
软件测试高频题库
0. 你以前工作时的测试流程是什么?
- 需求评审(有开发人员、产品经理、测试人员、项目经理) → 需求确定(出一份确定好的需求文档)→ 需求分析(使用思维导图梳理业务流程)
- 编写、评审测试计划
- 编写测试用例、测试用例评审(组内评审、组外评审(开发人员与产品经理))
- 执行测试用例 → 提交Bug给开发人员修改
- 回归测试:Bug解决,关闭;没有解决,重新提交给开发
- 测试报告,应用上线
1. 软件测试的目的与原则是什么?
软件测试目的:
-
通过测试工作可以发现并修复软件当中存在的缺陷;
-
可以降低同产品开发遇到的风险;
-
记录软件运行过程中的一些数据,从而为决策者提供技术支持。
软件测试原则:
- 缺陷集群性,2/8定律:核心功能占20%,非核心占80%,我们会集中测试20%的核心功能,发现缺陷的几率会高于80%,因此,遇到的缺陷都会集中20%功能模块里。
- 穷尽测试是不可能的:有些功能是无法将所有测试情况逻辑出来的,任何的测试都有结束的时间。
- 测试需要尽早介入:为了更好地发现和解决软件中的缺陷。
- 杀虫剂悖伦:同样的一个测试用例不能重复执行多次,不然软件会对它产生免疫
- 测试显示软件存在缺陷
- 测试活动依赖于测试内容:某些测试需要依赖于特殊的环境
- 没有错误是好是谬论:任何软件都不可能是完美的
2. 测试人员在测试中的任务是什么?
- 尽早的找出系统当中的Bug
- 避免软件开发过程中缺陷的出现
- 确保缺件的质量
- 关注用户的需求,并保证系统符合用户需求
3. BS/CS架构的区别是什么?
-
概念:所谓的架构就是用来指导我们软件开发的一种思维,目前最常见的就是BS/CS。
①B -- browser 浏览
②C -- client 客户
③S -- server 服务端
-
区别:
①标准:相对于C/S架构来说B/S架构的两端都是使用现成的成熟产品,B/S会显示的标准一些。
②效率:相对于B/S架构来说C/S中的客户端可以分担一些数据的处理,执行效率会高一些。
③安全:B/S架构当中得到数据的传输都是以Http协议进行传输的,而Http协议又是明文输出。可以被抓包,那么B/S架构相比C/S架构显得就不那么安全了
④升级:B/S架构只需要在服务器端将数据进行更新,前台只需要刷新页面就可以升级,而C/S架构必须要将两端都进行更新才可以。
⑤开发成本:相对于B/S架构来说C/S当中的客户端需要自己开发,B/S不用,所以说C/S成本会高一些。
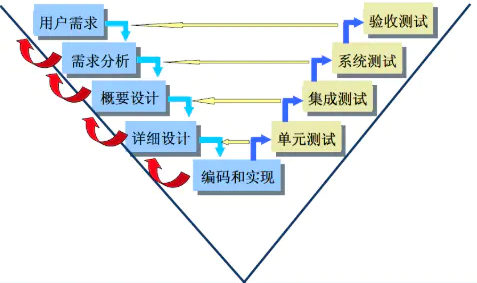
4. 请您描述一下测试的V和W模型?
用户需求-需求分析-概要设计-详细设计-编码-单元测试-集成测试-系统测试-验收测试

5. Bug不能复现怎么办?
- 首先考虑环境问题,看是否能够还原原来的环境
- 尽量回想发生问题时的复现步骤,不要漏掉任何一个细节,按照步骤的组合尝试复现
- 与开发人员配合,让开发人员对相应的代码检查,看是否通过代码层面检查出问题
6. 软件测试的分类
- 技术:黑、白、灰
- 阶段:单元、集成、系统、验收
- 其他:冒烟、随机、回归、兼容、内侧、公测
7. 缺陷引起原因
- 软件结构复杂
- 编码问题
- 使用新技术
- 需求不明确或者更改需求
- 项目周期短,时间紧迫
8. 缺陷报告内容包括什么?
- Bug的优先级
- Bug的严重程度
- 指派人
- Bug可能属于的模块。如果不能确认,可以由开发人员来判读
- Bug标题,需要清晰的描述现象
- Bug重现步骤、预期结果、实际结果
- Bug附件中能给出相关的日志与截图
9. Bug流转过程

10. 软件测试的需求标准是什么?
- 文档版本信息:包含文档版本,作者,完成日期,修订版需要加上修订记录(版本号,修订者,日期,内容)。
- 目录结构要清晰,不同级别的标题要区分字号。
- 产品架构:一般只有功能以及信息架构,
- 功能:一级-二级,三级功能要划出。以及产品特性(功能列表,原型界面,详细设计)。
11. 测试计划工作的目的是什么?测试计划文档的内容包括什么?
目的:明确测试任务与测试方法,保持测试实施过程的顺畅沟通。
内容:测试目的、测试资源、测试范围、测试风险、人员分工、测试策略、测试准则、测试进度、提交测试文档。
12. 测试报告包括哪些?
- 概述
- 编写目的:测试报告的描述、项目简介、测试内容描述。
- 人员分工:姓名、职务、任务
- 测试环境:软件、硬件环境
- 测试过程
- 测试进度:测试任务、测试负责人、启动时间、计划完成时间、实际完成时间、备注
- 用例执行情况:模块、用例总数、执行用例数、通过用例数、未通过用例数、阻塞用例数
- 缺陷统计:模块、bug总数、新增bug总数、修复bug总数、遗留bug总数
- 缺陷分析
- 按照级别分:
- 按照缺陷模块分:
- 按照缺陷类型分:版本、趋势
- 测试总结
- 测试结论:是否通过。各种率、按级别描述缺陷
- 风险分析:编号、风险描述、规避方法和建议
- 遗留问题:编号、缺陷描述、缺陷等级、处理方法
13. 测试用例评审的流程是什么?
1. 目的:主要是为了开展测试用例评审工作提供指引,规范测试用例管理工作。
2. 准备:时间、会议室、完整测试 用例
3. 与会人员:产品经理、开发人员、测试人员
4. 流程:
①开始评审:测试人员讲解测试用例,评审人员提出疑问,相关人员解答
②内容评审
模板:测试用例是否按照公司定义的模板进行编写的;
正确性:测试用例的本身的描述是否清晰,是否存在二义性;
一致性:必须与其他软件需求或高层需求不相矛盾 操作步骤应与描述是否相一致;
覆盖率:测试用例是否覆盖了所有的需求;
可行性:其每一项需求都必须是已系统和环境的权能和限制范围可以来实施的
可测性:每项需求都能通过设计测试用例或其他的验证方法来进行测试
分配优先级:应当对所有的需求分配优先级
必要性:每项需求都是用来授权你编写文档的“根源”,要使每项需求都能回潮至某项客户的输入。
可修改性:每项需求只应在SRS中出现一次,这样更改会容易保持一致性。
可跟踪性:软件需求、源代码、测试用例之间建立起链接
③结束
是否有争论,如果有是否需要二次评审,如需要给出二次的时间、地点
④内容记录整理
测试和对应研发人员做好信息记录
14. 测试用例的方法有哪些以及包含的内容?
