第一次个人编程作业*修正版
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 完成个人编程作业编码部分。 |
| GitHub: | https://github.com/Chikisama/3218005399 |
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。

Python分词工具
- Python分词工具有Jieba、SnowNLP、PkuSeg、THULAC、pyhanlp、LTP等
- Jieba支持三种分词模式:精确模式、全模式、搜索引擎模式。
- 在该项目中选用了Jieba.lcut()接口,默认精确模式,直接生成一个分词列表。
代码:
newtext = jieba.cut("我来北京上学") #Jieba分词
print("【精确模式】:" + "/ ".join(newtext))
运算结果:
【精确模式】:我/ 来/ 北京/ 上学
读取文本
readline()方法用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符。- 循环读取文件的每一整行。
#读取文本文件
def read_text(path):
data = ''
file = open(path, 'r', encoding='UTF-8') #只读
line = file.readline()
while line:
data += line
line = file.readline()
file.close()
return data
文本清洗
- re库是Python拥有全部的正则表达式功能,主要用于字符串匹配。
- 该项目中选用了re.sub和re.compile接口实现文本预处理清洗功能。只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果,去除标点符号。增加文章相似度的准确性。
| 函数 | 说明 |
|---|---|
| re.compile | 将正则表达式的字符串形式编译成正则表达式对象。 |
| re.match | 从字符串的起始位置匹配正则表达式,返回match对象。如果不是起始位置匹配成功的话,match()就返回none。 |
| re.sub | 在字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。 |
#文本清洗+分词
def text_clean(data):
newtext = []
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]") #定义正则表达式匹配模式
data = pattern.sub("",data) # 只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果。去除标点符号
newtext = [i for i in jieba.cut(data, cut_all=True) if i != ''] #分词
return newtext
文本相似度计算方法
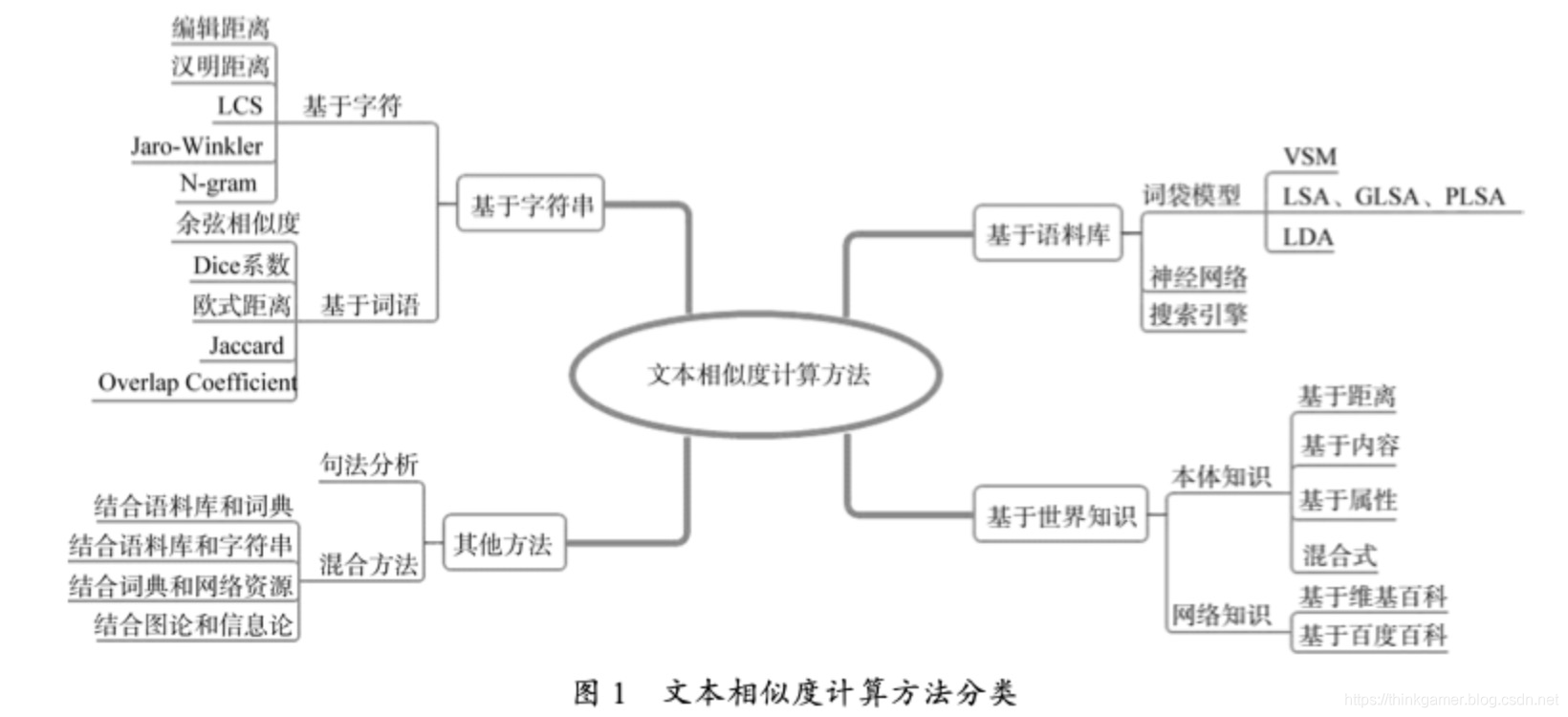
- 如上图所示,常用文本相似度计算方法有余弦相似度算法、TF-IDF算法、欧几里德距离、切比雪夫距离、曼哈顿距离、SimHash + 汉明距离等。
- 个人觉得最容易上手的是余弦相似度算法和TF-IDF算法。
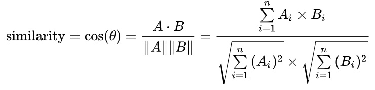

- 该项目选用的是余弦相似度算法计算文本相似度。
思路: 1、分词;2、列出所有词;3、分词编码;4、词频向量化;5、套用余弦函数计量两个句子的相似度。
句子A:今天是星期天,天气晴,今天晚上我要去看电影。
句子B:今天是周天,天气晴朗,我晚上要去看电影。
1、分词
使用结巴分词对上面两个句子分词后,分别得到两个列表:
listA=['今天', '是', '星期天', '天气', '晴', '今天', '晚上', '我要', '去', '看', '电影']
listB=['今天', '是', '周天', '天气晴朗', '我', '晚上', '要', '去', '看', '电影']
def text_clean(data):
newtext = []
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]") #定义正则表达式匹配模式
data = pattern.sub("",data) # 只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果。 去除标点符号
newtext = [i for i in jieba.cut(data, cut_all=False) if i != ''] #分词
return newtext
2、列出所有词
将listA和listB放在一个set中,得到:{'我要', '电影', '周天', '去', '今天', '晴', '要', '天气', '天气晴朗', '晚上', '看', '我', '是', '星期天'}
将上述set转换为dict,key为set中的词,value为set中词出现的位置,即‘电影’:1这样的形式。
dict1={'我要': 0, '电影': 1, '周天': 2, '去': 3, '今天': 4, '晴': 5, '要': 6, '天气': 7, '天气晴朗': 8, '晚上': 9, '看': 10, '我': 11, '是': 12, '星期天': 13}
