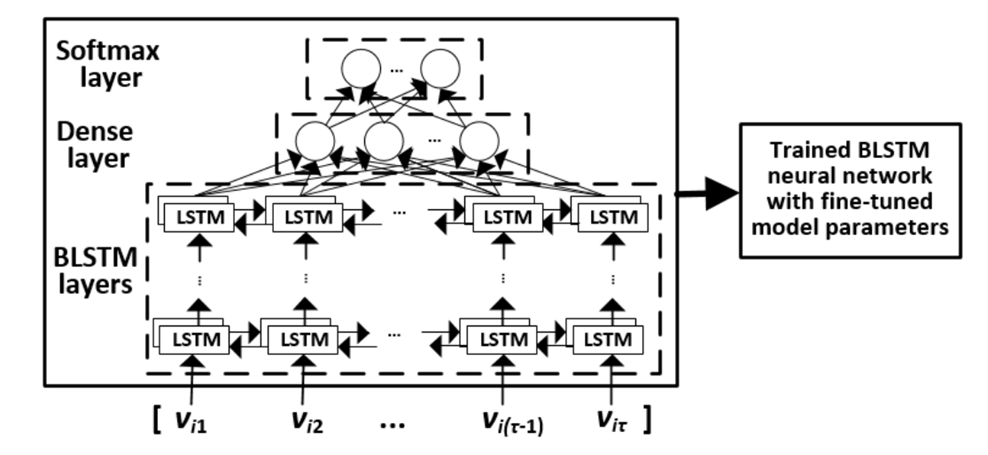
VulDeePecker总览:
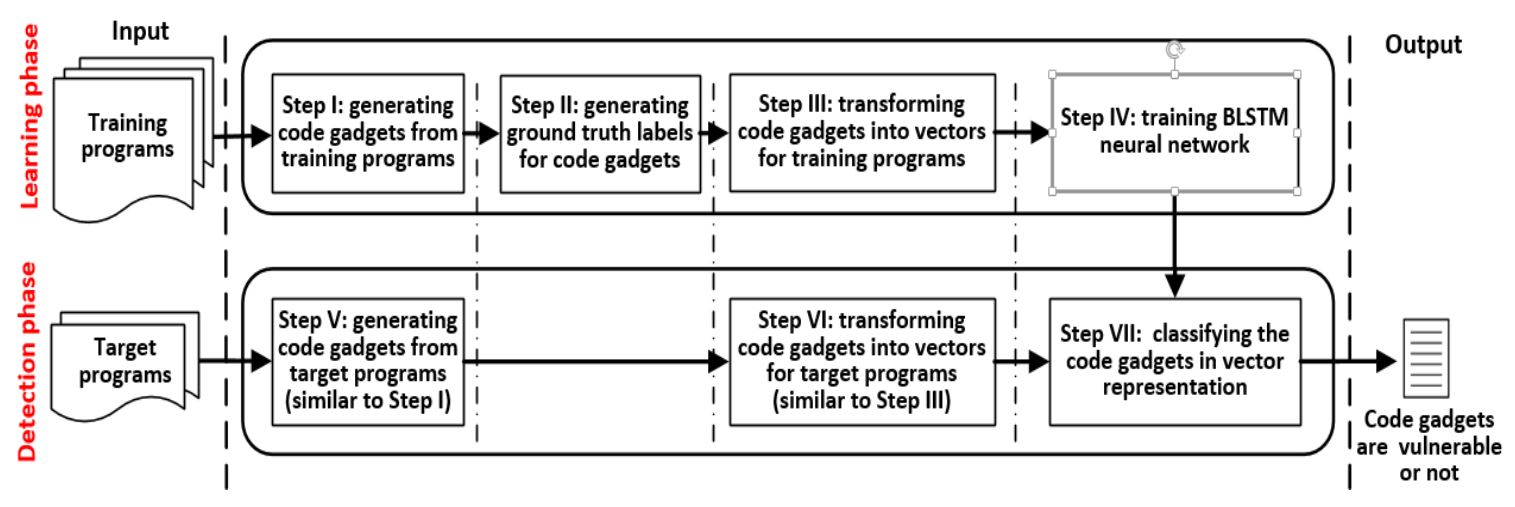
将训练集源码转化为code gadget代码集合,然后标记样本,将样本转化为可处理的特征向量,输入特征向量到BLSTM网络(fine-tune)中,得到模型参数后对测试集进行测试,判断程序是否存在漏洞。
具体流程
1. 生成code gadget
code gadget:基于启发式方法构建的代码语句集合,代码语句间存在一定的语义联系(数据流或控制流上的联系);
启发式方法:本文用程序的一些关键的元素(key point),如API调用,数组变量,指针变量等表征程序是否存在漏洞。比如有的漏洞是因为系统api调用,那么key point就是该api,通过把同该key point具有联系的代码语句组合起来形成相应的code gadget;
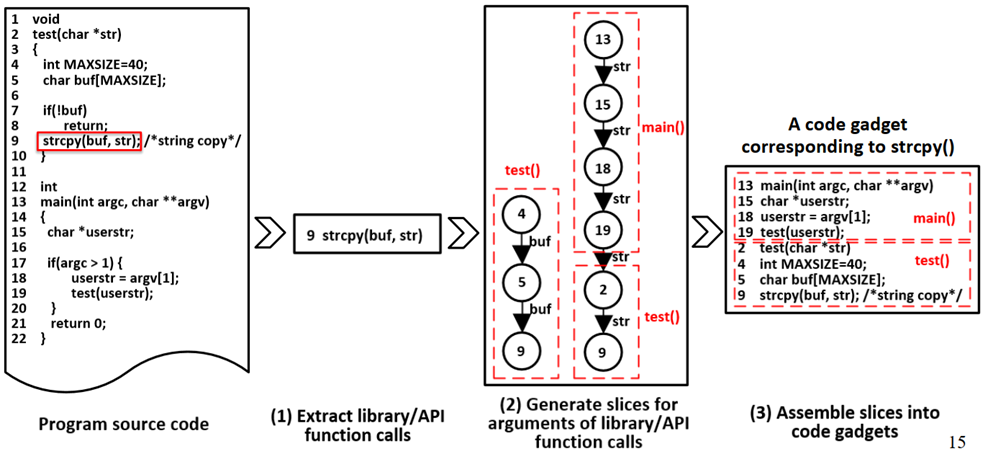
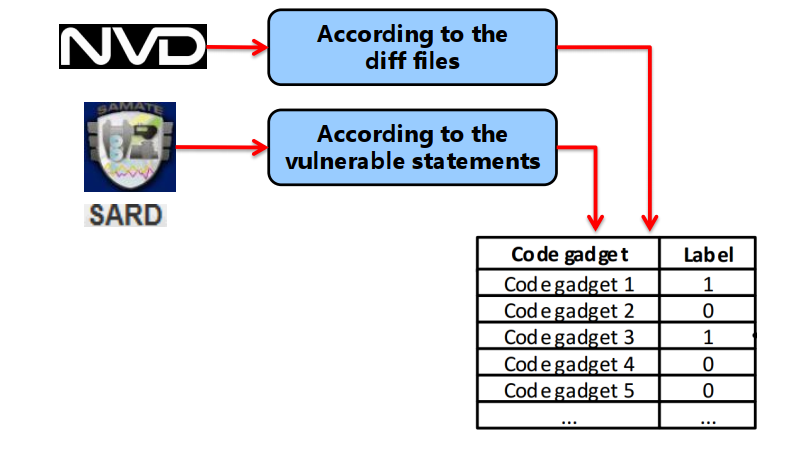
2. 标注样本
根据NVD和SARD漏洞库进行样本标注:
3. 将code gadgets编码为固定长向量
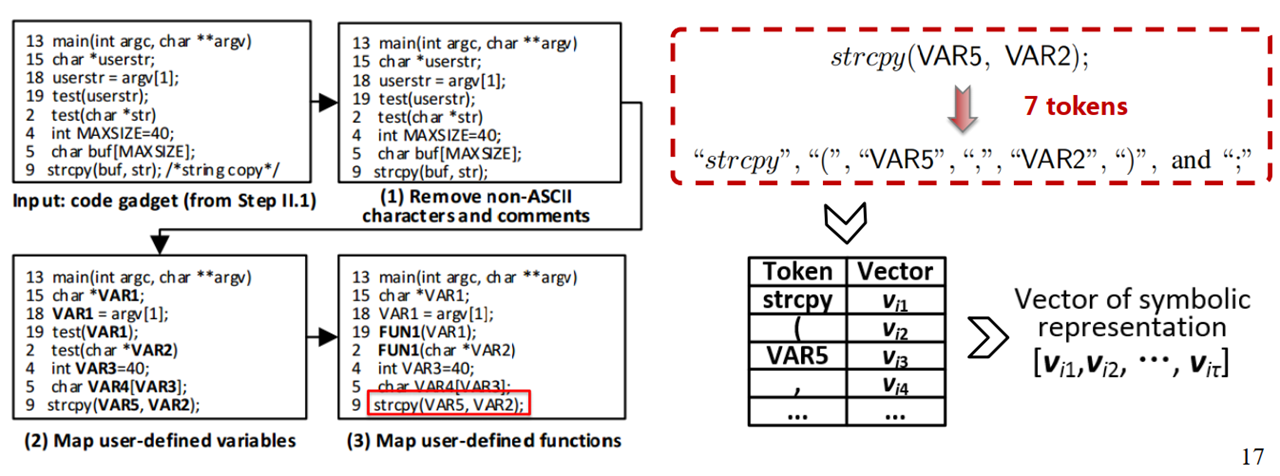
