
手动创建词向量训练神经网络
一直不太明白词向量怎样产生,搜索生成原理后,自己分别使用word2vector和自建单隐层神经网络进行训练(数据集优美,量少,不用太在意训练效果,主要记录流程)
先介绍数据处理与网络架构:




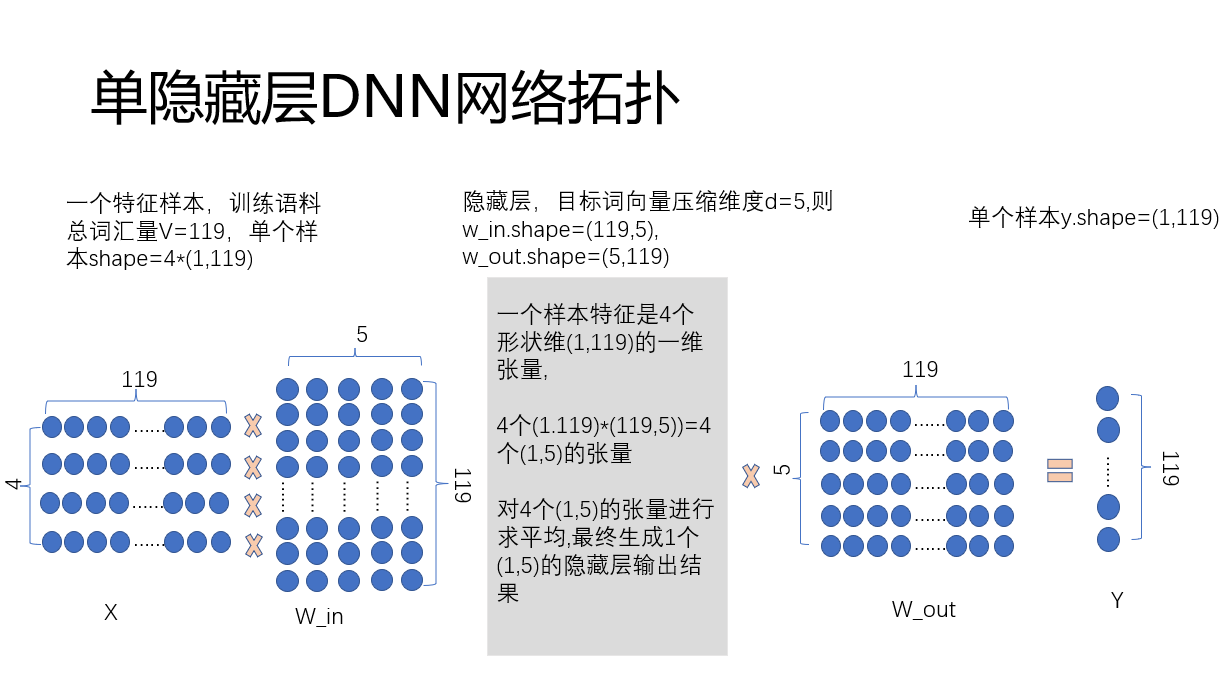
1.训练数据集:
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
import jieba
from gensim import corpora
import gensim
import numpy as np
import matplotlib.pyplot as plt
text = ['我爱你,就算不说出来,时光也会把它熬成最动人的情话。',
'我行过许多地方的桥,看过许多次数的云,喝过许多种类的酒,却只爱过一个正当最好年龄的人',
'我爱你。即使要拿这个江山做交换,我也不会放你离开,没有人能将你从我身边夺走',
'如果可以和你在一起,我宁愿让天空所有的星光全部损落,因为你的眼睛,是我生命里最亮的光芒。',
'你永远也看不到我最寂寞时候的样子,因为只有你不在我身边的时候,我才最寂寞。',
'对不起,我还是很想你,你早已远去,我却还待在原地。对不起,我还是好想你,怎能说放就忘,我没那么勇敢',
'世上最遥远的距离,不是生与死的距离,不是天各一方,而是我就站在你面前,你却不知道我爱你。',
'你会因为一首歌喜欢上一个人,因为一个人喜欢一个城市,因为一个城市喜欢上一种生活,然后因为一首歌,想念某个人。',
'我喜欢你,笨拙而热烈,一无所有又倾尽所有。']
#jieba.add_word() # 一次添加一个词汇
jieba.load_userdict('userdict.txt') # 添加自定义文件词典,词汇形式 ‘词 词频 词性(n)’
text_ = [jieba.lcut(i) for i in text]
text_ = [list(filter(lambda x: x not in ('。',','),i)) for i in text_]
text_
'''
['我', '爱', '你', '就算', '不说', '出来', '时光', '也', '会', '把', '它', '熬成', '最', '动人', '的', '情话’],
['我行', '过', '许多', '地方', '的', '桥', '看过', '许多', '次数', '的', '云', '喝过', '许多', '种类', '的', '酒', '却', '只', '爱过', '一个', '正当', '最好', '年龄', '的', '人’],
['我', '爱', '你', '即使', '要', '拿', '这个', '江山', '做', '交换', '我', '也', '不会', '放', '你', '离开', '没有', '人能', '将', '你', '从’,‘我', '身边', '夺走’],
......
