
基于word2vec+TextCNN 作文本分类
基于TextCNN作文本分类模型
一. 准备工作:
-
环境:python3.7+torch+GPU
-
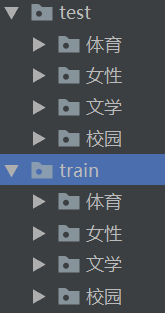
数据集:网上下载的4分类中文文本,如下图:
![]()
-
模块使用:
import os
import jieba
import torch
import joblib
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
- 模型参数配置
# 模型配置参数
class Config:
label_map_dict = {'体育': 0, '女性': 1, '文学': 2, '校园': 3} # 类别映射字典
stopword = [i.strip() for i in open('./datasets/stop/stopword.txt', encoding='utf-8')] # 停用词
sentence_lenth = 50 # 句子截断长度
batch_size = 10 # 批次数
output_channel = 3 # 输出通道
embedding_size = 5 # 嵌入词向量长度
vocab_dict_ = joblib.load('./models/vocab_dict')
- 中文分词后编辑词汇表
# 生成词汇表
def vocab_dict(*args, base_path='./datasets/train'):
vocab = set()
for i in args:
dataset = Dataset_(base_path, i)
for s in range(len(dataset)):
for v in dataset[s][0]:
vocab.add(v)
vocab_dict = {word: idx+1 for idx, word in enumerate(vocab)}
vocab_dict['unkown'] = 0
return vocab_dict
# 保存响应词汇表,供神经网络中Embedding使用
joblib.dump(vocab_dict('体育', '女性', '文学', '校园'), './models/vocab_dict')
二. 数据加载器
-
数据集类编写
class Dataset_(Dataset): def __init__(self, base_path, label_path): self.base_path = base_path self.label = label_path self.items_path = os.path.join(base_path, self.label) self.items = os.listdir(self.items_path) def __getitem__(self, index): label = Config.label_map_dict.get(self.label) sentence = list(self.cut_word(open(os.path.join(self.items_path, self.items[index])).read())) sentence_ = [] for i in sentence: if Config.vocab_dict_.get(i, None): sentence_.append(Config.vocab_dict_[i]) else: sentence_.append(Config.vocab_dict_['unkown']) if len(sentence_) > Config.sentence_lenth: sentence_ = sentence_[:Config.sentence_lenth] elif len(sentence_) < Config.sentence_lenth: sentence_.extend([0 for i in range(Config.sentence_lenth-len(sentence_))]) return sentence_, label def __len__(self): return len(self.items) @staticmethod def cut_word(text): return [i.strip() for i in jieba.cut(text) if i.strip() not in Config.stopword and i.strip() is not None] -
数据加载器格式化输出
