redis集群演变(单机架构、主从架构、哨兵架构、redis-cluster架构)
redis集群演变(单节点、主从、哨兵、redis-cluster)
由于Redis是基于内存的高性能KV数据库,这些年随时Redis的快速发展,更多的技术开发者将Redis融入自己的实际项目中。为了应对各式各样的业务场景保证数据更加稳定安全,各种高可用架构以及优化方案不断改进,导致Redis的整个架构体系也有了一个演变过程。集群模式是近年来Redis架构不断改进中较好的高可用方案。我们这里会对Redis的整个演变过程中每一个环节都进行一个介绍。主要包括了单机单节点模式、主从架构(M/S主从读写分离)、哨兵模式高可用架构、redis集群高可用架构等方案。
-
单节点模式
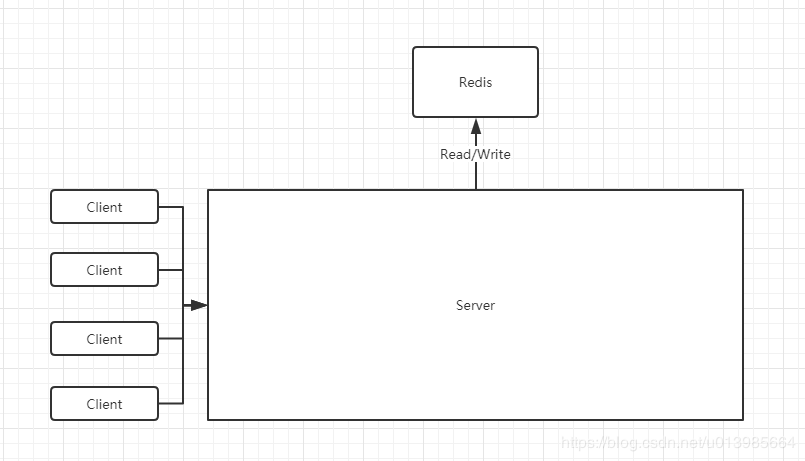
最初Redis刚进入我们身边的时候,是因为传统关系型数据库在某些特定场景下处理起来并不是十分合适,所以最初单机单节点的模式就能够满足我们对业务场景的应对,这里我们不做过多介绍这种模式,其实就是我们部署单个节点的Redis仅仅支持使用即可,对高可用以及数据安全性要求并不高。
总结一下:
优点:
(1)优点也就是redis的优点,单机模式没有什么好说的。
缺点:
(1)redis就一个服务,挂了,整个缓存就瘫痪了。没办法高可用。
(2)数据持久化只存在当前这一个服务器,发生磁盘坏道时,备份数据就丢失了。这时redis挂了,恢复数据时就丢失数据了。
(3)读写操作都在一个redis服务上,服务压力大。
搭建方式:
下载编译运行,不多说。
-
主从模式
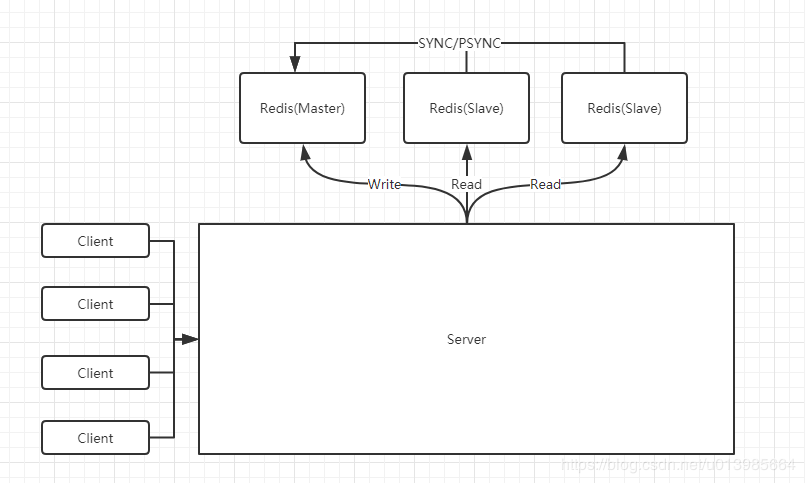
随着我们Redis不断融入我们项目中各式各样业务场景,我们发现其实在大多数时候甚至超过90%的情况下,我们只Redis进行读操作,写操作只是为了支撑缓存数据内容,一次写操作之后伴随的是大量的读操作。所以Master-Slave主从架构出现了。
我们通过部署额外的一些Redis服务让其与主服务器连接,主服务器会通过网络发送数据副本给从服务器进行准实时更新。我们在应用的过程中将写操作都集中在主服务器,而读操作集中在从服务器,这样就分散了主服务器的压力,使其性能更好并且更具备可用性,并且同时部署多台从服务器也能很大程度上解决读操作集中造成的性能瓶颈。
主从架构还有一个好处,那就是可以保证我们数据的安全性。我们知道Redis通过持久化的功能保证了服务器重启之后只会损失少量数据甚至不会损失数据的问题。由于持久化会将我们内存中的数据保存到磁盘上,重启之后会从磁盘上加载数据。但是由于数据仅会存储在一台服务器上,当这台服务器磁盘故障那么数据也会出现丢失。为了避免这种单点故障造成的数据丢失,所以通常会部署多个服务到不同服务器上,也就能够保证数据有多个备份,数据更加安全不易丢失。
总结一下:
优点:
(1)读写分离了。大量的读操作的压力可以分担到slave上。
(2)主从redis均保存着全量的数据,都做了持久化后,如果有一台机器磁盘出现坏道,也可以用其他机器的持久化文件来恢复。
缺点:
(1)主服务器挂了,必须人工介入恢复,手动设置新的主服务器。不满足高可用。
搭建方式:
假如搭建1主2从,一共3台redis服务器。
1主(6371)
2主(6372,6373)
6371的redis.conf:
port 6371 # 指定redis端口
requirepass password # 按个人需要设置redis密码
6372的redis.conf:
port 6372 # 指定redis端口
