

第一次个人编程作业
https://github.com/zsiothsu/FZU2021SE
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 540 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 60 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 5 |
| · Design | · 具体设计 | 190 | 540 |
| · Coding | · 具体编码 | 360 | 180 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 360 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 10 | 5 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1685 | 1030 |
二、计算模块接口
2.1 计算模块接口的设计与实现过程
2.1.1 概述
本项目实现了一个敏感词过滤算法。对于识别词汇,自然而然能想到的是使用字典树或AC自动机进行分类,而单词的各种混淆,使用枚举算法可以实现。
而计算机识别汉字是比较困难的事,所以本人参考了一下机器学习中识别英文垃圾邮件的算法,利用词库把单词映射为唯一的数字。那么类比一下,先把汉字转为“英文单词”,即拼音,然后再映射为唯一数字,这样也直接解决了谐音字和拼音缩写的问题
而汉字拆解,可以直接使用现成的字库,利用一个 map 储存汉字及对应的组成部分,编码可以直接将汉字映射为数字,而不经过拼音。
而怎样统一拼音编码和字形编码,将在编码设计的部分细说
2.1.2 类设计
依照以上思路,就可以把项目分成两个类:
Filter类作为整个项目的主干,用于构建字典树和进行查找Word类用于实现混淆算法,是模糊识别的关键
Word 类
word 类只有一个 confuse 方法,用于生成单词的变形,如“你好”这个单词,可以混淆为
-
纯拼音编码
['ni', 'hao']
['n', 'i', 'hao']
['n', 'hao']
['ni', 'h', 'a', 'o']
['n', 'i', 'h', 'a', 'o']
['n', 'h', 'a', 'o']
['ni', 'h']
['n', 'i', 'h']
['n', 'h'] -
纯字形编码
['亻', '尔', '女', '子']
-
混合编码
['亻', '尔', 'hao']
['亻', '尔', 'h', 'a', 'o']
['亻', '尔', 'h']
['ni', '女', '子']
['n', 'i', '女', '子']
['n', '女', '子']
Filter 类
Filter 类作为项目的主干需要实现以下功能
-
read_sensitive_words()读入敏感词 -
build_sensitive_word_tree()构建敏感词字典 -
filter()第一次过滤:清除与识别无关的字符,如标点符号,空格等 -
filter_line()第二次过滤:利用字典识别敏感词 -
logger()和output()输出和统计结果
2.1.3 编码设计
