表格可视化和线性回归模型预测
摘要:
本项目通过对对三个数据文件的可视化分析,每个数据文件做3个可视化图形(不同的图形),并建立模型对排名进行预测。
选题背景:
对外经济贸易、旅游业和居民收入情况是衡量一个国家经济和居民生活情况的重要依据。本项目对这三类数据进行可视化分析来体现我国近几年的发展情况。数据说明:
该项目的数据均来自国家统计局。实施过程及代码:
导入需要用到的库
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import math 5 plt.rcParams['font.sans-serif']=['SimHei']#这两句作用为防止中文乱码 6 plt.rcParams['axes.unicode_minus']=False
读取csv数据
1 economy = pd.read_csv(r'D:/program/表格数据可视化/对外经济贸易 货物进出口总额.csv', header=2) 2 economy.head(8)

对表格‘对外经济贸易 货物进出口总额’进行可视化
画出进出口总额随时间变化趋势图
1 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 2 y = [] 3 jinchukouzonge = economy.loc[0][1:] 4 for i in jinchukouzonge: 5 y.append(i) 6 fig, axes = plt.subplots(1, 1, figsize=(10, 5)) 7 # 折线图 8 axes.plot(x, y, linestyle='-', color='#DE6B58', marker='x', linewidth=1.5) 9 # 画网格线 10 axes.grid(which='minor', c='lightgrey') 11 # 设置x、y轴标签 12 axes.set_ylabel("亿元(人民币)") 13 axes.set_xlabel("年份") 14 plt.title('进出口总额变化趋势') 15 plt.savefig(r'D:/program/表格数据可视化/进出口总额.png', dpi=100) 16 # 展示图片 17 plt.show()
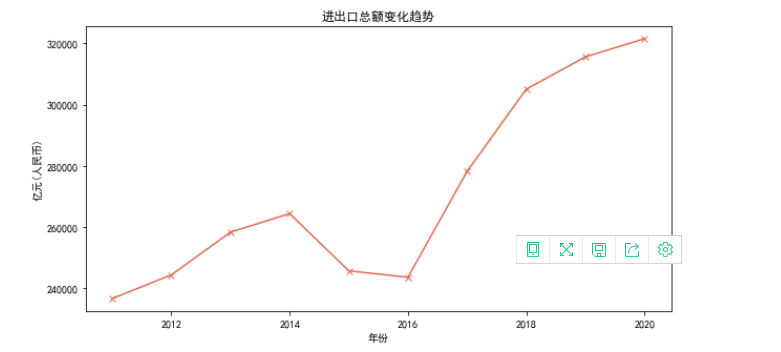
画出出口总额随时间变化的柱状图
1 chukouzonge = economy.loc[1][1:] 2 jinkouzonge = economy.loc[2][1:] 3 jinchukoucha = economy.loc[3][1:] 4 y = [] 5 y1 = [] 6 y2 = [] 7 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 8 for i in chukouzonge: 9 y.append(i) 10 for i in jinkouzonge: 11 y1.append(i) 12 for i in jinchukoucha: 13 y2.append(i) 14 size = 10 15 x = np.array(x) 16 a = np.random.random(size) 17 b = np.random.random(size) 18 c = np.random.random(size) 19 20 total_width, n = 0.8, 3 21 width = total_width / n 22 x = x - (total_width - width) / 2 23 plt.figure(figsize=(15,10)) 24 plt.bar(x, y, width=width, label='出口总额') 25 plt.bar(x + width, y1, width=width, label='进口总额') 26 plt.bar(x + 2 * width, y2, width=width, label='进出口差额') 27 plt.title('进出口情况',fontdict={'weight':'normal','size': 20}) 28 plt.xlabel('年份',fontdict={'weight':'normal','size': 15}) 29 plt.ylabel('亿元(人民币)',fontdict={'weight':'normal','size': 15}) 30 plt.legend() 31 plt.savefig(r'D:/program/表格数据可视化/进出口情况.png', dpi=100) 32 plt.show()
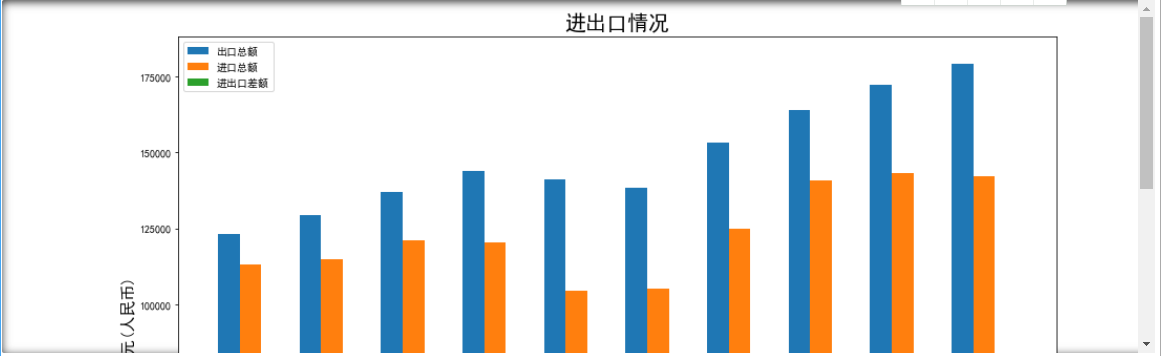
进出口总额(美元)占比饼状图
