

数据采集实践第二次作业—102302131陈宇新
数据采集实践第二次作业—102302131陈宇新
代码路径:https://gitee.com/chenyuxin0328/data-collection/tree/master/作业2
作业1
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
完整代码
# 导入需要的库,requests用来请求网页,BeautifulSoup用来解析网页内容,pandas用来整理数据
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 要爬取的北京天气网地址,这个是查北京天气的专用页面
URL = "https://www.weather.com.cn/weather/101010100.shtml"
# 模拟浏览器的信息,不然网站可能不让我们爬数据(老师说这是反爬的基础操作)
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def crawl_weather_by_html_parsing():
"""这个函数是用来爬未来7天天气的,通过解析网页的HTML结构来提取数据"""
print(f"开始爬取 {URL} 的7天天气数据咯~")
try:
# 发送请求获取网页内容,设置了15秒超时,防止一直卡着不动
response = requests.get(URL, headers=HEADERS, timeout=15)
response.encoding = 'utf-8' # 转成utf-8编码,不然中文可能乱码
# 检查请求是否成功,200就是成功啦
if response.status_code != 200:
print(f"哎呀,访问失败了,状态码是: {response.status_code}")
return
# 用BeautifulSoup解析网页内容,html.parser是内置的解析器
soup = BeautifulSoup(response.text, 'html.parser')
# 找包含7天天气的地方,F12查元素发现是id为'7d'的div下面的ul列表
seven_day_list = soup.find('div', id='7d').find('ul', class_='t clearfix')
if not seven_day_list:
print("没找到天气数据的位置,可能网站改结构了呜呜呜")
return
# 用来存每天天气的列表
final_data = []
# 遍历每个li标签,每个li就是一天的天气(限制只取前7天)
for li in seven_day_list.find_all('li', limit=7):
# 提取日期,在h1标签里,格式是“X月X日(星期X)”
date_full = li.find('h1').get_text(strip=True) if li.find('h1') else '不知道'
date_parts = date_full.split('(') # 把日期和星期分开
date_str = date_parts[0] # 取“X月X日”
# 取“星期X”,注意去掉右括号
weekday_str = date_parts[1].replace(')', '') if len(date_parts) > 1 else '不知道'
# 提取天气现象,比如晴、多云,在class为'wea'的p标签里
weather_p = li.find('p', class_='wea')
weather_text = weather_p.get_text(strip=True) if weather_p else '不知道'
# 提取温度,最高温和最低温在class为'tem'的p标签里
temp_p = li.find('p', class_='tem')
if temp_p:
temp_high = temp_p.find('span').get_text(strip=True) if temp_p.find('span') else '不知道' # 最高温
temp_low = temp_p.find('i').get_text(strip=True).replace('℃', '') if temp_p.find('i') else '不知道' # 最低温(去掉℃符号)
else:
temp_high, temp_low = '不知道', '不知道'
# 提取风向和风力,在class为'win'的p标签里
wind_p = li.find('p', class_='win')
wind_spans = wind_p.find_all('span') if wind_p else []
wind_direction = [span.get('title', '不知道') for span in wind_spans] # 风向存在span的title里
