内存分配机制
内存空间的分配包括连续分配存储管理和非连续分配存储管理。
连续分配管理方式
首先确定外部碎片和内部碎片的定义。在内存空间中,内部碎片是指分配给某进程的内存区域中没有被用到的部分,例如一个进程5MB,操作系统为其分配了6MB,则存在1MB用不到的内部碎片。外部碎片是指还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
单一连续分配
在单一连续分配中,内存分为系统区和用户区,系统区存放操作系统相关数据,用区去存放用户进程相关数据。在内存中只有一道用户程序。
该分配方式实现简单,但是存储器利用率极低,只适用于单用户、单任务的操作系统。无外部碎片,有内部碎片。
固定分区分配
固定分区分配是指将用户空间等分为若干个固定大小的分区,每个分区内最多装入一道作业,分为分区大小相等(例如每个分区都为5MB大小)和分区大小不等(划分为多种分区,例如5MB,10MB,20MB..,各种分区数量不等)。
固定分区分配的实现需要一张分区说明表,从而实现分区的分配与回收。分区说明表如下所示:
| 分区号 | 大小(MB) | 起始地址(M) | 状态 |
|---|---|---|---|
| 1 | 2 | 8 | 未分配 |
| 2 | 2 | 10 | 未分配 |
| 3 | 4 | 12 | 已分配 |
| .. | .. | .. | .. |
固定分区分配无外部碎片,有内部碎片,利用率低。且当有进程大小超过最大分区大小时,无法为该进程分配空间。
动态分区分配/可变分区分配
在进程装入内存时,操作系统会根据进程的大小动态分配分区,分区大小等同于进程大小。使用动态分区分配需要维护一张空闲分区表或空闲分区链,用于记录空闲分区。
动态分区分配无内部碎片,但是会产生外部碎片(某些空闲分区由于太小而难以利用),可以利用紧凑技术合并小分区。
对于动态分区分配,考虑到使用不同的空闲分区后空闲分区情况不同,需要使用动态分区分配算法。下面介绍4中动态分区分配的算法:
-
首次适应算法First-Fit
每次都从低地址开始查找,选择第一个能够满足大小的空闲分区。
-
最佳适应算法Best-Fit
为了保证大进程到来时能有大片连续空闲空间,优先使用更小的空闲分区。将空闲分区按照容量递增链接,每次寻找大小能够满足的第一个空闲分区。由于每次都选择最小的分区分配,因此会留下越来越多细碎、难以利用的空闲空间,使用Best-Fit会产生很多的外部碎片。
-
最坏适应算法Worst-Fit
为了防止留下太多细碎的空闲空间,每次分配时优先使用最大的空闲分区。可以将空闲分区按照容量递减链接,每次分配内存时顺序查找,找到大小能够满足的第一个空闲分区(第一个必定满足,否则后继空闲分区大小都不足以满足)。由于每次都使用最大的空闲分区,因此较大的连续分区会很快被利用完,导致大进程到来时可能不足以分配。