requirepass password # 设置redis密码
masterauth password # 配置验证主服务器的密码,这里必须与6371的密码配置一样
slaveof [6371服务器的ip] 6371 # 指定主服务器的ip与端口
6373的redis.conf:
port 6373 # 指定redis端口
requirepass password # 设置redis密码
masterauth password # 配置验证主服务器的密码,这里必须与6371的密码配置一样
slaveof [6373服务器的ip] 6371 # 指定主服务器的ip与端口
注:这里给出的只是最基本的配置,另外一些持久化的配置啊,淘汰策略的配置啊,日志文件的配置啊,需要自己去摸索。
-
哨兵模式

在我们使用主从模式时,从节点主要有两个作用:
(1)分担主节点读压力,保证数据安全性。
(2)主节点宕机后,从节点可以作为主节点的备份顶上来。
那么如果主节点宕机后,我们需要如何操作?首先将即将顶替主节点的从节点取消主备,然后将另外的从节点绑定上新的主节点。
这整个过程,包括从节点晋升为主节点,其他从节点修改关联主节点都需要人工操作,对于系统高可用都是不理想的方式。
但是,Redis已经给我们提供了Sentinel哨兵模式,哨兵模式就是自动帮我们去做灾备故障转移的一个机制。它的功能包含以下三个:
(1)监控(Monitoring): Sentinel 会不断地检查主服务器和从服务器是否运作正常。
(2)提醒(Notification): 当被监控的某个Redis服务器出现问题时, Sentinel可以通过API向管理员或者其他应用程序发送通知。
(3)自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为变更为新的主从关系。当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
总结一下:
优点:
(1)包含着主从架构的全部优点。
(2)主服务器挂了,不再需要人工介入恢复。哨兵可以直接把从服务器切换为主服务器。
缺点:
(1)哨兵模式包含着主从模式。但是主从模式只能有一台主服务器来进行写操作。虽然redis的并发量,官方宣称有10W左右。但是万一有大于10W的写操作并发时,只有一台主服务器可能承受不住。
(2)当公司大规模使用缓存时,如果缓存数据过大,例如到达几个T,十几个T时。因为主从模式是每台机器都全量保存数据的,这样每台机器的内存可能要到达几个T,十几个T。在做redis数据恢复时,耗时太长。
搭建方式:
假如搭建1主2从,3台哨兵,一共6台redis服务器。
1主(6371)
2主(6372,6373)
3哨兵(26371,26372,26373)
6371,6372,6373的配置跟主从模式的一样。
26371,26372,26373的配置只有端口号不一样。
下面只以26371作为示例:
26371的sentinel.conf:
port 26371 # 哨兵服务的端口
sentinel monitor mymaster [主服务器的ip] [主服务器的端口号] 2 # 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel auth-pass mymaster password # 配置哨兵的密码
注:其他配置省略。在jedis中使用时,只需要配置好这三台哨兵的ip,端口,密码就可以了。不需要配置主从服务器的节点信息。在建立连接时会访问哨兵,哨兵会根据判断是读操作还是写操作,自动返回主从节点信息,客户端再去连接执行操作。