方法:等价类划分法、边界值分析法、场景法,因果图、错误推测法
解释:
- 等价类划分:把所有可能输入的数据分为若干个区域,然后从每个区域中取少量有代表性的数据进行测试即可,分为有效等价类和无效等价类。
- 边界值分析法:取稍高于或稍低于边界的一些数据进行测试,使用离点、上点、内点确定取值。
- 错误推测法:测试经验丰富的人喜欢使用的一种测试用例设计方法。
一般这种方法是基于经验和直觉推测程序中可能发送的各种错误,有针对性地设计。只能作为一种补充。 - 因果图方法:比较适合输入条件比较多的情况,测试所有的输入条件的排列组合。所谓的原因就是输入,所谓的结果就是输出。
- 场景法:通过模拟业务场景来对系统的功能点或业务流程的描述,从而提高测试效果的黑盒测试方法
15. 写好测试用例的关键 /写好用例要关注的维度?
- 覆盖用户的所有需求;
- 从用户使用场景出发,考虑用户的各种正常和异常的使用场景;
- 用例的颗粒大小要均匀。通常,一个测试用例对应一个场景;
- 用例各个要素要齐全,步骤应该足够详细,容易被其它测试工程师读懂,并能顺利执行;
- 做好用例评审,及时更新测试用例。
16.红包的测试用例?
- 功能:
a)在红包钱数,和红包个数的输入框中只能输入数字
b)红包里最多和最少可以输入的钱数 200 0.01
c)拼手气红包最多可以发多少个红包 100
d)超过最大拼手气红包的个数是否有提醒
e)当红包钱数超过最大范围是不是有对应的提示
f)当发送的红包个数超过最大范围是不是有提示
g)当余额不足时,红包发送失败
h)在红包描述里是否可以输入汉字,英文,符号,表情,纯数字,汉字英语符号,
i)是否可以输入它们的混合搭配
j)输入红包钱数是不是只能输入数字
k)红包描述里许多能有多少个字符 10个
l)红包描述,金额,红包个数框里是否支持复制粘贴操作
m)红包描述里的表情可以删除
n)发送的红包别人是否可以领取
o)发的红包自己可不可以领取 2人
p)24小时内没有领取的红包是否可以退回到原来的账户
q)超过24小时没有领取的红包,是否还可以领取
r)用户是否可以多次抢一个红包
s)发红包的人是否还可以抢红包 多人
t)红包的金额里的小数位数是否有限制
u)可以按返回键,取消发红包
v)断网时,无法抢红包
w)可不可以自己选择支付方式 - 兼容:
a)苹果,安卓是否都可以发送红包
b)电脑端可以抢微信红包
c)界面
d)发红包界面没有错别字
e)抢完红包界面没有错别字
f)发红包和收红包界面排版合理,
g)发红包和收到红包界面颜色搭配合理 - 安全:
a)对方微信号异地登录,是否会有提醒 2人
b)红包被领取以后,发送红包人的金额会减少,收红包金额会增加
c)发送红包失败,余额和银行卡里的钱数不会少
d)红包发送成功,是否会收到微信支付的通知 - 易用性(有点重复):
a)红包描述,可以通过语音输入
b)可以指纹支付也可以密码支付
17.你都做过什么测试
功能测试、用户体验测试、性能测试、UI测试、兼容性测试、安装测试、文档测试、稳定性测试等。
在公司中大部分是做的功能与接口测试。
18. 软件质量的特性是什么?
- 功能性:软件需求要满足用户显示或者稳式的功能。
- 易用性:软件易于学习和上手使用。
- 可靠性:软件必须实现需求当中指明的具体功能。
- 效率性:类似于软件的功能。
- 可维护性:需求软件具有将某个功能修复之后继续使用的功能。
19. 如何提交高质量的软件缺陷记录(报告)?
- 通用UI要统一、准确。
- 尽量使用业界惯用的表达术语和表达方法
- 每条缺陷报告只包括一个缺陷
- 不可重现的缺陷也要报告
- 明确指明缺陷类型
- 明确指明缺陷严重等级和优先等级
- 描述 (Description) ,简洁、准确,完整,揭示缺陷实质,记录缺陷或缺陷出现的位置
- 短行之间使用自动数字序号,使用相同的字体、字号、行间距
短行之间使用自动数字序号,使用相同的字体、字号、行间距,可以保证各条记录格式一致,做到规范专业。
20. 怎样保证覆盖用户需求
- 分析显性需求:使用思维导图梳理需求文档中所有功能。
- 分析隐性需求:行业规范标准、研究行业标杆软件取长补短、站在用户的角度分析问题、通用规范
- 合理使用合适的用例设计方法
- 严格的用例评审:组内评审和组外评审
21. 开发环境与测试环境有什么区别?
开发环境:是在编码阶段,一般我们的代码基本上都是在开发环境中,不会再生产与测试环境,如操作系统,web服务器,语言环境,php,数据库等等。
测试环境:项目完成后,找Bug,以及修改Bug。
生产环境: 项目数据前后端已经疏通,部署到阿里云上有客户去使用以及访问,网络正常运行就好了。
22. 如果给你购物商城网页你会怎样进行测试?
-
首先要先进行需求分析,xmind梳理测试点,编写、评审用例,寻求他人意见,再完善案例,交给其他人检查。
-
测试点:如UI,美观度,易操作型,易理解型方面进行测试。
-
在考虑功能点,如登陆注册,添加购物车,下单,付款,发货,确认收货,评价。
-
性能方面:如打开网页,确认订单,付款的响应时间等。
-
兼容性:如支持各种主流浏览器,如(EI,360,火狐,谷歌等)。
注意:
①思路一致,都是功能和非功能(统一 一种)
②常用用例:电梯、红包、水杯、笔、朋友圈、购物车、搜索、登录注册、支付、评论(一键三联)
23. 跟开发人员因为BUG产生分歧你是如何解决的?
-
明确开发不修改该缺陷的原因
-
通过需求文档去确认与评估是否一个缺陷
-
如果不是缺陷修改测试用例和开发沟通,如果是一个缺陷找开发沟通确认缺陷
-
如果开发认为是一个缺陷,等着解决;如果不认为是缺陷,上报TM沟通,带着开发与PM的沟通并确认是否缺陷
注:TM表示测试经理 PM表示产品经理强调沟通。
24. Cookie和Session的区别与联系
- Cookie是存放在浏览器的,Session是存放在服务器;
- Cookie不是很安全,涉及用户隐私方面尽量放在Session;
- 当访问量大的时候,Session会占用服务器资源
25. 搭建过什么环境,搭建工作环境是如何搭建的?