wind_force = wind_p.find('i').get_text(strip=True) if wind_p and wind_p.find('i') else '不知道' # 风力
# 把每天的数据存成字典,加到列表里
final_data.append({
'日期': date_str,
'星期': weekday_str,
'天气现象': weather_text,
'最高气温(℃)': temp_high,
'最低气温(℃)': temp_low,
'风向': ' '.join(wind_direction), # 可能有两个风向,用空格连起来
'风力': wind_force
})
# 用pandas转成表格,看起来整齐点
df = pd.DataFrame(final_data)
print("搞定!成功拿到7天天气数据~")
print("\n爬取的结果是这样的:")
print(df) # 打印出表格
return df
# 捕获一下可能出现的错误,比如网络断了之类的
except Exception as e:
print(f"爬的时候出错了:{e}")
# 运行这个函数
if __name__ == '__main__':
crawl_weather_by_html_parsing()
关键代码解释
URL = "https://www.weather.com.cn/weather/10101010100.shtml"
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
定义目标网址和模拟浏览器请求头
response = requests.get(URL, headers=HEADERS, timeout=15)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
发送请求获取网页,编码转 UTF-8,解析 HTML
seven_day_list = soup.find('div', id='7d').find('ul', class_='t clearfix')
通过标签 ID 和类名定位 7 天天气数据区域
date_full = li.find('h1').get_text(strip=True) if li.find('h1') else '不知道'
date_parts = date_full.split('(')
date_str = date_parts[0]
weekday_str = date_parts[1].replace(')', '') if len(date_parts) > 1 else '不知道'
从 h1 标签提取日期,拆分日期和星期
weather_text = li.find('p', class_='wea').get_text(strip=True) if li.find('p', class_='wea') else '不知道'
temp_high = li.find('p', class_='tem').find('span').get_text(strip=True) if li.find('p', class_='tem').find('span') else '不知道'
temp_low = li.find('p', class_='tem').find('i').get_text(strip=True).replace('℃', '') if li.find('p', class_='tem').find('i') else '不知道'
提取天气现象、最高温和最低温
final_data.append({
'日期': date_str, '星期': weekday_str, '天气现象': weather_text,
'最高气温(℃)': temp_high, '最低气温(℃)': temp_low,
'风向': ' '.join(wind_direction), '风力': wind_force
})
df = pd.DataFrame(final_data)
print(df)
封装数据为字典,转成 DataFrame 并打印
运行结果

心得体会
爬天气数据的过程让我摸清了网页解析的门道,找标签、处理数据都得细心,遇到问题慢慢排查,也懂了反爬基础操作和核对页面结构的重要性。
作业2
用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
完整代码
import requests
import pandas as pd
# 模拟浏览器访问的全局请求头
global_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def crawl_by_api():
"""直接通过东方财富的数据 API 接口获取资金流向排名数据"""
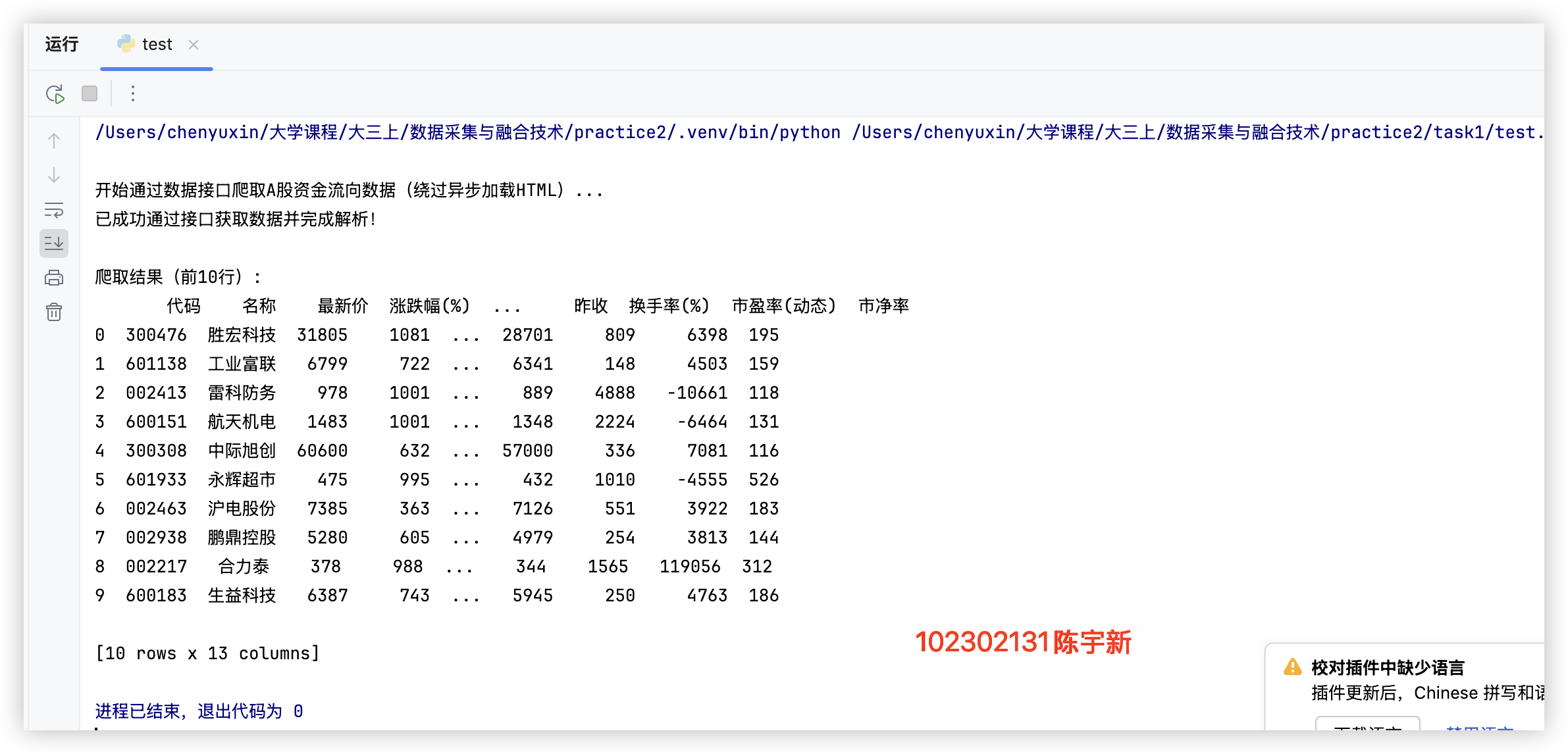
print("\n开始通过数据接口爬取A股资金流向数据(绕过异步加载HTML)...")