可以看出'我要'这个词在set中排第1,下标为0。
word_set = set(newtext1).union(set(newtext2)) #列出所有词
word_dict = dict()
i = 0
for word in word_set:
word_dict[word] = i
i += 1
3、将listA和listB进行编码
将每个字转换为出现在set中的位置,转换后为:
listAcode=[4, 12, 13, 7, 5, 4, 9, 0, 3, 10, 1]
listBcode=[4, 12, 2, 8, 11, 9, 6, 3, 10, 1]
我们来分析listAcode,结合dict1,可以看到4对应的字是“今天”,12对应的字是“是”,7对应的字是“天气晴朗”,就是句子A和句子B转换为用数字来表示。
text1_cut_index = [word_dict[word] for word in newtext1]
text2_cut_index = [word_dict[word] for word in newtext2]
4、词频向量化
对listAcode和listBcode进行oneHot编码,就是计算每个分词出现的次数。oneHot编号后得到的结果如下:
listAcodeOneHot = [1, 1, 0, 1, 2, 1, 0, 1, 0, 1, 1, 0, 1, 1]
listBcodeOneHot = [0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0]
text1_cut_index = [0]*len(word_dict)
text2_cut_index = [0]*len(word_dict)
for word in newtext1:
text1_cut_index[word_dict[word]] += 1
for word in newtext2:
text2_cut_index[word_dict[word]] += 1
5、套用余弦函数计量两个句子的相似度
得出两个句子的词频向量之后,就变成了计算两个向量之间夹角的余弦值,值越大相似度越高。
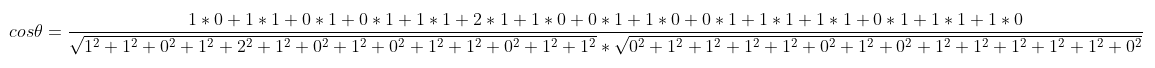
sum = 0 #计算余弦相似度
sq1 = 0
sq2 = 0
for i in range(len(text1_cut_index)):
sum += text1_cut_index[i] * text2_cut_index[i]
sq1 += pow(text1_cut_index[i], 2)
sq2 += pow(text2_cut_index[i], 2)
try:
cos_result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2)
except ZeroDivisionError:
cos_result = 0.0
return cos_result
余弦计算文本相似度 代码:
from math import sqrt
#列出所有词,将listA和listB放在一个set中
#余弦公式计算文本相似度
def cos(newtext1,newtext2):
word_set = set(newtext1).union(set(newtext2)) #列出所有词
word_dict = dict()
i = 0
for word in word_set:
word_dict[word] = i
i += 1
text1_cut_index = [word_dict[word] for word in newtext1]
text2_cut_index = [word_dict[word] for word in newtext2]
text1_cut_index = [0]*len(word_dict) #列出所有词,将listA和listB放在一个set中
text2_cut_index = [0]*len(word_dict)
for word in newtext1:
text1_cut_index[word_dict[word]] += 1
for word in newtext2:
text2_cut_index[word_dict[word]] += 1
sum = 0 #计算余弦相似度
sq1 = 0
sq2 = 0
for i in range(len(text1_cut_index)):
sum += text1_cut_index[i] * text2_cut_index[i]
sq1 += pow(text1_cut_index[i], 2)
sq2 += pow(text2_cut_index[i], 2)
cos_result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2)
return cos_result
项目实现
总代码:
import jieba #结巴分词
import re #正则表达式库
import math #math库
#读取文本文件
def read_text(path):
data = ''
file = open(path, 'r', encoding='UTF-8') #只读
line = file.readline()
while line:
data += line
line = file.readline()
file.close()
return data
#文本清洗+分词
def text_clean(data):
newtext = []