搭建过web测试环境 app测试环境等
个人PC(windows)可以搭建测试环境,但是由于个人PC硬件和软件的局限性,我们一般不使用其搭建测试环境,但如果是自己做模拟实验是没问题的。但是在企业中我们一般都不使用windows平台搭建服务器,而是选择Linux平台。这是因为我们经常选择Linux平台作为服务器的操作系统。搭建测试环境
如果你需要搭建的测试环境是刚装的Linux操作系统,
通常测试环境包括JDK环境,Tomcat环境和MySQL环境
下边是安全配置的步骤,大家可以理解,不用强背...,面试的时候,可以说就从网上找一份文档,按照文档进行配置
1.安装jdk
如果有自带,先卸载再装
1.把包复制/usr/local
2.解压
3.配置环境变量
export JAVA_HOME=/usr/local/jdk1.7.0_71
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
4.检查java是否安装成功
java -version
2.安装tomcat
1.把下载的tomcat包复制/usr/local
2.解压
3.在tomcat/bin目录执行startup.sh文件
启动服务
在浏览器中连接:IP:8080
4.如果连接不上,但tomcat又是显示启动OK,检查firewall
路径为 /etc/sysconfig/iptables,将8080端口开启
5.重启服务
3.安装数据库
数据库一般安装mysql和oracle多一些
首先下载相应的数据库安装包
mysql安装比较简单,可以使用源码安装,也可以使用yum在线安装,在这里简单地介绍一下yum在线安装
用yum在线安装
1. rpm -qa|grep mysql --检查Linux是否有存在的mysql
2.如果有mysql,卸载
rpm -e --nodeps mysql
3.安装
yum install mysql-server mysql mysql-dev -y
4.安装成功后,启动服务
service mysqld start
service 服务名 restart/start
5.直接输入mysql 进入到数据库
以上的只会在干净的操作系统上进行安装,一般来说只需要安装一次
26. 你们项目最佳的并发用户数是多少?
我们当时做到1500个并发用户的时候,查询功能的响应时间超过了性能指标2秒多,原因是有几个表的索引建得不合理导致的,我们当时做到1500并发用户后,就没再继续增加用户量了。
27. 如何判断网络是否存在瓶颈?
在性能测试结束之后,我们会根据性能测试的结果,查看在整个性能测试过程中,网络的吞吐量是多少,如果网络的吞吐量占到了服务器的70%以上,我们就认为网络存在瓶颈,通常会增加带宽或者压缩传输数据。
28. 如何判断响应时间不达标
响应时间不达标的话,我们会根据性能测试结果先检查看下是否是服务器带宽存在问题,如果带宽存在瓶颈,则会考虑增加带宽或者压缩传输数据,如果带宽没有问题的话,我们会从服务器上导出日志,开发一起讨论分析是哪个地方导致响应时间过长,确定问题后,就提单给开发修复,修复好了就进行回归测试。
29. 如何判断CPU使用率不达标
CPU使用率不达标,我们会从服务器上导出日志,分析是哪个地方导致CPU使用率不达标,如果分析不出来,就叫上开发一起讨论,确定问题后,就提单给开发修复,修复好了就进行回归测试。
30. 你在项目中最经典的BUG是什么?
- 兼容性问题,在ie浏览器,提交订单按钮可以点击,到了谷歌,火狐就不能了。
- 查询订单页面,根据条件筛选的结果不是想要的结果,还有某些字段的值没有显示出来,或者显示错误。(因为开发从库表取值有误)
- 付款成功后,订单状态一直不翻转为交易成功。(因为代码没有正确获取库表中付款成功记录的状态码)
- 修改支付密码,新密码和原密码一致,也通过了,系统没有做新旧密码的校验。
- 付款时候的手机验证码,可以一直使用,没有成功-做有效期控制。
- 手机app断开网络后,再去点击,没有友好的错误页面提示网络已断开,只有undefined返回
31. 你在你工作中遇到最棘手的问题是什么?
- bug无法复现
- 查询功能,翻页后第二页的内容与第一页的内容完全相同。原因是翻页的时候刷新了页面触发了查询语句。印象最深的原因:发生过两次,才知道原因所在。
32. Bug不能复现怎么办?
- 首先考虑环境问题,看是否能够还原原来的环境
- 遇到问题就要提,不能放过任何一个Bug,在提交的Bug描述中加上一句话,那就是复现概率,尝试20次,出现一次或尝试10次,交给开发,开发会根据Bug的复现概率,调整改Bug的优先级。
- 尽量回想发生问题时的复现步骤,不要漏掉任何一个细节,按照步骤的组合尝试复现
- 与开发人员配合,让开发人员对相应的代码检查,看是否通过代码层面检查出问题
- 保留发生bug时的log,附加到提交的Bug中,希望可以通过log中找到一些蛛丝马迹。
- 查看代码,也许是代码变更,引起的Bug
33. MySql数据库查询语言有哪些?多表联查会吗?什么是子查询?
-
DDL:数据定义语言
-
库
1. 查看数据库 show databases 2. 创建数据库 create database 库名 3. 删除数据库 drop database 库名 4. 切换数据库 use 库名 5. 显示创建数据库的细节 show create database 库名 6. 创建一个gbk的数据库 create database 库名 character set gbk -
表
1. 显示所有表 show tables 2. 创建表 create table 表名(类型 字段名,类型 字段名) 类型:数字类型、字符串、日期 3. 删除表 drop table 表名 4. 查看表结构 desc 表名 5. 查看创建表结构细节 show create table 表名 6. 添加列(字段) alter table 表名 add 字段名 类型 7. 删除列(字段) alter table 表名 drop 字段名 8. 表格约束条件 主键:primary key 自增:auto_increment 非空:not null 唯一:unique
-
-
DML:数据操作语言
-
插入数据
insert into 表名 values(数据) insert into 表名(字段名,字段名) values(对应前边字段的数据)插入中文注意:
set character_set_client = gbk; set character_set_results = gbk charset gbk; -
删除数据
delete from 表名 delete from 表名 where 字段=数据 truncate table 表名 -
修改数据
update 表名 set 字段=数据 update 表名 set 字段=数据 where 字段=数据 update 表名 set 字段=数据,字段=数据 where 字段=数据
-
-
DQL:数据查询语言
select * from 表名 select * from 表名 where 字段=数据 select 字段 from 表名 where 字段=数据 select * from 表名 where 字段>=<数值 select 字段1 as 名字1,字段2 as 名字2 from 表名 where 字段=数据 select * ,math+10 from 表名 //统计每个学生的总分 select name as 姓名,(math+english+chinese) as 总分 from student //查询总分大于230分的同学 select * from student where (math+english+chinese)>230 //查询数学成绩在80-90之间的同学 select * from student where math between 80 and 90 //查询数学语文英语都大于80的同学成绩 select * from student where math>80 and english>80 and chinese >80; //查询数学成绩在 80 60 90内的同学,即数学成绩有60、80、90的。 select * from student where math in(80,60,90); //模糊查询 // _ 代表一个,% 代表多个(0 - +∞) //查询所有姓名中包含张的同学 select * from student where name like ‘%张%’ //排序 select * from 表名 order by 字段 (asc) select * from 表名 order by 字段 desc //分页查询:从m+1开始,n条数据 select * from 表名 limit m,n //分组 select * from 表名 group by sex having age>18; //聚合函数 count 个数 sum 总数 avg 平均数 max 最大值 min 最小值 //子查询 //李老师的所有学生 select * from stu where id in(select s_id from ts where t_id=(select id from t where name="李老师")); //张三所有老师 select * from tea where id in(select t_id from ts where s_id=(select id from s where name="张三")); //交叉查询=笛卡尔积查修 cross join on , 内连接查询 inner join on 左外连接查询 left join on 右外连接查询 right join on 统计小于60,大于80,60-80之间的学生人数 select sum(if(score<60,1,0)) as '<60' ,sum(if(score between 60 and 80,1,0)) as '60-80',sum(if(score>80,1,0)) as '80' from s; 去重 select distinct name from s; -
案例
-
数据库语言最常SQL (结构化查询语du言)
创建表:create table user(id int(11) primary key auto_increment,name varchar(20),age int(4),sex varchar(10),); 增:insert into user(name,age,sex) values(?,?,?); 删:delete from user where name=?; 改:update user set age=?,sex=? where name=?; 查询所有:select * from user; 根据名称查找:select * from user where name=?; -
多表联查:
select * from customer,orders; select * from customer,orders where customer.id=orders.customer_id; select * from customer c left join orders o on c.id=o.customer_id; select * from customer c right join orders o on c.id=o.customer_id; -
子查询:老师和学生
//查询李老师所教的学生 select id from teacher where name=’李老师’ select student_id from teacher_student where teacher_id=id select * from student where id in(select student_id from teacher_student where teacher_id =(select id from teacher where name='李老师')); //查询张三的所有老师 select * from teacher where id in(select teacher_id from teacher_student where student_id=(select id from student where name='张三'));
34.SQL语句处理与代码处理哪个好,举例?