-
邻近适应算法Next-Fit
由于首次适应算法每次都从链头开始查找,可能导致低地址 部分出现很多小的空闲分区,而每次查找时都会遍历这些分区,增加了查找开销。因此将空闲分区按照地址递增的顺序排成一个循环链表,每次都从上次结束的位置开始查找,使用第一个满足的空闲分区。
对比First-Fit和Next-Fit,First-Fit更有可能将高地址部分的大分区保留下来(Best-Fit的优点),而Next-Fit会导致无论是高地址还是低地址的空闲分区都有相等的概率被使用,导致了高地址部分的大分区更有可能被使用,最后无大分区可用(Worst-Fit的缺点)。
综合考量,首次适应算法的综合效果更好。
非连续分配管理方式
以上讨论的都是连续分配管理方式,即对于一个进程,为其分配的内存空间是连续的,这样的话对于大进程十分不利,下面讨论非连续分配。非连续分配包括基本分页存储管理、基本分段存储管理、段页式存储管理。
基本分页存储管理
页表TLB
基本分页管理将内存空间分为大小相等的分区,每个分区就是一个页框(页帧/内存块/物理块/物理页面/Frame),每个页框有一个页框号;将逻辑空间分为与页框大小相等的一个个部分,每个部分称为页/页面/Page。为了能知道进程中每个页面在内存中的位置(即该页面在内存中的内存块号),需要为每个进程维护一张页表Page Table,实现页号->块号的印射,从而能在物理内存中找到相应的页。
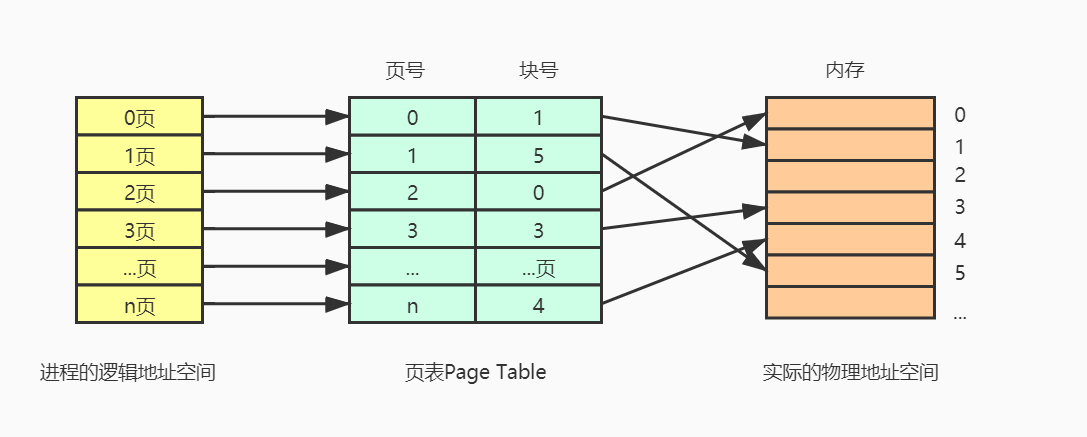
通过页表可以实现地址的转换,假设页面大小为M,若要访问逻辑地址A,首先确定A对于的页号P=A/M ,接着通过页表找到该页号对应的物理块号,假设为B,接着可以确定页内偏移W=A%M,则最终对应的物理地址为 P * M +W。
引入快表TLB
对于一次地址访问,假设访问内存所需时间为100us,则首先要访问一次在内存中的页表,找到对应的块号,然后再次访问内存,读取对应的物理块号,最终需要2*100us=200us的时间。若引入快表TLB,假设访问一次快表时间为1us,快表命中率为90%,若快表命中,则可以不用访问页表,直接访问对应物理块,否则还需要再访问一次页表,理论时间为 90% * (1us + 100us) + 10% * (1us + 100us + 100us) = 110.9us。可以看到引入快表后平均访存时间减少了不少,这也是利用了局部性的原理。

多级页表
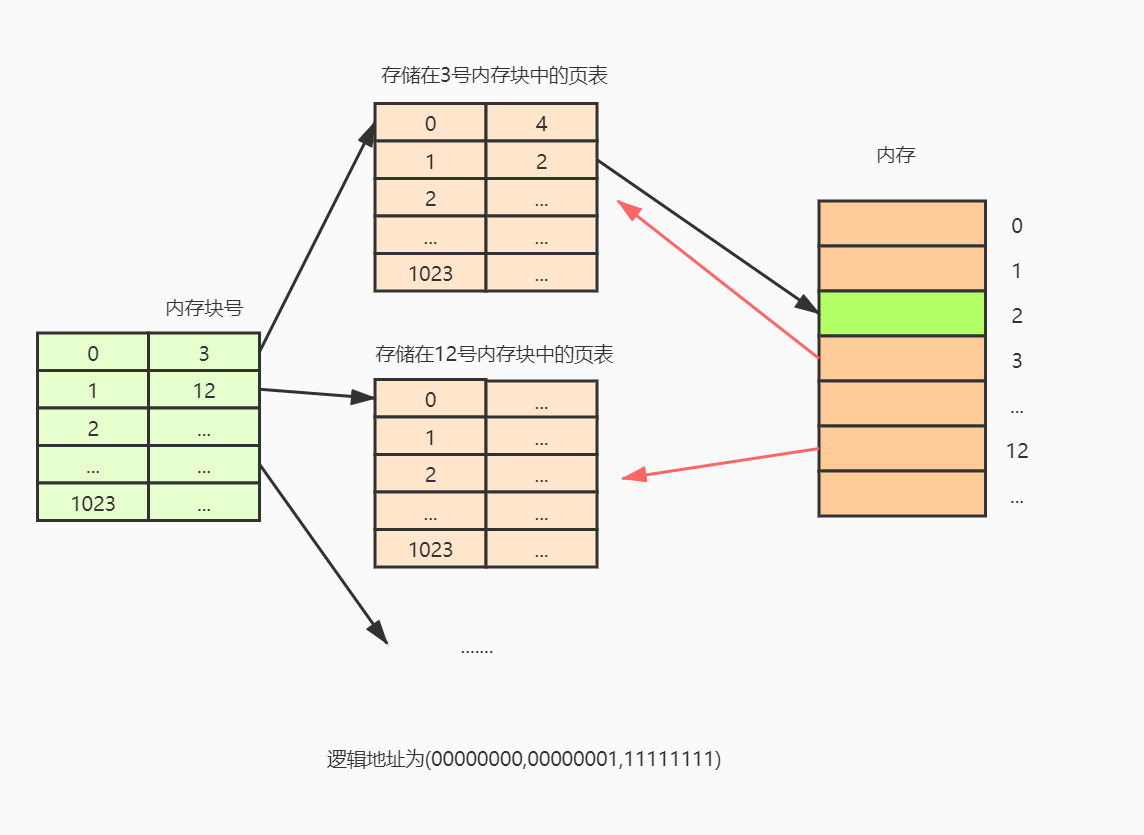