-
redis-cluster集群高可用架构
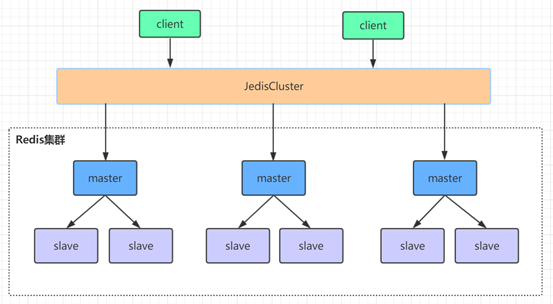
- 集群原理分析
redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
redis-cluster架构中,被设计成共有16384个hash slot。每个master分得一部分slot,其算法为:hash_slot = crc16(key) mod 16384 ,这就找到对应slot。采用hash slot的算法,实际上是解决了redis-cluster架构下,有多个master节点的时候,数据如何分布到这些节点上去。
- 集群的纠正机制
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽位映射表。
- 网络抖动解决方案
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项cluster-node-timeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
- 集群要求
集群至少需要3主3从。(关系到从服务的选举。)
总结一下:
优点:
(1)包含着上述架构的全部优点。
缺点:
(1)部署优点麻烦算吗?哈哈,如果用Docker应该会节省不少时间。
搭建方式:
redis集群需要至少要三个master节点,我们这里搭建三个master节点,并且给每个master再搭建一个slave节点,总共6个redis节点,这里用三台机器部署6个redis实例,每台机器一主一从,搭建集群的步骤如下:
第一步:
在第一台机器的/usr/local下创建文件夹redis-cluster,然后在其下面分别创建2个文件夾如下
(1)mkdir -p /usr/local/redis-cluster
(2)mkdir 8001、 mkdir 8004
第二步:
把之前的redis.conf配置文件copy到8001下,修改如下内容:
1. daemonize yes
2. port 8001 # 分别对每个机器的端口号进行设置
3. dir /usr/local/redis-cluster/8001/ # 指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据
4. cluster-enabled yes # 启动集群模式
5. cluster-config-file nodes-8001.conf # 集群节点信息文件,这里800x最好和port对应上
6. cluster-node-timeout 5000
7. bind 0.0.0.0
8. appendonly yes
# 如果要设置密码需要增加如下配置:
9. requirepass password (设置redis访问密码)
10. masterauth password (设置集群节点间访问密码,跟上面一致)
第三步:
把修改后的配置文件,copy到8002,修改第2、3、5项里的端口号。
第四步:
另外两台机器也需要做上面几步操作,第二台机器用8002和8005,第三台机器用8003和8006。
第五步:
分别启动6个redis实例,然后检查是否启动成功。
(1)/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/800*/redis.conf
(2)ps -ef | grep redis 查看是否启动成功