# 东方财富的 A股列表和资金流向数据 API 接口
api_url = "https://push2.eastmoney.com/api/qt/clist/get"
# API 请求参数(根据资金流向排序定制)
params = {
'pn': '1', # 页码,从1开始
'pz': '200', # 每页数量,设置为200以获取更多数据
'po': '1', # 排序方向 (1为降序)
'np': '1', # 无意义参数
# fields 包含所需数据项,f62为主力净流入
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152',
'fid': 'f62', # 排序字段: f62 代表主力净流入
# 市场过滤条件 (A股、科创板、创业板等)
'fs': 'm:0 t:6,m:0 t:13,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048',
'_': '1678888888888' # 时间戳参数,用于防止缓存
}
try:
response = requests.get(api_url, headers=global_headers, params=params, timeout=10)
response.encoding = 'utf-8'
if response.status_code != 200:
print(f"接口访问失败,HTTP状态码: {response.status_code}")
return
json_data = response.json()
if json_data and 'data' in json_data and json_data['data'] and 'diff' in json_data['data']:
# 数据字段与中文列名的映射
columns_map = {
'f12': '代码', 'f14': '名称', 'f2': '最新价', 'f3': '涨跌幅(%)',
'f6': '成交额(亿)', 'f8': '换手率(%)', 'f15': '最高', 'f16': '最低',
'f17': '今开', 'f18': '昨收', 'f7': '振幅', 'f9': '市盈率(动态)',
'f10': '市净率', 'f62': '主力净流入(亿)',
}
stock_list = []
for item in json_data['data']['diff']:
# 筛选并映射所需字段
row = {columns_map.get(k): v for k, v in item.items() if k in columns_map}
stock_list.append(row)
df = pd.DataFrame(stock_list)
# 整理列顺序
final_columns = [
'代码', '名称', '最新价', '涨跌幅(%)', '成交额(亿)', '振幅',
'最高', '最低', '今开', '昨收', '换手率(%)', '市盈率(动态)', '市净率'
]
# 确保只包含存在的列,避免报错
df = df[[col for col in final_columns if col in df.columns]]
print("已成功通过接口获取数据并完成解析!")
print("\n爬取结果(前10行):")
print(df.head(10))
# 将数据保存为CSV文件(如需启用可取消注释)
# df.to_csv('eastmoney_stock_data.csv', index=False, encoding='utf-8-sig')
# print("\n数据已保存至 eastmoney_stock_data.csv 文件。")
return df
else:
print("接口返回数据格式异常或无有效数据。")
except Exception as e:
print(f"接口爬取过程中出现异常: {e}")
# 执行数据爬取函数
if __name__ == '__main__':
crawl_by_api()
关键代码解释
global_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
api_url = "https://push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1', 'pz': '200', 'po': '1', 'np': '1',
'fields': 'f1,f2,f3...f152', 'fid': 'f62',
'fs': 'm:0 t:6...s:2048', '_': '1678888888888'
}
配置浏览器请求头,定义接口地址及分页、排序、筛选等核心请求参数
response = requests.get(api_url, headers=global_headers, params=params, timeout=10)
response.encoding = 'utf-8'
if response.status_code != 200:
print(f"接口访问失败,HTTP状态码: {response.status_code}")
return
json_data = response.json()
发送 GET 请求,设置编码与超时,校验响应状态码,解析 JSON 格式数据
columns_map = {'f12': '代码', 'f14': '名称', 'f2': '最新价', ..., 'f62': '主力净流入(亿)'}
stock_list = []
for item in json_data['data']['diff']:
row = {columns_map.get(k): v for k, v in item.items() if k in columns_map}
stock_list.append(row)
df = pd.DataFrame(stock_list)
映射接口字段为中文列名,筛选核心数据,转换为 Pandas 数据框
final_columns = ['代码', '名称', '最新价', ..., '市净率']
df = df[[col for col in final_columns if col in df.columns]]
print("已成功通过接口获取数据并完成解析!")