先转化为符号表示,然后在利用句法分析建立词表,再用word2vec模型进行向量编码。
4. 模型训练
将向量输入blstm网络,进行模型训练,得到训练参数,用于测试
4. 实验结果
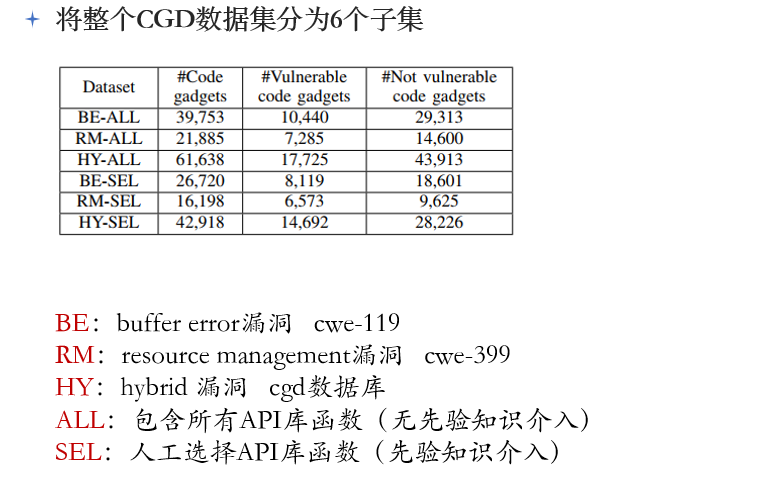
1. 数据集与评估标准
数据集是作者团队开发的一个数据集CGD(cwe339,cwe119,两类漏洞,缓冲区溢出和资源管理漏洞),具体见https://github.com/CGCL-codes/VulDeePecker ;
metrics:假负样本率,假正样本率,F值,精确度等。
数据集分为了六个子集用于不同的测试目的:
2. 实验结果

结论:系统可以识别多种漏洞,但具有数据依赖性 ;

结论:先验知识介入可以增加系统能力 ;
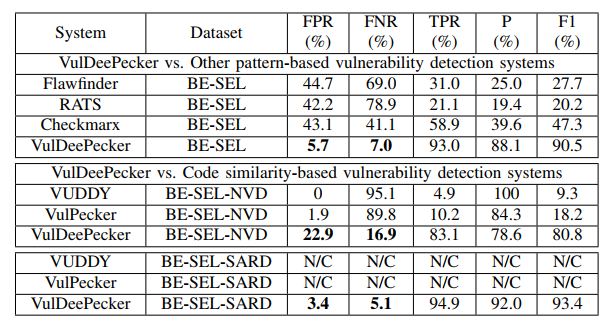
结论:系统相对于现有(2018)的一些静态检测方法具有显而易见的优势 ;
5. 讨论:创新,贡献,不足
创新与贡献:
- 首次在漏洞检测上引入深度学习的方法,并且解决了一些存在问题。
- 讨论了一些适用深度学习的面向程序源码的向量编码原则。
- 在实际应用中证明了该深度学习系统一定的有效性 (检测出了几个实际应用中存在的漏洞)