第六步:
用redis-cli创建整个redis集群(redis5以前的版本集群是依靠ruby脚本redis-trib.rb实现)
# 1代表为每个创建的主服务器节点创建一个从服务器节点
/usr/local/redis-5.0.2/src/redis-cli -a password --cluster create --cluster-replicas 1 192.168.0.61:8001 192.168.0.62:8002 192.168.0.63:8003 192.168.0.61:8004 192.168.0.62:8005 192.168.0.63:8006
第七步:
验证集群:
(1)连接任意一个客户端即可:./redis-cli -c -h -p (-a访问服务端密码,-c表示集群模式,指定ip地址和端口号)如:/usr/local/redis-5.0.2/src/redis-cli -a password -c -h 192.168.0.61 -p 800*
(2)进行验证: cluster info(查看集群信息)、cluster nodes(查看节点列表)
(3)进行数据操作验证
(4)关闭集群则需要逐个进行关闭,使用命令: /usr/local/redis/bin/redis-cli -a password -c -h 192.168.0.60 -p 800* shutdown
注:在jedis中使用时,需要配置集群全部节点的信息,只配置一台的话,虽然也是同样的效果。但是如果这一台挂掉的话,整个集群就连接不上了。
集群扩容操作:
第一步:
启动整个集群
/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/8001/redis.conf
/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/8002/redis.conf
/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/8003/redis.conf
/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/8004/redis.conf
/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/8005/redis.conf
/usr/local/redis-5.0.2/src/redis-server /usr/local/redis-cluster/8006/redis.conf
第二步:
客户端连接8001端口的redis实例
/usr/local/redis-5.0.2/src/redis-cli -a zhuge -c -h 192.168.0.61 -p 8001
第三步:
查看集群状态
192.168.0.61:8001> cluster nodes
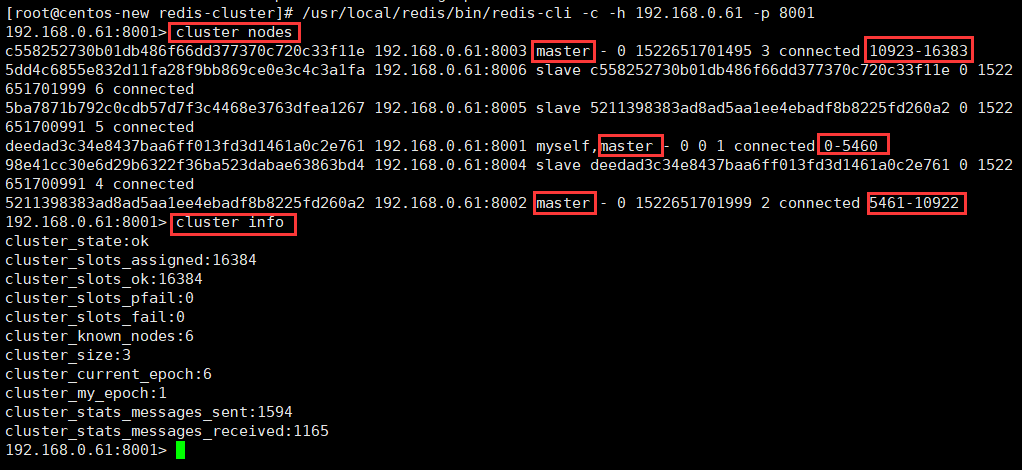
从上图可以看出,整个集群运行正常,三个master节点和三个slave节点。
8001端口的实例节点存储0-5460这些hash槽,
8002端口的实例节点存储5461-10922这些hash槽,
8003端口的实例节点存储10923-16383这些hash槽,
这三个master节点存储的所有hash槽组成redis集群的存储槽位,slave点是每个主节点的备份从节点,不显示存储槽位。
我们在原始集群基础上再增加一主(8007)一从(8008),增加节点后的集群参见下图,新增节点用虚线框表示:
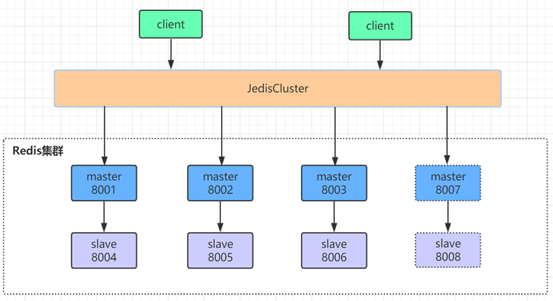
第四步:
增加redis实例8007,8008。配置跟上面一样。
第五步:
配置8007为集群主节点
/usr/local/redis-5.0.2/src/redis-cli --cluster add-node 192.168.0.64:8007 192.168.0.61:8001
查看集群状态
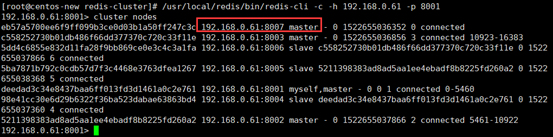
注意:当添加节点成功以后,新增的节点不会有任何数据,因为它还没有分配任何的slot(hash槽),我们需要为新节点手工分配hash槽。
第六步:
使用redis-cli命令为8007分配hash槽,找到集群中的任意一个主节点(红色位置表示集群中的任意一个主节点),对其进行重新分片工作。
/usr/local/redis-5.0.2/src/redis-cli --cluster reshard 192.168.0.61:8001
输出如下:
... ...
How many slots do you want to move (from 1 to 16384)? 600
(ps:需要多少个槽移动到新的节点上,自己设置,比如600个hash槽)
What is the receiving node ID? eb57a5700ee6f9ff099b3ce0d03b1a50ff247c3c
(ps:把这600个hash槽移动到哪个节点上去,需要指定节点id)
Please enter all the source node IDs.
Type "all" to use all the nodes as source nodes for the hash slots.
Type "done" once you entered all the source nodes IDs.
Source node 1:all
(ps:输入all为从所有主节点(8001,8002,8003)中分别抽取相应的槽数指定到新节点中,抽取的总槽数为600个)
... ...
Do you want to proceed with the proposed reshard plan (yes/no)? yes
(ps:输入yes确认开始执行分片任务)
... ...
第七步:
查看下最新的集群状态:
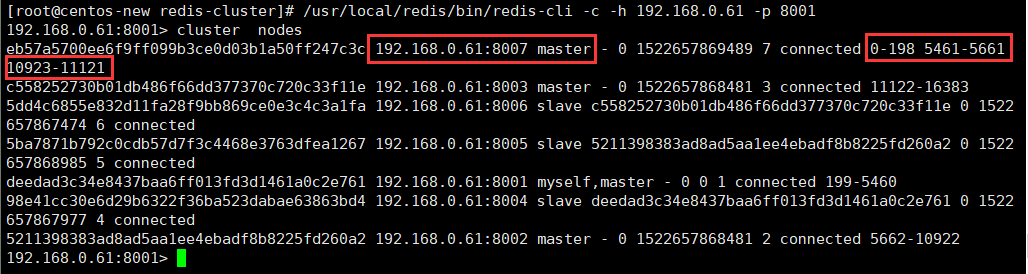
如上图所示,现在我们的8007已经有hash槽了,也就是说可以在8007上进行读写数据啦!到此为止我们的8007已经加入到集群中,并且是主节点(Master)。
第八步:
配置8008为8007的从节点
添加从节点8008到集群中去并查看集群状态
/usr/local/redis-5.0.2/src/redis-cli --cluster add-node 192.168.0.64:8008 192.168.0.61:8001
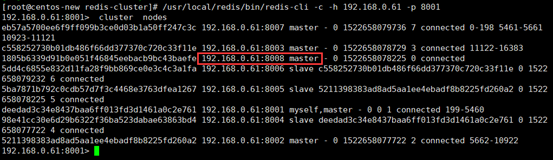
如图所示,还是一个master节点,没有被分配任何的hash槽。
第九步:
我们需要执行replicate命令来指定当前节点(从节点)的主节点id为哪个,首先需要连接新加的8008节点的客户端,然后使用集群命令进行操作,把当前的8008(slave)节点指定到一个主节点下(这里使用之前创建的8007主节点,红色表示节点id)