如果用sql语句,数据处理比较快,处理后传输的数据量稍大,由123变成了汉字。
在代码中处理,传输的数据量小点,处理速度取决于代码怎么处理。
如果数据量不大,两种方法区别不明显,建议用sql语句。
35. SQL内关联和外关联的区别?
内联接是求交集
左外是将两张表对应的数据查询出来,同时将左表自己没有关联的数据也查询出来;
右外是将两张表对应的数据查询出来,同时将右表自己没有关联的数据也查询出来。
36. having和where的区别?
1.一般情况下,WHERE 用于过滤数据行,而 HAVING 用于过滤分组。
2.WHERE 查询条件中不可以使用聚合函数,而 HAVING 查询条件中可以使用聚合函数。
3.WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤 。
4.WHERE 针对数据库文件进行过滤,而 HAVING 针对查询结果进行过滤。也就是说,WHERE 根据数据表中的字段直接进行过滤,而 HAVING 是根据前面已经查询出的字段进行过滤。
5.WHERE 查询条件中不可以使用字段别名,而 HAVING 查询条件中可以使用字段别名。
37.liunx磁盘满了,怎么处理?
ls –bailR /home >;files.txt
diff filesold.txt files.txt
38.Linux系统操作的指令说一下:增加,删除,复制,移动等问题?
目录操作
cd usr/ 切换到该目录下usr目录
cd .. 切换到上一层目录
cd / 切换到系统根目录
mkdir 目录名称 创建目录
ls 目录名称 查询该目录下所有的目录和文件
ls [-a] 目录名称 查询该目录下所有的目录和文件,包含隐藏文件
ls [-l] 目录名称 查询该目录下所有的目录和文件的详细信息
find / -name 目录名称 查找/root下的目录(文件)
mv 目录名称 新目录名称 修改目录名称
mv 目录名称 目录的新位置 剪切
cp -r 目录名称 目录的目标位置 拷贝
rm -rf 目录 强制删除目录
文件操作
touch 文件名称 创建空文件
cat/more/less/tail 文件 查看文件内容
tail -f 文件 动态查看/实时查看文件(日志)
grep 要搜索的字符串 要搜索的文件 关键字搜索
vi/vim 文件 修改文件内容
rm -rf 文件 强制删除文件
文件的打包
tar -zcvf 文件名.tar 要打包的文件
文件的解压
tar -xvf 文件名.tar
扩充:将文件解压到固定位置
tar -xvf 文件名.tar -C 指定解压的位置
查询当前所在位置
pwd
查看进程
ps -ef | grep 进程名称(tomcat/mysql)
杀死进程
kill -9 进程pid
查看端口号
netstat -an | grep 端口号(3306)
查看服务器ip
ifconfig
查看网络是否能正常使用
ping 外网地址 查看是否能访问外网
ping 内网ip 查看是否能访问内网
权限命令
chmod 777 文件 赋权
查看cpu
top
查看磁盘信息
df -h
查看内存信息
free
关机命令
shutdown -h now 立刻关机,其中now相当于时间为0的状态
shutdown -h 10:23
shutdown -h +10 系统再过十分钟后自动关机
重新启动
reboot 重新启动操作系统
sed
awk
Tar -n logcat 查看系统日志
39. 接口依赖 = 接口关联
(1)postman接口依赖怎么实现
①第一个接口的响应的某个value值,在test中提为全局变量pm.gloabls.set('k',v)
②第二个接口中调用去全局变量{{k}}
(2)jmeter接口依赖怎么实现
①在第一个接口中,通过正则提取器提取响应一个字段k
②在第二个接口中,使用${k}作为一个入参
(3)自动化request如何实现接口依赖
①抽取登录接口返回值中的token = jsonpath(res,'$..token')[0]
②使用全局变量存储Context.token = token。
③其他接口将token=Context.token值放入请求头,发送请求。
40. Linux上能不能直接进行性能测试?
不能,脚本需要通过windows调试好后,才能在Linux上运行,运行的时候,只能通过non GUL形式进行启动jmeter,但需要注意的是,csv文件在windows上与LInux上要统一路径,最好使用相对路径,放到统一目录下边。
41.shell写脚本
- 语法
- 执行
42. 请说几个常见的状态码
100:继续,客户端应继续其请求
101:切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议
200:请求发送成功。
301:永久重定向。
302:临时重定向。
400:客户端请求的语法错误,服务器无法理解。
401:请问的页面没有授权。
403:没有权限访问这个页面。
404:服务器无法根据客户端的请求找到资源(网页)
500:服务器内部错误,无法完成请求
501:服务器不支持请求的功能,无法完成请求
502:作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
43. OSI与TCP/IP网络模型?TCP与UDP的区别?
-
概念
①OSI模型:物理层、链路层、网络层、传输层、回话层、表示层、应用层
②tcp/ip模型:网络接口层、网际层、运输层(TCP/UDP)、应用层(HTTP)
-
TCP与UDP区别
① TCP:传输控制协议,建立连接、 安全可靠协议、以流进行数据传递,无大小限制、三次握手协议、四次挥手
②UDP:数据包协议、不建立连接、不可靠协议、以数据包传递、有大小限制64k
44. 什么是Http协议,请求方法是什么?Http协议与Https协议的区别?
- Http协议:又叫超文本传输协议,是定义了一个客户端到服务器请求与应答的标准。
- 请求方法:get、post、head、delete、put、patch。
- HTTPS协议:以安全为目标的HTTP通道,简称Http的安全版。
- HTTPS与HTTP的区别:
A. http协议是超文本传输协议,是无状态的,而https协议是由SSL+http协议构建的可进行加密、更安全的传输协议;
B. https协议需要ca申请证书,一般免费证书较少,需要一定费用;
C. http协议与https协议使用的链接方式不同,http用的端口是80,https是443。
45. get请求与post请求的区别?
- Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。
- Get传送的数据量较小,这主要是因为受URL长度限制;Post传送的数据量较大,一般被默认为不受限制。
- Get执行效率却比Post方法好。Get是form提交的默认方法。
46.为什么要进行抓包?