1 x = ['2020','2019','2018','2017','2016','2015','2014','2013','2012','2011'] 2 y = [] 3 jinchukouzonge = economy.loc[4][1:] 4 for i in jinchukouzonge: 5 y.append(i) 6 labels = 'Frogs', 'Hogs', 'Dogs', 'Logs' 7 sizes = [15, 30, 45, 10] 8 explode = (0.1, 0, 0, 0,0,0,0,0,0,0) # only "explode" the 2nd slice (i.e. 'Hogs') 9 10 fig1, ax1 = plt.subplots() 11 ax1.pie(y, explode=explode, labels=x, autopct='%1.1f%%', 12 shadow=True, startangle=90) 13 ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle. 14 plt.title('进出口总额(美元)占比饼状图') 15 plt.savefig(r'D:/program/表格数据可视化/进出口总额(美元)占比饼状图.png', dpi=100) 16 plt.show()
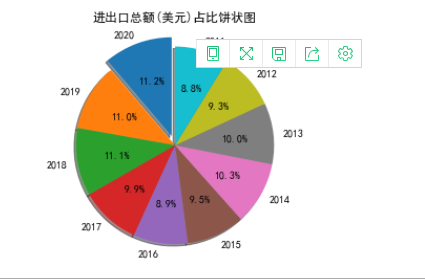
对表格‘旅游业—国内旅游情况’进行可视化
1 travel = pd.read_csv(r'D:/program/表格数据可视化/旅游业—国内旅游情况.csv', header=2) 2 travel.head(9)

人均消费柱状图
1 guonei = travel.loc[6][1:] 2 chengzhen = travel.loc[7][1:] 3 nongcun = travel.loc[8][1:] 4 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 5 y = [] 6 y1 = [] 7 y2 = [] 8 for i in guonei: 9 y.append(i) 10 for i in chengzhen: 11 y1.append(i) 12 for i in nongcun: 13 y2.append(i) 14 size = 10 15 x = np.array(x) 16 a = np.random.random(size) 17 b = np.random.random(size) 18 c = np.random.random(size) 19 20 total_width, n = 0.8, 3 21 width = total_width / n 22 x = x - (total_width - width) / 2 23 plt.figure(figsize=(15,10)) 24 plt.bar(x + width, y1, width=width, label='城镇居民国内旅游人均花费',color='g') 25 plt.bar(x, y, width=width, label='国内旅游人均花费') 26 plt.bar(x + 2 * width, y2, width=width, label='农村居民国内旅游人均花费') 27 plt.title('旅游人均花费情况',fontdict={'weight':'normal','size': 20}) 28 plt.xlabel('年份',fontdict={'weight':'normal','size': 15}) 29 plt.ylabel('元(人民币)',fontdict={'weight':'normal','size': 15}) 30 plt.legend() 31 plt.savefig(r'D:/program/表格数据可视化/旅游人均花费情况.png', dpi=100) 32 plt.show()
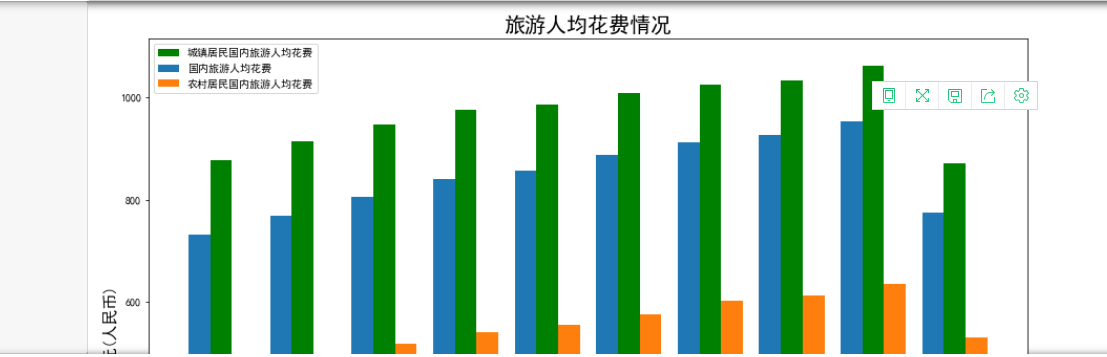
国内旅游总花费趋势图
1 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 2 y = [] 3 zonghuafei = travel.loc[3][1:] 4 for i in jinchukouzonge: 5 y.append(i) 6 fig, axes = plt.subplots(1, 1, figsize=(10, 5)) 7 # 折线图 8 axes.plot(x, y, linestyle='-', color='r', marker='+', linewidth=1.5) 9 # 画网格线 10 axes.grid(which='minor', c='lightgrey') 11 # 设置x、y轴标签 12 axes.set_ylabel("亿元(人民币)") 13 axes.set_xlabel("年份") 14 plt.title('国内旅游总花费趋势') 15 plt.savefig(r'D:/program/表格数据可视化/国内旅游总花费趋势图.png', dpi=100) 16 # 展示图片 17 plt.show()

国内游客人次饼状图
![]()

国内游客人次饼状图
对表格‘人民生活—全国及分城镇居民收支基本情况’进行可视化
1 life = pd.read_csv(r'D:/program/表格数据可视化/人民生活—全国及分城镇居民收支基本情况.csv', header=2) 2 life.head(12)

画居民人均可支配收入变化趋势图