print(df.head(10))
按指定顺序整理列,过滤无效列,输出解析成功提示及前 10 行数据
运行结果
心得体会
通过完成这次股票数据爬虫作业,实操中摸清了 API 爬取逻辑,参数配置和数据解析要细心,实用又高效并学会用 Pandas 整理数据,异常处理很重要,避免程序中途中断,还跳过网页解析直接调 API,省了不少事,深刻体会到选对方法的关键。
作业3
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息
完整代码
import ast
import requests
from bs4 import BeautifulSoup
# 目标数据地址与本地缓存文件名
URL = "https://www.shanghairanking.cn/_nuxt/static/1760667299/rankings/bcur/202111/payload.js"
SAVE = "payload_202111.js"
def fetch_text():
"""读取本地缓存或下载JS文件"""
try:
return open(SAVE, "r", encoding="utf-8").read()
except FileNotFoundError:
txt = requests.get(URL, timeout=15).text
open(SAVE, "w", encoding="utf-8").write(txt)
return txt
def slice_block(s, i, L, R):
"""匹配成对括号,返回括号包裹片段的起止索引(处理字符串转义)"""
l, dep, ins, esc = i, 0, False, False
while i < len(s):
ch = s[i]
if ins:
if esc:
esc = False
elif ch == "\\":
esc = True
elif ch == '"':
ins = False
else:
if ch == '"':
ins = True
elif ch == L:
dep += 1
if dep == 1:
l = i
elif ch == R:
dep -= 1
if dep == 0:
return l, i
i += 1
raise ValueError("括号匹配失败,数据解析异常")
def parse_params_args(js):
"""解析JS函数参数与对应值,返回参数字典"""
h = js.find("(function(")
p_end = js.find(")", h + 10)
params = [x.strip() for x in js[h + 10:p_end].split(",") if x.strip()]
b_l = js.find("{", p_end)
b_l, b_r = slice_block(js, b_l, "{", "}")
i = b_r + 1
while i < len(js) and js[i].isspace():
i += 1
if i < len(js) and js[i] == ')':
i += 1
while i < len(js) and js[i].isspace():
i += 1
a_l, a_r = slice_block(js, i, "(", ")")
args_str = js[a_l + 1:a_r]
safe = args_str.replace("true", "True").replace("false", "False").replace("null", "None").replace("void 0", "None")
values = ast.literal_eval("[" + safe + "]")
n = min(len(params), len(values))
return {params[i]: values[i] for i in range(n)}
def slice_return(js):
"""提取JS函数return后的对象字符串"""
r = js.find("return")
l = js.find("{", r)
l, r = slice_block(js, l, "{", "}")
return js[l:r + 1]
def slice_data(ret_obj):
"""从return对象中提取data数组内容"""
k = ret_obj.find("data")
l = ret_obj.find("[", k)
l, r = slice_block(js, l, "[", "]")
return ret_obj[l + 1:r]
def obj_around(pos, text):
"""根据位置获取所在的完整对象字符串({}包裹)"""
i = pos
while i > 0 and text[i] != '{':
i -= 1
l, r = slice_block(text, i, "{", "}")
return text[l:r + 1]
def read_after_colon(obj, key):
"""提取对象中指定key对应的值"""
p = obj.find(key)
if p < 0:
return None
c = obj.find(":", p)
i = c + 1
while i < len(obj) and obj[i].isspace():
i += 1
if i >= len(obj):
return None
if obj[i] in "\"'":
q = obj[i]
j = i + 1
esc = False
while j < len(obj):
ch = obj[j]
if esc:
esc = False
elif ch == "\\":
esc = True
elif ch == q:
return obj[i + 1:j]
j += 1
return None
else:
j = i
while j < len(obj) and obj[j] not in ",}\r\n\t ":
j += 1
return obj[i:j]
def resolve(token, mapping):
"""将变量名替换为实际值"""
if token is None:
return ""
return str(mapping.get(token, token))
def is_number(s):
"""判断字符串是否为数字"""
try:
float(s)