- 有些时候公司没有标准的接口文档,测试人员只能抓包来获取接口测试。
- 抓包可以迅速找到请求,通过抓包可以查看整个请求的过程,以及响应时间,还可以分辨前台与后台Bug。
- 通过抓包,可以查看是否有敏感信息,如(用户密码,个人账户信息等数据)
- 可以通过抓包进行测试,拦截请求,修改请求数据,查看对应的响应结果,抓包本身就是接口的一部分。
47.Charles有哪些功能
- 网络抓包
- 移动端抓包
- 证书安装
- 断点
- 过滤
- 模拟慢速网络
- 修改网络请求
- 压测服务器
- 模拟404、403
48.如何移动端抓包?https怎么抓包
1. 移动端如何抓包?
A. 设置Http代理,设置端口号,在手机上设置与fiddler在同一网段上,设置代理ip,设置代理端口,手机上的请求就能获取到了。
B. 抓取请求查看,可以过滤,找到自己域名下的请求,通过分析请求地址,请求参数,响应结果来查找问题。
2. Https包怎么抓?
A. http与Https协议区别在于Https多了一个ssL协议,更加安全,默认端口是443,而http默认端口是80.
B. 抓取Https时,需要获取申请证书,在fiddler与charles两个工具中,可以模拟下载966证书,下载后,在手机上访问代理服务器的ip与端口,下载证书,就可以抓取到HTTPS的请求了。
49. Postman做哪些操作?
- 接口功能测试
- 接口集,导入,导出
- 批量执行
- 内置脚本-断言
- 接口依赖=接口关联,使用步骤(同jmeter)
- 预处理脚本
50.Postman与Jmeter的区别是什么?
- 用例组织不同,jmeter的组织是比较扁平,首先他没有工作空间的概念,直接就是测试计划,而postman功能上更简单,组织方式是轻量级,他主要针对的是单个的http请求。
- 支持接口的类型与测试的类型不同:jmeter的功能更强大,可以通过各种类型的接口,不支持的也可以通过网上或者自己编写的插件进行扩展,而postman更轻量级,定位不同,可用来测试Rest接口。
- 配置不同:jmeter可以在线程组里添加http,tcp,而postman只支持Rest接口。
51. 性能测试关注的指标是什么?
-
响应时间:发送请求+服务器处理请求+接受响应,258原则
-
并发用户数:同一时刻向发送请求的用户数,秒杀、请购、红包等。
-
吞吐量(throughput):单位时间内处理请求数
-
QPS(Query per second):每秒查询数,单位时间内服务器处理请求数
-
TPS(Transaction per second):每秒事务数,单位时间内服务器处理事务请求数
-
点击数:页面所有元素请求数量
-
错误率:失败个数
-
资源使用率
CPU 75-85% 内存 80% 磁盘速率 90% 网络速率 80%
52. 性能测试怎么做的?
①性能需求分析:挑选了用户使用最频繁的功能来做性能测试,比如:登陆,打开系统首页,搜索,提交订单,确定性能指标,比如:事务通过率为100%,90%的事务响应时间不超过3秒,CPU和内存的使用率为70%以下;
②搭建性能测试环境,编写、评审测试用例;
③使用Jmeter执行测试用例,设计性能测试场景,我们这个项目做了单用户单功能循环200次的基准测试,然后使用1500个用户,执行30分钟的负载测试,看系统有没有性能瓶颈;做了参数化、断言、接口依赖。
④分析性能测试结果,如果有性能瓶颈,收集相关的日志提单给开发修改。
⑤开发修改好后,回归性能测试,输出性能测试报告。
53. 思维开拓题
54. App的性能测试怎么做的?
总概述:App的性能分为服务器端的性能和手机端的性能。 服务器端的性能,我们用Jmeter工具进行测试的。
App性能:手机端App的稳定性测试是用monkey做的,使用monkey跑12万次,看它会不会出问题,如果出了问题,我们再定位原因。
具体的做法是这样的:下班时,执行monkey命令12万次:adb shell monkey -p com.example.login --ignore-crashes --ignore-timeouts --throttle 300 --pct-touch 50 --pct-motion 50 -v -v 120000 >c:\login\c.txt
日志分析:看看monkey日志中有没有crash、anr、fatal、exception的关键字,如果有定位到是什么原因导致的,将相关logcat日志与进程号提交给开发定位,如果是anr的问题,还需要从安卓中获取/data/anr/traces.txt文件提交给开发定位。
55.怎样分析性能测试结果?
- 查看聚合报告和服务器的资源使用图,检查响应时间,事务成功率,CPU,内存和IO使用率是否达到要求,如果出错率达到了总请求数的3%,我们会检查是什么原因导致的,修改好后,重新测试;
- 如果出现了性能瓶颈,比如响应时间,或者CPU使用率不达标,我们会从服务器上导出日志,分析是哪个地方导致响应时间过长,如果分析不出来,就叫上开发一起讨论,确定问题后,就提单给开发修复,修复好了就进行回归测试。
56.列表与元组的异同点
-
相同点
- 都是序列
- 都可以存储任何数据类型
- 可以通过索引访问
-
不同点
- 语法差异:列表使用[]创建,元组使用()创建
- 是否可变:列表是可变的,而元组是不可变的,这标志着两者之间的关键差异。可以修改列表的值,但是不修改元组的值。
- 重用与拷贝:元组无法复制。 原因是元组是不可变的。
- 大小差异:Python将大内存块分配给元组,因为它们是不可变的。 对于列表则分配小内存块。 与列表相比,元组的内存更小。 当你拥有大量元素时,元组比列表快。列表的长度是可变的。
- 同构与异构:习惯上元组多用于用于存储异构元素,异构元素即不同数据类型的元素,比如(ip,port)。列表用于存储同构元素,这些元素属于相同类型的元素,比如[int1,in2,in3]。
57.Jmeter的是如何进行测试的?(请您介绍一下Jemeter是如何使用的?Jemeter如何进行压力测试?)
- 创建线程组,设置线程数、循环次数、准备时间,我这里设置线程数为500,循环一次
- 添加HTTP采样器:配置我接口的协议、地址、端口、方法、路径、编码格式、参数
- 添加断言:json断言和响应断言
- 添加监听器:察看结果树、聚合报告、用表格查看
- 添加Summary Report
- 执行测试计划,需要用命令行来执行
- Web报告
58.Jmeter的连接数据库
- 添加jar包
mysql-connector-java-8.0.11.jar - 配置JDBC Connection Configuration:连接池名字、地址、驱动器、数据库名、密码
