

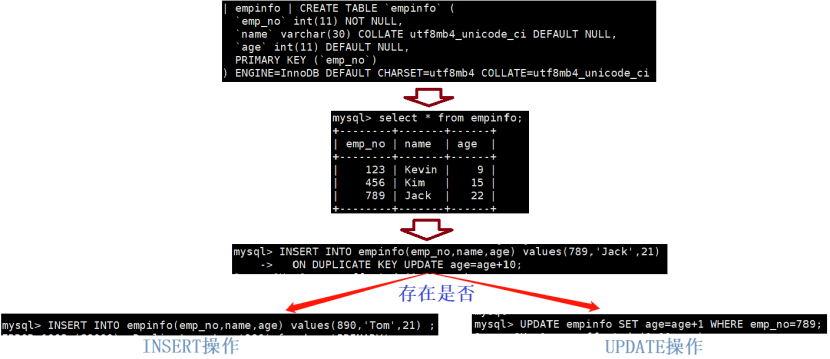
mysql数据插入INSERT INTO ON DUMPLICATE KEY UPDATE执行
执行逻辑图
初始化表结构
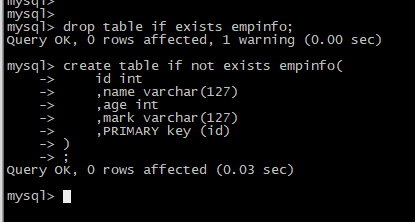
-- 初始化表结构
drop table if exists empinfo;
create table if not exists empinfo(
id int
,name varchar(127)
,age int
,mark varchar(127)
,PRIMARY key (id)
)
;
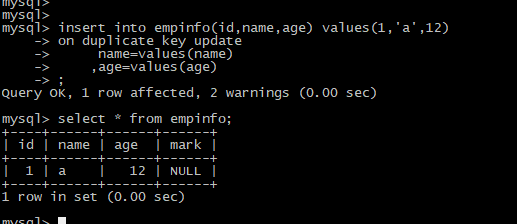
第一次插入数据id=1
insert into empinfo(id,name,age) values(1,'a',12)
on duplicate key update
name=values(name)
,age=values(age)
;
select * from empinfo;
说明: 当主键不存在时,执行insert into语句,等值SQL如下:
insert into empinfo(id,name,age) values(1,'a',12);
注意:update使用values时,只支持字段名,不支持计算和赋值
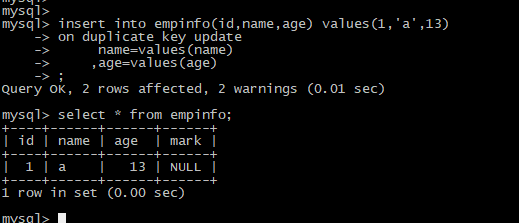
第二次插入数据id=1
insert into empinfo(id,name,age) values(1,'a',13)
on duplicate key update
name=values(name)
,age=values(age)
;
select * from empinfo;
说明:主键1已存在,执行update语句,等值SQL如下:
update empinfo
set name='a'
,age=13
where id = 1
;
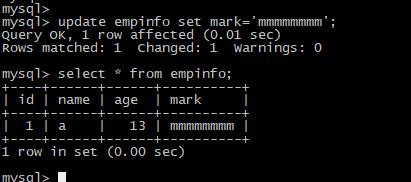
更新mark字段
update empinfo set mark='mmmmmmmm';
select * from empinfo;
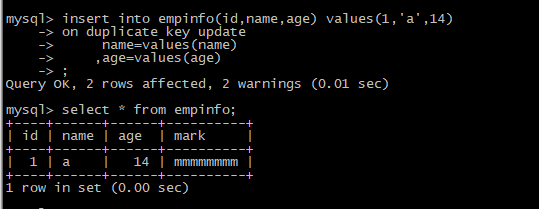
第三次插入数据id=1
insert into empinfo(id,name,age) values(1,'a',14)
on duplicate key update
name=values(name)
,age=values(age)
;
select * from empinfo;
说明: 主键1已存在,执行update语句,此处不涉及的字段mark保持不变,等值SQL如下:
update empinfo
set name='a'
,age=14
where id = 1
;
注意: 此处更新的值取的是insert中的VALUE值。
另外一种写法
insert into empinfo(id,name,age) values(2,'a',12)
on duplicate key update
name=name
,age=age+1
;
说明: 支持直接赋值,当主键已存在时,等值SQL如下:
update person
set name=name
,age=age+1
where id = 1
;
注意: 此处更新的值取的是结果表里的字段或直接赋值
批量插入
insert into empinfo(id,name,age) values(1,'a',15),(2,'b',20)
on duplicate key update
name=values(name)
,age=values(age)
;
与replace into的差异
id不存在
均为insert into
id已存在
replace into 为delete + insert into
INSERT INTO ON DUMPLICATE KEY UPDATE为update
注意
ON DUPLICATE KEY UPDATE语句,并且要插入的行将导致惟一索引或主键中出现重复值,则会对旧行进行更新。但主键和唯一键同事存在的时候,选择主键。
drop table if exists tbl_test;
create table tbl_test(
id int primary key auto_increment,
name varchar(30) CHARACTER SET utf8 COLLATE utf8_bin unique not null,
age int comment '年龄',
address varchar(50) comment '住址',
update_time datetime default null
) comment '测试表';
drop table if exists tbl_test2;
create table tbl_test2(
id int primary key auto_increment,
name varchar(30) CHARACTER SET utf8 COLLATE utf8_bin unique not null,
age int comment '年龄',
address varchar(50) comment '住址',
update_time datetime default null
) comment '测试表';
insert into tbl_test2(name,age,address,update_time) values('zhangsan',20,'杭州',now());
insert into tbl_test2(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now());
insert into tbl_test(
name
,age
,address
,update_time
)
select
name
,age
,address
,update_time
from tbl_test2
on duplicate key update
age = values(age)
,address = values(address)
,update_time=values(update_time)
;
insert into table_name_test (
id
,bu_code
,table_name
,source_table_name
,source_count_sql
,source_ids_sql
,source_detail_sql
,target_detail_sql
,remark
)
select
id
,bu_code
,table_name
,source_table_name
,source_count_sql
,source_ids_sql
,source_detail_sql
,target_detail_sql
,remark
from table_name_test
where bu_code = 'cy_sr_dataset_test'
and table_name = '%(table_name)s'
ON DUPLICATE KEY UPDATE
bu_code = 'cy_sr_dataset_test'
,table_name = '%(table_name)s'
,source_table_name = '%(source_table_name)s'
,source_count_sql = 'select count(*) from %(source_table_name)s'
,source_ids_sql = 'select row_number() over() as id from %(table_name)s limit 100'
,source_detail_sql = "%(source_detail_sql)s"
,target_detail_sql = "%(target_detail_sql)s"
,remark = ''
;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号