'''
2.使用gensim中的word2vector直接生成词向量
w2v = gensim.models.Word2Vec(sentences=text_,vector_size=5,window=2,min_count=0)
#1 输出词汇的词向量
w2v.wv['爱']
w2v.wv['喜欢']
'''
array([-0.03110135, 0.00735455, -0.08144382, -0.15453787, -0.0296591 ],
dtype=float32)
array([-0.14973408, -0.01746239, 0.19247814, -0.14743246, -0.04586641],
dtype=float32)
'''
#2 求词汇的文本相似度
w2v.wv.similarity('我','你')
w2v.wv.similarity('我','一无所有')
'''
0.20868862
-0.29505315
'''
#3 求句子异常值
w2v.wv.doesnt_match(['我', '不说', '你'])
'''
'你' # 明显感觉训练的差点意思
'''
# 求文本相似度topN
w2v.wv.most_similar(positive=['爱'],negative=['我'],topn=2)
'''
[('云', 0.8236473798751831), ('可以', 0.8154597878456116)]
'''
3.使用pytorch创建单隐层神经网络,训练词向量
#1 生成语料的词汇表
dictionary = corpora.Dictionary(text_) # 每句话是分词列表
list(dictionary.items())
'''
[(0, '不说'),
(1, '也'),
(2, '会'),
(3, '你'),
(4, '出来'),
(5, '动人'),
(6, '它'),
(7, '就算')
......
(114, '倾尽'),
(115, '又'),
(116, '热烈'),
(117, '笨拙'),
(118, '而')]
'''
#2 形成训练数据集(使用CBOW训练方式)
def create_train(texts,windows=2):
'''
texts: 带训练语料(已one-hot处理)
windows: 滑动窗口,表示每个词考虑前面n个词,后面n个词(若不够,按实际个数)
'''
X = []
for text in texts:
for index in range(len(text)):
x_l = text[index-windows:index]
label = text[index]
x_r = text[index+1:index+1+windows]
X.append((x_l+x_r,label))
return X
data = create_train(text_)
data
'''
[(['爱', '你'], '我'),
(['你', '就算'], '爱'),
(['我', '爱', '就算', '不说'], '你'),
(['爱', '你', '不说', '出来'], '就算'),
(['你', '就算', '出来', '时光'], '不说'),
(['就算', '不说', '时光', '也'], '出来'),
(['不说', '出来', '也', '会'], '时光'),
(['出来', '时光', '会', '把'], '也'),
......
(['笨拙', '而', '一无所有', '又'], '热烈'),
(['而', '热烈', '又', '倾尽'], '一无所有'),
(['热烈', '一无所有', '倾尽', '所有'], '又'),
(['一无所有', '又', '所有'], '倾尽'),
(['又', '倾尽'], '所有')]
'''
#3 生成one-hotEncoder
def gen_x_onehot(words):
res = []
def gen_onehot(x): # 输入字符,返回字符对应的one-hot编码
eg = [0 for i in range(len(dictionary))]
eg[dictionary.doc2idx([x])[0]] = 1
return eg
if isinstance(words,str):
return gen_onehot(words) # y 是一维数组
if isinstance(words,list): # x 是二维数组,对于中心词两边不满指定windows词汇的输入,使用全0数组填充
for x in words:
eg = [0 for i in range(len(dictionary))]
res_temp = [gen_onehot(i) for i in x]
if len(res_temp) < 4:
res_temp += [eg for i in range(4-len(res_temp))]
res.append(res_temp)
return res
#4 形成X和y
x,y = [i[0] for i in data],[i[1] for i in data]
x,y = gen_x_onehot(x),[gen_onehot(i) for i in y]
x = torch.tensor(x,dtype=torch.float32)
y = torch.tensor(y,dtype=torch.float32)
x.shape
y.shape
x[2]
y[2]
'''
torch.Size([203, 4, 119])
torch.Size([203, 119])
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
...... 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.