# 自定义Dataloder加载器数据输出格式 def truncate(data_list): """ 传进一个batch_size大小的数据""" x_train = [] label = [] for data in data_list: x_train.append((data[0])) label.append(data[1]) return torch.tensor(x_train), torch.tensor(label) loader_t = DataLoader(Dataset_('./datasets/train', '体育'), batch_size=10, collate_fn=truncate) loader_n = DataLoader(Dataset_('./datasets/train', '女性'), batch_size=10, collate_fn=truncate) loader_w = DataLoader(Dataset_('./datasets/train', '文学'), batch_size=10, collate_fn=truncate) loader_x = DataLoader(Dataset_('./datasets/train', '校园'), batch_size=10, collate_fn=truncate)三. 模型搭建
-
TextCNN类
# 模型搭建 class TextCNN(nn.Module): def __init__(self): super(TextCNN, self).__init__() self.embeding = nn.Embedding(num_embeddings=len(Config.vocab_dict_), embedding_dim=Config.embedding_size) self.cord = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=Config.output_channel, kernel_size=(2, Config.embedding_size)), nn.ReLU(), # nn.MaxPool1d(3, stride=2), 2维卷积需要使用2维池化 nn.MaxPool2d((2, 1), stride=2) ) self.fc = nn.Linear(Config.output_channel * 24, len(Config.label_map_dict)) self.sf = nn.Softmax(dim=1) def forward(self, X): batch_size = X.shape[0] embedding_x = self.embeding(X) embedding_x = embedding_x.unsqueeze(1) # 卷积神经网络输入4维, conved = self.cord(embedding_x) flatten = conved.view(batch_size, -1) # 展平成一维 output = self.sf(self.fc(flatten)) return output四. 训练模型
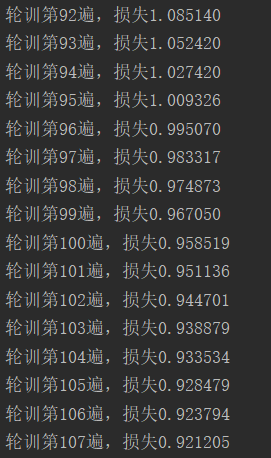
for epoch in range(5000): for i in ['t', 'n', 'w', 'x']: for X_train, y_train in eval(f'loader_{i}'): pred = textCNN(X_train.to(device)) loss = criterion(pred, y_train.to(device)) optimizer.zero_grad() loss.backward() optimizer.step() print(f'轮训第{epoch+1}遍,损失{loss.data:.6f}')五. 模型保存
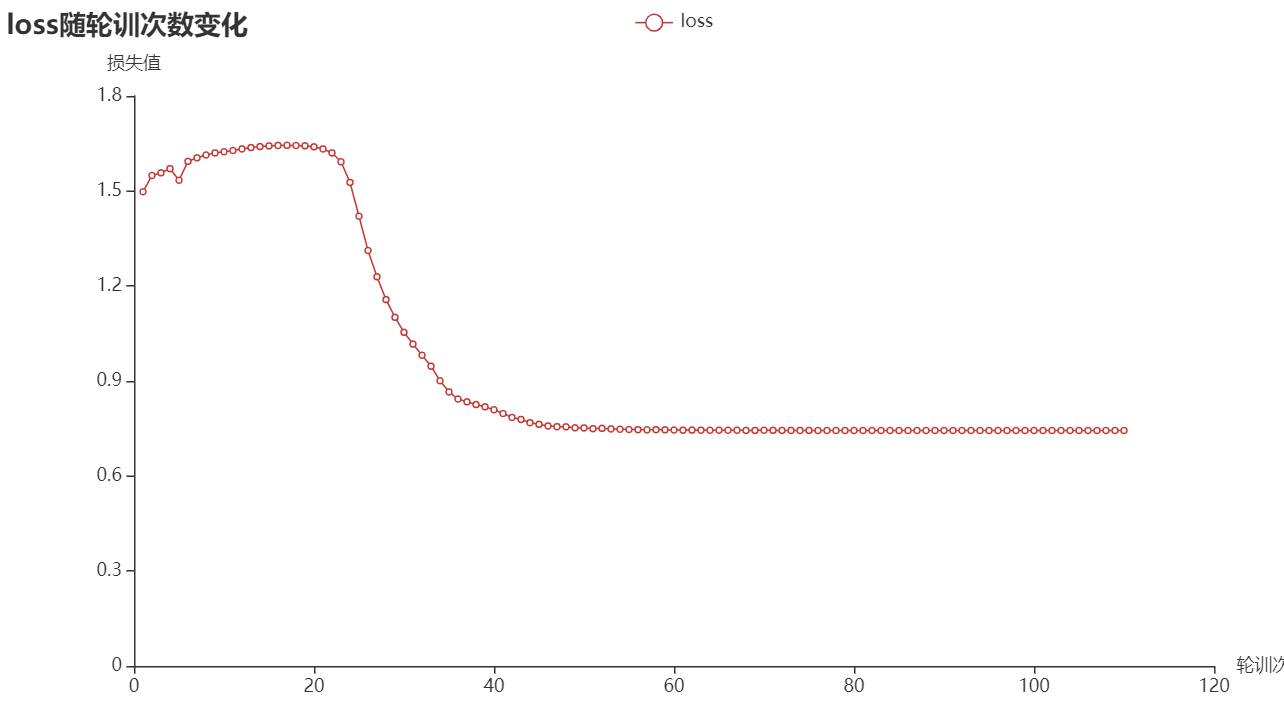
# 保留模型参数 # 保存 torch.save(model.state_dict(), '\parameter.pkl') # 加载 model = TheModelClass(...) # model.load_state_dict(torch.load('\parameter.pkl')) # 保存完整模型 # 保存 torch.save(TextCNN, './models/model.pkl') # 加载 model = torch.load('./models/model.pkl')训练如下图:
![]()
![]()
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号