1 x = [2020,2019,2018,2017,2016,2015,2014,2013] 2 y = [] 3 jumin = life.loc[3][1:] 4 for i in jumin: 5 y.append(i) 6 fig, axes = plt.subplots(1, 1, figsize=(10, 5)) 7 # 折线图 8 axes.plot(x, y, linestyle='-', color='b', marker='+', linewidth=1.5) 9 # 画网格线 10 axes.grid(which='minor', c='lightgrey') 11 # 设置x、y轴标签 12 axes.set_ylabel("元(人民币)") 13 axes.set_xlabel("年份") 14 plt.title('居民人均可支配收入变化趋势图') 15 plt.savefig(r'D:/program/表格数据可视化/居民人均可支配收入变化趋势图.png', dpi=100) 16 # 展示图片 17 plt.show()

人均消费支出对比柱状图
1 jm = life.loc[6][1:] 2 chengzhen = life.loc[8][1:] 3 nongcun = life.loc[10][1:] 4 y = [] 5 y1 = [] 6 y2 = [] 7 for i in jm: 8 y.append(i) 9 for i in chengzhen: 10 y1.append(i) 11 for i in nongcun: 12 y2.append(i) 13 size = 10 14 x = [2020,2019,2018,2017,2016,2015,2014,2013] 15 x = np.array(x) 16 a = np.random.random(size) 17 b = np.random.random(size) 18 c = np.random.random(size) 19 20 total_width, n = 0.8, 3 21 width = total_width / n 22 x = x - (total_width - width) / 2 23 plt.figure(figsize=(15,10)) 24 plt.bar(x + width, y1, width=width, label='城镇居民人均消费支出',color='g') 25 plt.bar(x, y, width=width, label='居民人均消费支出') 26 plt.bar(x + 2 * width, y2, width=width, label='农村居民人均消费支出') 27 plt.title('人均消费支出对比柱状图',fontdict={'weight':'normal','size': 20}) 28 plt.xlabel('年份',fontdict={'weight':'normal','size': 15}) 29 plt.ylabel('元(人民币)',fontdict={'weight':'normal','size': 15}) 30 plt.legend() 31 plt.savefig(r'D:/program/表格数据可视化/人均消费支出对比柱状图.png', dpi=100) 32 plt.show()

居民人均可支配收入同比增长饼图
1 x = ['2020','2019','2018','2017','2016','2015','2014'] 2 y = [] 3 guonei = life.loc[1][1:-1] 4 print(guonei) 5 for i in guonei: 6 y.append(i) 7 explode = (0, 0, 0, 0.2,0,0,0) # only "explode" the 2nd slice (i.e. 'Hogs') 8 9 fig1, ax1 = plt.subplots() 10 ax1.pie(y, explode=explode, labels=x, autopct='%1.1f%%', 11 shadow=True, startangle=90) 12 ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle. 13 plt.title('居民人均可支配收入同比增长饼状图') 14 plt.savefig(r'D:/program/表格数据可视化/居民人均可支配收入同比增长饼状图.png', dpi=100) 15 plt.show()

通过线性回归模型预测居民人均可支配收入(元)和城镇居民人均可支配收入(元)之间的关系
1 X = [] 2 y = [] 3 for i in life.loc[0][1:]: 4 X.append(i) 5 for i in life.loc[2][1:]: 6 y.append(i) 7 8 print(X) 9 print(y)

1 X_train = X[:9] 2 y_train = y[:9] 3 n_train = len(X_train) 4 5 X_test = X[5:] 6 y_test = y[5:] 7 n_test = len(X_test)
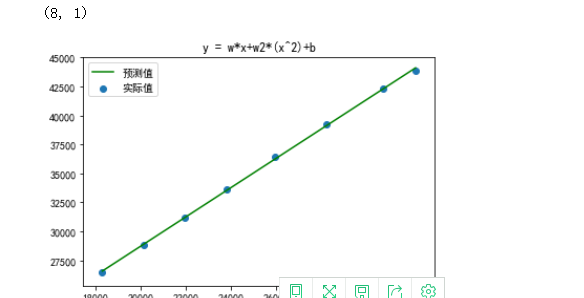
训练模型 y = w*x+b
实际数据的分布接近一条直线所以可以直接用一次函数线性回归模型即可预测,后面也使用了二次函数线性回归模型,两者预测效果基本一致