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]") #定义正则表达式匹配模式
data = pattern.sub("",data) # 只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果。 去除标点符号
newtext = [i for i in jieba.cut(data, cut_all=False) if i != ''] #分词
return newtext
#列出所有词,将listA和listB放在一个set中
#余弦公式计算文本相似度
def cos(newtext1,newtext2):
word_set = set(newtext1).union(set(newtext2)) #列出所有词
word_dict = dict()
i = 0
for word in word_set:
word_dict[word] = i
i += 1
text1_cut_index = [word_dict[word] for word in newtext1]
text2_cut_index = [word_dict[word] for word in newtext2]
text1_cut_index = [0]*len(word_dict) #列出所有词,将listA和listB放在一个set中
text2_cut_index = [0]*len(word_dict)
for word in newtext1:
text1_cut_index[word_dict[word]] += 1
for word in newtext2:
text2_cut_index[word_dict[word]] += 1
sum = 0 #计算余弦相似度
sq1 = 0
sq2 = 0
for i in range(len(text1_cut_index)):
sum += text1_cut_index[i] * text2_cut_index[i]
sq1 += pow(text1_cut_index[i], 2)
sq2 += pow(text2_cut_index[i], 2)
cos_result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2)
return cos_result
if __name__ == '__main__':
path1 = r'C:\Users\Chiki\Desktop\homework\text\orig.txt' #论文原文的文件的绝对路径 作业要求
path2 = r'C:\Users\Chiki\Desktop\homework\text\orig_add.txt' #抄袭版论文的文件的绝对路径
save_path = r'C:\Users\Chiki\Desktop\homework\rate\save.txt' #输出结果绝对路径
data1 = read_text(path1)
data2 = read_text(path2)
text1 = text_clean(data1)
text2 = text_clean(data2)
cos_result = cos(text1,text2)
print("文章相似度: %.4f"%cos_result)
#将相似度结果写入指定文件
file = open(save_path, 'w', encoding="utf-8") #只写
file.write("文章相似度: %.4f"%cos_result)
file.close()
运行结果:
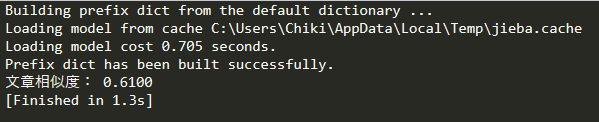
测试代码覆盖率:
安装Coverage库:
安装命令:pip install coverage
生成覆盖率报告:coverage html -d report
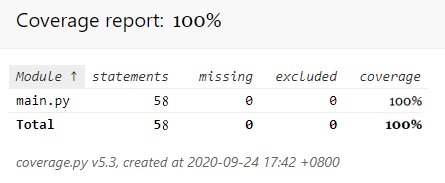
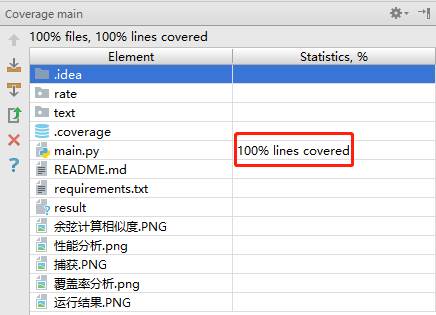
在pycharm用coverage插件测试代码覆盖率:
性能分析:
GitHub:https://github.com/Chikisama/3218005399
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 80 |
| Estimate | 估计这个任务需要多少时间 | 420 | 450 |
| Development | 开发 | 300 | 330 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 40 | 20 |
| Design Review | 设计复审 | 40 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| Design | 具体设计 | 30 | 35 |
| Coding | 具体编码 | 240 | 250 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 10 | 10 |
| Reporting | 报告 | 40 | 30 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 5 |
| Total | 合计 | 550 | 545 |
参考文献:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号