
gerapy+scrapyd 爬虫项目部署
爬虫项目部署
部署环境 : linux+python3+scrapy+scrapyd+gerapy
介绍:
-
Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待当前URL抓取完毕之后在进行下一个URL的抓取,抓取效率可以提高很多。
-
Scrapy-redis:虽然Scrapy框架是异步加多线程的,但是我们只能在一台主机上运行,爬取效率还是有限的,Scrapy-redis库为我们提供了Scrapy分布式的队列,调度器,去重等等功能,有了它,我们就可以将多台主机组合起来,共同完成一个爬取任务,抓取的效率又提高了。
-
Scrapyd:分布式爬虫完成之后,接下来就是代码部署,如果我们有很多主机,那就要逐个登录服务器进行部署,万一代码有所改动..........可以想象,这个过程是多么繁琐。Scrapyd是专门用来进行分布式部署的工具,它提供HTTP接口来帮助我们部署,启动,停止,删除爬虫程序,利用它我们可以很方便的完成Scrapy爬虫项目的部署。
-
Gerapy:是一个基于Scrapyd,Scrapyd API,Django,Vue.js搭建的分布式爬虫管理框架。简单点说,就是用上述的Scrapyd工具是在命令行进行操作,而Gerapy将命令行和图形界面进行了对接,我们只需要点击按钮就可完成部署,启动,停止,删除的操作。
一、安装scrapyd和gerapy
pip install scrapyd
pip install gerapy
# 创建软连接
ln -s /usr/local/python3/bin/scrapyd /usr/bin/scrapyd
ln -s /usr/local/python3/bin/gerapy /usr/bin/gerapy
二、配置scrapyd
# 在/usr/local/python3/lib/python3.7/site-packages/scrapyd/default_scrapyd.conf
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0 # 修改绑定ip,供远端链接
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
三、配置gerapy
# 创建项目仓库
# 1.自定义项目目录
mkdir /opt/spider_system
cd /opt/spider_system
# 初始化gerapy
gerapy init
# 完成数据迁移
cd gerapy
gerapy migrate
四、配置scrapy项目
# 项目目录下/scrapy.cfg
[settings]
default = dangdangwang.settings
[deploy:dangdangwang] #设置爬虫项目名称
url = http://81.70.100.13:6800/ #绑定远程scrapyd服务主机地址
project = dangdangwang
五、服务启动
# 1.服务器scrapyd启动
nohup scrapyd & #后台服务运行
# 2.服务器gerapy启动(基于Django)
cd gerapy
gerapy runserver 0.0.0.0:6900
六、gerapy部署操作
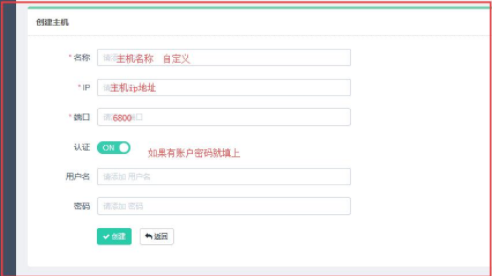
- 主机管理
- 项目管理
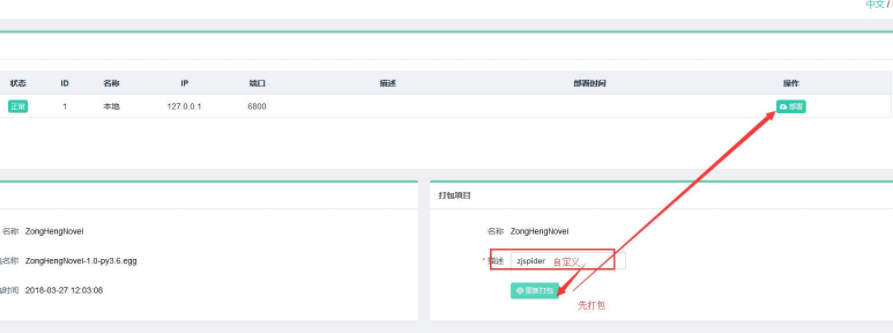
- 任务管理
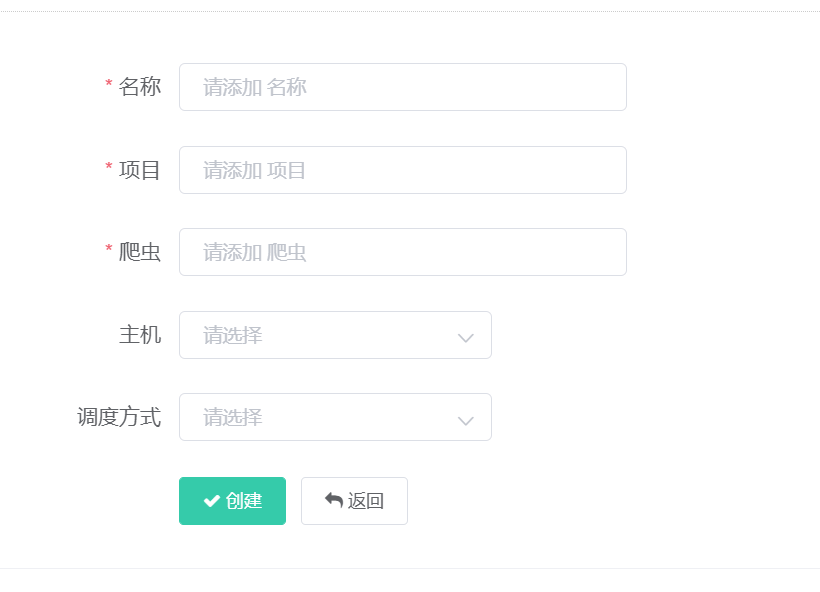
名称:自定义名称
项目:爬虫项目名
爬虫:爬虫名_spider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号