1 from sklearn.linear_model import LinearRegression 2 from sklearn.linear_model import Lasso 3 from sklearn.linear_model import Ridge 4 x_data = np.array(X_train) 5 y_data = np.array(y_train ) 6 x_data = x_data.reshape(-1,1) 7 y_data = y_data.reshape(-1,1) 8 X2 = np.hstack([x_data]) 9 print(X2.shape) 10 model = LinearRegression() # 线性回归 11 model.fit(X2,y_data) 12 y_pre = model.predict(X2) 13 t = np.arange(len(x_data)) 14 plt.plot(x_data,y_pre,color='g') 15 plt.scatter(x_data, y_data) 16 plt.title('y = w*x+w2*(x^2)+b') 17 plt.legend(('预测值','实际值'),loc='upper left') 18 plt.show()
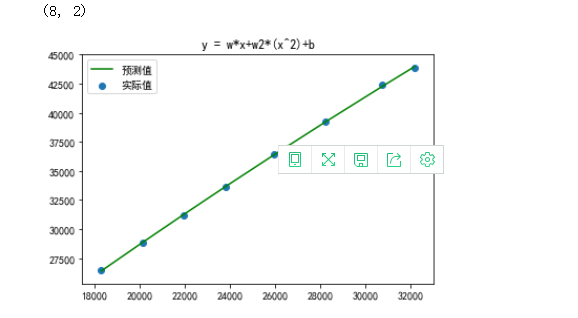
训练模型 y = wx+w2(x^2)+b
1 x_data = np.array(X_train) 2 y_data = np.array(y_train ) 3 x_data = x_data.reshape(-1,1) 4 y_data = y_data.reshape(-1,1) 5 X2 = np.hstack([x_data ** 2,x_data]) 6 print(X2.shape) 7 model = LinearRegression() # 线性回归 8 model.fit(X2,y_data) 9 y_pre = model.predict(X2) 10 t = np.arange(len(x_data)) 11 plt.plot(x_data,y_pre,color='g') 12 plt.scatter(x_data, y_data) 13 plt.title('y = w*x+w2*(x^2)+b') 14 plt.legend(('预测值','实际值'),loc='upper left') 15 plt.show()
完整代码
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import math 5 plt.rcParams['font.sans-serif']=['SimHei']#这两句作用为防止中文乱码 6 plt.rcParams['axes.unicode_minus']=False 7 8 economy = pd.read_csv(r'D:/program/表格数据可视化/对外经济贸易 货物进出口总额.csv', header=2) 9 economy.head(8) 10 11 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 12 y = [] 13 jinchukouzonge = economy.loc[0][1:] 14 for i in jinchukouzonge: 15 y.append(i) 16 fig, axes = plt.subplots(1, 1, figsize=(10, 5)) 17 # 折线图 18 axes.plot(x, y, linestyle='-', color='#DE6B58', marker='x', linewidth=1.5) 19 # 画网格线 20 axes.grid(which='minor', c='lightgrey') 21 # 设置x、y轴标签 22 axes.set_ylabel("亿元(人民币)") 23 axes.set_xlabel("年份") 24 plt.title('进出口总额变化趋势') 25 plt.savefig(r'D:/program/表格数据可视化/进出口总额.png', dpi=100) 26 # 展示图片 27 plt.show() 28 29 chukouzonge = economy.loc[1][1:] 30 jinkouzonge = economy.loc[2][1:] 31 jinchukoucha = economy.loc[3][1:] 32 y = [] 33 y1 = [] 34 y2 = [] 35 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 36 for i in chukouzonge: 37 y.append(i) 38 for i in jinkouzonge: 39 y1.append(i) 40 for i in jinchukoucha: 41 y2.append(i) 42 size = 10 43 x = np.array(x) 44 a = np.random.random(size) 45 b = np.random.random(size) 46 c = np.random.random(size) 47 48 total_width, n = 0.8, 3 49 width = total_width / n 50 x = x - (total_width - width) / 2 51 