项目的编码是识别的基础,不同于纯拉丁字母,汉字可以表示成“汉字“,”拼音“,”偏旁“,甚至把汉字当音节,如 ”汉字“ 的 ”汉“/xan/ 字也可以写成 ”喝暗“/xɤan/ ,当然这种极端例子不在本文的讨论范围内。所以这部分做的越精细,识别的类型也会越多(但也可能出现误报)。
题外话:更有甚者可以用典,其实英文也可以
项目采用两种编码,一个汉字可能会同时拥有以下两个流程,这边以‘你’为例:
-
拼音编码
你 --> ['ni'] -> [56]
-
字形编码
你 --> [‘亻’ , ‘尔’] --> [439, 440]
英文(直接使用汉字全拼也会被当英文处理)采用直接拆分映射
ni --> ['n', 'i'] --> [14, 9]
编码后可以直接输入字典树

但识别就没那么容易了,传统字典树无法处理多匹配的情况,如 '亻' 可以走向 ‘ren’(322) 分支,也可以走向 ‘亻’(439) 分支,如果敏感词是 [‘你好’, ‘人们’] 输入是 [' 亻', '尔', '好'],那将直接导致无法识别。所以这里引入失配指针的概念,将字典树升级为AC自动机
2.1.4 关键算法
AC自动机
其实严格来讲这里用的不是AC自动机,只是在改进字典树的时候借用了AC自动机的失配指针思想,所以实现上是AC的一个简化版。
总的来说失配指针只需要实现以下需求:当拼音编码走不通的时候,回忆起刚刚还有一个字形码的分支,然后改到字形码的分支,且自动机回到分支之前的状态再尝试匹配。
所以失配指针最小需要储存以下状态:
- 被分支的字符在原始句子中的位置
- 另一个分支的指针
- 目前识别了一半的单词的起始位置
因为本项目具体实现的自动机在失配后会立刻忘记刚刚在识别哪个单词,所以加上了第三点,但如果设计的好是不用这点的。
具体来说的话,指针长这个样子:
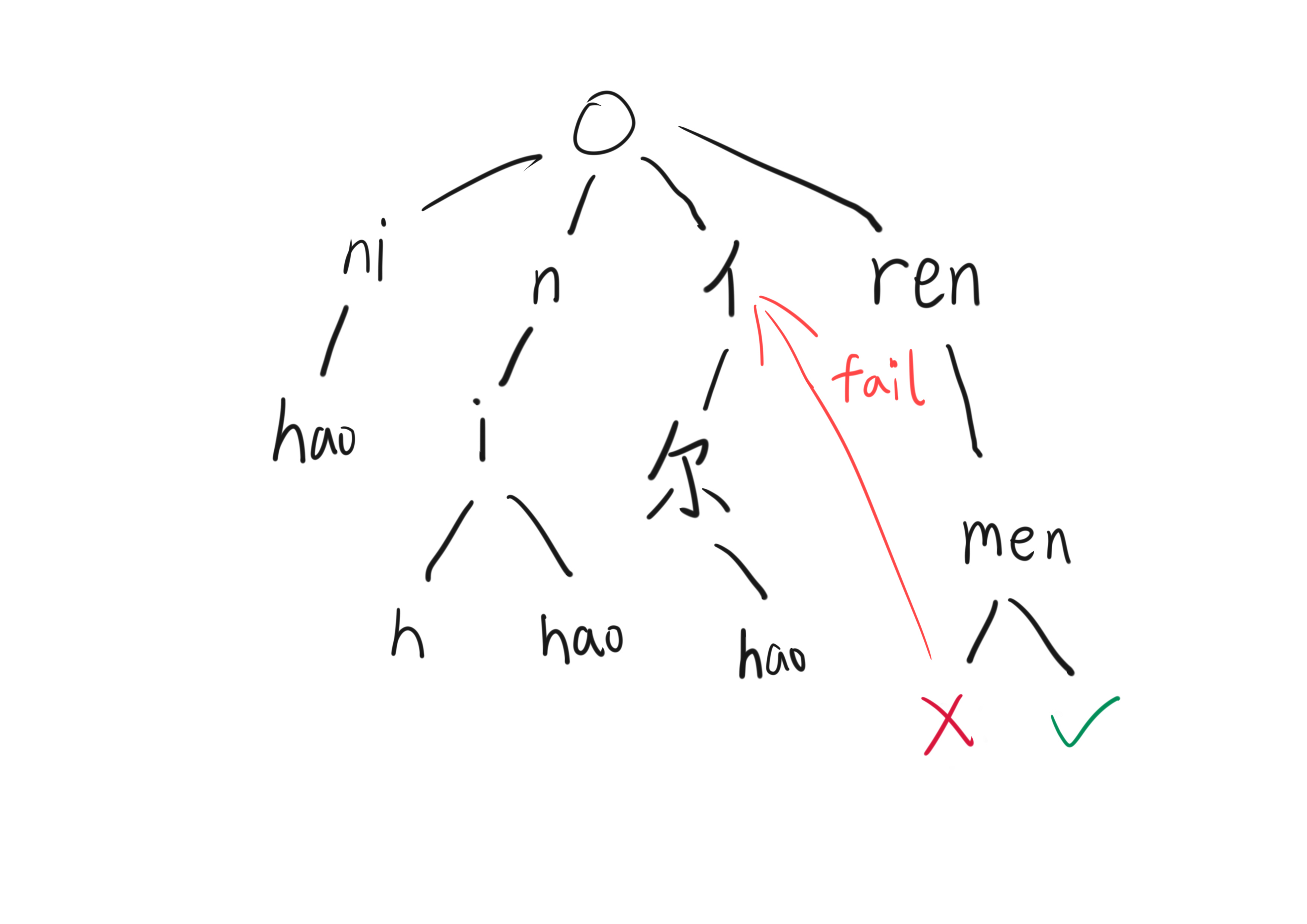
然后就可以让自动机自动运行了:

2.2 计算模块接口部分的性能改进
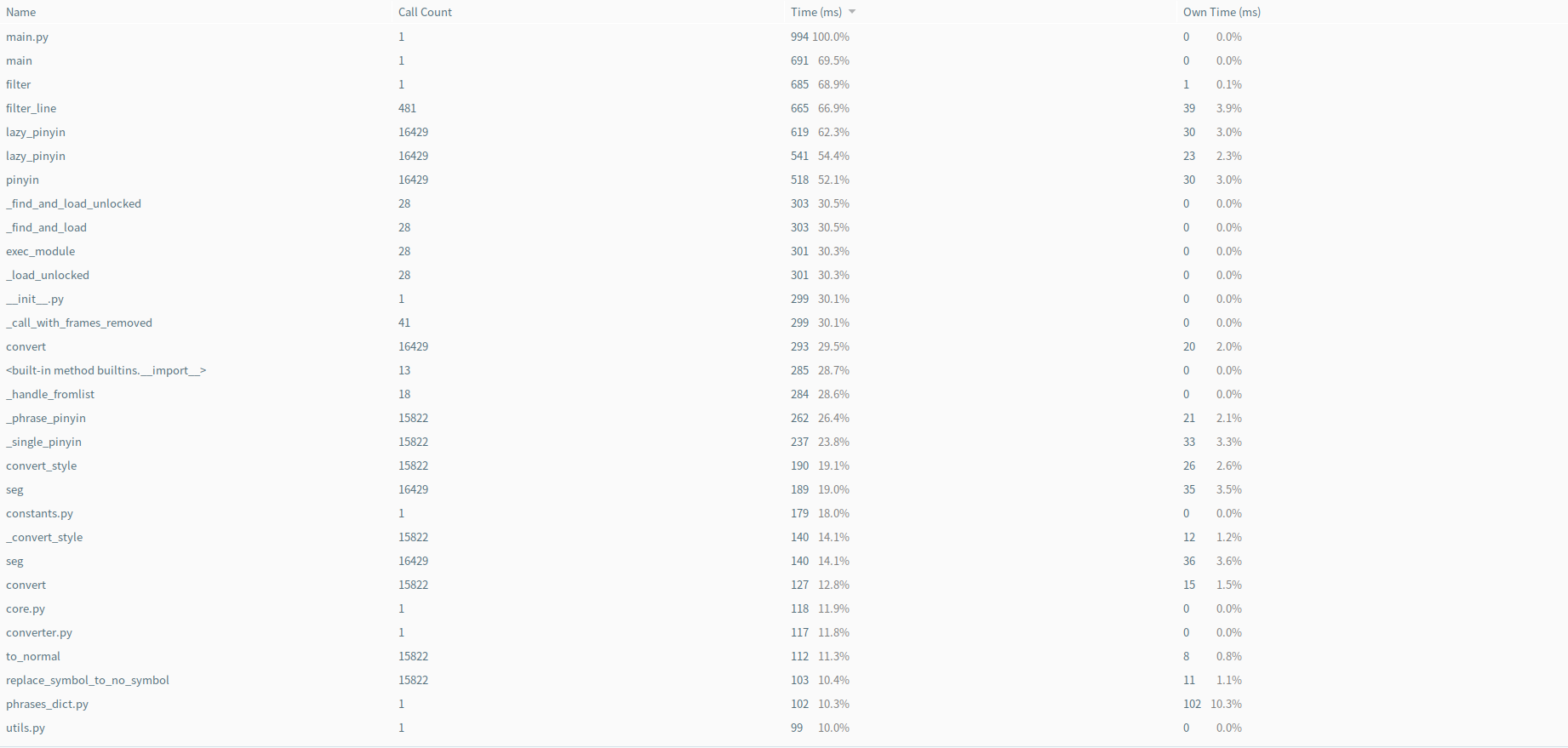
性能测试 按总时间排序:
性能测试 按函数实际运行时间排序:
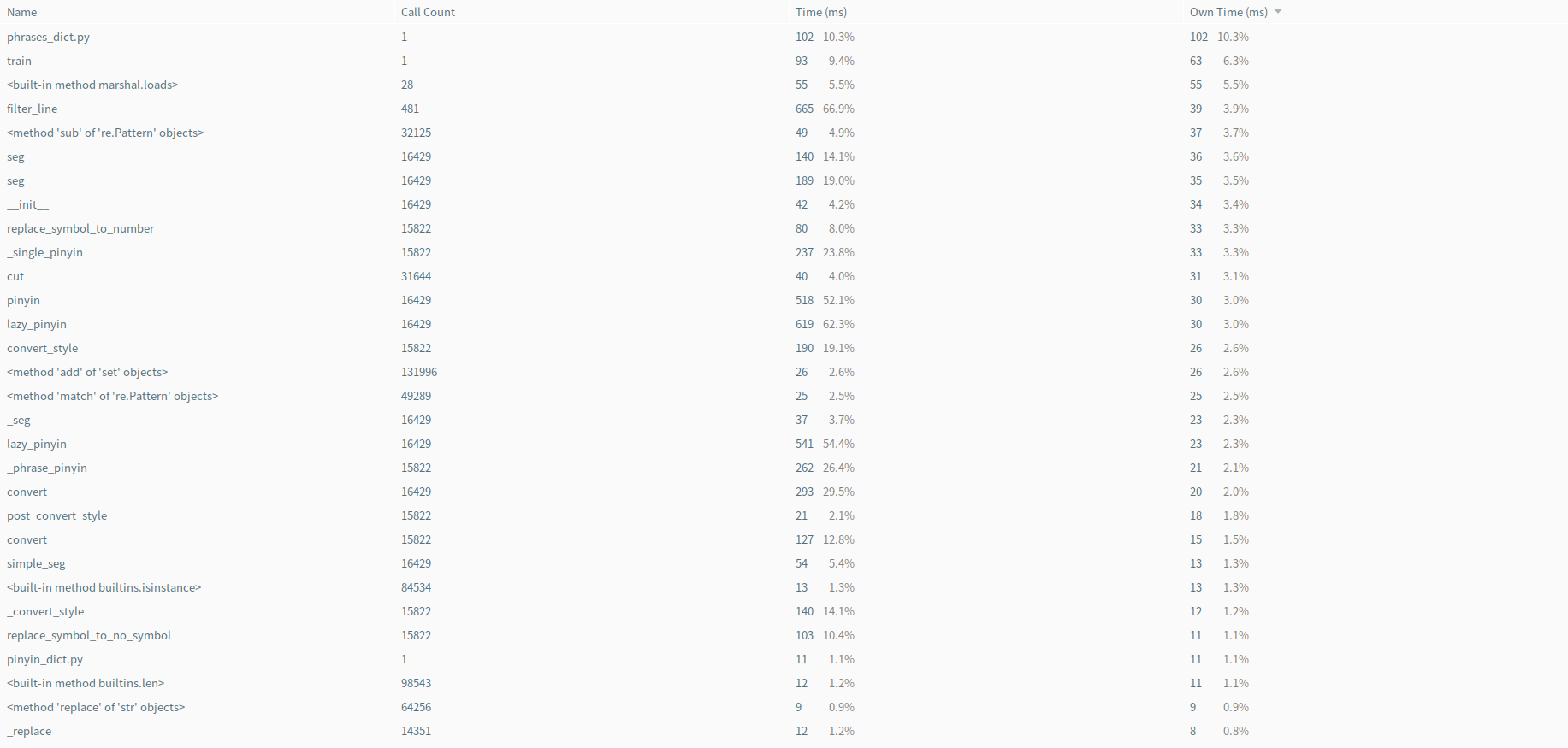
可以看到,最耗时的其实是我采用的第三方拼音库,点开源代码发现拼音库的初始化就耗费了总时长的10%,当然因为是常数时间,所以不是太大的问题,而且目前pypinyin是我能找到的字库最全面的库,所以也暂时没有替代方案。
就我自己的程序而言,耗时最大的是AC自动机的查找函数,但其实已经足够精简,每个分支执行的代码都是固定的几行,所以在性能分析表上也没有显得特别突出。(如果有改进办法的话欢迎讨论):
def filter_line(self, sentence):
""" filter a single line
filter a single line. cannot detect sensitive words in
two different lines at the same time
:arg
sentence[string]: text to be detected
:return -> set
the starting index of the answer
"""
current = self.sensitive_dict
word_begin_index = 0
# a set storing answer for unit test
ans_set = set()