......0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
......0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
tensor([0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
......0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
'''
#5 构建单层DNN神经网络
class Net(nn.Module):
def __init__(self,V=1,dim=5):
super().__init__()
# self.con = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=con_kernel)
self.linear1 = nn.Linear(in_features=V,out_features=dim)
self.linear2 = nn.Linear(in_features=dim,out_features=V)
def forward(self,x):
x_temp = torch.tensor([self.linear1(i).tolist() for i in x],dtype=torch.float32) # forward函数,会对输入的特征一一处理,再封装成原shape
x = torch.tensor([torch.mean(i,dim=0).tolist() for i in x_temp],dtype=torch.float32)
x = self.linear2(x)
return x
#6 生成网络对象,参数初始化(本次试验代码,参数少,可以不进行初始化)
net = Net(V=len(dictionary))
for module in net.modules():
if isinstance(module,nn.Linear):
nn.init.kaiming_uniform_(module.weight)
#7 定义交叉熵损失函数
loss = CrossEntropyLoss()
#8 定义优化参数
opt = SGD(params=net.parameters(),lr=0.03,momentum=0.2)
#9 训练
y = torch.tensor([torch.argmax(i) for i in y]) # 把真实标签转换成序列类别编码,方便损失函数使用,交叉熵要求y标签维整形
epochs = 1000
loss_value_list =[]
for epoch in range(epochs):
z = net(x)
loss_value = loss(z,y)
opt.zero_grad()
loss_value.backward()
opt.step()
print(loss_value)
loss_value_list.append(loss_value)
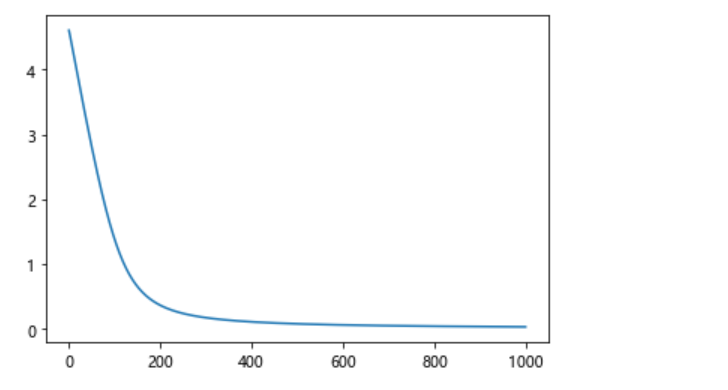
4.1画出训练结果
plt.plot(range(epochs),loss_value_lis
4.2 使用训练模型的参数进行词向量生成和文本相似度计算
#10 查看模型效果
# 获取训练后的词向量函数,使用词的one-hot稀疏向量*模型训练出的weight就是词向量
def get_vector(word):
m = torch.tensor(gen_x_onehot(word),dtype=torch.float32).unsqueeze(dim=0)
v = net.linear1.weight.detach()
return torch.mm(m,torch.t(v))
#11 输出词汇的词向量
a = get_vector('我')
b = get_vector('你')
c = get_vector('一无所有')
a,b,c
'''
(tensor([[-0.0368, 0.0531, -0.1158, -0.1076, 0.0613]]),
tensor([[-0.0711, 0.0060, -0.0542, -0.0017, -0.0071]]),
tensor([[ 0.1930, -0.0442, 0.1802, -0.2211, -0.0414]]))
'''
#12 # 求取余弦相似度
torch.cosine_similarity(a,b)
torch.cosine_similarity(a,c)
'''
tensor([0.5493])
tensor([-0.1428])
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号