plt.figure(figsize=(15,10)) 52 plt.bar(x, y, width=width, label='出口总额') 53 plt.bar(x + width, y1, width=width, label='进口总额') 54 plt.bar(x + 2 * width, y2, width=width, label='进出口差额') 55 plt.title('进出口情况',fontdict={'weight':'normal','size': 20}) 56 plt.xlabel('年份',fontdict={'weight':'normal','size': 15}) 57 plt.ylabel('亿元(人民币)',fontdict={'weight':'normal','size': 15}) 58 plt.legend() 59 plt.savefig(r'D:/program/表格数据可视化/进出口情况.png', dpi=100) 60 plt.show() 61 62 x = ['2020','2019','2018','2017','2016','2015','2014','2013','2012','2011'] 63 y = [] 64 jinchukouzonge = economy.loc[4][1:] 65 for i in jinchukouzonge: 66 y.append(i) 67 labels = 'Frogs', 'Hogs', 'Dogs', 'Logs' 68 sizes = [15, 30, 45, 10] 69 explode = (0.1, 0, 0, 0,0,0,0,0,0,0) # only "explode" the 2nd slice (i.e. 'Hogs') 70 71 fig1, ax1 = plt.subplots() 72 ax1.pie(y, explode=explode, labels=x, autopct='%1.1f%%', 73 shadow=True, startangle=90) 74 ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle. 75 plt.title('进出口总额(美元)占比饼状图') 76 plt.savefig(r'D:/program/表格数据可视化/进出口总额(美元)占比饼状图.png', dpi=100) 77 plt.show() 78 79 x = ['2020','2019','2018','2017','2016','2015','2014','2013','2012','2011'] 80 y = [] 81 jinchukouzonge = economy.loc[4][1:] 82 for i in jinchukouzonge: 83 y.append(i) 84 labels = 'Frogs', 'Hogs', 'Dogs', 'Logs' 85 sizes = [15, 30, 45, 10] 86 explode = (0.1, 0, 0, 0,0,0,0,0,0,0) # only "explode" the 2nd slice (i.e. 'Hogs') 87 88 fig1, ax1 = plt.subplots() 89 ax1.pie(y, explode=explode, labels=x, autopct='%1.1f%%', 90 shadow=True, startangle=90) 91 ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle. 92 plt.title('进出口总额(美元)占比饼状图') 93 plt.savefig(r'D:/program/表格数据可视化/进出口总额(美元)占比饼状图.png', dpi=100) 94 plt.show() 95 96 travel = pd.read_csv(r'D:/program/表格数据可视化/旅游业—国内旅游情况.csv', header=2) 97 travel.head(9) 98 99 guonei = travel.loc[6][1:] 100 chengzhen = travel.loc[7][1:] 101 nongcun = travel.loc[8][1:] 102 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 103 y = [] 104 y1 = [] 105 y2 = [] 106 for i in guonei: 107 y.append(i) 108 for i in chengzhen: 109 y1.append(i) 110 for i in nongcun: 111 y2.append(i) 112 size = 10 113 x = np.array(x) 114 a = np.random.random(size) 115 b = np.random.random(size) 116 c = np.random.random(size) 117 118 total_width, n = 0.8, 3 119 width = total_width / n 120 x = x - (total_width - width) / 2 121 plt.figure(figsize=(15,10)) 