- 添加JDBC Request:连接池名字、选择查询类型、输入SQL语句
59. Jemeter为什么要参数化?
- 多用户登录的时候,如果不进行参数化就没演示了。需要使用CSV将参数放到文件,来演示多用户登陆。
- 在进行录制的时候,有可能存在第二个请求的参数是从第一个请求中获取出来的,需要在第一个请求下,去将参数提取出来,再到第二个请求中进行参数化。
60. Jemeter中有哪些常用元件或组件?
-
测试计划:jmeter性能测试起点,其他元件容器
-
线程组:性质相同的一组线程
线程数:模拟用户数
准备时间:启动所有用户所用的时间
循环次数:
-
采样器:
- http:协议、主机地址、端口、请求方法、路径、编码格式、参数
- jdbc
-
监听器:采集测试结构
①查看结果树:采样器结果、请求、响应数据
②聚合报告:label、#samples、average、median、90%line、min、max、error%、throughput、rec/sec、send/sec
③用表格查看:sample#、starttime、thread name、label、sample time、status、bytes、send bytes、latency、connect time、样本数、最新样本、平均响应时间、偏离
-
循环控制器:控制采样器执行次数
-
事务控制器
- 事务:多个操作组合
- 作用
- 勾选
-
固定定时器
控制两个采样器的间隔
-
断言
- Json断言:判断某个key对应某个value
- 响应断言:响应中包含某个串
-
前置处理器和后置处理器(正则、json提取器)
-
参数化
-
用户自定义变量:
- 作用:提供全局变量,方便修改
- 使用:配置元件 → 用户定义的变量 → key value → $
-
CSV data set config
- 配置文件:
- 添加元件:CSV data set config → 选中文件 → 编码 → 字段1,字段2
- 在采样器界面:添加参数 → 调用$
-
CSV函数小助手
工具 → 函数小助手 → 选择CSV Read → 复制文件路径 → 字段编号 → 生成 → 自动复制,过去粘贴
-
61.你做过单元测试吗?步骤是什么?
1. 拉取开发代码
2. 编写测试用例
3. 写开发需要用到的数据
4. 读取数据
5. 在用例代码中调用数据
6. 用HTMLTestRunner.py生成测试报告
62. Unittest和Pytest区别?
| Unittest | Pytest |
|---|---|
| python自带单元测试框架,测试类直接继承unittest.TestCase | 需要安装,但不需要继承 |
| 测试函数必须以“test”开头 | 测试类和测试函数必须以“test”开头 |
| 参数化需要依赖三方库nose_parameterized | 直接使用内部的@pytest.mark.parametrize |
| 测试报告需要下载HTMLTestRunner | 需要pytest-html,或者allure |
| 没有插件 | 有很丰富的插件 |
| 不支持失败重试 | 支持失败重试 |
| 断言assertEqual(a,b) | assert a==b |
| 环境准备setup[class],环境还原teardown[class] | 可以设置执行用例的具体部分 |
63.接口测试流程?
- 分析接口文档,了解请求URL请求的方法、请求的媒体格式、每个入参和出参的含义
- 编写、评审接口测试用例
- 使用Postman或者是Jmeter,也可以用脚本来执行接口测试用例
- 在执行的过程中如果有bug,提交bug,开发修改bug,回归测试
- 提交测试报告
- 进行线上环境的回归测试
64. 举例说一下你的接口测试是怎么做的?
- 下单这个接口用的是http协议,使用post请求方式,发送给服务器的参数有token,产品ID,购买数量,收货人地址等等,这些参数都是必传的参数。
- 我们是使用Jmeter来做接口测试的,首先,要新建一个线程组,在线程组下面添加一个http的请求,然后填写好服务器地址,接口路径,请求方式,请求参数。
- 由于下单的接口依赖于登录,所以我们会先调用登录接口,从中获取token值,在下单接口中使用
${参数名}的方式引用,接下来还要对其他参数进行参数化,构造各种正常和异常的数据,我们先在本地创建一个txt文档,把参数填写到文档里面,在Jmeter中添加一个csv文件设置,填写好txt文档的路径,然后在请求参数中使用Json提取器把token值关联出来,然后在下单接口中使用${参数名}的方式引用;接下来添加断言,检查服务器返回的结果和预期结果是不是一致的。 - 最后,添加查看结果树查看测试结果。
65. 请描述下接口测试与UI测试是如何协同测试的?(可以自己总结)
- 有一部分是重叠的,Ui测试是通过前端写的界面,是来调用接口的,而接口测试是直接调用接口。
- 排除前端的处理逻辑与调用的正确性,在理论上接口测试是可以覆盖所有的Ui测试,但实际中,如接口层覆盖所有的业务流,在Ui上只测试前端的逻辑,而最终的结果会忽视很多原有的功能点,导致了Ui测试的不充分,那么会存在人多分工且时间充分的时候可以尝试接口去做业务流的全覆盖,否则不要轻易的去尝试。
66. 接口自动化
requests + pytest + allure实现自动化
- 准备csv数据
- 读取csv文件
- 结合读取的数据使用requests做http请求,返回列表(状态码、部分字符串)
- 单元测试断言,生成测试报告
67.Web自动化测试流程?PO
1.先分包为base,pages,test
2.创建BasePage基类,抽取公共方法:定位元素、点击元素、输入内容、清空内容、http请求
3.然后写业务逻辑
4.写测试用例最后的执行
68.Web自动化八大元素定位方式?
通过id、name、class_name、xpath、css_selector、link_text、partial_link_text、tag_name定位元素。
一般,如果有id就使用id,然后使用css或者xpath来定位,当然定位的时候,需要在浏览器里边安装firebug firepath来抓取页面元素对应的xpath信息。
69. 浏览器的兼容性测试是怎么测试的?
大型的、用户群体多的网站都需要做浏览器兼容性测试,需要测试主流的浏览器(除特定要求的浏览器以外)
测试的内容:一般是页面的排版,页面格式,字体,颜色,下拉菜单,复选框等测试(UI:CSS,HML,Js在不同浏览器下的表现)
再就是对功能进行检查
为什么选择这几个浏览器?
原因:以浏览器内核分类浏览器进行测试
常见浏览器及四大内核:
IE、360(兼容模式)、搜狗(兼容模式)(Trident内核)
Firefox(Gecko内核)
Chrome、360(极速模式)、搜狗(极速模式)(Blink内核)
Apple Safari(WebKit内核)
70. 如何理解压力、负载、性能测试测试?
性能测试是一个较大的范围,包含基准、稳定性、压力、负载等多方面的测试内容。
基准测试:确定基准线。
稳定性测试:在服务器稳定运行(用户正常业务负载下)的情况进行长时间测试(1天-一周等),并最终保证服务器能满足线上业务需求。
压力测试:在强负载下的测试,查看系统在峰值下是否功能隐患、系统是否具有良好的容错能力和可恢复的能力。
负载测试:通过逐步增加系统负载,确定在满足性能指标的情况下,找出系统所能承受最大负载量的测试。
71. 安全性测试包括哪些方面?
用户验证、用户权限管理、系统数据的保护、SQL注入、反编译、跨站攻击、XSS攻击
72.弱网情况下你是如何测试的?
使用Charles做弱网测试,Proxy → throttling setting → 勾选enable,添加IP,选择速率:
- 2G的网速150kbps,折合下载速度15-20K/S.B=8b.g
- 3G的网速 1-6Mbps,折合下载速度120K/S-600K/S.
- 4G的网速10-100Mbps,折合下载速度1.5M/s-10M/s.
- 使用真实的SIM卡,运营上网络来进行测试。
73. selenium和appium使用,web自动化和App自动化的思路,PO
74.Android和IOS测试区别,系统有什么区别?