假设计算机按字节编址,逻辑地址空间为32位,采用分页存储管理,页面大小为4KB(2^12 B) ,页表项长度为4B。则在该系统中,一个用户进程最多2^20页,一个页表最大需要 2^20 * 4KB = 1M * 4B = 2^22B 大小的内存来存放,一共需要2^22B / 2^12B = 2^10 个页框来存放页表。在内存中找到这么多连续的页框来存放页表不太容易,需要连续分配内存,因此可以考虑将页表像页面一样离散地存储,此时就要用到多级页表。
考虑一个二级页表,基本假设同上。每个页面最多可以存放 4KB/4B = 1K = 2^10 = 1024 个页表项,对于一个32位的地址,一级页号占10位,二级页号占10位,页内偏移占12位,地址转换过程如下:
基本分段存储管理
分段存储管理是将程序根据逻辑功能划分为若干个段,每个段都有一个段名,每个段在内存中占据连续的存储空间,但是各个段之间可以不相邻。由于各个段的大小可能不一样,因此在段表中还要额外指明段长
| 段号 | 段长 | 基址 |
|---|---|---|
| 分段存储管理中的地址转换与分页存储管理类似,将逻辑地址划分为段号和段内偏移,然后再查找段表,实现逻辑地址到物理地址的转换。 |
分段管理 vs 分页管理
-
页是信息的物理单位,分页主要是为了提高内存利用率,分页对用户是不可见的。而段是信息的逻辑单位,分段是为了更好的满足用户的需求,用户在编程时要显式地给出段名,分段对用户是可见的。
-
页的大小由系统决定,而段的大小却是不固定的,由用户编写的程序决定。
-
分段更容易实现信息的共享和保护,可以直接指明一个段是否能被共享,而在分页存储管理中,可能出现一个页面的部分内容是可以被共享的,而另外一部分内容无法被共享,难以管理,这是因为分页是系统自动进行的。
-
分页管理内存利用率高,不会产生外部碎片,只会产生少量的内部碎片,但是不方便按照逻辑模块实现信息的共享和保护。而分段管理可以很方便地按照逻辑模块实现信息的共享和保护,但是可能会产生外部碎片。
段页式存储管理
段页式存储管理式结合了分段管理和分页管理,基本上就是对于每个段再进行分页管理,防止某些段过大。例如假设地址结构如下:
| 31 ... 16 | 15 ... 12 | 11...0 |
|---|---|---|
| 段号 | 页号 | 页内偏移 |
| 假设系统是按照字节编址,其中段号占16位,说明每个进程最多有 2^16 = 64K 个段;页号占4位,说明每个段最多由 2^4 = 16 个页面组成;页内偏移占12位,因此每个页面 or 每个内存块大小 = 2^12 = 4KB。在进行寻址时,首先根据段表找到该段对应的页表在内存中的物理块号,然后读取出该页表,根据页号找到该页面对应的物理块号,将该物理块读取出来,最后根据页内偏移得到物理地址。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号