122 plt.bar(x + width, y1, width=width, label='城镇居民国内旅游人均花费',color='g') 123 plt.bar(x, y, width=width, label='国内旅游人均花费') 124 plt.bar(x + 2 * width, y2, width=width, label='农村居民国内旅游人均花费') 125 plt.title('旅游人均花费情况',fontdict={'weight':'normal','size': 20}) 126 plt.xlabel('年份',fontdict={'weight':'normal','size': 15}) 127 plt.ylabel('元(人民币)',fontdict={'weight':'normal','size': 15}) 128 plt.legend() 129 plt.savefig(r'D:/program/表格数据可视化/旅游人均花费情况.png', dpi=100) 130 plt.show() 131 132 x = [2020,2019,2018,2017,2016,2015,2014,2013,2012,2011] 133 y = [] 134 zonghuafei = travel.loc[3][1:] 135 for i in jinchukouzonge: 136 y.append(i) 137 fig, axes = plt.subplots(1, 1, figsize=(10, 5)) 138 # 折线图 139 axes.plot(x, y, linestyle='-', color='r', marker='+', linewidth=1.5) 140 # 画网格线 141 axes.grid(which='minor', c='lightgrey') 142 # 设置x、y轴标签 143 axes.set_ylabel("亿元(人民币)") 144 axes.set_xlabel("年份") 145 plt.title('国内旅游总花费趋势') 146 plt.savefig(r'D:/program/表格数据可视化/国内旅游总花费趋势图.png', dpi=100) 147 # 展示图片 148 plt.show() 149 150 life = pd.read_csv(r'D:/program/表格数据可视化/人民生活—全国及分城镇居民收支基本情况.csv', header=2) 151 life.head(12) 152 153 x = [2020,2019,2018,2017,2016,2015,2014,2013] 154 y = [] 155 jumin = life.loc[3][1:] 156 for i in jumin: 157 y.append(i) 158 fig, axes = plt.subplots(1, 1, figsize=(10, 5)) 159 # 折线图 160 axes.plot(x, y, linestyle='-', color='b', marker='+', linewidth=1.5) 161 # 画网格线 162 axes.grid(which='minor', c='lightgrey') 163 # 设置x、y轴标签 164 axes.set_ylabel("元(人民币)") 165 axes.set_xlabel("年份") 166 plt.title('居民人均可支配收入变化趋势图') 167 plt.savefig(r'D:/program/表格数据可视化/居民人均可支配收入变化趋势图.png', dpi=100) 168 # 展示图片 169 plt.show() 170 171 jm = life.loc[6][1:] 172 chengzhen = life.loc[8][1:] 173 nongcun = life.loc[10][1:] 174 y = [] 175 y1 = [] 176 y2 = [] 177 for i in jm: 178 y.append(i) 179 for i in chengzhen: 180 y1.append(i) 181 for i in nongcun: 182 y2.append(i) 183 size = 10 184 x = [2020,2019,2018,2017,2016,2015,2014,2013] 185 x = np.array(x) 186 a = np.random.random(size) 187 b = np.random.random(size) 188 c = np.random.random(size) 189 190 total_width, n = 0.8, 3 191 width = total_width / n 192 x = x - (total_width - width) / 2 193 plt.figure(figsize=(15,10)) 194 plt.bar(x + width, y1, width=width, label='城镇居民人均消费支出',color='g') 195 plt.bar(x, y, width=width, label='居民人均消费支出') 196 plt.bar(x + 2 * width, y2, width=width, label='农村居民人均消费支出') 197 