/usr/local/redis-5.0.2/src/redis-cli -c -h 192.168.0.64 -p 8008
192.168.0.61:8008> cluster replicate eb57a5700ee6f9ff099b3ce0d03b1a50ff247c3c
第十步:
查看集群状态,8008节点已成功添加为8007节点的从节点
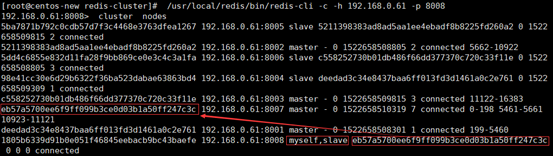
集群缩容操作:
第一步:
删除8008从节点
用del-node删除从节点8008,指定删除节点ip和端口,以及节点id(红色为8008节点id)
/usr/local/redis-5.0.2/src/redis-cli --cluster del-node 192.168.0.64:8008 1805b6339d91b0e051f46845eebacb9bc43baefe
第二步:
再次查看集群状态,如下图所示,8008这个slave节点已经移除,并且该节点的redis服务也已被停止。
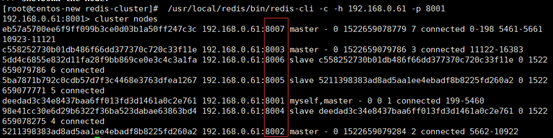
第三步:
最后,我们尝试删除之前加入的主节点8007,这个步骤相对比较麻烦一些,因为主节点的里面是有分配了hash槽的,所以我们这里必须先把8007里的hash槽放入到其他的可用主节点中去,然后再进行移除节点操作,不然会出现数据丢失问题(目前只能把master的数据迁移到一个节点上,暂时做不了平均分配功能),执行命令如下:
/usr/local/redis-5.0.2/src/redis-cli --cluster reshard 192.168.0.64:8007
输出如下:
... ...
How many slots do you want to move (from 1 to 16384)? 600
What is the receiving node ID? deedad3c34e8437baa6ff013fd3d1461a0c2e761
(ps:这里是需要把数据移动到哪?8001的主节点id)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node 1:eb57a5700ee6f9ff099b3ce0d03b1a50ff247c3c
(ps:这里是需要数据源,也就是我们的8007节点id)
Source node 2:done
(ps:这里直接输入done 开始生成迁移计划)
... ...
Do you want to proceed with the proposed reshard plan (yes/no)? Yes
(ps:这里输入yes开始迁移)
至此,我们已经成功的把8007主节点的数据迁移到8001上去了,我们可以看一下现在的集群状态如下图,你会发现8007下面已经没有任何hash槽了,证明迁移成功!
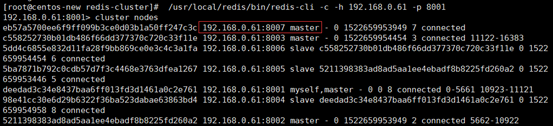
第四步:
最后我们直接使用del-node命令删除8007主节点即可(红色表示8007的节点id)。
/usr/local/redis-5.0.2/src/redis-cli --cluster del-node 192.168.0.64:8007 eb57a5700ee6f9ff099b3ce0d03b1a50ff247c3c
查看集群状态,一切还原为最初始状态啦!大功告成!
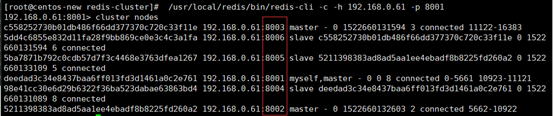

 浙公网安备 33010602011771号
浙公网安备 33010602011771号