# fail pointer:
# fail_pointer_stack(position, dict of glyph code branch, curren word_begin_index)
# When the Chinese character has both pinyin code and glyph code,
# pinyin code is preferred for matching.When it cannot be matched,
# the fail pointer is used to switch to the branch of glyph code.
fail_pointer_stack: (int, dict, int) = []
i = 0
while i < len(sentence):
c = sentence[i]
if c == '*':
i = i + 1
continue
# is a breakable hanzi
if c in glyph_code_map:
pinyin_code = pinyin_alpha_map[lazy_pinyin(c)[0]]
glyph_code = glyph_code_map[c]
is_pinyin_code_in_current = pinyin_code in current
is_glyph_code_in_current = glyph_code in current
# if not matched, try to return dict to root
if (not is_pinyin_code_in_current) and (not is_glyph_code_in_current):
current = self.sensitive_dict
word_begin_index = 0
if is_pinyin_code_in_current:
# append fail pointer for glyph code branch
if is_glyph_code_in_current:
fail_pointer_stack.append((i + 1, current[glyph_code], word_begin_index))
if current == self.sensitive_dict:
word_begin_index = i
current = current[pinyin_code]
if current['end']:
self.logger(word_begin_index, i + 1, current['word'])
ans_set.add(word_begin_index)
elif is_glyph_code_in_current:
if current == self.sensitive_dict:
word_begin_index = i
current = current[glyph_code]
if current['end']:
self.logger(word_begin_index, i + 1, current['word'])
ans_set.add(word_begin_index)
# failed to match
else:
# switch to last glyph code branch
if len(fail_pointer_stack) != 0:
i = fail_pointer_stack[-1][0]
current = fail_pointer_stack[-1][1]
word_begin_index = fail_pointer_stack[-1][2]
fail_pointer_stack.pop()
continue
else:
current = self.sensitive_dict
word_begin_index = 0
# is a unbreakable hanzi or a latin letter
else:
pinyin_code = pinyin_alpha_map[lazy_pinyin(c)[0]]
if pinyin_code not in current:
current = self.sensitive_dict
word_begin_index = 0
if pinyin_code in current:
if current == self.sensitive_dict:
word_begin_index = i
current = current[pinyin_code]
if current['end']:
self.logger(word_begin_index, i + 1, current['word'])
ans_set.add(word_begin_index)
i = i + 1
continue
# switch to last glyph code branch
if len(fail_pointer_stack) != 0:
i = (fail_pointer_stack[-1])[0]
current = (fail_pointer_stack[-1])[1]
word_begin_index = fail_pointer_stack[-1][2]
fail_pointer_stack.pop()
else:
current = self.sensitive_dict
word_begin_index = 0
i += 1
return ans_set
2.3 计算模块部分单元测试展示
主要测试 Filter.filter_line() 和 Word.confuse()两个核心函数,用例根据代码的各个if分支构造(但最后发现有的分支基本不会进入,怀疑为冗余代码)。
部分测试函数展示:
class MyTestCase(unittest.TestCase):
def test_filter_line_2(self):
main.init_pinyin_alpha_map()
f = Filter()
f.read_sensitive_words(file_words)
org = "nihao世界"
ans_set = {0}
org = re.sub(u'([^\u3400-\u4db5\u4e00-\u9fa5a-zA-Z])', '*', org)
org = org.lower()
ans = f.filter_line(org)
self.assertEqual(ans_set, ans)
def test_filter_line_3(self):
main.init_pinyin_alpha_map()
f = Filter()
f.read_sensitive_words(file_words)
org = "泥濠世界"
ans_set = {0}