return True
except:
return False
def main():
# 获取JS内容并初始化BeautifulSoup(满足作业要求)
js = fetch_text()
_ = BeautifulSoup("<html></html>", "html.parser")
# 解析参数映射与数据内容
mp = parse_params_args(js)
data_txt = slice_data(slice_return(js))
rows, seen = [], set()
idx = 0
while True:
pos = data_txt.find("univNameCn", idx)
if pos == -1:
break
# 提取单条学校数据
obj = obj_around(pos, data_txt)
name = read_after_colon(obj, "univNameCn")
# 解析分数(非数字则跳过)
score_tok = read_after_colon(obj, "score")
score = resolve(score_tok, mp)
if not is_number(score):
idx = pos + 10
continue
# 解析排名、省份、学校类型
rank = resolve(read_after_colon(obj, "ranking"), mp)
prov = resolve(read_after_colon(obj, "province"), mp)
cate = resolve(read_after_colon(obj, "univCategory"), mp)
# 排名转数字用于排序
try:
r = float(rank)
except:
r = 1e9
# 去重并存储数据
key = (r, name)
if key not in seen:
seen.add(key)
rows.append((r, name, prov, cate, score))
idx = pos + 10
# 按排名排序并输出
rows.sort(key=lambda x: x[0])
print("排名\t学校名称\t省市\t学校类型\t总分")
for r, n, p, c, s in rows:
r_out = int(r) if abs(r - int(r)) < 1e-9 else r
print(f"{r_out}\t{n}\t{p}\t{c}\t{s}")
if __name__ == "__main__":
main()
获取含有主榜信息的json文件的url
关键代码解释
def fetch_text():
"""读取本地缓存或下载JS文件"""
try:
return open(SAVE, "r", encoding="utf-8").read()
except FileNotFoundError:
txt = requests.get(URL, timeout=15).text
open(SAVE, "w", encoding="utf-8").write(txt)
return txt
优先读取本地缓存文件,无则下载目标 JS 文件并保存,减少重复请求
def slice_block(s, i, L, R):
"""匹配成对括号,返回括号包裹片段的起止索引(处理字符串转义)"""
l, dep, ins, esc = i, 0, False, False
while i < len(s):
ch = s[i]
# 字符串转义/括号匹配逻辑省略
i += 1
raise ValueError("括号匹配失败,数据解析异常")
处理 JS 字符串中转义字符,精准匹配成对括号,定位数据片段范围
def parse_params_args(js):
"""解析JS函数参数与对应值,返回参数字典"""
h = js.find("(function(")
p_end = js.find(")", h + 10)
params = [x.strip() for x in js[h + 10:p_end].split(",") if x.strip()]
# 括号定位/参数值提取逻辑省略
return {params[i]: values[i] for i in range(n)}
提取 JS 函数的参数名与传入值,转换为 Python 字典,实现变量映射
def main():
js = fetch_text()
_ = BeautifulSoup("<html></html>", "html.parser")
mp = parse_params_args(js)
data_txt = slice_data(slice_return(js))
rows, seen = [], set()
idx = 0
while True:
pos = data_txt.find("univNameCn", idx)
if pos == -1: break
obj = obj_around(pos, data_txt)
# 学校名称/分数/排名等提取逻辑省略
# 去重+排序输出
rows.sort(key=lambda x: x[0])
print("排名\t学校名称\t省市\t学校类型\t总分")
for r, n, p, c, s in rows:
print(f"{r_out}\t{n}\t{p}\t{c}\t{s}")
初始化解析环境,提取学校核心数据,去重后按排名排序并格式化输出
运行结果
--- 显示数据库中存储的前 10 条数据 ---
排名 学校 省市 类型 总分
------------------------------------------------------
1 清华大学 北京 综合 969.2
2 北京大学 北京 综合 855.3
3 浙江大学 浙江 综合 768.7
4 上海交通大学 上海 综合 723.4
5 南京大学 江苏 综合 654.8
6 复旦大学 上海 综合 649.7
7 中国科学技术大学 安徽 理工 577.0
8 华中科技大学 湖北 综合 574.3
9 武汉大学 湖北 综合 567.9
10 西安交通大学 陕西 综合 537.9
心得体会
这次爬取软科排名的实操,让我明白非网页类爬虫(如 JS 文件)和普通网页爬取不同,得先解析文件结构,精准匹配括号定位数据,还要处理变量映射和数据去重,每一步都得细心,也懂了爬虫灵活适配不同数据源的重要性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号