python xpath无法解析网站
奇怪,xpath无法解析出内容,结果为空。但使用注释的就可以,能解析出来。参考https://bbs.csdn.net/topics/392248325,把headers去掉就好了,不知道为什么。
使用了headers未解析出内容:
1 from urllib import request 2 import urllib.parse 3 from lxml import etree 4 5 def loadPage(): 6 header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"} 7 data={'kw':'赵丽颖'} 8 data=urllib.parse.urlencode(data) 9 url = 'https://tieba.baidu.com/f?' + data + '&ie=utf-8&pn=50' 10 11 # url = 'http://tieba.baidu.com/p/6118150338?red_tag=v3401180473' 12 a=request.Request(url,headers=header) 13 #a=request.Request(url) 14 response=request.urlopen(a).read().decode('utf-8') 15 # print(response) 16 17 content=etree.HTML(response) 18 link_list=content.xpath("//div[@class='t_con cleafix']/div[2]/div/div[1]/a/@href") 19 # link_list=content.xpath("//img[@class='BDE_Image']/@src") 20 print(link_list) 21 22 if __name__ == '__main__': 23 loadPage()
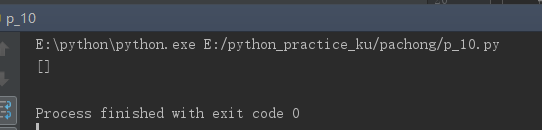
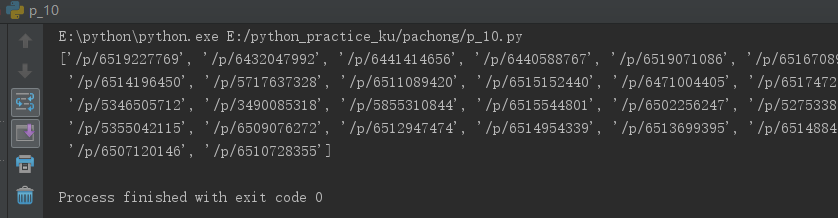
不使用headers解析出来了内容:
1 from urllib import request 2 import urllib.parse 3 from lxml import etree 4 5 def loadPage(): 6 header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"} 7 data={'kw':'赵丽颖'} 8 data=urllib.parse.urlencode(data) 9 url = 'https://tieba.baidu.com/f?' + data + '&ie=utf-8&pn=50' 10 11 # url = 'http://tieba.baidu.com/p/6118150338?red_tag=v3401180473' 12 # a=request.Request(url,headers=header) 13 a=request.Request(url) 14 response=request.urlopen(a).read().decode('utf-8') 15 # print(response) 16 17 content=etree.HTML(response) 18 link_list=content.xpath("//div[@class='t_con cleafix']/div[2]/div/div[1]/a/@href") 19 # link_list=content.xpath("//img[@class='BDE_Image']/@src") 20 print(link_list) 21 22 if __name__ == '__main__': 23 loadPage()
posted on 2020-02-29 20:17 cherry_ning 阅读(840) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号