org = re.sub(u'([^\u3400-\u4db5\u4e00-\u9fa5a-zA-Z])', '*', org)
org = org.lower()
ans = f.filter_line(org)
self.assertEqual(ans_set, ans)
def test_filter_line_4(self):
main.init_pinyin_alpha_map()
f = Filter()
f.read_sensitive_words(file_words)
org = "泥 h&*%^&世界he^&l^(&lo"
ans_set = {0, 11}
org = re.sub(u'([^\u3400-\u4db5\u4e00-\u9fa5a-zA-Z])', '*', org)
org = org.lower()
ans = f.filter_line(org)
self.assertEqual(ans_set, ans)
def test_confuse_1(self):
s = "你好"
w = Word(s)
ans = [
['ni', 'hao'],
['n', 'i', 'hao'],
['n', 'hao'],
['ni', 'h', 'a', 'o'],
['n', 'i', 'h', 'a', 'o'],
['n', 'h', 'a', 'o'],
['ni', 'h'],
['n', 'i', 'h'],
['n', 'h'],
['亻', '尔', '女', '子'],
['亻', '尔', 'hao'],
['亻', '尔', 'h', 'a', 'o'],
['亻', '尔', 'h'],
['ni', '女', '子'],
['n', 'i', '女', '子'],
['n', '女', '子']
]
result = w.confuse()
flag = True
for i in ans:
if i not in result:
flag = False
break
self.assertEqual(flag, True)
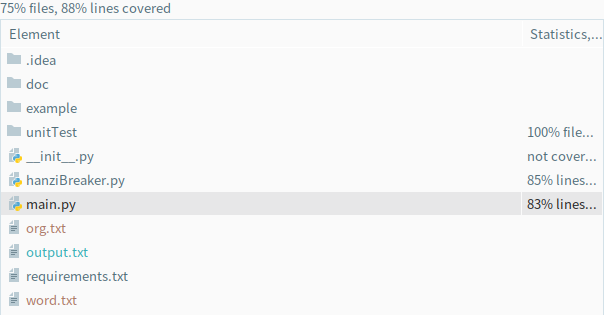
单元测试覆盖率:
2.4 计算模块部分异常处理说明
IOError: 当输入文件不存在或没有权限时抛出
单元测试代码:
def test_file_read(self):
main.clear_status()
main.init_pinyin_alpha_map()
f = Filter()
try:
f.read_sensitive_words("./nofile.txt")
except IOError:
self.assertTrue(True)
else:
self.assertTrue(False)
三、心得
要说心得最多的时候,大概是看到自己检测出的敏感词比老师给的答案多吧(
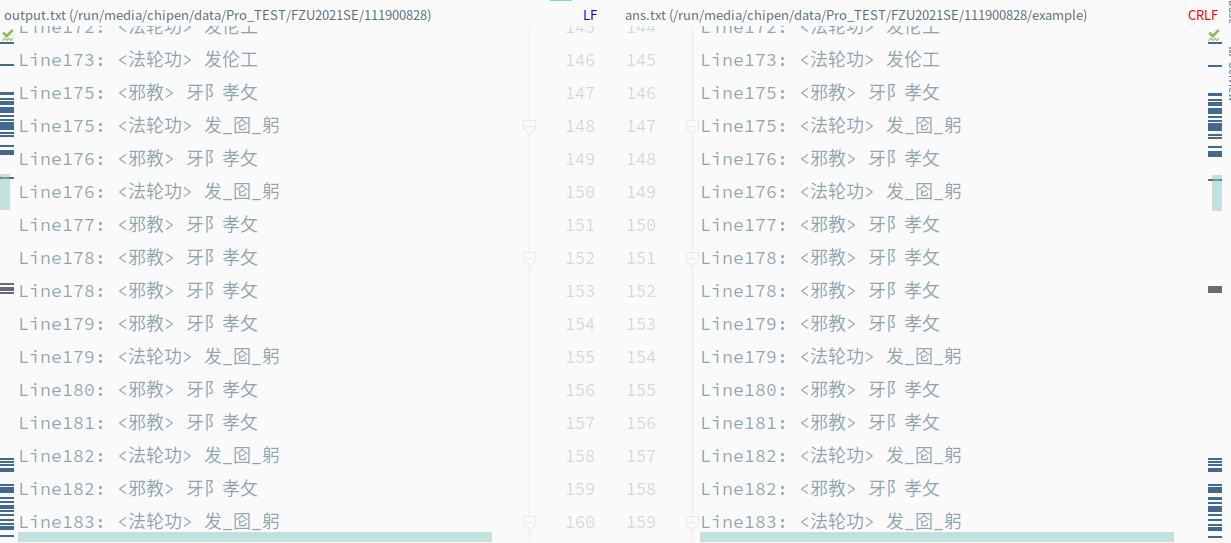
左边是我的程序,右边是标答
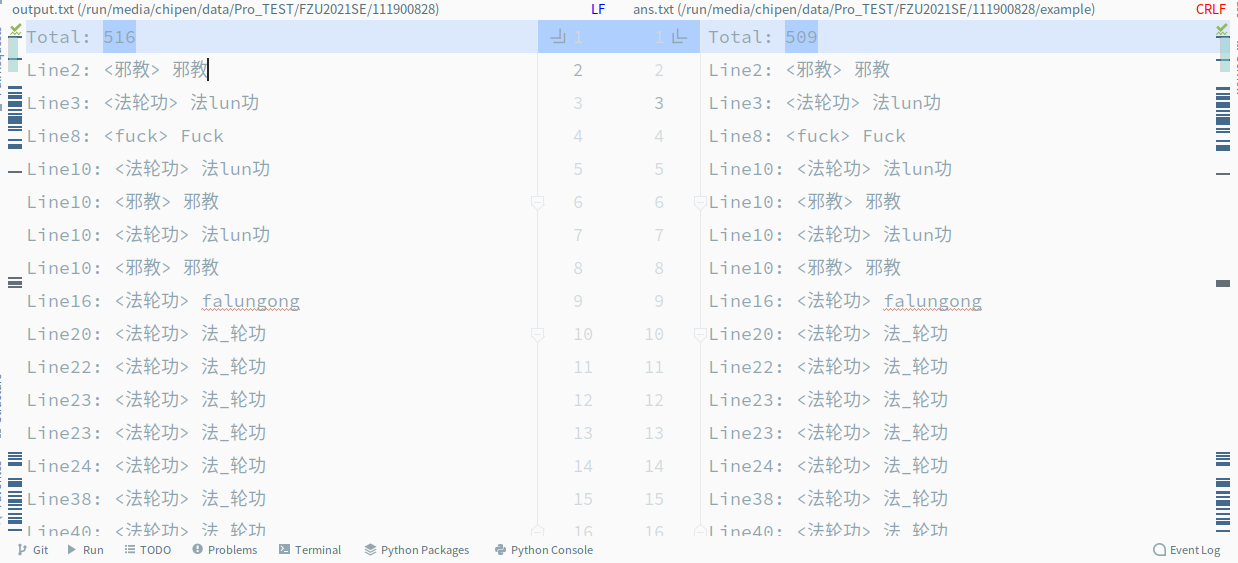
我一开始觉的不可能检测出来的东西也检测出来了

这是一次很难得的大作业的机会,知道了如何进行单元测试,(之前一直以为单元测试要对每个函数都测试一遍。。。) 和进行性能分析。
PSP表格还是难以使用,因为题目没写出来的话,就算是睡觉也要想解决方法。
词云在补了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号