Android与IOS测试的区别
相同点:
都需要进行界面测试、功能测试、兼容性测试、网络测试、交互性测试、异常测试、易用性专项测试、安全专项测试以及权限测试。
不同点:
- IOS稳定性比较高 安卓相对的比较差 这个看不同厂商的优化
- 安卓因为开源 而导致碎片化非常的严重 每个厂商都定制了自己的rom(机身内存/存储器)
- 安卓更容易出现信息泄露 权限问题 安全漏洞的问题 等
- IOS 开发的语言是SWift 和 Objetive-c 运行效率很高,而安卓的开发语言是JAVA运行效率比较低
- 咱们在做兼容性测试的时候安卓要做的设备比较多 IOS相对是比较少的
系统区别
- 运行机制不同:IOS采用的是沙盒运行机制,安卓采用的是虚拟机运行机制
- 两者后台制度不同:IOS中任何第三方程序都不能在后台运行,安卓中任何程序都能在后台运行,直到没有内存才会关闭
- IOS中用于UI指令权限最高,安卓中数据处理指令权限最高
75. 手机端测试的关注点有哪些?
专项测试:UI测试,功能,性能测试,安装卸载测试,软件升级测试,登陆测试,安全性测试,消息推送,前后台切换,兼容性测试,网络环境测试,monkey测试。
- 兼容性:
- 系统版本:android:原生安卓系统:4.4 5.8。定制版本:小米、华为、魅族..
IOS:原生系统:5.0.。。 - 屏幕分辨率:7201280 19281888.,图片(根据分辨率做一些图片)
- 网络状态:2g 3g 4g 5g wifi
76. APP测试与Web测试、小程序的区别?
- 相同点:
同样的测试用例方法相同。
同样的测试方法:都会依据原型图或效果图来检查UI。
测试应用系统的稳定性。 - 不同点:
- App的安装卸载:全新安装,升级安装,第三方工具安装,第三方工具卸载,直接卸载删除,消息推送测试,手机授权测试,前后台切换,网络环境(wifi/2G/3G/4G/无网络)。
- App的中断测试:来电中断,短信中断,蓝牙,闹钟,拔插数据线,手机锁定,手机断电,手机问题(系统死机重启)。
- 兼容性测试:Web项目考虑不同浏览器(火狐、谷歌、IE、苹果)和操作系统(win78910、Linux、OS)的兼容,app需要考虑手机不同的操作系统,不同机型,不同屏幕等。
- 网路测试:不同网络与运营商,目前我国有三大运营商如:电信,移动,联通,不同的网络制式,如:GSM,CDMA,3G等,在不好或无网络的情况下的APP行为。
- 网络测试:2345G、WiFi、无网测试、弱网测试。
- 测试用具:自动化工具:APP 一般使用 Appium; Web 一般使用 Selenium
- 界面操作:关于手机端测试,需注意手势,横竖屏切换,多点触控,前后台切换
- 安全测试:安装包是否可反编译代码、安装包是否签名、权限设置,例如访问通讯录等
- 边界测试:可用存储空间少、没有SD卡/双SD卡、飞行模式、系统时间有误、第三方依赖(QQ、微信登录)等
- 权限测试:设置某个App是否可以获取该权限,例如是否可访问通讯录、相册、照相机等
- 性能方面:web项目需监测响应时间、CPU、Memory(Nmon),app项目除了监测响应时间、CPU、Memory外,还需监测流量、电量等(GT)。
77. 测试手机兼容性测试是如何测试的?
一般测试手机兼容性的时候会考虑到手机的型号,分辨率以及安卓版本号,一般常用的手机型号如:华为,锤子,小米,魅族等,一般碎片化会严重,从Android6.0到Android10.0的版本是不一样的,而最近的版本号已经到10了,也就是AndroidQ,它是协助开发者利用5G,折叠屏,无框屏,设备内置Al等最新技术继续创新,同时确保用户安全,隐私及数字健康。向分辨率这块大部分是1920*1080,一般会买真机去测。
78. Appium的工作原理是什么?Selenium工作原理?
我们的电脑(c端)上运行自动化测试脚本,调用的是appium的webdriver的接口,appium服务器(s端)接收到我们client上发送过来的命令后,他会将这些命令转换为UIautomator认识的命令,然后由UIautomator来在设备上执行自动化。
79.说几个常用的adb命令?
adb install -r(apk的文件路径) 安装软件到手机或者模拟器
adb uninstall(包名) 卸载手机或模拟器上的某款软件
adb devices 查看与当前电脑连接的移动设备
adb start-server 启动adb
adb kill-server 杀死
adb logcat 查看日志
adb logcat -s 设备名称 -v time *:W process > path
adb shell
adb shell dumpsys cpuinfo
adb shell getprop | findstr dalvik
adb shell dumpsys meminfo +包名
adb shell pm list packages [-s -3]
80.软件负盖安装的adb命令?
adb install -r xx.apk覆盖低版本的
adb install -r -d 覆盖高版本的
81.性能测试的Adb命令?
adb shell dumpsys cpuinfo 查看手机cpu的使用情况
adb shell getprop|findstr dalvik 手机系统自己运行的内存使用
82.说几个Monkey指令?
adb shell monkey -p 包名
adb-shell--ignore-crashes 忽略崩溃
adb-shell--ignore-timeouts 忽略延时
adb-shell -throttle 300 延时毫秒值
adb-shell--pct-touch--pct-motion 触摸与滑动事件的比例
# 12万次,相当于10个小时,每个300ms操作一次
adb shell monkey -p com.example.login --ignore-crashes --ignore-timeouts --throttle 300 --pct-touch 50 --pct-motion 50 -v -v 120000 > c:\login\c.txt
83. App常见崩溃的原因?
- 设备碎片化:由于设备极具多样性,App在不同的设备上可能有不同表现形式。
- 宽带限制:宽带不佳的的网络对APP所需的快速响应时间不够。
- 网络的变化:不同网络间的切换可能会影响App的稳定性。
- 内存管理:可能内存过低,或非是授权的内存位置的使用可能会导致App失败。
- 空值指针
- 数组越界
- 内存不足
- CPU满负荷(由于现在的手机基本都是8核CPU,所以基本不会出现CPU满负荷的情况)