plt.title('人均消费支出对比柱状图',fontdict={'weight':'normal','size': 20}) 198 plt.xlabel('年份',fontdict={'weight':'normal','size': 15}) 199 plt.ylabel('元(人民币)',fontdict={'weight':'normal','size': 15}) 200 plt.legend() 201 plt.savefig(r'D:/program/表格数据可视化/人均消费支出对比柱状图.png', dpi=100) 202 plt.show() 203 204 x = ['2020','2019','2018','2017','2016','2015','2014'] 205 y = [] 206 guonei = life.loc[1][1:-1] 207 print(guonei) 208 for i in guonei: 209 y.append(i) 210 explode = (0, 0, 0, 0.2,0,0,0) # only "explode" the 2nd slice (i.e. 'Hogs') 211 212 fig1, ax1 = plt.subplots() 213 ax1.pie(y, explode=explode, labels=x, autopct='%1.1f%%', 214 shadow=True, startangle=90) 215 ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle. 216 plt.title('居民人均可支配收入同比增长饼状图') 217 plt.savefig(r'D:/program/表格数据可视化/居民人均可支配收入同比增长饼状图.png', dpi=100) 218 plt.show() 219 220 X = [] 221 y = [] 222 for i in life.loc[0][1:]: 223 X.append(i) 224 for i in life.loc[2][1:]: 225 y.append(i) 226 227 print(X) 228 print(y) 229 230 X_train = X[:9] 231 y_train = y[:9] 232 n_train = len(X_train) 233 234 X_test = X[5:] 235 y_test = y[5:] 236 n_test = len(X_test) 237 238 from sklearn.linear_model import LinearRegression 239 from sklearn.linear_model import Lasso 240 from sklearn.linear_model import Ridge 241 x_data = np.array(X_train) 242 y_data = np.array(y_train ) 243 x_data = x_data.reshape(-1,1) 244 y_data = y_data.reshape(-1,1) 245 X2 = np.hstack([x_data]) 246 print(X2.shape) 247 model = LinearRegression() # 线性回归 248 model.fit(X2,y_data) 249 y_pre = model.predict(X2) 250 t = np.arange(len(x_data)) 251 plt.plot(x_data,y_pre,color='g') 252 plt.scatter(x_data, y_data) 253 plt.title('y = w*x+w2*(x^2)+b') 254 plt.legend(('预测值','实际值'),loc='upper left') 255 plt.show() 256 257 x_data = np.array(X_train) 258 y_data = np.array(y_train ) 259 x_data = x_data.reshape(-1,1) 260 y_data = y_data.reshape(-1,1) 261 X2 = np.hstack([x_data ** 2,x_data]) 262 print(X2.shape) 263 model = LinearRegression() # 线性回归 264 model.fit(X2,y_data) 265 y_pre = model.predict(X2) 266 t = np.arange(len(x_data)) 267 plt.plot(x_data,y_pre,color='g') 268 plt.scatter(x_data, y_data) 269 plt.title('y = w*x+w2*(x^2)+b') 270 plt.legend(('预测值','实际值'),loc='upper left') 271 plt.show()
总结:
可以看出各个指标都随时间增长,足以说明我国近几年的经济和居民生活水平趋于上涨趋势,并且可以看出居民人均可支配收入(元)和城镇居民人均可支配收入(元)之间的关系呈线性关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号