- 给出了一个可用的数据集
不足
- 非端到端方法
- 向量编码时使用启发式方法
- 仅面向C/C++源码,且用例漏洞类型太少
- 不是每个软件都开源
论文复现
该论文官方并没有放出源码,但在github上还是有一份他人的复现代码 ,我这就直接拿来用了。值得强调的是,复现的难点不在于模型,而是在于之前的一些预处理工作,所谓的dirty work。说实话,如果面对的是写的琐碎但却细节模糊而且还不放源码的论文,复现的难度太大而且没啥意义。
这个复现代码也存在几个坑,都在blstm.py中,
一个是在建立特征向量的时候,转换了label和feature;这个重写一下就行。
另一个是关于样本类别权重平衡的问题,这个就是tf的锅了,tf的版本迭代的兼容性确实让人头疼。不嫌麻烦的可以根据调试信息改下相应的源码,或者用pytorch重写一个。或者简单点直接把关于样本类别权重平衡的代码注释掉就行了,像本文数据集这样的样本分布,其实也没多偏,影响不了多少精度。事实上,关于样本分布和取样的问题到现在还是一个基础问题,需要做的突破还有很多的。
复现结果:
cwe339:
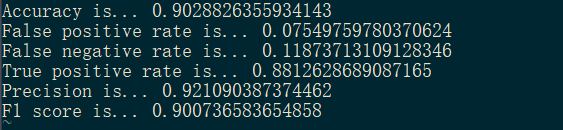
cwe119:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号