84. APP出现ANR的原因?
线程阻塞的,内存不足,CPU满负荷(由于现在的手机基本都是8核CPU,所以基本不会出现CPU满负荷的情况)。
85.App自动化元素定位方式
# id → uiautomatorViewer、appium
ele = driver.find_element_by_id(id)
eles = driver.find_elements_by_id(id)
# class → uiautomatorViewer、appium
ele = driver.find_element_by_class_name(class)
eles = driver.find_elements_by_class_name(class)
# Xpath → appium手写
# 手写:Xpath = "//*[contains(@text,'text')]"
# 手写:Xpath = "//*[contains(@id,'id')]"
# 手写:Xpath = "//*[contains(@class,'class')]"
ele = driver.find_element_by_xpath(xpath)
eles = driver.find_elements_by_xpath(xpath)
86. 代码的版本管理用什么工具,上传和合并代码?SVN介绍用的版本管理工具
SVN是Subversion的简称,是一个开放源代码的版本控制系统,说得简单一点SVN就是用于多个人共同开发同一个项目,共用资源的目的
SVN需要部署服务端和客户端,我们公司服务端部署在服务器上,我们只需要在自己的电脑上安装客户端(小乌龟),服务端给分配好账号密码和权限,并且给我们仓库的地址,我们就可以对仓库中的文件或代码进行checkout update commit等操作,当然共同协作开发可能还会有冲突发生,这就需要处理冲突
当然除了SVN我会使用GIT, Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。 是一个开放源码的版本控制软件。Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持。
在使用GIT都是使用指令进行操作:
- 配置用户信息 用户名和邮箱
git config --global user.name "DashShi"
git config --global user.email 805256908@qq.com
- 创建版本库 git init进行仓库的初始化
- 添加文件到版本库(其实是到版本库的缓存)
git add . 把这个文件夹下面所有的文件都添加到库
git add abc.txt 把某一个文件添加到库中
git status -s 可以查看添加的状态
- 提交添加到缓存的文件到真实的仓库git commit -m "提交的信息说明"
- 查看提交的日志/记录
git log
git log --pretty=oneline 简略信息查看日志
- git的远程仓库
//远程仓库存在,把本地的代码推送到远程需要执行
git push -u origin master
- 如果想把github远程仓库的代码拿到本地
git clone "url"
87. 如何定位前后端bug?
-
最容易区分的前端问题
页面上的样式布局、按钮、页面文案、字体大小、图片以及兼容性问题都是前端问题,这个比较容易定位。
-
页面上的报错问题
页面报错了,如何区分前后端呢?如果是web端的项目可以查看开发者工具的Console是否报错,一般报错都是前端问题。
APP的页面报错就会困难些,可以通过接口定位。
-
接口报错定位
首先只要有请求到后端都是需要通过接口请求。
(1)若页面上操作点击没有请求响应,一般是前端没有接入这个功能接口。
(2)有接口请求响应了,我们需要通过请求数据RequestInfo和响应数据Response来定位问题。
①响应数据的返回值返回的报错信息,大部分情况都是后端问题;注意状态码500开头的都是服务端问题。
②除后端有问题外,前端也可能有问题。需要通过请求参数来验证,如参数拼接错误、名称错误、参数值错误等都是前端导致 的。状态码400开头的都是属于客户端问题。
③我们还可以借助数据库以及日志来清晰定位后端问题,如空指针异常、数组下标越界、数据字段长度溢出等等问题。
-
逻辑问题定位
要清晰定位逻辑问题必须对项目的需求逻辑非常清楚,要知道是前端做的逻辑处理,还是后端做的处理。有些限制前后端都必须做处理。
87.Oracle与MySQL区别
- Oracle是大型数据库,而MySQL是中小型数据库。但是MySQL是开源的,Oracle是收费的
- Oracle的内存占有量非常大,而mysql非常小
- MySQL支持主键自增长,插入时会自动增长。Oracle主键一般使用序列。
- MySQL分页用limit关键字,而Oracle使用rownum字段表明位置
- MySQL中0、1判断真假,Oracle中true false
- MySQL中命令默认commit,但是Oracle需要手动提交
- MySQL在windows环境下大小写不敏感,在linux环境下区分大小写,Oracle不区分
88. 测试常问的几个数字
(1)这个项目总共写了多少条用例?多久迭代一次?
我们做的这个xx项目用例数大概在1200条左右,如果再复杂点的有2000条左右。我们项目采取双周迭代的模式。
周一:进行需求评审,需求评审会出现一些有歧义的地方,产品进行修改,直到产品,研发,测试达成一致,无异议。
周二:如果需求评审完毕,测试基于确定的需求进行测试计划的编写
周三:写用例,在编写用例的过程中甚至会有一些需求的缺陷点被发掘出来,找产品确认,包括对齐,按照对齐之后的需求,修改有影 响的模块用例,以及编写剩余的用例,强调一点,中间会有部分之前迭代的用例被复用。
周四:有可能用例没完成,还会继续编写(复杂点可能就300条左右,这个数字包含之前复用的用例),以及输出冒烟测试用例。
周五:大前端可能没有开发完毕,我们先进接口测试、集成测试
周一、周二:开发提测,第一轮测试
周三:回归测试(第二轮)
周四:质量好的时候,基本以及第三轮测试(选取主功能进行测试),准备上线以及线上验证。
周五:线上问题实时跟进,以及线上环境的功能验证
(2)一天编写多少条?一般是没有具体数量的,主要看负责模块的复杂度、用例执行步骤、用例颗粒度,一般50条左右
(3)一天执行多少条?这个没有标准,遇到阻塞用例,可能一条都完不了。多场景交互的也就 30-40 条,单个场景 100 条左右,这些都 是建立在没有阻塞用例的基础上。
(4)测试几轮:一般三轮,集成测试 → 系统测试 → 验收测试
其他
分布式压力测试
幂等性
装饰器
提高自动测试脚本的稳定性
token测试有效期
jmeter的局限性
GT检测手机App的CPU、内存、电量、帧率
AppScan
安全测试:加密、SQL注入、xss攻击、跨站攻击、授权
面试官您好 我叫刘殿鑫,来自辽宁省朝阳市 19年 毕业于 辽宁理工学院 计算机系 专业学的是 计算机科学与技术。 从事测试行业3年多,从业期间经历了2家公司我之前主要做过的是功能测试,web 自动化测试、app专项测试、接口测试、也有用过Jmeter做过一些性能方面的测试。熟练操作一些SQL语句,增、删、改、查等操作。还有一些自动化测试框架工具Selenium、Appium、Unittest、Pytest、Requests.还了解一些抓包工具Charles、Fiddler。以上就是我的一些简单的自我介绍,希望能给贵公司带来效益,谢谢!
Hello, interviewer My name is Liu Dianxin. I come from shanxi Province. I graduated from the Department of Computer science of Liaoning University of Science and Technology in two thousand and nineteen, majoring in computer Science and technology. I have been engaged in testing industry for more than 3 years, and I have worked in 2 companies during this periodI have mainly done functional tests, web automation tests, APP specific tests, interface tests, and some performance tests with Jmeter. Skilled operation of some SQL statements, add, delete, change, search and other operations. There are also automated test framework tools Selenium, Appium, Unittest, Pytest, and Requests. I also know some capture tools Charles and Fiddler. Above is some of my simple self-introduction, I hope to bring benefits to your company, thank you!python。
春已走,夏当立,万物提醒已换季。北京软测市场堪忧,带学生来杭州需求就业机会,这期间发生了好多小故事。我们的班长刘殿鑫也随之而来。他是一位能说会道、管理能力极强的孩子,但是学习不是特别好。初来杭州,天真的认为很快能就业,可现实打脸了,甚至面试都约不上,陷入惆怅,想回老家。随后,我带他爬 山,讲各种人生道理。此后,他“洗心 革面”,每天晚上学习到十二点,吃饭在约面试,走路在背题,信心倍增,随之面试量激增,不到三天就拿到了字节跳动首个offer,随后又拿到了几个offer。现在开开心心的居家办公,他对我深表感谢。所以,人总要在磨难中成长,风雨之后才见彩虹,体验人生百态才能苦尽甘来。
本文来自博客园,作者:ChinaBigFly,转载请注明原文链接:https://www.cnblogs.com/chinabigfly/p/16824267.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号